

Z9411_КафкаРС_ИИС_ЛР3
.docxМИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ»
ИНСТИТУТ НЕПРЕРЫВНОГО И ДИСТАНЦИОННОГО ОБРАЗОВАНИЯ
КАФЕДРА 82 |
ОЦЕНКА
ПРЕПОДАВАТЕЛЬ
доцент |
|
|
|
В. С. Блюм |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ЛАБОРАТОРНАЯ РАБОТА №3
|
МЕТОДЫ ПОДГОТОВКИ ДАННЫХ ДЛЯ ОБРАБОТКИ И ЗАДАЧА РАНЖИРОВАНИЯ
|
по дисциплине: Интеллектуальные информационные системы |
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ гр. № |
Z9411 |
|
|
|
Р. С. Кафка |
|
номер группы |
|
подпись, дата |
|
инициалы, фамилия |
Студенческий билет № |
2019/3603 |
|
|
|
|
Шифр ИНДО |
|
Санкт-Петербург 2024
Цель работы: изучить методы подготовки данных для обработки в пакете RapidMiner.
Ход работы:
Для начала создам новый набор данных, основанный на сведениях приемной комиссии ГУАП о поданных абитуриентами заявлениях о поступлении на направление 09.03.03 Прикладная информатика по состоянию на 26 июля 2019 года. Данные взяты на сайте ГУАП http://portal.guap.ru/?n=priem/. Далее данные были сформированы в таблицу Excel.
После этого нужно импортировать файл в RapidMiner (рисунок 1).
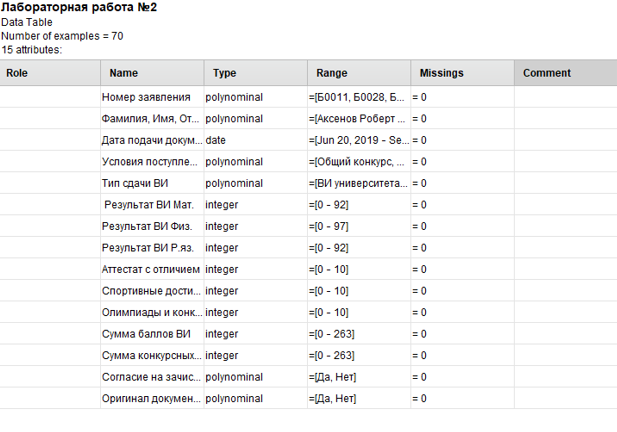 Рисунок
1 - Импортированный файл
Рисунок
1 - Импортированный файл
Теперь представим эти данные в Visualizations, здесь по оси Х отображены даты подачи документов в приемную комиссию, по Y – сумма конкурсных баллов (рисунок 2).
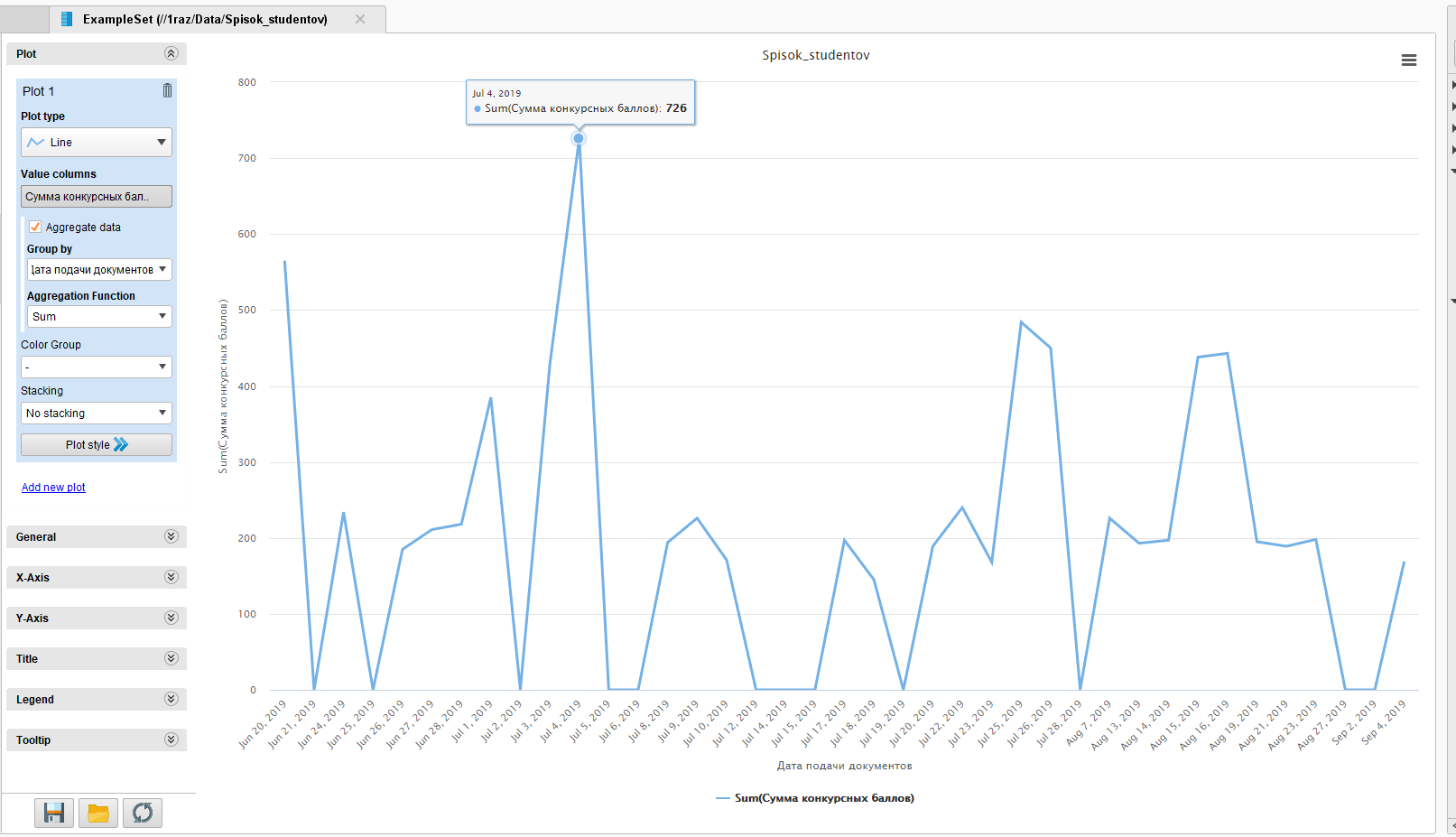 Рисунок
2 - Обрабатываемый набор данных
Рисунок
2 - Обрабатываемый набор данных
Начнем создавать процесс подготовки данных. Перетащим мышкой из вкладки «Repository» на поле «Process» папку с импортированными данными. Соединим выход «Out» папки с точкой «Res» на рабочем поле. Убедимся, что если подвести курсор к выходу «Out» можно просмотреть атрибуты импортированной таблицы с данными (рисунок 3).
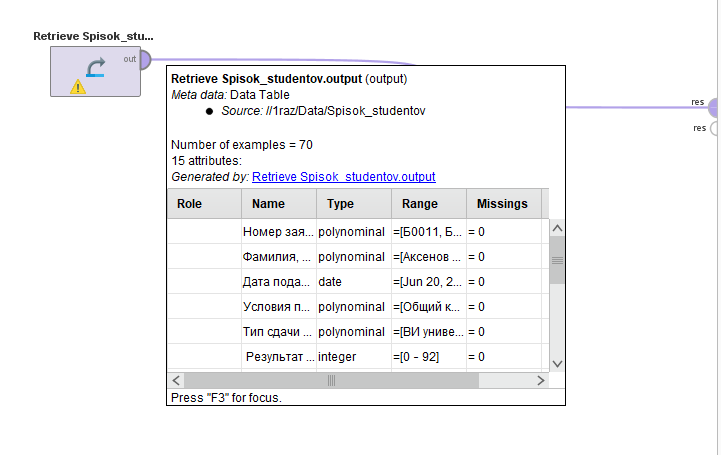 Рисунок
3 - Размещение на рабочем поле исследуемой
таблицы
Рисунок
3 - Размещение на рабочем поле исследуемой
таблицы
После этого нажмем на кнопку старта.
Как результат выполнения процесса получим набор данных импортированной таблицы (рисунок 4).
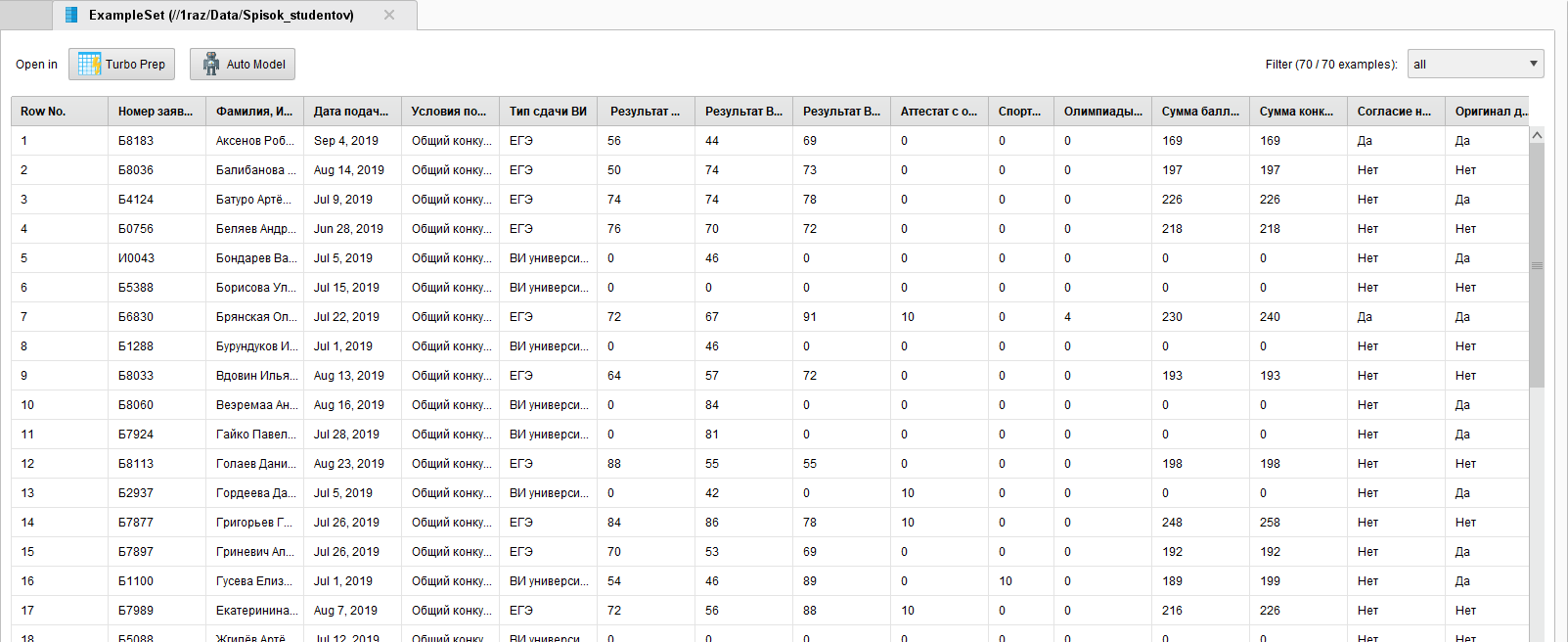 Рисунок
4 - Результат выполнения процесса
Рисунок
4 - Результат выполнения процесса
Ознакомимся с содержимым и закроем вкладку ExampleSet и нажмем кнопку Design для того, чтобы вернуться в режим программирования процесса.
Хотя все поступающие в ГУАП дали согласие на обработку их персональных данных, исключим из дальнейшего рассмотрения фамилии имена и отчества абитуриентов.
Перейдем во вкладку Operators и изучим ее содержимое. Перейдем в папку Blending (Смешенные) и там найдем папку Attributes. Поскольку требуется удалить из таблицы колонку, воспользуемся оператором SelectAttributes.
Удалим соединение выхода Out папки с точкой Res. Перетащим мышкой оператор SelectAttributes на рабочее поле и соединим выход Out папки с входом exa оператора, а его выход exa с точкой Res на рабочем поле. Сделаем активным оператором SelectAttributes щелкнув по нему мышкой так, чтобы он выделился красным цветом.
В нижней части окна активизируется вкладка Parameters (рисунок 5), а в нижней части вкладка Help.
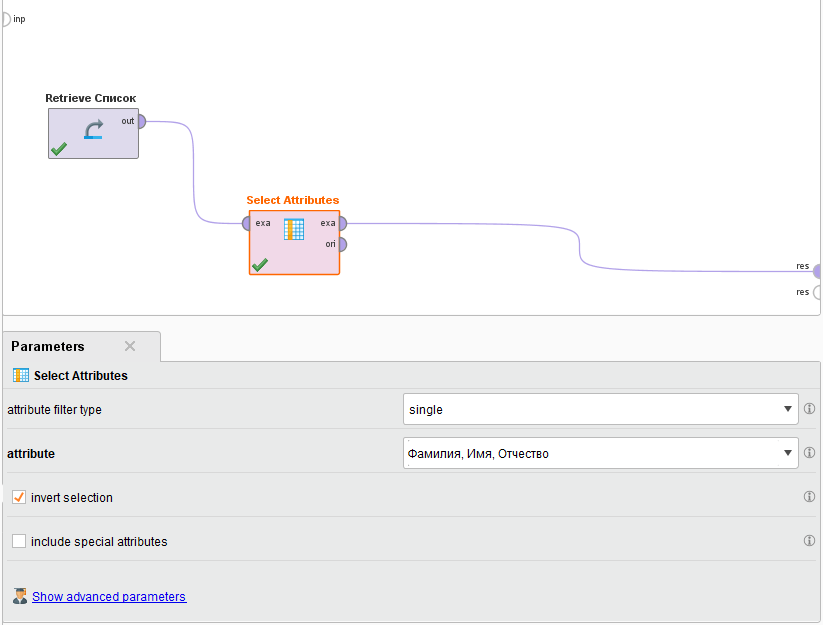 Рисунок
5 - Настройка параметров блока
SelectAttributes
Рисунок
5 - Настройка параметров блока
SelectAttributes
Настроим параметры работы блока SelectAttributes так, чтобы в окне attributefiltertype было установлено single, в окне атрибуты Фамилия, Имя, Отчество, а ключ invertselection стоял в положении включено. Запустим голубым треугольником процесс на выполнение и убедимся в том, что колонка Фамилия, Имя, Отчество в итоговой выдаче отсутствует (рисунок 6).
 Рисунок
6 - Результаты удаления колонки ФИО из
обрабатываемого набора данных
Рисунок
6 - Результаты удаления колонки ФИО из
обрабатываемого набора данных
С помощью команды File/ SaveProcessAs сохраним полученные результаты в репозитории под именем Лабораторная работа 2-Удаление колонки.
Продолжим работу с набором данных и решим задачу его сортировки. Снова обратимся к описанию атрибутов исследуемой таблицы и отметим, что в ее составе существует две колонки: Номер заявления и Дата подачи документов. Логично предположить, что номер заявления должен быть уникальным, а вот в течение одного дня в приемную комиссию может быть подано несколько заявлений. Поэтому упорядочим имеющиеся записи по номеру заявления.
Запустим обучающую систему, найдем соответствующий раздел и убедимся в существовании оператора Sort. Как и в предыдущем случае, исследуя содержимое вкладки Operators найдем его в папке Examples/ Sort.
Командой File / OpenProcess загрузим во вкладку Process ранее сохраненный процесс Лабораторная работа 2-Удаление колонки. Удалим последнюю связь и перетащим мышкой на рабочее поле оператор Sort. Выполним необходимые соединения входов и выходов, сделаем оператор Sort активным и произведем настройку его параметров. Так в окне attributename установим поле сортировки Номер заявления, а в окне sortingdirection направление сортировки increasing (рисунок 7).
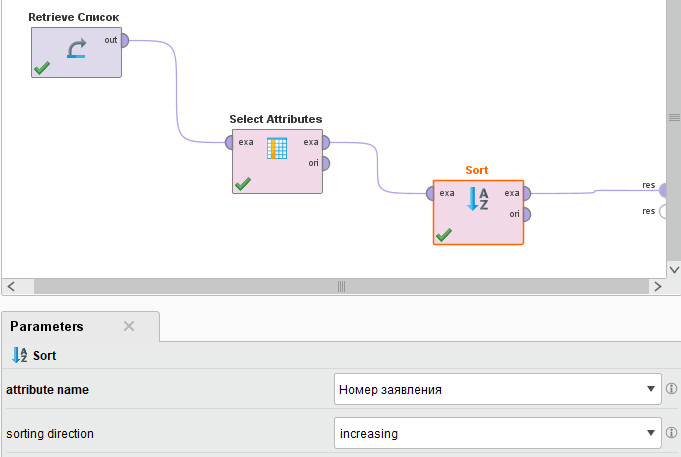 Рисунок
7 - Настройка режима сортировки
Рисунок
7 - Настройка режима сортировки
Выполним процесс и получим результаты сортировки (рисунок 8).
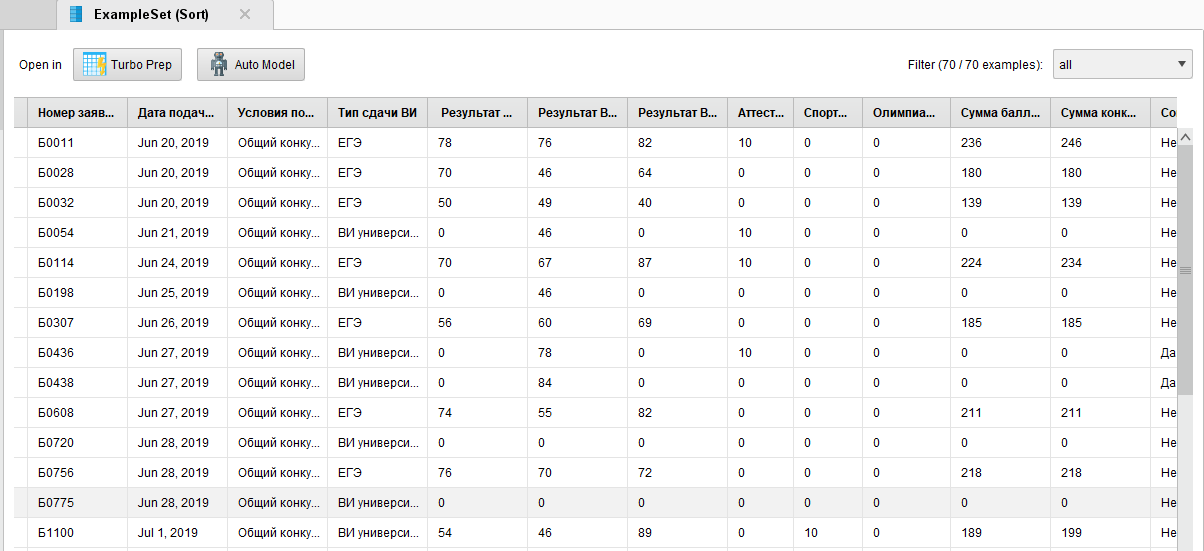 Рисунок
8 - Результаты сортировки списка
абитуриентов
Рисунок
8 - Результаты сортировки списка
абитуриентов
Воспользуемся возможностями системы визуализации и построим круговую диаграмму отображения соотношения согласий на зачисление по датам. (рисунок 9).
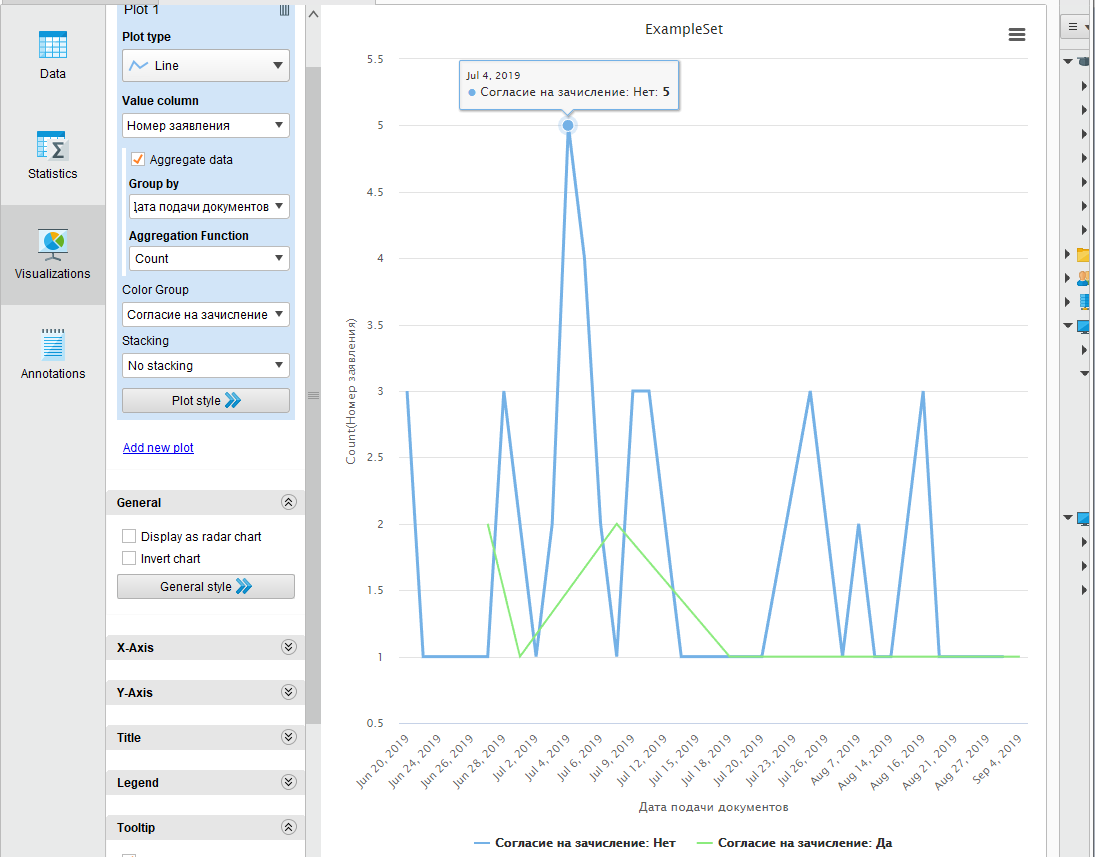 Рисунок
9 - Отображение результатов сортировки
в режиме Visualization
Рисунок
9 - Отображение результатов сортировки
в режиме Visualization
Сохраним созданный процесс как Лабораторная работа 2-Сортировка.
Вернемся в режим программирования процесса нажатием кнопки Design и решим задачу фильтрации. Сортировка и фильтрация находятся в одной категории пошагового руководства и следует ожидать, что соответствующие им операторы размещены в близких папках.
Загрузим ранее сохраненный процесс Лабораторная работа 2-Сортировка и добавим последовательно оператор фильтр сделав его активным.
На вкладке Parameters в окне conditionclass зададим значение customfilters. Нажмем кнопку AddFilters и начнем его настройку. Будем выбирать только тех абитуриентов, которые подали в приемную комиссию оригинал документа об образовании. Таких оказалось 37 человек (рисунок 10).
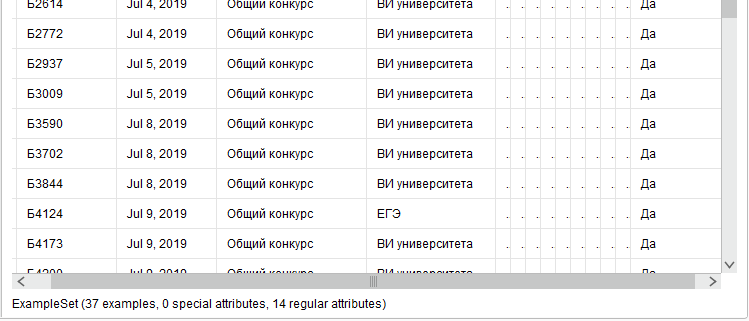 Рисунок
10 -Результаты фильтрации
Рисунок
10 -Результаты фильтрации
Воспользуемся графическим представлением данных и получим текущую ситуацию с зачислением (рисунок 11). Сохраним созданный процесс как Лабораторная работа 2-Фильтрация.
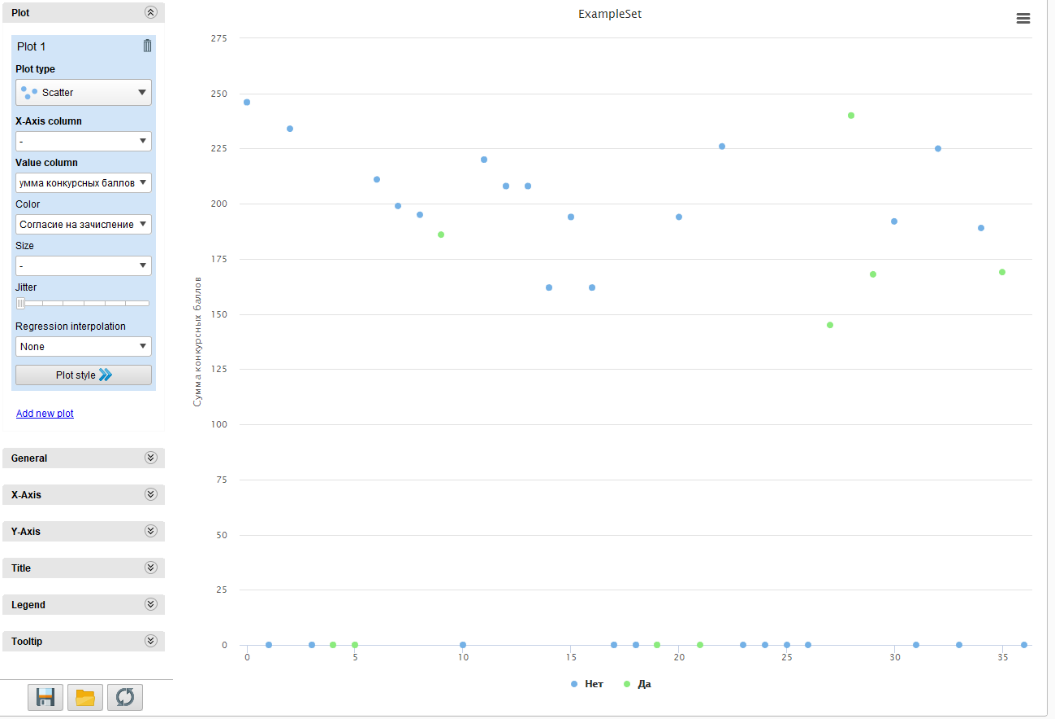 Рисунок
11 - Текущая ситуация с претендентами на
зачисление на направление 09.03.03 Прикладная
информатика.
Рисунок
11 - Текущая ситуация с претендентами на
зачисление на направление 09.03.03 Прикладная
информатика.
Вернемся к ранее сохраненному процессу Лабораторная работа 2-Фильтрация и загрузим его на новый лист. Нам необходимо провести упорядочение данных в соответствии с изложенными выше требованиями. Воспользуемся уже известным нам оператором сортировки Sort. Поскольку условия задачи требуют провести четыре последовательных сортировки, нам придется включить в процесс последовательно четыре таких оператора. Нижний уровень сортировки определяется оценкой по русскому языку. Поэтому для первого оператора последовательности attributename устанавливается в положение Результаты ВИ русский, а ключ sortingdirection в положение decreasing. Следующий оператор имеет attributenameРезультаты ВИ физика, следующий Результаты ВИ математика и последний Сумма конкурсных баллов. Все операторы имеют ключ sortingdirection в положении decreasing. Результаты программирования процесса показаны на рисунке 12.
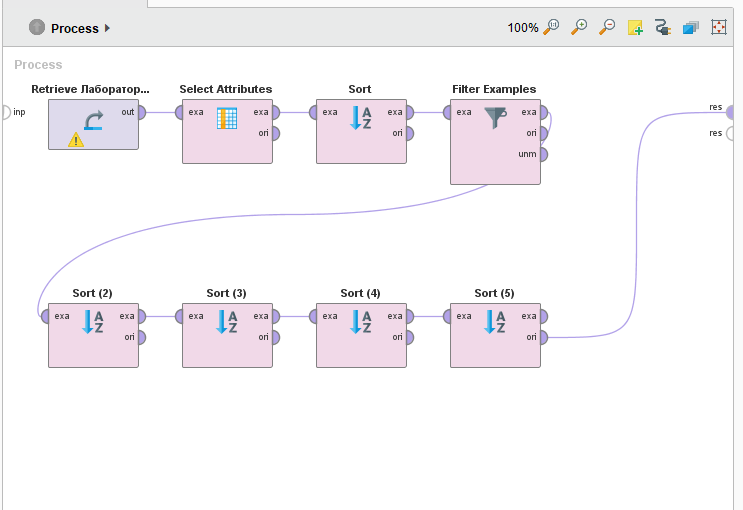 Рисунок
12 - Программирование ранжирования
абитуриентов
Рисунок
12 - Программирование ранжирования
абитуриентов
Его выполнения на рисунке 13.
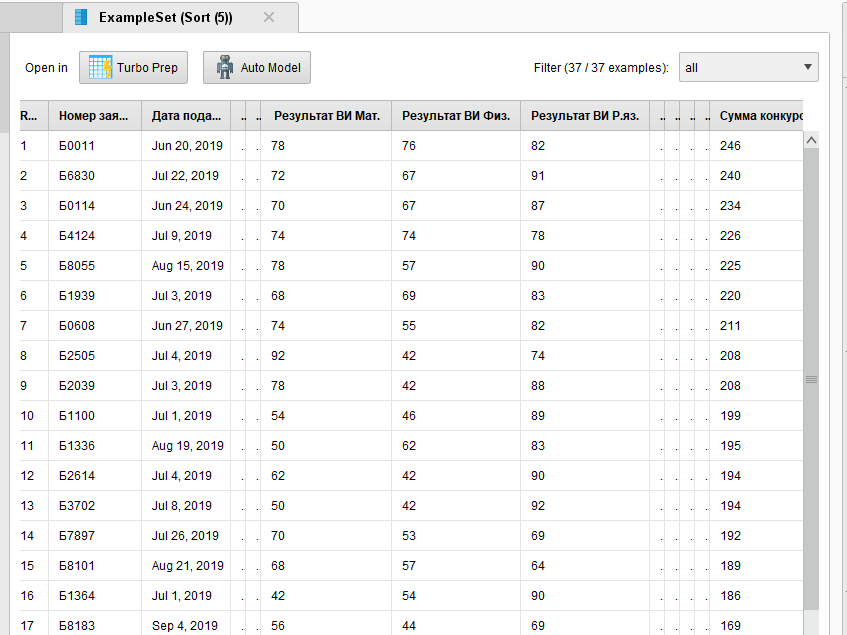 Рисунок
13 - Результаты ранжирования абитуриентов
Рисунок
13 - Результаты ранжирования абитуриентов
Графическое представление на рисунке 14. Сохраним созданный процесс как Лабораторная работа 2-Ранжирование.
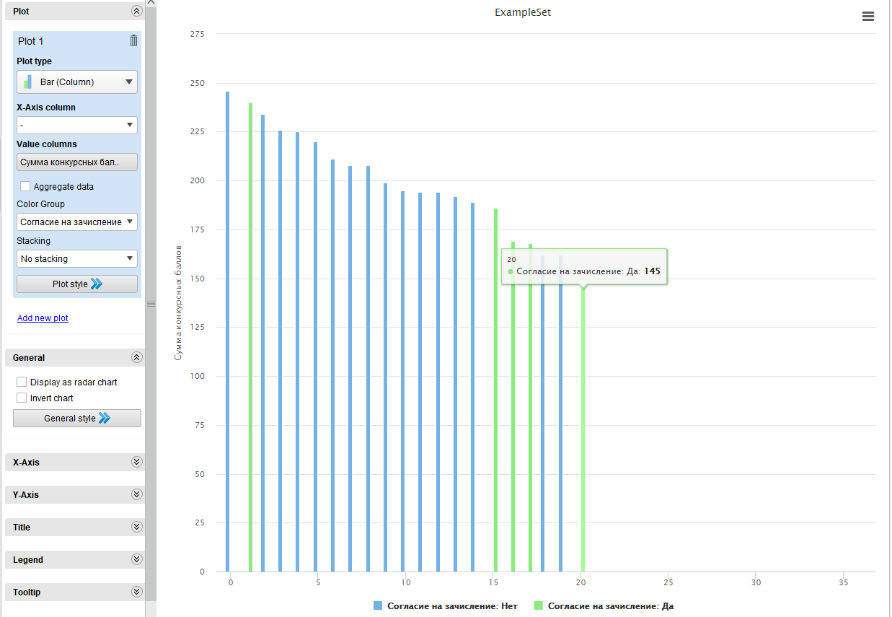 Рисунок
14 - Графическое представление результатов
ранжирования
Рисунок
14 - Графическое представление результатов
ранжирования
Исходными данными для выполнения лабораторной работы является подготовленная и помещенная в репозиторий таблица данных.
Возьмем таблицу из лабораторной работы №1 (рисунок 15).
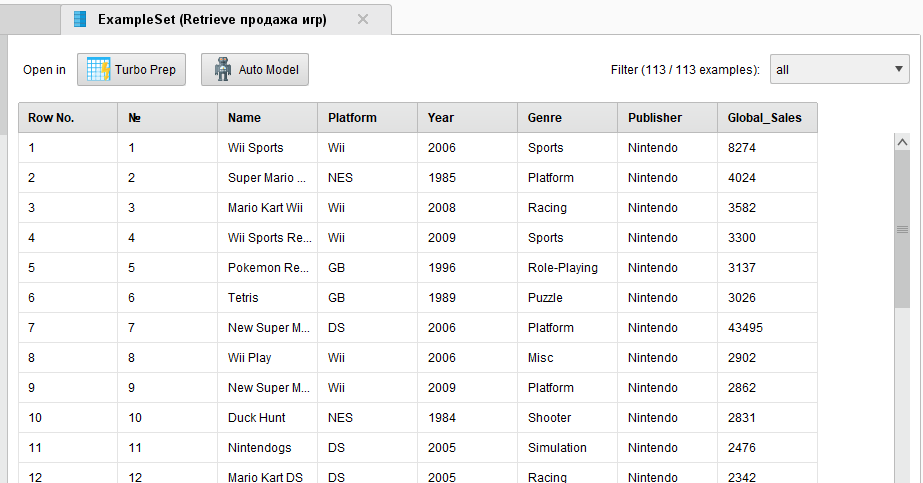 Рисунок
15 - Помещенная в репозиторий таблица
Рисунок
15 - Помещенная в репозиторий таблица
Поместим в рабочее поле нашу таблицу и убедимся, что, если подвести курсор к выходу Out можно просмотреть атрибуты импортированной таблицы с данными.
Удалим из дальнейшего рассмотрения колонку №. Перейдем во вкладку Operators и изучим ее содержимое. Перейдем в папку Blending (Смешенные) и там найдем папку Attributes. Поскольку требуется удалить из таблицы колонку, воспользуемся оператором SelectAttributes.
Удалим соединение выхода Out папки с точкой Res. Перетащим мышкой оператор SelectAttributes на рабочее поле и соединим выход Out папки с входом exa оператора, а его выход exa с точкой Res на рабочем поле. Сделаем активным оператором SelectAttributes щелкнув по нему мышкой так, чтобы он выделился красным цветом (рисунок 16).
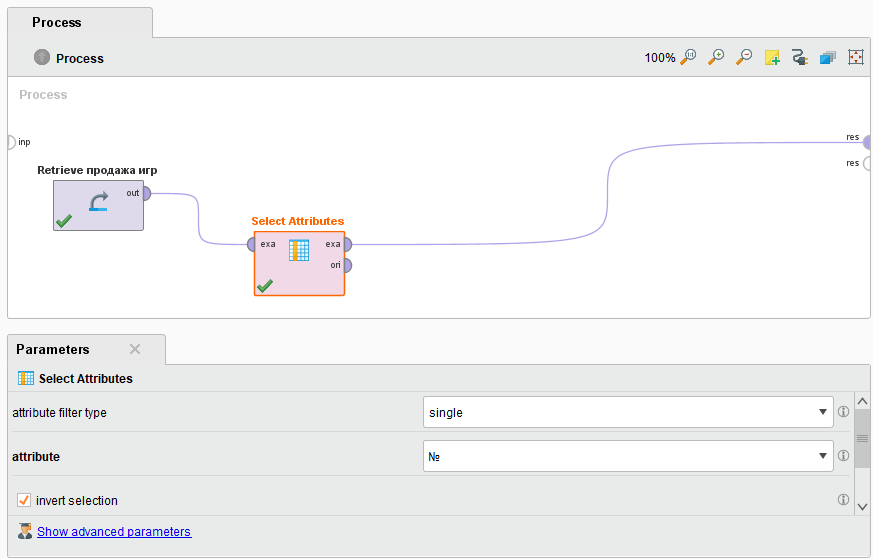 Рисунок
16 - Настройка параметров блока
SelectAttributes
Рисунок
16 - Настройка параметров блока
SelectAttributes
Запустим голубым треугольником процесс на выполнение и убедимся в том, что колонка № в итоговой выдаче отсутствует (рисунок 17). С помощью команды File/ SaveProcessAs сохраним полученные результаты в репозитории под именем Продажа игр - Удаление колонки.
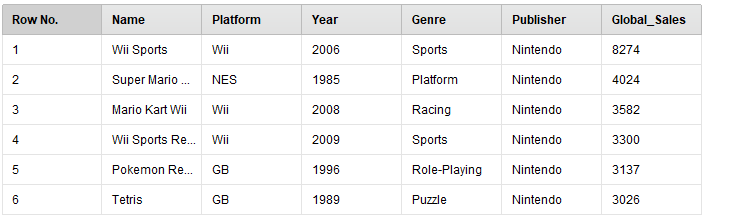 Рисунок
17 - Результаты удаления колонки № из
обрабатываемого набора данных
Рисунок
17 - Результаты удаления колонки № из
обрабатываемого набора данных
Продолжим работу с набором данных и решим задачу его сортировки.
Командой File / OpenProcess загрузим во вкладку Process ранее сохраненный процесс Лабораторная работа 2 - Удаление колонки. Удалим последнюю связь и перетащим мышкой на рабочее поле оператор Sort. Выполним необходимые соединения входов и выходов, сделаем оператор Sort активным и произведем настройку его параметров. Так в окне attributename установим поле сортировки Возраст, а в окне sortingdirection направление сортировки increasing (рисунок 18).
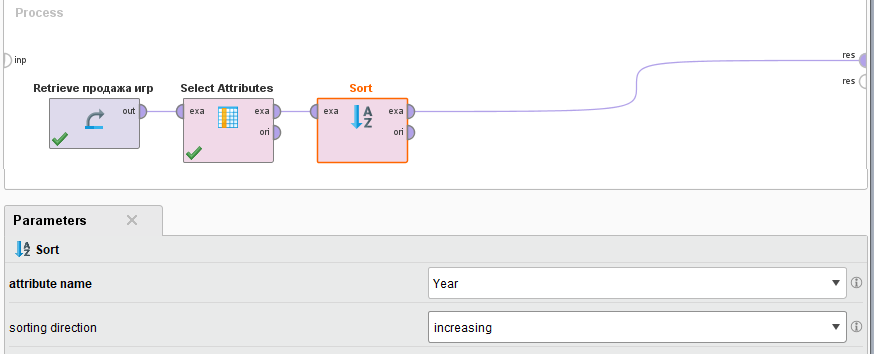 Рисунок
18 - Настройка режима сортировки
Рисунок
18 - Настройка режима сортировки
Выполним процесс и получим результаты сортировки (рисунок 19).
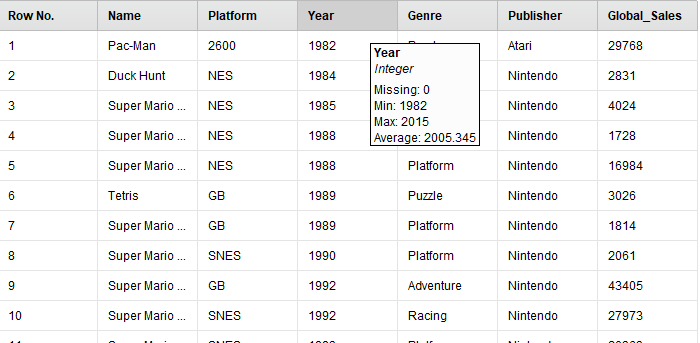 Рисунок
19 - Результаты сортировки списка игр
Рисунок
19 - Результаты сортировки списка игр
Воспользуемся возможностями системы визуализации и построим гистограмму отображения частоты выхода игр по годам (рисунок 20). Сохраним созданный процесс как Продажа игр - Сортировка.
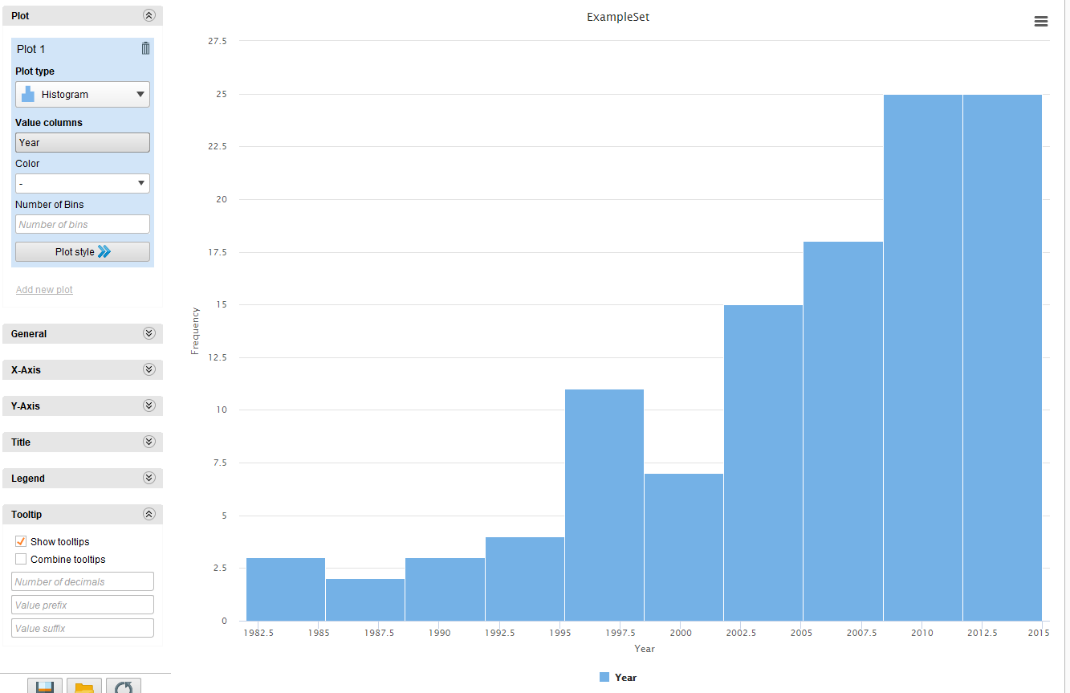 Рисунок
20 - Отображение результатов сортировки
в режиме Visualization
Рисунок
20 - Отображение результатов сортировки
в режиме Visualization
Загрузим ранее сохраненный процесс и добавим последовательно оператор фильтр сделав его активным.
На вкладке Parameters в окне conditionclass зададим значение customfilters. Нажмем кнопку AddFilters и начнем его настройку. Будем выбирать только игры с 2010 года, вышедшие на платформу PS3 (рисунок 21).
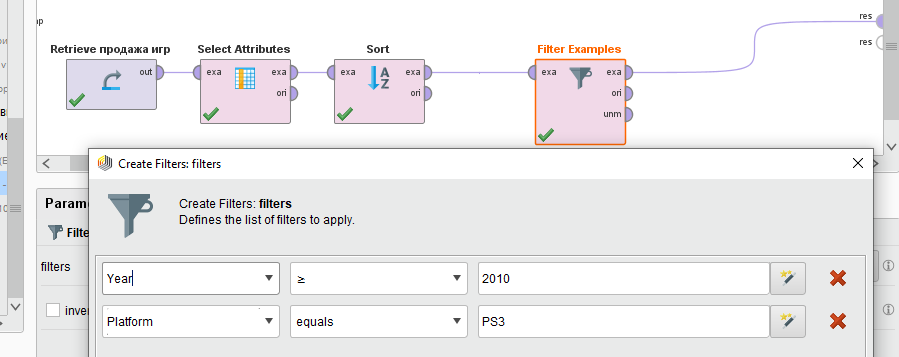 Рисунок
21 - Параметры
Рисунок
21 - Параметры
В результате осталось 9 игр (рисунок 22).
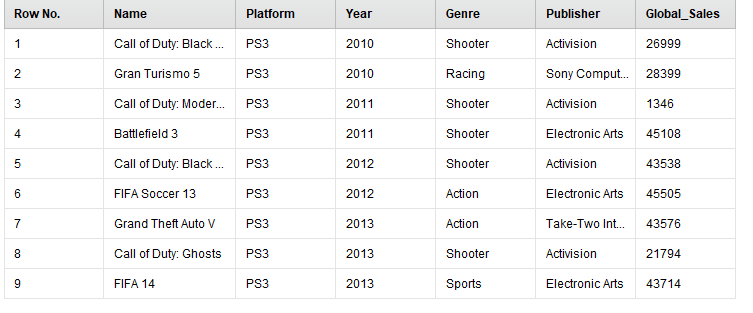 Рисунок
22 - Результаты фильтрации
Рисунок
22 - Результаты фильтрации
Сохраним созданный процесс как Продажа игр - Фильтрация.
Далее необходимо провести упорядочение данных в соответствии с изложенными выше требованиями. Я решил, что будет достаточно провести еще 2 сортировки. Для первого оператора attributename устанавливается в положение global_sales, а ключ sortingdirection в положение decreasing. Для второго оператора attributename устанавливается в положениеGenre, а ключ sortingdirection в положение decreasing. Результаты компановки процесса показаны на рисунке 23.
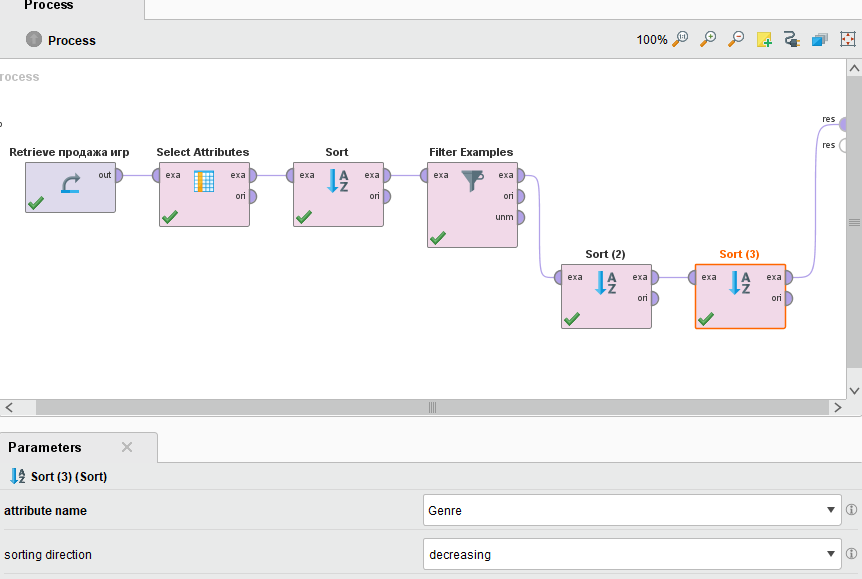 Рисунок
23 - Программирование ранжирования продаж
игр
Рисунок
23 - Программирование ранжирования продаж
игр
Его выполнение на рисунке 24.
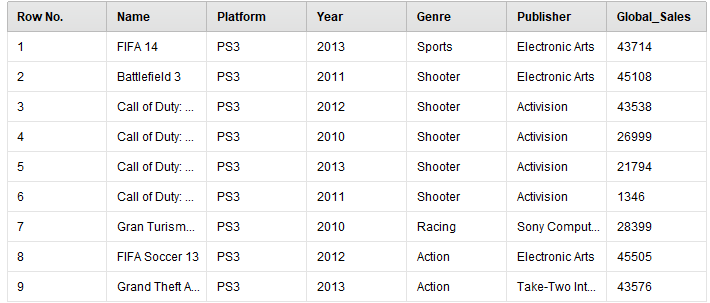 Рисунок
24 - Результаты ранжирования студентов
Рисунок
24 - Результаты ранжирования студентов
Графическое представление на рисунке 25. Сохраним созданный процесс как Продажа игр - Ранжирование.
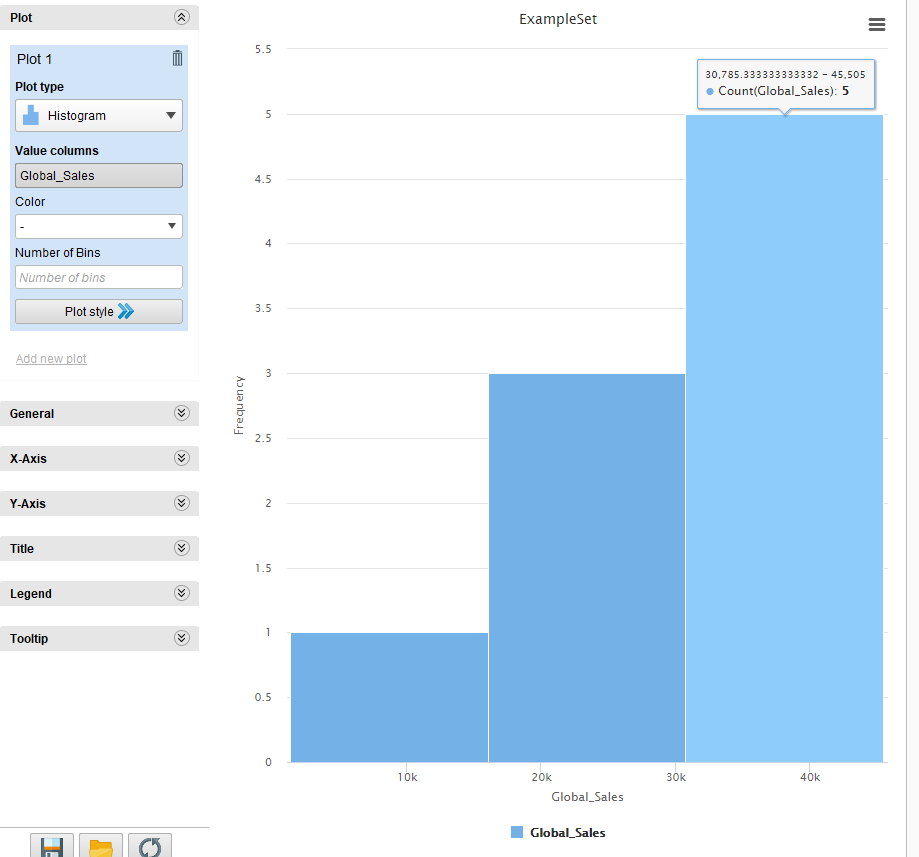 Рисунок
25 - Графическое представление результатов
ранжирования
Рисунок
25 - Графическое представление результатов
ранжирования
Контрольные вопросы
Из каких разделов состоит пошаговое руководство по продукту?
• Начало (Get started)
• Подготовка данных (Prepare data)
• Построение модели (Build a model)
• Сотрудничество и масштабирование (Collaborate and scale)
• Использование Hadoop (Use Hadoop)
Как можно найти интересующий вас оператор RapidMiner?
Чтобы найти интересующий оператор в RapidMiner, можно использовать справочник операторов, который предоставляет подробные описания всех доступных операторов. Кроме того, можно использовать функцию поиска в RapidMiner Studio.
Как можно узнать назначение входов и выходов оператора?
Чтобы узнать назначение входов и выходов оператора в RapidMiner, можно обратиться к документации оператора. Она содержит информацию о входах, выходах и параметрах каждого оператора.
Как программируются операторы?
Операторы в RapidMiner программируются путем создания собственного класса оператора. Можно использовать расширения для создания своих собственных операторов. Также существуют “супероператоры”, которые содержат один или несколько подпроцессов. Чтобы воспользоваться оператором необходимо нажать на него и перенести в рабочую область процесса, а далее во вкладке параметры уже происходит выбор и задание тех или иных параметров.
Каково назначение режима визуализации результатов?
Режим визуализации результатов в RapidMiner позволяет визуализировать и интерпретировать результаты вашего анализа данных. Это помогает быстро и эффективно передавать сложные данные и информацию, обнаруживать новые тренды и шаблоны, которые могли бы остаться незамеченными в сырых данных.
Какие возможности графического представления данных?
RapidMiner предлагает множество возможностей для графического представления данных. Можно быстро создавать различные виды диаграмм, такие как столбчатые диаграммы или круговые диаграммы. Данные могут быть представлены в легко читаемом и интерактивном формате, часто в виде графика, диаграммы или карты.
Как реализована задача фильтрации в RapidMiner?
Задача фильтрации в RapidMiner реализована с помощью оператора "Filter Examples". Этот оператор позволяет выбирать примеры из набора примеров, которые соответствуют заданному условию. Условия определяются пользователем, также существуют некоторые предопределенные условия.
Как реализована задача сортировки в RapidMiner?
Задача сортировки в RapidMiner реализована с помощью оператора "Sort". Этот оператор сортирует набор данных в порядке возрастания или убывания в соответствии с несколькими атрибутами. Атрибуты для сортировки указываются с помощью параметра “sort_by”. Для каждого атрибута сортировка выполняется в порядке возрастания или убывания, в зависимости от настройки параметра “sorting order”.
Как можно удалить столбец данных?
Чтобы удалить столбец данных в RapidMiner, можно использовать оператор “Select Attributes”. Нужно выбрать один тип атрибута и выберать атрибут (столбец), который надо удалить, затем отметить "invert selection".
Как можно реализовать сортировку данных в таблице по нескольким параметрам?
Чтобы реализовать сортировку данных в таблице по нескольким параметрам в RapidMiner, можно использовать оператор “Sort” с несколькими атрибутами. Если указано несколько атрибутов, набор данных сортируется по первому атрибуту, затем подмножества одного и того же значения в первом атрибуте сортируются по второму атрибуту и т.д.
Вывод
Я ознакомился со структурой и содержанием пошагового руководства по продукту RapidMiner. Это помогло мне лучше понять, как использовать различные функции и инструменты в RapidMiner. Я научился находить соответствующий раздел руководства и пользоваться им в процессе работы.
Также я обеспечил себя автоматизированными средствами перевода с английского языка на русский, что позволило мне лучше понять документацию и руководства по RapidMiner.
Затем я выделил группы задач на программирование процесса применительно к собственной таблице данных. Я решил задачи удаления, переименования и дополнения столбцов, сортировки, фильтрации, замены пропущенных значений и другие в соответствии со смыслом обрабатываемых собственных данных. Это было полезно для понимания, как данные могут быть подготовлены для последующего анализа.
В целом, эта лабораторная работа была очень полезной и образовательной. Я получил ценный опыт работы с RapidMiner Studio и с жду возможности применить эти навыки в будущих проектах по анализу данных.