

ГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
Ассистент |
|
|
|
В.В. Боженко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №2 |
АНАЛИЗ СВЯЗЕЙ МЕЖДУ ПРИЗНАКАМИ ДВУМЕРНОГО НАБОРА ДАННЫХ |
по курсу: ВВЕДЕНИЕ В АНАЛИЗ ДАННЫХ |
|
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
4016 |
|
|
|
М.О. Жовтяк |
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2022
Цель работы
Цель: осуществить предварительную обработку данных csv-файла, выявить и устранить проблемы в этих данных.
Вариант задания
Вариант 14. Так как преподаватель выдал только 10 вариантов, то будет выполняться 4 вариант работы.
Файл – 4liver.csv
Датасет заболеваемости печенью.
Столбцы:
1. Возраст пациента
2. Пол пациента
3. Общий билирубин
4. Прямой билирубин
5. Щелочная фосфатаза
6. Аламиноаминотрансфераза
7. Аспартатаминотрансфераза
8. Всего белков
9. Альбумин
10.Соотношение альбуминов и глобулинов
11.Цель: поле, используемое для разделения
данных на два набора (пациент с заболеванием
печени или без заболевания).
Предварительный анализ данных
Загружается датасет с помощью библиотеки pandas в Jupyter-ноутбук, использую Google Colab. Результат на рисунке 1.

Рисунок 1 – Загрузка датасета
Выполняется загрузка библиотек, настройка csv-файла. Выводятся первые 20 строк с помощью команды head(). Результат работы можно увидеть на рисунке 2.

Рисунок 2 – Вывод таблицы
Датасет содержит информацию о заболеваемости печенью, а конкретно содержит столбцы:
Возраст пациента
Пол пациента
Общий билирубин
Прямой билирубин
Щелочная фосфатаза
Аламиноаминотрансфераза
Аспартатаминотрансфераза
Всего белков
Альбумин
Соотношение альбуминов и глобулинов
Болезнь (1 – да, 2 – нет)
С помощью команды info() оцениваются столбцы датасета. Результат на рисунке 3.

Рисунок 3 – Информация о датасете
Проанализировав данные, можно сделать следующие выводы:
Всего 587 объектов, но существуют строки, где данные заполнены не полностью;
Aspartate_Aminotransferase, Alamine_Aminotransferase и Dataset123 столбцы должны иметь типы float, float и int соответственно;
Dataset123 столбец имеет неверное название;
Не исключено, что есть значения, которые отличаются от верных для этого выполняется проверка.
Выполняется команда для просмотра столбцов df.columns. Результат на рисунке 4.

Рисунок 4 – Информация о столбцах датасета
С помощью команды df.rename переименовывается Dataset123 столбец, так как такой заголовок не несет никакого смысла.

Рисунок 5 – Переименование столбца
Так как речь идет о данных болезни человека, то без полного набора данных невозможно поставить диагноз, поэтому строка пациента будет полностью удаляться. Так как максимум удалится всего 4 строки исходя из информации о столбцах, то такое удаление также допустимо. Выполняется проверка и удаление пропущенных значений с помощью команды print(df.isna().sum()). Результат на рисунке 6.
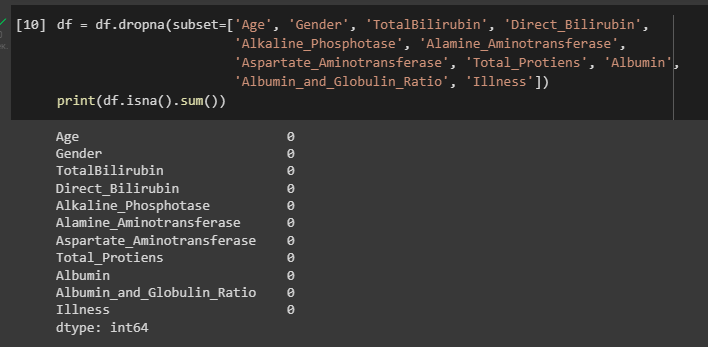
Рисунок 6 – Удаление строк с пропущенными значениями
В датасете выполняется поиск неявных дубликатов. Они ищутся в строке, где строковые значения могут быть написаны с ошибкой, таких так Gender и Illness, в которых могут находится только два значения: Female и Male; 1 и 2 соответственно. После того, как такие ошибки найдены, они исправляются методом replace(). Результат на рисунке 7.

Рисунок 7 – Исправление неявных дубликатов
В датасете удаляются дубликаты данных с помощью команды drop_duplicates(), так как необходимы только уникальные значения. После этого выполняется обновления индексации с помощью команды drop_duplicates().reset_index(), чтобы не существовало пустых строк. После этого выполняется проверка датасета на дубликаты с помощью команды duplicated().sum(). Результат на рисунке 8.

Рисунок 8 – Удаление дубликатов
Alamine_Aminotransferase, Aspartate_Aminotransferase столбцы должны иметь типы float, так как все измерения в датасете представлены именно в этом формате. Illness столбец даёт информацию о том, болеет ли человек (1 - да, 2 - нет). Тогда логично перевести этот столбец в тип int. Aspartate_Aminotransferase столбец - строкое значение, поэтому во время перевода некорректные значения будут заменяться на Null, а такие пустые строки будут удаляться. Результат на рисунке 9.
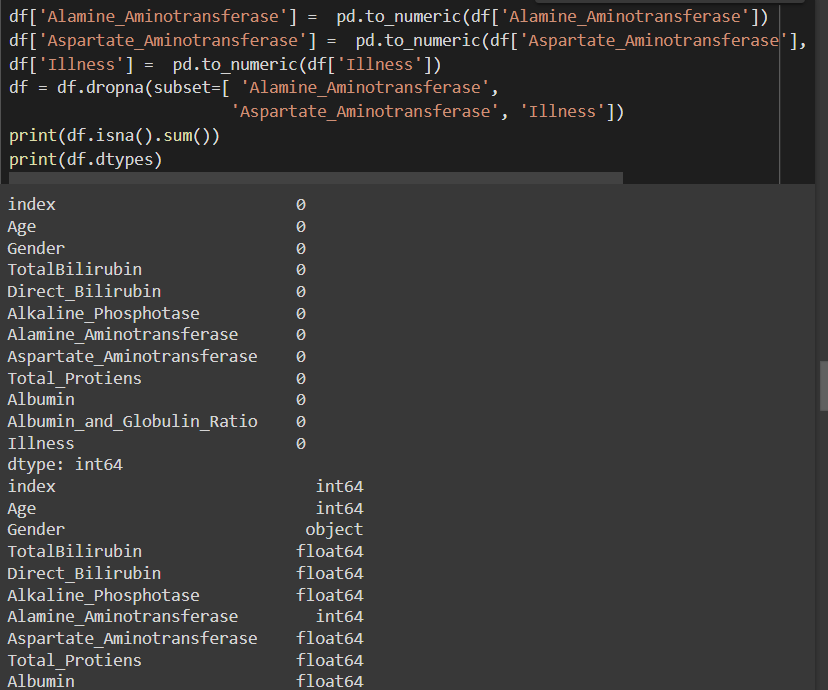
Рисунок 9 – Изменение типов данных столбцов