

Дополнительное задание
Объединяются таблицы df_new и labels, которая берется из метода KMEANS. Выводится объединенная таблица. Результат на рисунке 17.
Рисунок 17 – Объединенный датафрейм
Составляется сводная таблица со средними показателями по каждому кластеру. Результат на рисунке 18.
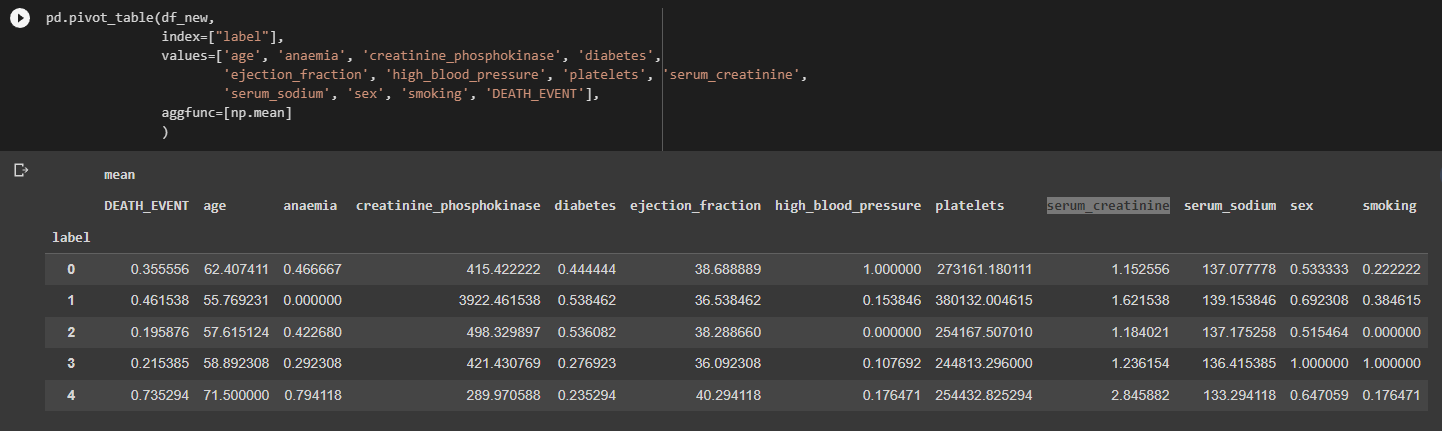
Рисунок 18 – Сводная таблица по кластерам
Проанализировав сводную таблицу можно сделать следующие выводы по каждому кластеру:
1) В первом кластере средний возраст пациента - 62 года, куда входят и мужчины и женщины, чаще всего не курят, самый низкий уровень creatinine_phosphokinase и serum_creatinine, остальные медицинские показатели средние относительно других, выживаемость - 35%;
2) Во втором кластере средний возраст пациента - 55 года, куда входят в большинстве своем мужчины, большинство не курят, самый низкий уровень anaemia, serum_sodium и platelets, остальные медицинские показатели средние относительно других, выживаемость - 46%;
3) В третьем кластере средний возраст пациента - 57 года, куда входят и мужчины и женщины, никто не курит, самый низкий уровень high_blood_pressure и serum_creatinine, остальные медицинские показатели средние относительно других, выживаемость - 19% - лучший результат;
4) В четвертом кластере средний возраст пациента - 58 года, куда входят только мужчины, все курят, самый низкий уровень platelets, остальные медицинские показатели средние относительно других, выживаемость - 21% - удивительно для курящей группы;
5) В пятом кластере средний возраст пациента - 71 года, куда входят в большинстве своем мужчины, мало людей курят, самый высокий уровень anaemia, ejection_fraction и serum_creatinine, остальные медицинские показатели средние относительно других, выживаемость - 21% - ожидаемо для престарелого возраста.
Ссылка на Jupyter Notebook:
https://colab.research.google.com/drive/1Pvf1KyI0dy1uBnFdY4OUEXwJePn-FOjy#scrollTo=oUtpDXJOYlcq
Вывод
В ходе выполнения работы я познакомился с методами кластериазции:
1) Методом K-Means, где в представлении гистограмм можно было увидеть, как сильно определенные признаки влияют на кластеризацию датасета. Самыми влиятельными признаками оказались serum_creatine и age.
2) иерархически агломеративным методом, где с помощью формирования дендрограммы можно было увидеть разделенные кластеры.
С помощью метрики силуэта можно было подсчитать, какое количество кластеров оптимально, но он отличается от количества кластеров, заданных в ходе указанных выше методов. Согласно теореме невозможности Клейнберга оптимального алгоритма кластеризации не существует, что и было продемонстрировано в ходе работы.
В ходе дополнительного задания была составлена сводная таблица, которая отражает средние показатели таблицы по кластерам, проанализировано содержимое сводной таблицы.
В ходе работы проблем не возникло.