

Лекція 1. Компютерна мережа як розподілена комп’ютерна система. Визначення, структура та функції мережевої ОС
Комп’ютерні мережі виникли та розвинулися на стику двох галузей техніки – телекомунікацій та комп’ютерно-інформаційних систем. Відповідно до цього їх можна розглядати з двох різних перспектив – як систему, що забезпечує передавання даних між прикладними процесами, або як розподілену комп’ютерно- інформаційну систему. На початку розвитку мереж головна увага приділялася першій перспективі, що зрозуміло, адже організувати надійний обмін даними є необхідною передумовою функціювання комп’ютерної мережі і це завдання треба вирішити першим. Хоча і на цьому етапі погляд на мережу як розподілений комп’ютер проголошувався окремими науковцями. (Досить згадати девіз фірми Sun Microsystems1 – The network is the computer – Мережа це комп’ютер). На сьогодні перспектива розгляду комп’ютерної мережі як єдиного розподіленого комп’ютера виходить на перший план завдяки розвитку хмарних та грід-технологій, віртуалізації збереження та опрацювання даних. У цій частині будуть розглянуті системні, апаратні та програмні рішення, що реалізують функції комп’ютерної мережі як єдиної комп’ютерно- інформаційної системи.
1.1. Визначення та функції мережевої ОС
Центральне місце в організації роботи окремого комп’ютера займає його операційна система (ОС). Ця система функціонально знаходиться між прикладними програмами (застосуваннями) та апаратними засобами комп’ютера (рис. 6.1).
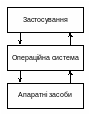
Рис. 6.1. Місце операційної системи у комп’ютерній системі
Таким чином, операційна система – це комплекс програм, що виконує інтерфейсні функції між застосуваннями та апаратною частиною комп’ютера та виконує дві групи функцій:
надання користувачу та прикладним програмам замість реальної апаратури комп’ютера певної віртуальної машини, з якою легше працювати і яку легше програмувати;
ефективне керування ресурсами комп’ютера.
Функціональні компоненти локальної ОС:
керування процесами;
керування пам’яттю;
керування файлами та зовнішніми пристроями;
захист даних та адміністрування;
підтримка API;
підтримка користувацького інтерфейсу.
Визначимо поняття мережевої операційної системи по аналогії з локальною ОС. Мережева ОС надає користувачам мережі певну віртуальну машину, яка приховує складність реальних апаратно-програмних вирішень розподіленої комп’ютерно – інформаційної системи та забезпечує ефективне використання її ресурсів. Аналогічно до локальної ОС мережева ОС також реалізує ефективне керування обчислювальними процесами, збереженням даних, реалізує функції адміністрування та захисту даних. Складність реалізації такої ОС полягає у складності координації використання ресурсів, розподілених на багатьох комп’ютерах мережі, які, як правило належать різним власникам.
На відміну від локальної ОС, функції мережевої реалізуються в результаті роботи великої кількості мережевих сервісів, апаратно-програмних та системних рішень розгорнутих у мережі.
Сьогоднішні системи ще не в змозі повністю реалізувати парадигму мережі як єдиного розподіленого комп’ютера і приховати деталі реалізації мережі, такі як, наприклад, адреси URL серверів. Але загальна тенденція розвитку комп’ютерних мереж полягає у подальшій віртуалізації використання мережевих ресурсів.
1.2. Принципи організації та роботи ОС комп’ютерної мережі
Комп’ютери мережі відповідно до функцій та ресурсів, які вони виділяють для загального користування, поділяють на такі.
Сервери - це комп’ютери, які надають свої ресурси для загального користування абонентам мережі. Кажуть, що сервери надають певні послуги (сервіси) клієнтам. Залежно від типу виділеного ресурсу розрізняють файловий сервіс, сервіс друкування, модемний сервіс, сервіс часу та ін. Один сервер може надавати декілька різних сервісів. Залежно від призначення є файл-сервери, сервери друкування, модем-сервери та ін. Файл-сервери виділяють свій дисковий простір і файли для загального користування та керують цим процесом. Сервери друкування керують друкуванням на мережевому друкувальному пристрої, на який надходять завдання зі всієї мережі. Сервери бувають призначеними (dedicated) та непризначеними (non dedicated). Призначені сервери займаються тільки організацією обслуговування запитів, що надходять з мережі, а непризначені, крім того, працюють зі своєю прикладною програмою і користувачем. Непризначений сервер менш надійний: прикладна програма користувача на ньому може призвести до його ‘зависання’. Через це сервер припинить роботу всієї мережі.
Робочі станції - це комп’ютери, що використовують ресурси, надані серверами, однак своїх ресурсів для користування не виділяють.
Залежно вiд набору класифiкацiйних ознак операційні системи та побудованi на їхній основi комп’ютерні мережі подiляють так.
За наявнiстю призначених серверiв:
одноранговi (peer to peer). Кожна робоча станцiя може одночасно бути сервером та робочою станцiєю. Такi системи гнучкiші. Вони особливо вигiднi для органiзацiї робочих груп (приблизно до 20 станцiй). Недолiки: складнiсть в адмiнiструваннi у великих мережах, менша надiйнiсть;
з окремими серверами. Для виконання серверних функцiй видiляють окремi машини. На них встановлюють системне програмне забезпечення, спроектоване спецiально для виконання серверних функцiй. Сервери можуть бути призначенi (напр. в Novell Netware) або непризначені (напр. MS Windows Server ).
За характером роботи:
тi, що працюють у режимi витiснення. Спецiальний диспетчер видiляє процесам кванти часу центрального процесора (UNIX, Windows);
тi, що не працюють у режимi витiснення. Процеси самi вiддають керування iншим процесам (Novell Netware2).
Операційна система мережі складається з серверних компонентів та компонентів операційної системи на робочих станціях. Спрощена схема роботи операційної системи показана на рис.6.2.
В основі операційних систем робочих станцій є проста програма переспрямування (redirector). Вона резидентно міститься в пам’яті комп’ютера. Коли користувач або його програма звертається з запитом до операційної системи комп’ютера, ця програма перехоплює запит та аналізує, хто його може виконати, і спрямовує або в ОС тієї ж машини, або на сервер, якому адресовано цей запит. Користувач не бачить, до яких ресурсів (своєї машини чи мережі) він звертається. Програма переспрямування зберігає інформацію про наявність серверів мережі і ставить у відповідність символічним посиланням (наприклад a: o: z: ) реальні ресурси локального комп’ютера або сервера у мережі.
Iдею переспрямування широко застосовують в архiтектурi сучасних мережевих ОС головно для збiльшення унiверсальностi їхнього застосування, наприклад, в органiзацiї багатопротокольностi. В сучасних ОС переспрямування здійснюється на багатьох архітектурних рівнях.
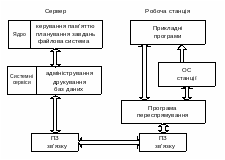
Рис.6.2. Структурна схема ОС мережі.
Операційна система сервера складніша. Вона виконує набір функцій, які умовно розділяють на базові, реалізовані в ядрі ОС (ядро – це головна програма ОС, яка резидентно міститься у пам’яті), та додаткові, що їх реалізують зовнішні щодо ядра програми. До функцій, які виконує ядро, як звичайно, належать:
керування пам’яттю;
планування заввдань та керування виконанням процесів;
підтримка файлових систем.
Додатковими функціями, наприклад, можуть бути такі:
адмістративні;
керування друкуванням;
мережеві функції.
Запити від робочих станцій виконуються спеціальними програмами - системними сервісами. Конкретний набір функцій сервера залежить від типу сервера та його конфігурації. Наприклад, для файл-сервера головними є функції файлової системи, планування завдань, керування пам’яттю та доступом до ресурсів. До появи ідеології файл-серверів кожний користувач прямо звертався до диска так званого диск-сервера. Оскільки вплив перешкод від одночасного звертання був значним, то така система не була надійною і не зберігала цілісність інформації. У файл-сервері запит спочатку потрапляє в ОС сервера, яка керує доступом усіх користувачів та дає змогу уникнути взаємних перешкод.
Порядок взаємодії клієнта та сервера в кожному випадку залежить від типу сервіса (та клієнта). Так, якщо звертаємося до файлу на файловому сервері, то він фактично передається на клієнт і там виконується. Якщо звертаються до файла на термінальному сервері, то програма виконується вже на сервері а на клієнт передаються тільки зображення екрану. При звертанні до сервера баз даних по мережі передається запит та певна кількість записів бази.
ОС сервера, застосовує деякі вбудовані в цю ОС функції, орієнтовані на колективне використання файлів, зокрема розширене відкривання файлів та їхнє фізичне блокування. Функція розширеного відкривання визначає, які права доступу можуть мати користувачі, а саме: читання, записування, читання/записування. Якщо файл потрібно змінити, то його відкривають з правом читання/записування та відміняють такі права для інших користувачів. Права зберігають аж до закриття файлу. Описане відкривання файлу називають неподільним (монопольним). Якщо файл треба читати, то його можна відкрити з правом читання та заборонити записування для інших. Файл можуть відкрити одночасно кілька користувачів, якщо їхні права не суперечать одне одному. Якщо два або більше користувачів одночасно хочуть змінити файл, то ОС використовує операцію блокування запису. Прикладні програми можуть блокувати конкретний запис: доки є блокування, всі спроби прочитати або записати блокований запис будуть відхилені.
Отже, однією з функцій ОС мережі є керування доступом до файлів, створення черг запитів та керування ними. Іноді реазують пріоритетний доступ до файлів. Концепцію сумісного використання файлів найзручніше описати на прикладі операцій з базами даних. Спеціальні операції керування колективним доступом до баз даних є практично у всіх СКБД. У деяких з них (Access, Foxpro, Oracle, Sybase) блокування записів відбувається автоматично, в інших це робить програміст.
1.3. Організація системи мережевого друкування
Сервер друкування - це комп’ютер, який виконує завдання для окремої групи користувачів з друкування матеріалів. Як звичайно, він керує одним або кількома принтерами. Подібно до файл-сервера, сервер друкування може бути призначеним та непризначеним.
Якщо якійсь робочій станції дано завдання роздрукувати документ, то вона звертається до принтера мережі за його символічним іменем (до робочої станції можна приєднати і локальний принтер, однак він повинен мати інше ім’я). Програма переспрямування, в якій зберігається інформація про ресурси мережі, надсилає запит на сервер друкування. Якщо принтер вільний, сервер відразу спрямовує завдання в буфер друкування - частину оперативної пам’яті прінтера, використовувану для скерування завдань на друкування з заданою швидкістю (рис.6.3).
Якщо прінтер зайнятий, то завдання буде записане на диск сервера друкування і чекатиме своєї черги. Програмне забезпечення сервера друкування може керувати чергою, присвоювати завданням пріоритети, групувати за форматами документів та ін. Якщо буфер друкування частково звільняється, до нього надходять завдання з диска. Такий процес називають спулінгом (spooling), а відповідний програмно-апаратний механізм - спулом друкування.
1.4. Забезпечення єдиного мережевого часу
Для успішної роботи мережі в ній повинен бути заданий єдиний час. Найчастіше клієнтські станції під час приєднання до мережі узгоджують свій годинник з годинником сервера. Це виконується в системах, де потрібний узгоджений час (проте не обов’язково точний) а також у невеликих мережах.
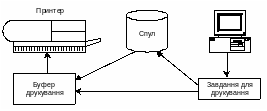
Рис. 6.3. Робота сервера друкування.
У деяких застосуваннях треба простежувати час подій з точністю до мілісекунд. Власне для цього і призначений протокол NTP (Network Time Protocol, RFC-1305), який дає змогу також побудувати ієрархічну схему узгодження часу в довільній мережі.
Архітектура системи узгодження часу з використанням NTP має ієрархічну будову. На верхньому рівні ієрархії є джерело точного часу (як звичайно, UTC (Universal Coordinated Time) – час за Грінвічем). Таким джерелом може бути годинник-еталон, еталонні радіосигнали точного часу та ін. Здебільшого це джерело не є комп’ютером. Сервери часу залежно від ієрархічної віддаленості від джерела поділяють на рівні.
Сервери першого рівня безпосередньо узгоджують час з джерелом часу. Сервери другого рівня узгоджують свій годинник з серверами першого і т.д. Отже, чим більший номер рівня, тим менша точність ходу годинника.
Протокол NTP забезпечує такі режими синхронізації:
клієнт-серверний – використовують у невеликих мережах з кількістю станцій не більше 200;
груповий (multicast) – використовується в більших мережах;
циркулярний – можна використовувати в межах локальної мережі.
Протокол NTP підтримують такі ОС: Windows, Novell Netware, Linux. Демон ntpd працює як окремий процес сервера часу, виконує автентифікацію, веде протокол подій, обмежує доступ по діапазону IP-адрес.
1.5. Апаратно – програмні рішення розподілених комп’ютерних систем
У цьому розділу буде зроблено огляд апаратних, програмних та системних вирішень, які застосовуються у розподілених комп’ютерних системах для підвищення продуктивності, надійності, захищеності та які підтримуються і реалізуються мережевою ОС.
Комп’ютер сервера посідає особливе місце серед інших комп’ютерів мережі. Він повинен мати більші ємності для зберігання даних, більші швидкодію та оперативну пам’ять. Критичним моментом у роботі, наприклад, файл-сервера, є його здатність швидко відшукувати дані та видавати їх без помітної затримки на робочу станцію. На продуктивність файл-сервера впливають багато факторів: швидкість роботи інтерфейсної плати, тип мережі, ємність доступної оперативної пам’яті, параметри твердого диска. Найважливішим параметром такого сервера є час доступу до даних. Він складається з часу шукання (радіального переміщення головок) та часу обертання (часу, потрібного для підходу потрібного сектора).
Збільшити продуктивність сервера та надійність зберігання даних можна за допомогою різних апаратних та програмних вирішень, які можна розділити на групи за окремими видами ресурсів та підсистемами комп’ютера.
Підсистема збереження та доступу до даних
Ємність сучасних жорстких дисків сягає десятків терабайт, а час доступу до кращих з них – декілька мілісекунд. Жорсткі диски (HDD – Hard Disk Drive) залишаються найбільш економічно вигідними пристроями для збереження даних. Твердотільні диски (SSD – Solid State Drive) мають більшу надійність та час служби, менший час доступу до даних порівняно з жорсткими дисками. Ємності SSD дисків постійно зростають (16 ТВ для промислових дисків). Час доступу до даних в найкращих SSD порядку 0,1 мс.
Розглянемо типові вирішення, які застосовують для підвищення ефективності використання підсистеми збереження даних.
Використання дискового співпроцесора.
Спеціальний дисковий співпроцесор керує зчитуванням та записуванням інформації на диск. Отже, розвантажується центральний процесор, збільшуються продуктивність та вартість системи.
Дублювання дисків (disc mirroring).
Поряд з одним встановлюють інший ідентичний твердий диск, який в оперативному режимі дублює роботу попереднього. Якщо один вийшов з ладу, робота сервера не припиняється.
Ліфтове шукання (elevator seeking).
Ліфтове переміщення головок дисковода - це процедура, що дає змогу поліпшити записування та зчитування даних з диска. Запити, які надходять, накопичуються протягом деякого часу. Після цього оптимізується їхня черговість, щоб мінімізувати переміщення головок. Така процедура зменшує тривалість виконання запиту на 40%. Крім того, зменшується зношування диска.
RAID-масиви та мережі систем зберігання даних.
У сучасних серверах для збільшення гнучкості та обсягів інформації часто використовують масиви твердих дисків. В RAID- масивах вводиться надлишковість у збереження даних. З рахунок цього з’являється можливість виявляти та виправляти помилки у даних.
Якщо дискових масивів багато, їх об’єднують окремими мережами зберігання даних SAN (Storage Area Networking). Це дає змогу ефективно виконувати операції менеджменту даних та підтримки функціювання масивів.
Зовнішні бібліотеки зберігання даних.
У великих корпоративних мережах поряд з зовнішніми дисковими пристроями використовують і повільніші (зате значно ємніші) бібліотеки магнітних стрічок або оптичних дисків. Ці пристрої потрібні для резервного копіювання, а також для тимчасового переміщення на них файлів, які не застосовують, та автоматичного повернення їх назад у разі виникнення потреби (міграція та деміграція).
Хмаркові (cloud) системи збереження даних
Збереження даних користувача на віддаленому сервері дає змогу забезпечити краще збереження даних, автоматичну синхронізацію між усіма платформами з якими працює користувач.
Ефективне використання оперативної пам’яті
Важливим вирішенням, спрямованим на підвищення швидкодії системи є кешування, тобто використання швидкодіючої пам”яті замість повільної.
Кеш-пам’ять (cash memory).
На сервері розміщують спеціальну швидкодійну пам’ять, у яку заносять структуру каталогів та FAT-таблиці (апаратний кеш). Крім того, частину вільної оперативної пам’яті комп’ютера виділяють для зчитування/записування. Кожного разу зчитують не тільки визначений кластер диска, й кілька сусідніх (файли найчастіше містяться в сусідніх кластерах). У цьому випадку велика ймовірність того, що наступне зчитування можна буде виконати з пам’яті, а не з диска. Отже, тривалість доступу зменшиться.
Кешування файлів.
У процесі роботи система може аналізувати, які файли використовують найчастіше, та зберігати їх у пам’яті, а не на диску. Це разом з операцією ліфтового шукання підвищує ефективність застосування сервера в сотні разів.
Гешування каталогів (directory hashing).
Якщо каталоги в сервері дуже великі, то потрібен тривалий час на відшукання конкретного файлу за його іменем (необхідно переглянути всі імена попередніх файлів каталогу). У процесі гешування кожен запис каталогу перетворюється у 2-байтові значення, які зберігаються в спеціальних геш-таблицях. Шукання потрібного імені файлу зводиться до порівнянь числових значень з цих таблиць.
Індексування FAT та геш-таблиць.
Для прискореного шукання використовують індексування таблиць. У цьому випадку створюють та зберігають спеціальні індексні файли.
Використання твердотільних дисків та масивів оперативної пам’яті
Найповільнішими серверними компонентами є тверді диски. Для зменшення тривалості доступу замість цих дисків застосовують твердотільні диски SSD. Якщо треба забезпечити ще менший час доступу до даних, то використовують масиви оперативної пам’яті. Зокрема, до класу таких масивів належать пристрої MegaRam компанії Imperial Technology – це, по суті, набір блоків пам’яті. Параметри їхньої ємності сягають десятків гігабайтів. (наводиться цифра 38 Гбайт). Крім пам’яті, в цих пристроях є швидкодійні тверді диски, з яких інформація зчитується після запуску та після зупинки. Пристрій має вбудований UPS. У тестах MegaRAM 2000 виявив швидкість передавання даних та виконання трансакцій у 20 разів більшу, ніж масив твердих дисків.
Опрацювання даних - процесорна система
Мультипроцесорність.
Для збільшення швидкодії в сучасних серверах використовують багатоядерні процесори. Щораз частіше також використовують кілька (до кількох десятків) процесорів, які працюють у режимі розподілу пам’яті (Symmetrical Multiprocessing (SMP)), (Asymmetrical Multiprocessing (ASMP)). Як звичайно, у таких серверах можна виконати гарячу (без припинення роботи сервера) заміну окремих блоків.
Конструктиви серверних масивів
У центрах опрацювання даних працюють тисячі та десятки тисяч серверів. При їх експлуатації виникають додаткові проблеми енергозбереження, охолодження, раціонального використання простору. Ці проблеми значною мірою вирішуються конструкціями серверних масивів, наприклад – у blade серверах.
Кластерні вирішення.
Поряд з використанням багатопроцесорних комп’ютерів, окремі сервери об’єднують у кластери, які дають змогу розподіляти навантаження, передавати задачі з несправного сервера на інший сервер кластера.
Грід- комп’ютинг
Віртуалізація опрацювання даних у формі грід–комп’ютингу дає змогу ефективно використати наявні у мережі процесорні потужності та розподілити обчислення між багатьма вузлами. При цьому треба враховувати, що не всі класи задач придатні для паралельного виконання.
Підсистема живлення.
Дублювання блоків живлення.
Ця операція захищає сервер від можливої несправності блока, її використовують у серверних системах високої надійності поряд з дублюванням інших пристроїв.
Використання UPS та резервних джерел живлення.
Джерела безперебійого живлення застосовують (Uninterrupted Power Supply (UPS)) для живлення файл- серверів та інших пристроїв з цінною інформацією. Фірма Novell для своїх систем зазначає: «Будь-який файл – сервер та його тверді диски повинні бути приєднаними до апробованого Novelloм' джерела безперебійного живлення. Ми також рекомендуємо UPS захист робочих станцій».
Джерела безперебійного живлення виробництва різних фірм мають різну початкову потужність та сервіс. Потужність змінюється від 300-400 до 3000-5000 ВА. Чим більша потужність, тим більшу кількість комп’ютерів можна приєднати, і тим більший період роботи після відімкнення живлення. Джерела безперебійного живлення живляться з батарей і дають змогу комп’ютеру в разі вимкнення головного живлення працювати ще деякий період (від 15 хв до кількох годин). UPS стежать за формою струму живлення, коректують його, подають спеціальні попередження на комп’ютери, ведуть статистику стану живлення тощо. Вартість UPS може коливатися від 200- 300 для дешевих до 1000 – 3000 дол. для дорогих UPS. Найвідоміша фірма, яка виготовляє UPS, – це American Power Conversion (APC).
Питання до самоконтролю
1. Які функції в ком’ютерній мережі виконує мережева ОС?
2. Дайте визначення терміну “сервер”. Чим сервер відрізняється від робочої станціїт?
3. Що таке витісняюча ОС ?
4. Для чого використовуть механізм спулінгу у системі мережевого друкування ?
5. Як працює програма переспрямування ?
6. Функції ядра ОС.
7. В чому полягає та для чого використовується кешування ?
8. Що таке гешування та для чого воно використовується
Лекція 2. Віртуалізація збереження даних в комп’ютерних мережах
2.1. Методи збереження даних у пристроях комп’ютерної мережі
Найчастіше дані зберігають на жорстких дисках (HDD - hard disk drive) які є електромеханічними пристроями. В основі HDD є пластини, покриті феромагнітним матеріалом, що швидко обертаються. Дані на диск записують використовуючи зміни напряму орієнтації магнітних доменів. Інформація кодується по зміні орієнтації сусідніх магнітних доменів. Пластини виготовляють з немагнітних матеріалів (скло, алюміній) та покривають шаром феромагнітного матеріалу завтовшки 10 – 20 нм. (в 10 тис раз тоншим ніж товщина аркушу паперу). Зчитування/запис даних відбувається шляхом переміщення головки (актуатора) над поверхнею диску. Головка «пливе» над поверхнею пластини на відстань порядку 13 нм. Враховуючи масу головки, її швидкість руху та відстань до пластини, для ілюстрації прецизії її виготовлення та роботи цей процес часто порівнюють з рухом Боінгу 747, що летить зі швидкістю 3 млн. км/год на постійній висоті 0,25 мм над поверхею Землі. HDD має два двигуни – один для обертання, інший для переміщення головки диску.
Головні параметри HDD такі:
швидкість обертання пластин - від 4200 до 15000 обертів на хвилину.
ємність (макс. 10 Тб),
час доступу (5-20 мс).
форм-фактор: 8; 5,25; 3,5 (десктоп); 2,5 дюймові (ноутбук)
HDD були розроблені фірмою IBM в 1956 році (перший диск мав розмір як два холодильники, ємність 4 Мб на 50 пластинах). Головки зчитування висувалися при запуску диску. В 1973 році IBM розробила модифікацію HDD «Вінчестер», і якій головки при виключенні живлення паркувалися на визначене місце на самому диску. Це зменшило вартість диску. Перші вінчестера мали діаметр пластин 360 мм.
З бігом часу параметри жорстких дисків були значно покращені. Для них діє закон Крайдера (аналог закону Мура) який визначає, що густина збереження даних подвоюється у кожні 2-4 роки. Зокрема,
обсяги дисків зросли 4 Мб до 8 Тб,
об’єм зменшився від 1,9 м3 до 20 см3,
вага зменшилася від 910 кг. до 48 грам,
вартість впала від 15000 за мегабайт до 0,0001$ за мегабайт,
час доступу покращено з 100 мс. до 5 мс.
Сучасні диски використовують коректуючі коди (ECC) для виявлення та виправлення помилок. (коди Ріда-Соломона та ін) за рахунок використання надлишкових бітів. Це дозволяє збільшити густину запису. Контролер диску визначає збійні блоки диску та переспрямовує запис на інші, запасні блоки. SMART (Self-monitoring analysis and reporting technology system) веде облік збійних секторів і дозволяє передбачити аварію диску.
Жорсткі диски є механічними пристроями і як такі погано сприймають удари – існує можливість механічного пошкодження. З іншого боку, кількість операцій зчитування/ запису такого диску необмежена. Суттєвою перевагою є також можливість передбачити аварію диску по збільшенню кількості помилок і вчасно замінити його.
Альтернативою використання жорстких дисків на сьогодні є твердотільні диски (SSD – Solid State Disk). У них для збереження даних використовують мікросхеми.Таким чином, SSD не мають рухомих частин, вони надійніші ніж HDD та мають менший час доступу. Максимальна ємність промислових SSD на сьогодні – 16 TB, а мінімальний час доступу порядка 0,1 мс.
Таблиця 6.1. Порівняння характеристик HDD та SSD
Параметр |
HDD |
SSD |
Час запуску |
Декілька секунд до повної доступності |
Моментально |
Час доступу |
Від 5 мс до 12 мс |
Менше за 100 мкс |
Швидкість передачі даних |
Для послідовного доступу – до 140 МБ/с. На практиці набагато менша, так як потрібно врахувати час перемішення головок |
100- 600 МБ/с. |
Фрагментація |
Час доступу до даних можна зменшити, якщо періодично проводити дефрагментацію даних. |
Фрагментація не впливає на продуктивність |
Шум |
Рівень шуму значний та залежить від моделі диску |
Відсутній |
Час служби та надійність |
На час експлуатації впливають можливі механічні помилки. |
Обмежена кількість операцій запису. Загалом, час служби більший за HDD |
Вартість за ГБ |
Порядка $0,05 |
Порядка $0,65 |
Енергоспоживання |
Типове споживання дисків формату 2,5” – 5 Вт, 3,5” – 20 Вт |
Диски на базі флеш-пам’яті споживають від половини до третини енергії своїх HDD аналогів |
Недоліком SSD є те, що кожна комірка пам’яті у ньому має обмежену кількість операцій витирання та запису даних. Контролер диску намагається рівномірно розподілити зношення окремих комірок. Коли SSD виходить з ладу, це часто відбувається неочікувано. Поновити втрачені дані з SSD досить складно. Також, суттєвим недоліком SSD порівняно з HDD є обмежений час збереження даних, якщо диск не отримує живлення. Виробники визначають цей час трьома місяцями, але результати незалежних досліджень показують, що окремі типи SSD починають втрачати дані вже після тижня перебування у відключеному стані.
На сьогодняшній день для шин підключення жорстких дисків використовують такі архітектурні вирішення: SATA, SCSI.
Контролери SATA (Serial Advanced Attachment Interface) використовують AHSI (Advanced Host Controller Interface) інтерфейс доступу до інформації. Для роботи з диском SATA мусить бути наявна підтримка SATA материнською платою.
На фізичному рівні SATA використовує кабель що складається з чотирьох дротів. Використовується диференційне передавання з невеликою амплітудою сигнала. Дані кодуються та передаються з використанням кодування 8B/10B, що дозволяє сумістити синхросигнал та сигнал даних та виключає потребу в окремій лінії для синхросигналу.
Перша генерація SATA інтерфейсу (SATA- 150) мала швидкість передавання 1.5 Гбіт/с, що є порівняльним зі швидкістю роботи попереднього паралельного інтерфейсу (PATA). Новіша версія SATA (SATA-300) пропонує більшу швидкість передавання – до 3 Гбіт/с. Наступна, третя версія SATA-600 була розроблена у 2009 році та працює з швидкістю до 6 Гбіт/с. Наступні доробки цієї версії (3.1 – 2011 рік, 3.2 – 2013 рік) були орієнтовані на підтримку взаємодії з швидкими SSD. Швидкість передачі даних у них сягнула 16 Гбіт/с. У таблиці 6.2. наведено порівняння SATA та деяких споріднених технологій.
Таблиця 6.2. Порівняння SATA та деяких інших інтерфейсних мереж
Технологія |
Макс швидкість передавання, Мбіт/с |
Макс. Довжина кабелю, м |
Чи надається живлення по кабелю |
eSATA |
2400 |
2 |
Ні |
SATA-150 |
1200 |
1 |
Ні |
SATA-300 |
2400 |
1 |
Ні |
SATA-600, 3.2 |
19000 |
1 |
Ні |
PATA – 133 |
1064 |
0,46 |
Ні |
FireWire-800 |
786 |
4,5 |
Так |
USB 2.0 |
480 |
5 |
Так |
USB 3.0. |
5000 |
5 |
Так |
USB 3.1 |
10000 |
5 |
Так |
Ultra-320 SCSI |
2560 |
12 |
Ні |
Fiber Channel |
4000 |
1-50000 |
Ні |
Таким чином, на сьогодні інтерфейси специфікації SATA повністю забезпечують можливості пристроїв збереження даних (як HDD так і SSD) по зчитуванню та запису інформації.
2.2. Використання надлишковості для захисту даних - RAID та MAID масиви
Тверді диски – один з найпотрібніших і таких, що найінтенсивніше працюють компонентів сервера. У них наявні рухомі частини, тому такі диски швидко зношуються. З іншого боку, збереження інформації на диску є дешевшим. Вартість інформації може набагато перевищувати вартість твердого диска. Періодичне копіювання інформації частково захищає дані, однак втраченими можуть виявитися ще не скопійовані дані. Збільшити ступінь захищеності даних без припинення роботи системи можна за допомогою дискових масивів.
Дискові масиви RAID
У 1988 р в Каліфорнійському університеті Д. Паттерсон, Г. Гібсон, Р. Хац опублікували статтю ‘A Case for Redundant Arrays of Inexpensive Disks’ в якій сформулювали головні принципи та класифікацію RAID-дисків. Автори визначили п’ять категорій RAID, які є і сьогодні. Нові категорії RAID, що з’явилися пізніше переважно рекламні, маркетингові, у них використано незначні модифікації та комбінації рис базових класів.
Пізніше, коли RAID диски набули широкого поширення, маркетологи для кращого звучання замінили термін Inexpensive на Independent не зважаючи що при цьому втрачається відповідність назви до змісту технології.
Стандартизує RAID-масиви комісія радників з RAID (RAID Advisory Board -RAB). Сьогодні ця організація нараховує понад 50 членів. Вона розробляє проекти стандартів, тестові процедури, напрацьовує єдину технічну політику, а також популяризує ідеї RAID. Головні її документи: ‘The RAIDbook’ та короткий витяг з нього ‘RAIDprimer’.
Не кожний дисковий масив є масивом RAID. Наприклад, приєднавши декілька твердих дисків у комп’ютер через SCSI інтерфейс, ми отримаємо багатодискову систему. Однак збільшення надійності збереження інформації чи продуктивності не буде.
Як звичайно, дискові масиви приєднують з використанням SATA, SCSI або подібних інтерфейсів. Це пояснюють можливістю приєднання значної кількості дисків. Водночас ця архітектура сьогодні дещо застаріла. Перепускна здатність шини SCSI3 – 640 Мбіт/с. Ланцюжкове приєднання дисків цією шиною створює проблеми надійності. Альтернативою є використання каналу Fiber Channel, який надає швидкість передавання до 100 Мбіт/с у повнодуплексному режимі. Команди керування таким каналом відповідають командам SCSI 3.
Рівні RAID.
Рівень нуль
Першим кроком до RAID є перетворення групи дисків у віртуальний диск (striped array, disk striping). Операційна система сприймає масив дисків як один диск. Контролер масиву записує послідовні блоки файлу на різні диски по-черзі. Ємність такого віртуального диска буде дорівнювати сумі ємностей дисків. Завдяки паралельному виконанню операцій записування-зчитування можна зменшити період доступу до віртуального диска (пропорційно до кількості дисків). Проте надійність такої системи зменшиться (також пропорційно до кількості дисків). У разі виходу з ладу одного диска не працюватиме вся система. Тому віртуальні диски у чистому вигляді трапляються зрідка. Інколи його називають RAID рівня нуль. Переваги, недоліки та сфера використання масивів нульового рівня наведена у таблиці 6.3.
Таблиця 6.3. Переваги, недоліки та сфера використання масивів нульового рівня
Переваги |
Збільшення швидкодії. Простота реалізації |
Недоліки |
Зменшення надійності — досить вийти з ладу одному з дисків, і всі дані стають недоступними. Недопустиме застосування у критичних системах |
Сфера застосування |
Виробництво відео та графічної продукції, додрукарське опрацювання |
Рівень 1
Надійність дискового масиву можна збільшити, якщо організувати дзеркальне відображення: виконувати записування та зчитування одної й тої ж інформації з усіх дисків масиву одночасно. Один диск у цьому разі буде головним, первинним, інші – вторинними, дзеркальними. Якщо якийсь диск вийде з ладу, то користувач навіть не помітить цього, а адміністратор матиме змогу замінити його. Використання дзеркальних дисків збільшує надійність, однак вартість збереження інформації також значна. Дзеркальні масиви дисків визначені як RAID-масиви першого рівня. Переваги та недоліки масивів першого рівня наведені у таблиці 6.4.
Таблиця 6.4. Переваги, недоліки та сфера використання масивів першого рівня
Переваги |
Збільшення надійності Одночасно може відбуватися два різні читання або один запис на два диски. У випадку збою треба тільки зробити копію диску Проста конструкція |
Недоліки |
Неефективне використання дисків Якщо система реалізована програмно, то сильно завантажується процесор. Рекомендована апаратна реалізація |
Сфера застосування |
Бухгалтерія, зарплата, фінанси, довільна система, що вимагає високої готовності |
Рівень 2
Якщо RAID першого рівня працює з декількома копіями даних, то його вищі рівні – працюють з однією копією даних розподіленою між багатьма дисками та захищеною завадостійким кодом. Завдяки цьому диски можна використовувати ефективніше.
Другий рівень RAID забезпечує надлишковість з використанням коду Хемінга, який дає змогу виправити одиничні та виявити подвійні помилки. Дані розподілені між декількома дисками, а надлишкові контрольні дані записані на окремий диск. Система має високу надійність, проте складна і дорога. Наприклад, для чотирьох дисків з даними потрібно ще три диски для перевірної інформації. Основні переваги та недоліки RAID масивів другого рівня наведені у таблиці 6.5.
Таблиця 6.5. Переваги, недоліки та сфера використання масивів другого рівня
Переваги |
Виправлення помилок на льоту Можливі високі швидкості роботи Проста конструкція контролера |
Недоліки |
Потрібно багато дисків з перевірочною інформацією. |
Сфера застосування |
Комерційних реалізацій не існує |
Рівні 3,4
У масивах RAID третього рівня використовують віртуальний диск, що складається з декількох фізичних дисків і додаткового диска, що зберігає дані контролю за парністю. Блок парності формується внаслідок виконання операції XOR над відповідними байтами (або блоками) різних дисків. У випадку виникнення збою дані можна поновити. В системі RAID третього рівня зменшується тривалість читання інформації, однак дещо збільшується тривалість записування з огляду на потребу обчислення даних коректувального коду. Системи з RAID третього рівня особливо добре працюють з записами великої кількості послідовних блоків (відеоінформація, мультимедіа). Через високу вартість реалізації RAID третього та чертвертого рівнів використовуються рідко.
Четвертий рівень RAID подібний до третього, однак дані в ньому зберігаються не байтами, а блоками. Підсумкова інформація по рівням 3,4 RAID наведена у таблиці 6.6.
Таблиця 6.6. Переваги, недоліки та сфера використання масивів рівнів 3,4
Переваги |
Висока швидкість запису та читання Відмова диску мало впливає на швидкість Небагато дисків з перевірочними даними — висока ефективність збереження |
Недоліки |
Складна конструкція контролера Високе споживання ресурсів у програмній реалізації |
Сфера застосування |
Виробництво відео. Потокове відео. Додрукарське опрацювання |
Рівень 5
Для виконання великої кількості операцій уведення-виведення з різних місць диска (довільний доступ), що буває, наприклад, під час роботи з базами даних, використовують RAID п’ятого рівня. В цьому масиві перевірні блоки розміщені по всіх дисках масиву, і зберігаються разом з даними. Це прискорює роботу з довільним доступом і гальмує роботу з доступом послідовним. Переваги, недоліки та сфера використання масивів RAID п’ятого рівня наведена у таблиці 6.7.
Таблиця 6.7. Переваги, недоліки та сфера використання масивів п’ятого рівня
Переваги |
Найвища швидкість читання Середня швидкість запису Невелика кількість перевірочних даних — висока ефективність використання дискового простору |
Недоліки |
Відмова диску суттєво впливає на швидкість роботи системи Найскладніша конструкція контролера |
Сфера застосування |
Файлові сервера та сервера застосувань, веб-сервера, сервера баз даних, електронної пошти |
Рівень 6
Шостий рівень подібний до п'ятого, проте забезпечує подвійний контроль парності. Крім обчислення перевірних даних з кожної смуги, виконуються обчислення і для диска в цілому. Тому такий масив має на один диск більше, ніж масив п’ятого рівня.
Інші рівні
Дискову систему сьомого рівня випускає тільки фірма Storage Computer Corp. У її продукції реалізоване асинхронне виконання операцій уведення-виведення, використана спеціалізована операційна система реального часу, та інші вирішення.
RAID десятого рівня вважають комбінацією рівнів першого та нульового. Недоліки масиву першого рівня – обмеженість та недостатність одного диска, недостатня продуктивність. Тому використовують підхід віртуального диска з почерговим записуванням блоків на різні диски і дзеркальне копіювання таких дискових масивів.
RAID 53 – це масив масивів, який логічно можна уявити у вигляді матриці, в колонках якої містяться масиви третього (або п’ятого) рівня, а в рядках – масиви нульового рівня.
На практиці найчастіше використовуються RAID рівнів 0, 1, 3, 5.
Технічна реалізація та окремі вирішення для RAID
Для реалізації масиву RAID можна застосувати:
відповідні програмні продукти. Такі продукти є в Novell Netware, Windows та Linux. Вони дають змогу створити масив зі звичайних дисків, навіть різних типів. Таке вирішення дешеве, однак і продуктивність його невисока;
плату розширення, яка містить відповідний контролер, її включають у роз’няття розширення сервера;
окремий пристрій. Таке вирішення найдорожче, проте й забезпечує найвищі параметри щодо продуктивності, надійності та зручності адміністрування.
Закони Зіпфа
та Парето
Емпіричні закони Зіпфа та
Парето визначають частоти використання
певних елементів.
Закон Зіпфа,
сформульований американським лінгвістом
та філософом Дж. Зіпфом (1902-1950) на основі
аналізу частоти використання слів у
тексті, яка може бути подана як рівнобічна
гіпербола. Так, якщо найвживаніше слово
у тексті використовується n раз, то
слово друге за частотою використовується
в k раз менше (n/k раз), а наступне слово
— n/2k раз ітд. Значення k називають
коефіціентом Зіпфа.
Закон Парето
сформульований економістом Парето,
який звернув увагу, що 20% населення
володіє 80% всього національного
багатства. Пізніше Семюель Бредфорд
розширив цей принцип на неекономічні
області, перш за все на закономірності
бібліографічного пошуку.
Різні фірми розробили окремі вирішення, спрямовані на поліпшення роботи масивів RAID. Так, Digital використовує кеш зворотного запису з живленням від батарей. Відомо, що кешування інформації прискорює операції записування та читання. Однак, якщо виникне збій і частина даних виявиться не переписаною з кешу на диск, то інформацію буде втрачено. Запобігти цьому покликане додаткове живлення кешу з батарей. У разі поновлення роботи сервера першою буде записана інформація кешу.
Деякі фірми застосовують потрійні дзеркальні диски. Крім додаткового захисту інформації, така конфігурація дає змогу тимчасово від’єднувати один з дисків для резервного копіювання.
HP пропонує технологію динамічного конфігурування RAID. У звичайних системах є чітке відображення між логічними блоками віртуального диска і фізичними блоками дисків масиву. Це полегшує роботу контролера, збільшує його продуктивність, проте утруднює роботу адміністратора, який повинен підбирати параметри оптимального функціювання масиву вручну. Технологія динамічного конфігурування дає змогу автоматично обирати рівні RAID залежно від характеристик інформації, додавати до дискового масиву нові диски без зупинення інших. У цій технології використана проміжна адресна таблиця блоків.
Дублювання жорстких дисків не вирішує всіх проблем з надійністю сервера. Для її підвищення застосовують дублювання й інших пристроїв: SCSI адаптерів, дискових котролерів, джерел живлення, вентиляторів тощо.
MAID
В 2002 році в університеті ш. Колорадо Д.Колларели та Д.Грюнвальд запропонували використати масиви дисків для збереження зархівованих даних. В сучасних умовах, коли вартість окремого диску стрімко падає, стає вигідним будувати величезні масиви дисків. А щоб зекономити споживання електроенергії та зменшити тепловиділення, значну частину дисків можна періодично зупиняти. Такі дискові масиви отримали назву MAID (Massive Array of Idle Disks). MAID диски працюють з даними у режимі WORO (Write Once, Read Occasionally). При цьому до значної частини даних не звертаються взагалі.
Спочатку була запропонована така схема організації масива MAID. Усі диски поділялися на два рівні. Диски нульового рівня не працюють в нормальному режимі. Диски першого рівня виконують функції кешу і постійно ввімкнені. Якщо інформації у кешу немає, то вмикається один з дисків у нульового рівня. Як виявилося така схема має ряд суттєвих недоліків. Зокрема, залежно від значення коефіціентів Зіпфа та Парето-Бредфорда (див. врізку), потрібна ємність дисків першого рівня може різко зрости і звести нанівець усі переваги в економії електроенергії. Крім того, вузьким місцем стає обмін даними між дисками нульового та першого рівнів
Розглянемо будову дискового масиву фірми Copan. В масив входить 896 дисків сумарною ємністю у 224 Тбайта. Більшість дисків простоюють, а запускаються тільки тоді, коли потрібна інформація, що зберігається на них. Кожен диск є незалежним елементом збереження даних, а самі дані можуть мігрувати між дисками. Окремий рівень кешування — відсутній.
Диски у масиві утворюють трьохрівневу архітектуру. На нульовому рівні знаходиться коробка з 14 дисками обсягом 250 Гбайт кожен. Вісім коробок дисків зібрано в одну полицю. На найвищому рівні вісім полиць розміщують в одній стійці.
На кожному рівні є свій блок керування. Блок керування коробки забезпечує маршрутизацію даних та контроль температури. На рівні полиці контролер забезпечує внутрішню організацію збереження даних по типу RAID, а також кешування. На рівні стійки блок керування надає зовнішній доступ до бібліотеки згідно з протоклами SCSI, iSCSI, NFS, CIFS.
В процесі роботи виявилося, що оптимальна кількість ввімкнених дисків складає 0.27 від загальної кількості дисків. Для збільшення надійності у кожній коробці 4 диски є резервними і можуть бути перекомутовані так, щоб замінити довільний диск, у будь-якій іншій коробці, якщо той вийде з ладу.
Приймаючи до уваги, що певна кількість дисків не працює, традиційні підходи до реалізації RAID дисків були непридатні і довелося розробляти окремо Power Managed RAID.
Загалом масиви MAID забезпечують надійне та дешеве збереження даних у таких галузях застосування:
системи архівації даних;
бібліотеки контенту
2.3. Схеми приєднання дискової пам’яті до мережі
Традиційні підходи до приєднання засобів зберігання інформації до мережі такі. Тверді диски приєднують до серверів з використанням відповідних інтерфейсів. Така структура отримала назву DAS (Direct Attached Storage). Диски приєднують до сервера за двопунктовою схемою (рис. 6.4). При приєднанні використовують один з інтерфейсів (SATA, SCSI).
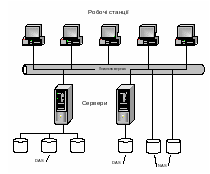
Рис. 6.4. Схеми приєднання дисків до комп’ютерної мережі DAS та NAS
Кожен сервер керує безпосередньо приєднаними до нього накопичувачами. Доступ до потрібних даних відбувається за посередництвом локальної мережі та відповідного сервера. Як локальна мережа, так і сервери можуть обмежувати швидкість виконання запиту та продуктивність системи. Однак така система є дешевою. Дуже просто також приєднувати нові тверді диски. Схема непогано працює в невеликих організаціях з незначними обсягами даних та невеликою кількістю серверів. Проте зі збільшенням розміру мережі та кількості серверів керувати стає щораз тяжче.
Недоліки DAS випливають з використання ресурсів серверів для виконання дискових операцій. Якщо сервер вимкнений, або вийшов з ладу, то інформація на дисках стає недоступною. Інтенсивні дискові операції, такі як архівування, призводять до недоступності сервера для клієнтів.
У схемі NAS (Network Attached Storage) дискові масиви безпосередньо приєднують до мережі. Недолік – перевантаження локальної мережі внутрішніми потоками дискових масивів. Крім того, дискові масиви керуються як частина загальної мережі, а не одне ціле. Перевагою систем NAS є краща керованість, більша надійність порівняно з DAS.
Для великих корпоративних мереж, зі значними обсягами даних доцільно об’єднати дискові масиви в окрему керовану систему збереження даних на базі мереж дискових масисів SAN.
2.4. Мережі дискових масивів
У 1998 р. запропоновано концепцію SAN (Storage Area Network), яка полягає у створенні окремої локальної мережі для об’єднання пристроїв зберігання інформації та забезпечення їх вбудованим інтелектом. Така система придатна для централізованого зберігання великих обсягів даних, які постійно збільшуються, наприклад, web-даних (рис. 6.5). Збереження даних у мережі SAN має такі переваги:
централізоване зберігання розвантажує сервери та локальну мережу;
інформація на довільному пристрої однаково доступна з довільного сервера;
можна виконувати резервне копіювання без припинення роботи системи;
у такій системі ліпша масштабованість, легше шукати несправності.
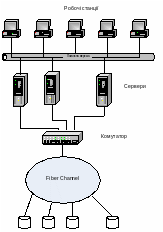
Рис. 6.5. Приєднання дискових масивів за схемою SAN
Як звичайно, для реалізації мережі зберігання використовують дуже швидкодійні мережеві вирішення (найчастіше FC-AL (Fiber Channel Arbitrated Loop)); це дає змогу приєданати до 128 пристроїв та передавати дані зі швидкістю до 200 Мбайт/с, що значно перевищує швидкості інтерфейсів SCSI. При цьому:
уся система зберігання приєднана через комутатори та маршрутизатори;
система допускає централізоване керування адміністратором, що створює додаткові можливості для захисту даних, та керованості даними;
схема дає змогу створювати декілька резервних кілець FC та приєднувати сервери до декількох кілець одночасно, що підвищує її надійність та швидкодію;
SAN значно послаблює обмеження на максимальні відстані між серверами та пристроями зберігання даних. Для SCSI, наприклад, це 25 м; для FC-AL максимальна відстань становить уже 10 км.
Керування збереженням даних у мережах SAN
Виділення даних корпорації для збереження в єдиній мережі SAN ставить та робить можливим вирішення задачі керування збереженням даних. Цю задачу вирішує SAM (Storage Area Management) – підсистема керування зберіганням даних. Більш детально, до функцій SAM належить керування засобами збереження, дисковими масивами та засобами їх з’єднання, керування даними та потоками даних, (архівування, дзеркалювання, поновлення), моніторинг продуктивності, контроль експлуатаційних характеристик, облік вартості збереження даних.
Функції, що реалізують SAM та реалізовані в продуктах окремих виробників розташовані на декількох рівнях абстракції.
на найнижчому рівні реалізоване керування базовими технічними та програмними компонентами мережі зберігання.
наступний рівень – керування мережами зберігання даних – отримує дані з найнижчого рівня, агрегує їх та здійснює керування на основі агрегованої інформації, розглядаючи SAN як одне ціле.
рівень віртуалізації виконує функції віртуалізації даних.
• рівень керування даними містить традиційні функції керування такі як архівування та поновлення даних, міграції даних.
Відносно новими є рівні Керування ресурсами збереження та інтеграції застосувань.
Рівень керування ресурсами надає можливість працювати з файловими системами, томами, каталогами та файлами не залежно від типів з’єднань. Таким чином, створюється єдина логічна модель ресурсів.
Рівень Інтеграції застосувань співвідносить окремі ресурси збереження з бізнес – застосуваннями.
До недавнього часу розумілося, що SAN найчастіше розташована в локальній мережі корпорації – в межах одного будинку, або декількох близько розташованих будинків. Але з’являється все більше глобальних мереж SAN. Це пояснюється глобальним характером сучасних корпорацій, те неохідністю побудови рішень стійких до катастроф.
Таким чином, за своїми розмірами на сьогодні виділяють такі типи SAN:
у межах одного будинку або групи будинків. Використовується Fiber Channel та призначені оптичні канали
в межах невеликого міста. Дані Fiber Channel транспортуються поверх систем CWDM.
в межах регіону або великого міста. Дані Fiber Channel транспортуються поверх систем DWDM або SDH.
у межах світу – дані Fiber Channel передаються поверх IP.
Недоліки SAN
Збереження даних у SAN має недоліки. Зокрема, дослідження показують, що ресурси задіяні тільки на 50%; сервери з різними файловими системами вимагають різних квот дискового простору та не бачать інформації в інших розділах дисків. Таким чином неможливо створити єдиний пул дискових ресурсів. Такі файлові системи доводиться і адмініструвати вручну, окремо. При цьому також неможливо динамічно перерозподіляти ресурси.
Для усунення зазначених недоліків та досягнення більш ефективного збереження даних використовують рішення віртуалізації.
Доступ до даних на дисках через Інтернет. Протокол iSCSI
Протокол iSCSI (RFC 3720) можна використовувати як вирішення для віддаленого приєднання пристроїв SAN.
iSCSI розроблено IETF як протокол для сполучення дискових пристроїв через Інтернет. В основі цього протоколу лежить передавання команд SCSI на віддалену систему. Цей протокол може використовуватися у всіх типах мереж.
Коли застосування користувача створює запит до дискової системи, операційна система генерує команди SCSI які потім розміщуються в IP-пакеті та передаються по мережі. При потребі ці команди шифруються. Пакет передається мережею та надходить до отримувача, який дешифрує та виокремлює команди SCSI, а потім передає їх на контролер диску. Так як протокол SCSI передбачає діалог між учасниками обміну, то контролер у свою чергу може згенерувати відповіді та переслати їх на комп’ютер користувача.
Використання протоколу iSCSI для доступу до віддалених дискових масивів має альтернативи. Зокрема протокол FCIP (Fibre Channel over IP) дає змогу інкапсулювати в IP пакети команди керування мережі Fibre Channel на віддалену мережу цього протоколу. На відміну від цього протоколу iSCSI працює і в мережах Ethernet.
2.5. Технології віртуалізації збереження даних
Головні поняття та рівні віртуалізації
Віртуалізація збереження даних – це логічне абстрагування фізичних систем збереження, яке приховує деталі реалізації від користувача.
Метою розробки та впровадження віртуалізації є зменшення вартості збереження даних, краща керованість системами збереження, прозорість щодо платформ.
На сьогодні технології віртуалізації інтенсивно розвиваються. Тому не існує єдиного розуміння їх призначення чи стандартів. Велику роботу з впорядкування та класифікації основних принципів віртуалізації даних проводить Асоціація виробників мереж збереження даних (Storage Networking Industry Association – SNIA). Зокрема вона розробила таксономію основних принципів та систем віртуалізації збереження даних (рис. 6.6).
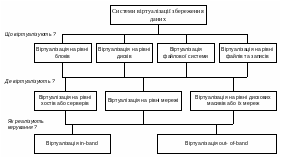
Рис. 6.6. Таксономія SNIA для систем віртуалізації збереження даних
Відповідно до цієї таксономії визначено, на якому рівні системи відбувається віртуалізація: блоків на диску, дисків, файлових систем, окремих записів чи файлів. За місцем впровадження віртуалізації розрізняють віртуалізацію на базі сервера (хоста), рішення на базі мережі, або дискових масивів. За способом організації передавання даних керування розрізняють віртуалізацію “In-band” та “Out-of-band”.
Важливою вимогою до сучасних систем віртуалізації збереження даних є автоматизація рутинних операцій з даними, таких як архівування, реплікація, балансування, додавання нових дисків або масивів тощо. Для зменшення ручних операцій віртуалізація має використовувати політики, за допомогою яких можна визначити, наприклад, що дана транзакція повинна використовувати швидкодіючу пам’ять та вимагає негайної реплікації порівняно з іншими транзакціями. Система збереження також повинна розрізняти застосування та їх потоки. Наприклад, відтворення та збереження відео вимагає більшої швидкодії, фінансові операції вимагають частого резервного копіювання.
Віртуалізація на рівні диску. Абстракції віртуальної пам’яті
Найменшою одиницею запису даних на диск з точки зору файлової системи є блок. Блок – це послідовність суміжних байтів на диску визначеного розміру. Розмір блоку визначають під час створення файлової системи, він буває у межах від 512 байтів до 512 Кбайтів. Чим більше блок, тим ефективніші операції з ним – за один запит, наприклад, зчитують більше даних. З іншого боку, у великих блоках можливе неефективне використання дискового простору – наприклад файл розміром 20Кбайт буде займати три 8-Кбайтні блоки, і 4 Кбайти будуть порожніми. Блоки одного файлу можуть знаходитися на різних дисках.
Коли операційна система ініціює операцію зчитування даних з диску, вона видає для контролера перелік адрес блоків, які необхідно зчитати у пам’ять. Контролер диску перетворює ці адреси, що використовує диск – номери циліндра, головки та сектору. З точки зору контролера блоки можуть бути розмішені на декількох дисках RAID масиву. Запис вказаного набору блоків з точки зору ОС для контролера масиву може виглядати як запис на віртуальний диск, що складається з багатьох блоків.
Таким чином, віртуалізація на рівні диску зводиться до відображення адрес отриманих від операційної системи в адреси дискової системи та навпаки.
Віртуалізація на рівні файлових систем
На рівні файлової системи дані зберігають у файлах. Файл – це іменована послідовність байтів, яка зберігається на запам’ятовуючому пристрої. Запис відрізняється від файлу тим, що його зміст є структурованим, таким як зміст запису таблиці бази даних. Записи можна зберігати в одному, або у декількох файлах. Записи у звичайних файлах можуть бути і неструктуровані.
Важливою частиною файлу є його метадані. Ці дані містять керуючу інформацію файлу – його назву, час створення, власника, дозволи доступу. Метадані файлу можна зберігати та використовувати окремо від тіла файлу. Це часто використовують у системах віртуалізації.
Файлова система вирішує завдання організації систематичного зберігання та ефективного використання файлів. Для виконання цього завдання вона використовує набір таблиць керування. Файловий простір поділяють на томи. Для кожного тому ФС підтримує окремий набір таблиць. Фізично том може бути розмішений на частині диску, або декількох дисках.
Рішення віртуалізації на рівні тому (LVM – Logical Volume Management) дозволяє застосуванням працювати з логічними томами замість фізичних. Логічний том виглядає як один локальний диск, хоча насправді він може охоплювати декілька фізичних дисків. Рішення LVM дають змогу динамічно (без зупинки системи) додавати або вилучати дисковий простір з тому, проводити операції архівування, перевіряти цілісність даних та ін. LVM може бути реалізована як проміжне ПЗ розміщене між файловою системою та драйверами пристроїв, між комп’ютером та масивом у SAN, або навіть у вигляді вбудованого ПЗ у масиві RAID.
Віртуальні файлові системи
Одним з недоліків збереження даних на багатьох масивах з різними типами файлових систем є неефективність використання дискового простору. При цьому окремі типи файлових систем вимагають окремого налаштування та адміністрування. Вирішення цієї проблеми – у використанні серверів метаданих, які опрацьовують запити до файлів, враховуючи специфіку конкретної файлової системи.
Прикладом реалізації віртуальної файлової системи є SAN File System (SAN FS) розроблена фірмою IBM у межах проекту Storage Tank (рис. 6.7). Головним принципом такої системи є реалізація відображення функцій логічного доступу до даних у фізичний ввід- вивід в окремому сервері метаданих. Сервери застосувань звертаються до сервера метаданих за інформацією про місце знаходження потрібного файлу та за дозволом виконати потрібну операцію над даними. Наступні операції відбуваються між серверами застосувань та системами збереження напряму, без посередників, що дозволяє підняти продуктивність.
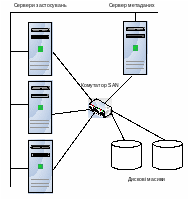
Рис. 6.7. Схема віртуальної файлової системи SAN FS
Сервер метаданих зберігає всю інформацію, яка звичайно зберігається у файловій системі (назва файлу, дати створення та модифікації, адреса розміщення, права доступу та ін).
Дискові масиви зберігають тільки блоки даних. Це дозволяє динамічно переміщувати інформацію між окремими дисковими масивами без зупинки застосувань. Це також створює єдиний адресний простір та простір імен.
Віртуалізація на рівні хоста
Рішення віртуалізації на рівні окремого хоста звичайно полягає у реалізації LVM (рис. 6.8.).
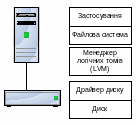
Рис. 6.8. Схема реалізації LVM на рівні хоста
Недоліком такого підходу є перевантаження процесора хоста функціями LVM, що, наприклад, у випадку реалізації програмного RAID може призвести до уповільнення роботи. Параметри роботи LVM на хості залежать від ефективності операційної системи та серверної платформи. Відсутність спеціалізованого апаратного та програмного забезпечення LVM також знижує вислідну ефективність.
Використання LVM базованого на хості призводить до необхідності налаштування та адміністрування кожного хоста окремо, що може бути неприйнятним у випадку великої та складної мережі з сотнями або тисячами серверів. Крім того, хост є власником ресурсів, доступних через LVM. У випадку виходу хоста з ладу його ресурси та налаштування приєднаних до нього дисків втрачаються, що може створити проблеми доступу до даних.
Головною перевагою розміщення LVM на хості є незалежність від дискових архітектур, їх механізмів керування.
Ще одне рішення використовує подвійні шляхи доступу з хоста до дискового масиву (рис. 6.9).
Рис. 6.9. Надлишкова конфігурація з подвійним шляхом доступу до масиву
Використання резервних шляхів доступу до дискового масиву є обов’язковим для систем високої доступності. Незважаючи на великі додаткові кошти на обладнання, побудова резервних шляхів доступу – це єдиний шлях до забезпечення доступності.
Віртуалізація збереження даних на рівні дискових масивів
Віртуалізація на базі дискових масивів унезалежнює від технічних деталей серверів та дає змогу використати додаткові можливості, запропоновані виробниками масивів. Контролери масивів реалізують базові механізми віртуалізації у формі підтримки RAID масивів, підрахунку контрольних сум.
На рівні масивів реалізують різні форми координації збереження даних між різними масивами, зокрема реплікацію. У випадку синхронної реплікації (рис. 6.10) транзакція запису даних вважається завершеною, коли запис проведено як на первинний, так і на вторинний масив. Для кращого захисту від крадіжок, стихійних лих первинний і вторинний масиви розміщують якнайдалі один від одного, у надійних приміщеннях та локаціях. При цьому на загальну продуктивність системи впливає відстань між точками розміщення масивів. Це обмежує відстань між масивами до 100 – 150 км.
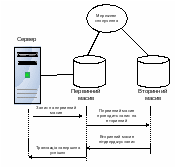
Рис. 6.10. Синхронна реплікація
В методі асинхронної реплікації транзакція запису вважається завершеною при закінченні запису на первинний масив (рис. 6.11). Як правило первинний масив ставить транзакції у чергу на запис до вторинного масиву та вимагає підтвердження успішного запису. Метод асинхронної реплікації менш надійний ніж метод синхронної, але він не має обмежень на відстань між масивами.
Важливим видом сервісу віртуалізації, який надається на рівні дискових масивів є побудова знімків (snapshots) стану даних масиву у визначений момент часу. Знімки стану доповнюють реплікацію як механізм захисту даних. Якщо реплікація здійснюється на рівні транзакцій, то знімки стану відображають усі зміни у даних на визначений момент часу. На відміну від реплікації, виконання знімку вимагає попереднього очищення буферів пам’яті та завершення усіх незавершених операцій. Для більшої надійності, знімки стану даних не зберігають на локальному масиві, а реплікують його на інший масив (рис. 6.12).
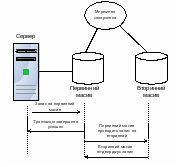
Рис. 6.11. Асинхронна реплікація
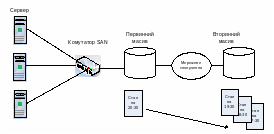
Рис. 6.12.Реплікація знімку даних
З метою зменшення розміру знімку, у ньому записують тільки зміни, що відбулися відносно попереднього стану даних. Знімки стану даних використовують для відновлення стану даних у випадку їх спотворення вірусами, втручанням зловмисників, а також для проведення аналізу у ході розслідування операцій з даними.
Віртуалізація збереження даних на рівні мережі
Реалізація функцій віртуалізації на рівні мережі передбачає перенесення цих функцій у комутатори мережі SAN. Таке перенесення унезалежнює розробників віртуалізаційних технологій від необхідності врахування обмежень, закладених виробниками комп’ютерів та дискових масивів. Прикладом такого вирішення є перенесення функцій дискового контролера з диску у комутатор мережі. Водночас, завдання реалізації віртуалізації на рівні мережі повинно враховувати, що комутатори виконують складні комунікаційні функції і мають обмежені ресурси, що може вплинути на швидкодію виконання операцій віртуалізації.
Віртуалізація “In-band” та “Out-of-band”.
У системах віртуалізації збереження даних виділяють два типи потоків даних: потоки керування, що передають метадані про файли та налаштування та потоки даних, що переносять блоки файлу. Якщо потоки керування та потоки даних прямують одним і тим же шляхом, то систему називають “in-band” системою. Якщо потоки керування та даних розділені (як наприклад, у віртуальній файловій системі SAN FS, то таку систему називають “out-of-band” системою.
Використання систем віртуалізації збереження даних та їх менеджмент
Системи віртуалізації збереження даних використовуються для підвищення надійності збереження даних. Вважають, що необхідну гнучкість таким системам можна надати шляхом використання політик та профілів керування. Такий підхід дає змогу виокремити певний тип транзакцій та застосувати до нього окремі вимоги щодо збереження. Наприклад, закон може наголошувати, що інформація про торгові транзакції повинна бути доступна для аналізу протягом 24 годин після транзакції. Виконання цієї вимоги потребує виокремлення певного типу торгових транзакцій та гарантування доступності даних залежно від часу.
Для стандартизації процесів керування в галузі віртуалізації збереження даних SNIA розробила специфікацію інтерфейсу керування (SMI-S) яка базується на використанні інформаційної моделі CIM (Common Information Model). Схема CIM дає змогу визначити політики керування системами віртуалізації даних та здійснити відповідні операції керування за посередництвом протоколу WBEM.
Вирішення питання взаємодії систем віртуалізації даних з застосуваннями відбувається двома шляхами: побудовою систем віртуалізації орієнтованих на застосування (Application-Aware Storage Virtualization) та розробкою застосувань, орієнтованих на системи віртуалізації збереження (Virtualization-Aware Applications).
У першому випадку для кожного типу застовувань визначено свій набір політик. Система віртуалізації аналізує тип застосування та використовує відповідний набір політик при роботі з ним (рис. 6.13).
Для застосувань, орієнтованих на віртуалізовані системи збереження даних необхідно розробити API доступу. Застосування використовують сервіси надані системою віртуалізації відповідно до своїх потреб (рис. 6.14).
Використання API доступу дає змогу побудувати гнучкі системи віртуалізації та використати особливі вимоги застосувань.
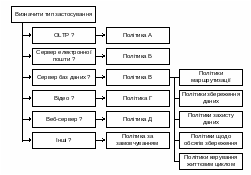
Рис.6.13. Робота систем віртуалізації орієнтованих на застосування
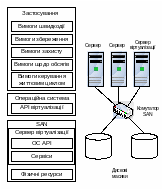
Рис.6.14. Робота застосувань орієнтованих на системи віртуалізації збереження даних
Питання до самоконтролю
1. В чому переваги SSD дисків порівняно з HDD ?
2. Принципи збереження даних на RAID масивах.
3. Сфера застовування RAID п’ятого рівня.
4. Сформулюєте закон Зіпфа.
5. Схеми приєднання дискової пам’яті.
6. Де застосовують менеджери віртуальних томів (LVM) ? Які задачі вони вирішують?
7. Як побудована та працює віртуальна файлова система ?
8. В чому різниця між синхронною та асинхронною реплікаціями ?
Лекція 3. Служби каталогів.
3.1. Загальна характеристика служб каталогів комп’ютерних мереж
Потреба пiдтримки спецiальних служб каталогiв комп’ютерних мереж зумовлена значним зростанням мереж, наявнiстю в них багатьох серверiв рiзного профiлю, великої кiлькостi користувачiв та застосувань. Що ж таке служба каталогiв?
Служба каталогiв (Directory Service) - це розподiлена база даних з iнформацiєю про мережевi об’єкти, а також засоби доступу до неї та пiдтримки. Це також мережевий сервіс, який надає інформацію про мережеві об’єкти, та послуги аутентифікації.
Вона дещо подiбна до Реєстру (Registry) Windows, однак, на вiдмiну вiд нього, мiстить параметри конфiгурацiї не одного комп’ютера, а всiх об’єктiв мережi. Наявнiсть служби каталогiв (СК) дає змогу створювати тiльки один варiант реєстрацiйних параметрiв кожного мережевого об’єкта. Наприклад, користувач, зареєстрований у СК, може працювати з багатосерверною мережею на будь-якiй робочiй станцiї i завжди працюватиме у звичному для себе середовищi. Без СК йому довелося б реєструватися на кожному серверi у випадку запуску кожного застосування. Аналогiчнi переваги СК має для централiзованого збереження iнформацiї про iншi об’єкти мережi: файл-сервери, сервери друкування та принтери, модемнi сервери тощо. Загалом, служба каталогів мережі дає змогу розглядати мережу як з одне ціле. Вона віртуалізує мережеві ресурси, та дає змогу працювати з ними незалежно від місця їх розташування. Окремим випадком служби каталогів є DNS. Розглянемо властивості сучасної служби каталогів детальніше.
Мережеві ресурси згруповані в ієрархічну структуру (дерево).
У корені дерева є логічний об’єкт, який об’єднує всі ресурси дерева та зберігає їхні спільні властивості.
Гілки дерева – логічні об’єкти-контейнери, які слугують для групування об’єктів. Об’єкт-контейнер містить інші об’єкти, серед яких також можуть бути контейнери. Таким способом утворюється дерево об’єктів. Найуживанішими типами контейнерів є об’єкти–країни, організації, підрозділи.
Листя дерева – це об’єкти, що відповідають мережевим ресурсам. Такими ресурсами можуть бути сервери різних типів, робочі станції, принтері, користувачі, їхні посади, окремі застосування та ін. Список можливих типів кінцевих об’єктів постійно поповнюється.
Групування мережевих ресурсів у вигляді дерева дало змогу розглядати логічну структуру мережі окремо від фізичної, хоча в окремих випадках під час побудови дерева доводиться враховувати й особливості фізичної структури, наприклад структуру комунікацій.
Успадкування прав доступу на нижчих рівнях ієрархїї.
Деякі типи об’єктів є принципалами безпеки (security principal). Таким об’єктам можуть бути визначені права доступу до інших об’єктів. Принципал безпеки може отримати певні права доступу до контейнера (наприклад, підрозділу організації). В цьому випадку він отримає ці ж права на всі об’єкти, вкладені в контейнер (належать підрозділу). Це дуже зручно для адміністрування, адже за одну операцію можна призначити права доступу великій кількості об’єктів.
Якщо потрібно обмежити таке успадкування прав для деяких об’єктів, то використовують фільтри успадкованих прав (Inheritance rights filter (IRF)) які блокують успадкування визначених прав.
Наявність ієрархічної бази даних з інформацією про мережеві ресурси.
База даних про мережеві об’єкти спроектована для збереження ієрархічних структур даних. Вона є об’єктною асоціативною базою, записи якої – це пари атрибут–значення. Кожен об’єкт має набір атрибутів (властивостей) з конкретними значеннями.
База даних є розподіленою і доступна з довільного комп’ютера мережі.
Окремі частини бази даних зберігаються на різних серверах. Крім того, для збільшення надійності та зменшення тривалості доступу окремо зберігають копії (репліки) частин бази. Для узгодження інформації, розміщеної на різних серверах, розроблено складні, проте ефективні механізми. Такий підхід дає змогу створювати дуже великі дерева для корпорацій світового масштабу. Зокрема, база eDirectory підтримує понад 1 млрд об’єктів.
Схема бази даних дає змогу адміністратору розширювати її новими типами елементів та новими властивостями
Аналогічно до інших типів баз даних, бази служб каталогів мають схему, яка визначає допустимі типи об’єктів та допустимі їхні властивості. Сучасні СК дають змогу додавати нові типи об’єктів або нові властивості для наявних об’єктів. СК може містити характеристики всіх компонент інформаційної системи підприємства (файлова система, бізнес-логіка, комутатори, маршрутизатори та інші активні пристрої мережі, користувацькі профілі, інформація для автентифікації користувачів, інформація окремих застосувань та ін.). Така здатність важлива для застосувань, що працюють зі службами каталогів.
Наявність служб пошуку даних
Як звичайно, СК має окрему службу пошуку даних у базі даних. Цю службу часто називають ‘білими сторінками’. Такий довідник дає змогу знайти потрібний ресурс за наявності неповної інформації про нього.
Використання застосувань, які працюють зі службами каталогів
Служби каталогів мають відкритий інтерфейс, який дає змогу звертатися до бази даних СК за інформацією, автентифікувати користувачів. З СК співпрацює значна кількість нових застосувань, що дає змогу спростити та здешевити їх, передаючи деякі функції до СК. Такі застосування називають Directory enabled applications.
Запровадження СК дає змогу створювати та використовувати розподiлену систему керування ресурсами мережi, перерозподiляти навантаження, оптимiзувати надання послуг незалежно вiд мiсця розташування вiдповiдних серверiв та реально наблизитися до створення розподiлених iнформацiйних систем.
3.2. Історія розвитку служб каталогів
Розвиток служб каталогiв був значно зумовлений вирiшенням проблеми усунення багаторазової реєстрацiї клiєнта.
Спочатку була окрема мережева ОС. Клiєнт, входячи у мережу, реєструвався на певному серверi. У цьому випадку перевiрялися його повноваження та права доступу. Отже, клiєнт був ‘прикрiплений‘ до цього сервера. Наприклад, у Novell Netware 3.11 iнформацiя каталогу зберiгалася в базi даних ‘bindery` кожного сервера. Кожен сервер мав свою базу, i для роботи з iншим сервером потрібна була повторна реєстрацiя.
Такий же принцип діє в UNIX системах і сьогодні, тобто клієнт реєструється на кожному сервері окремо. Адміністратор повинен стежити, щоби користувачі мали однакові реєстраційні параметри на всіх серверах. Однак під час роботи з системою, що має велику кiлькiсть серверiв, перереєстрацiя є незручною.
Наступним кроком став перехiд до доменних СК. У цьому випадку користувач реєструвався один раз у визначеному доменi. Доменну систему використовували в ОС Windows NT. Заради сумісності з попередніми версіями цю систему підтримувано і в наступних версіях Windows поряд зі службою каталогів Active Directory. Доменна система є проміжною в переході від посерверного вирішення до повноцінних СК. У такій системі мережеві ресурси (комп’ютери, принтери, користувачі) ґрупують за спеціальними логічними сутностями, які називають доменами. Один домен може об’єднувати багато серверів та робочих станцій. У межах одного домену реєстрація користувачів відбувається прозоро. Інформація про ресурси зберігається централізовано на призначених для цього серверах (контролерах домену). Для зменшення тривалості часу доступу бази даних продубльовані в первинних та вторинних контролерах домену. Недоліки доменної структури: недостатня масштабованість, неможливість групування мережевих ресурсів відповідно до специфіки організації бізнес-процесів, мала кількість типів мережевих ресурсів, неможливість додавання нових типів даних та ін. Доменну архітектуру доцільно використовувати в невеликих мережах з малим набором функцій.
Iєрархiчна структура виявилася зручнішою порiвняно з доменною. Пiсля реєстрацiї користувач може працювати з усiма ресурсами дерева. Перша повноцінна служба каталогів (Netware directory service (NDS)) з’явилася в ОС Novell Netware 4.0. Пізніше розроблено служби LDAP, MS Active Directory, NIS+ та ін.
Деякі з наявних сьогодні служб каталогів (MS Active Directory, NIS+) успішно працюють у мережах тільки однієї ОС. Інші (eDirectory, LDAP) мають засоби для роботи в гетерогенних мережах. Загалом проблему роботи в гетерогенних мережах можна вирiшити, максимально поширивши найпопулярніший продукт СК або розробивши продукти-посередники, якi забезпечують взаємодiю рiзних СК (наприклад, продукт VIA фiрми Zoomit), або використовуючи єдиний протокол доступу до каталогiв (такий як LDAP або Х.500). Iсторiю розвитку конфiгурацiй СК відображено на рис. 6.15.
Розглянемо найпопулярніші СК детальніше.
Рис. 6.15. Різні органiзацiї служб каталогів
3.3. Стандарти X.500 та LDAP
LDAP (Lightweight Directory access protocol) є головною СК для мереж TCP/IP завдяки підтримці IETF, а також міжнародному, не фірмовому характеру специфікації.
Спочатку міжнародні організації зі стандартизації розробили та прийняли стандарт служби каталогів X.500, що надавав багато можливостей, однак виявився занадто складним і працював тільки на потужних Unix-серверах. Водночас більшість потенційних клієнтів СК працювало на персональних комп’ютерах. Виникла потреба організувати сполучення цих клієнтів з серверами каталогів X.500 – розробити відповідний протокол, який би працював у мережах стека TCP/IP. Першими такими протоколами були Dixie (RFC-1249) та DAS (Directory Assistance Service, RFC-1202). У 1992 р. IETF почало розробляти стандарт цих протоколів, які працювали б з усіма версіями X.500. Завдяки цьому з’явився LDAP, який і затверджено як попередній стандарт 1995 р.
З часом відставання у розвитку та недостатня підтримка виробниками обладнання стандарту X.500 спонукала розробити slapd – сервер LDAP. Це дало змогу системі LDAP працювати незалежно і без систем X.500. Версію LDAP 3 затверджено як проект стандарту 1997 р.
LDAP складається з таких компонент.
Інформаційна модель. Складається з рядків (entries). Кожний рядок має атрибут та список значень цього атрибута. Ця модель повністю відповідає моделі Х.500; дає змогу додавати іншу інформацію.
Схема LDAP. Визначає типи елементів, інформація про які може зберігатися в БД LDAP. Визначено такі елементи, як країни, організації, користувачі, їхні групи. Сервери можуть визначити свої елементи.
Модель найменування. Визначає структуру інформації та її позначення. Імена ієрархічні та складаються з атрибутів і значень відповідного рядка БД LDAP (рис. 6.16).
Модель найменування LDAP походить з X.500 та сумісна з ним, однак вона гнучкіша, накладає менше обмежень.
Модель безпеки. Розширені засоби автентифікації дають змогу клієнтам та серверам взаємно підтверджувати автентичність.
Функційна модель визначає те, як клієнти можуть отримати інформацію в LDAP, як маніпулювати нею. LDAP передбачає виконання дев’яти базових операцій: додати, знищити, модифікувати, приєднатися (bind), від’єднатися (unbind), шукати, порівняти, припинити (abandon), змінити DN (distinguished name). Операції приєднатися та від’єднатися керують автентифікацією між серверами та клієнтами, операція пошуку дає змогу шукати користувачів та послуги на дереві каталогів, операція порівняння – застосуванням порівнювати свої значення зі значеннями в LDAP, зміна DN – змінити ім’я запису в БД, операція ‘припинити’ на вимогу клієнта припиняє поточну операцію на сервері.
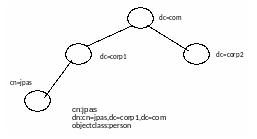
Рис. 6.16. Модель найменування ресурсів в LDAP
Протокол LDAP визначає взаємодію між клієнтами та серверами і відображення на LDAP. Наприклад, протокол визначає, що окремі записи, які надходять у відповідь на команду пошуку, передаються окремими пакетами, це дає змогу передавати багато даних, не перевантажуючи мережу.
Програмні інтерфейси (API). Визначають функції та програми доступу до інформації LDAP.
Формат обміну даними (LDAP data interchange format). Простий текстовий формат для наведення записів БД і змін до них. Дає змогу синхронізувати БД LDAP з іншими базами даних.
Застосування LDAP звертаються до бази LDAP з використанням визначених API. Система LDAP надає такі сервіси:
пошук користувачів та ресурсів мережі;
керування ними;
аутентифікація користувачів та ресурсів.
Використання LDAP як мережевої БД має певні обмеження а саме:
LDAP не замінює традиційних СУБД. Він не має механізмів опрацювання транзакцій, двох фазних операцій commit, можливостей будувати звіти та розробляти застосування, його не оптимізовано для інтенсивних операцій з даними, нема єдиної мови доступу, подібної до SQL;
LDAP не заміняє DNS, тому що DNS масово розгорнута, добре працює (хоча LDAP виконує споріднені функції);
LDAP не замінює файлової системи. Його не пристосовано до роботи з великими бінарними файлами. Він не підтримує блокування записів та деяких інших функцій, властивих файловій системі.
В IETF над розширенням LDAP працюють дві робочі групи:
LDAP Directory update розробляє стандарти реплікації;
LDAP Extensions розробляє стандартні розширення до LDAP, такі як контроль доступу, розширення API.
3.4. Служба каталогів eDirectory
Загальна характеристика eDirectory
В основі архітектурної концепції Netware є eDirectory (Служба каталогів Netware, попередня назва – Netware Directory Services -NDS). Згідно з цією концепцією всі ресурси мережі зображені об’єктами, занесеними в спеціальну розподілену базу даних - Netware Directory Database. Визначено різні можливі типи об’єктів: користувач, сервер, том, група користувачів та ін. Окремі об’єкти можуть відображати як реальні (наприклад, комп’ютер або користувач), так і абстрактні сутності. Ці об’єкти згруповані в ієрархічному дереві. Ієрархічна деревоподібна структура відображає взаємну підпорядкованість об’єктів. Кожен об’єкт конкретного типу має власний набір властивостей та їхніх значень. Зокрема, об’єкт типу ‘користувач’ має такі властивості: ім’я, пароль, поштову адресу, адресу електронної пошти, номер телефону, належність до груп користувачів тощо. Людина, що працює в мережі, а також і зовнішня програма, може аналізувати властивості об’єктів у eDirectory.
Служба eDirectory повністю відповідає стандарту X.500 і діє на базі структури об’єктів, яку називають деревом каталогів (Directory tree). Вона має три структурні типи об’єктів:
кореневий об’єкт (Root );
контейнерний об’єкт (Container object);
кінцевий об’єкт (Leaf object).
Кожне дерево має тільки один кореневий об’єкт. Йому умовно відповідає об’єкт - весь світ. Контейнерні містять інші об’єкти. Кінцеві об’єкти є головними, з якими працюють.
Контейнерні об’єкти, як уже зазначено, містять інші об’єкти. Вони призначені для організації та групування кінцевих об’єктів. Визначено такі типи контейнерних об’єктів:
C - Країна (Country) - містить код позначення країни та не є обов’язковим. Кожне дерево може мати не більше одного рівня країн.
O- Організація (Organization) містить назву організації та є обов’язковим. Кожне дерево повинно мати не менше одного об’єкта цього типу. Однак допустимий тільки один структурний рівень об’єктів-організацій.
OU - Організаційний підрозділ (Organizational Unit) зберігає інформацію про певний підрозділ організації та його параметри. Кількість об’єктів OU у дереві довільна, вони можуть бути довільно вкладені один в одний.
Згідно з вимогами стандарту X.500 eDirectory підтримує і такі контейнерні об’єкти, як
S – Штат (State) містить позначення певного штату США;
L – Розташування (Location) визначає розміщення ресурсу.
Кiнцевi об’єкти. Для кінцевих об’єктів використовують позначення CN (Common Name). Для зручності наведення кінцевих об’єктів згрупуємо їх відповідно до функційного призначення.
Зазначимо, що об’єктом eDirectory є не сам фізичний об’єкт (сервер або принтер), а лише інформація про нього, що зберігається у розподіленій базі даних. Кількість типів можливих об’єктів у eDirectory є змінною. Базова версія Netware 5 визначає 34 класи об’єктів, які не можуть бути знищені. Novell Netware API дає змогу розробникам застосувань визначати нові типи об’єктів або ж додавати нові властивості до наявних. Наприклад, використання Windows у мережі відображене застосуванням об’єктів, що відтворюють специфіку цієї ОС. Водночас кожен новий тип об’єкта повинен бути зареєстрований у Novell Developer Support, щоб уникнути суперечностей та спотворень даних.
Приклад дерева для гіпотетичного міжнародного університету зображений на рис. 6.17.
Іменування об’єктів eDirectory
Для правильної роботи eDirectory перед її запровадженням потрібно розробити систему правил називання об’ктів. Им’я об’єкта для зручності роботи користувачів повинно віддображати його функційне призначення.
Деякі компоненти назв задає сама система. До них належать типи імен. Позначення типів визначені у стандарті X.500. Наприклад, контейнерні об’єкти мають такі позначення: С - країна, L - розміщення, S - штат, O - організація, OU – підрозділ. Для позначення типу кінцевого об’єкта зарезервовано одне позначення - CN.
Розрізняють такі імена.
Повні ідентифікаційні (Distinguished name). У них відображено шлях від об’єкта до кореня дерева. Корінь дерева в імені не зазначено. Наприклад, повне ім’я для користувача VCoval таке: cn=vcoval.ou=ailab.ou=computer.ou=lviv.o=tech_univ.
Відносне ім’я (relative distinguished name), тобто ім’я щодо поточного контейнера. Наприклад, якщо поточний контейнер ailab, то відносне ім’я користувача Vcoval буде cn=vcoval. Для забезпечення унікальності відносних імен eDirectory не дає змоги створювати в одному контейнері декілька об’єктів з однаковими іменами (навіть різних типів.)
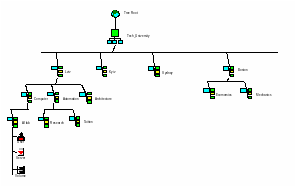
Рис.6.17. Дерево каталогів для міжнародного університету
Часткове ім’я (partial name), тобто ім’я щодо якогось проміжного контейнера. Приклад часткового імені:
cn=vcoval.ou=ailab. Воно визначене щодо контейнера ou=computer.ou=tech_univ.
Для зручності роботи, крім типізованих імен, у яких зазначено типи кожного об’єкта, визначені також нетипізовані імена, у яких типи об’єктів називати не треба. Наприклад, повне нетипізоване ім’я для об’єкта server таке: server.ailab.computer.lviv.tech_university.
Аналогічно до того, як під час роботи з файловою системою визначено поточний каталог, під час роботи з eDirectory треба брати до уваги місце (контейнер), щодо якого визначають відносні імена. Адресу такого контейнера називають контекстом. Наприклад, контекстом для користувача vcoval є ailab.computer.lviv.tech_university.
Поточний контекст змінюють спеціальною командою CX; її аргументом стає адреса певного контейнера, який і стає поточним.
Використання крапок у позначенні контексту таке: крапка всередині імені розділяє частини; крапка спочатку (ліворуч) означає, що треба ігнорувати поточний контекст і шукати з кореня дерева. Наприклад, .boston.tech_univ свідчить про те, що треба визначити контекст, починаючи з кореня. У кінці імені (праворуч) може бути декілька крапок. Кожна з них переміщує на один контейнер уверх. Наприклад, якщо поточний контекст ailab.computer.lviv.tech_univ, то команда cx boston.. змінить контекст на boston.tech_univ.
Імена деяких об’єктів повинні бути унікальними в межах мережі (файлові сервери та сервери друкування). Це пов’язано з роботою протоколу SAP (Service advertisement protocol).
Схема Netware Directory database та керування нею
База даних eDirectory, як і будь-яка інша база даних, має схему. Схема eDirectory містить правила, які використовуються під час створення об’єктів eDirectory, опису їхніх властивостей, виконання всіх операцій з eDirectory. Для поліпшення продуктивності схему eDirectory зберігають на кожному сервері Netware.
Визначення схеми передбачає таке:
класи об’єктів визначають певний тип об’єкта та інкапсулюють його властивості;
типи властивостей (для кожного об’єкта класу визначають перелік його властивостей);
синтаксис властивостей (визначають правила запису значення властивості);
кожен об’єкт eDirectory належить до певного класу, від чого залежать його властивості.
Клас визначають за такими компонентами:
Structure rules – залежності між об’єктами в дереві. Правила називання (Naming properties), правила вкладення об’єкта в контейнер (Containment Class);
Super classes - суперклас для заданого класу. Через визначення супекласів у схемі eDirectory описують використання одних класів для побудови інших;
Mandatory properties – обов’язкові властивості об’єкта;
Optional properties – необов’язкові властивості об’єкта;
Object class flags – прапорці класів. Визначають, наприклад, що за даний клас відповідає контейнерам, поточний статус, заборону знищення.
Нові типи об’єктів запроваджують шляхом визначення нового класу.Для роботи зі схемою використовують утиліту Schema Manager. Функції утіліти: перегляд об’єктів та властивостей, розширення схеми, створення нових класів і властивостей; додавання властивостей до наявних класів, звіти про стан вибраного класу.
Керування доступом до об'єктів eDirectory
Система обмежень доступу до об'єктів eDirectory розділяє всі права доступу на дві групи:
Права на об’єкти;
Права на властивості
Права на об'єкти задають обмеження доступу до об'єкта як єдиного цілого. Об'єкт можна створювати, знищувати, перейменовувати, однак немає доступу до його конкретних властивостей. Права на властивості задають для кожної властивості об'єкта окремо. Вони дають змогу читати значення властивості, змінювати його, шукати. Якщо якомусь об'єкту (наприклад, користувачу) присвоєно якесь право доступу до іншого об'єкта (наприклад, тому), то перший об'єкт (користувача) називають довірителем (довіреною особою, trustee) другого об'єкта. Головні права доступу наведені у таблицях 6. 8., 6.9.
Таблиця 6.8. Права на об’єкти
Позначка |
Назва |
Зміст права |
S |
Supervise - адміністрування |
Дає всі права на об'єкт та його властивості. Право адміністрування може бути блоковане за допомогою IRF нижче того місця дерева, де його виділено |
B |
Browse – перегляд |
Право бачити об'єкт у дереві. Якщо триває шукання об'єкта, це право дає змогу знаходити об'єкт |
C |
Create - створення |
Право створювати новий об'єкт у межах заданого контейнерного об'єкта. |
D |
Delete - знищення |
Дає змогу знищити об'єкт з дерева каталогів. Контейнерний об'єкт можна знищити, якщо попередньо знищити всі його кінцеві об'єкти. |
R |
Rename - перейменування |
Дає змогу змінювати ім’я об’єкта
|
Таблиця 6.9. Права на властивості
Позначка |
Назва |
Зміст права |
S |
Supervise - адміністрування |
Всі права на властивість. Це право може бути блоковане IRF на нижчому рівні дерева |
C |
Compare – порівняння |
Дає змогу порівнювати довільне значення зі значенням властивості. Не забезпечує змоги бачити значення властивості |
R |
Read - читання |
Дає змогу читати значення властивості. Передбачає право “Сompare” |
W |
Write - записування |
Дає змогу додавати, змінювати або знищувати значення у властивостях. Це право передбачає право “Add or delete self ” та еквівалентно праву “Supervise” |
A |
Add or delete self – додавання або знищення свого об’єкту |
Дає змогу додавати або знищувати себе як частину властивості. Діє в таких списках, як списки членів групи. Інші частини списків змінювати не можна |
Кожен об’єкт має серед властивостей компоненту, яку називають Access Control List(ACL). ACL - це список об'єктів-довірених осіб цього об'єкта з зазначенням їхніх прав. Приклад ACL показано на рис. 6.18.
Trustees of this object: student (Довірителі об'єкту: студент ) |
||
property, rights, trustee (властивість, права, довірителі.) |
||
[All properties right] |
[ R ] |
another_student |
[Object rights] |
[ R ] |
another_student |
[All properties rights] |
[CRWAS] |
admin |
City |
[CRWA ] |
a_student |
Рис. 6.18. Приклад ACL
З метою спростити призначення прав виділено такі дві групи прав: усі права на властивості та всі права на об'єкт. Виділені права позначають їхньою першою літерою. Якщо право не виділене, то відповідної літери немає. У третій колонці рис. 6.18 наведено об'єкти, що мають ці права.
Кожному об'єкту на рівні контейнера або директорії можна бути виділити певні права. В цьому випадку ці права успадковують усі для всіх об'єкти цього контейнера або всі вкладені директорії. Для обмеженого успадкування прав використовують фільтр наслідуваних прав (Inherited Rights Filter IRF), тобто список прав, для яких треба обмежити успадкування вниз по дереву. Приклад визначення IRF зображено на рис. 6.19.
Inherited rights filters (Фільтр успадкованих прав) |
|
[Object rights] |
[CR A ] |
City |
[CRWA ] |
Рис. 6.19. Приклад фільтра успадкованих прав.
У лівій частині списку фільтрів успадкованих прав зазначено всі права, на які задано фільтри, у правій частині в квадратних дужках – усі права, які успадковують. Розглянемо приклад успадкування прав та використання фільтрів успадкованих прав (рис. 6.20). Користувачу Ніку на рівні контейнера SALES виділено набір прав на контейнер [ BCDR]. У цьому списку немає права S. Такі права користувач Нік автоматично успадковує на всі вкладені у контейнер об'єкти: профайл MANAGEMENT, групу ACCOUNTING, відображення каталогу SPREADSHEET. Водночас, для об'єкта SPREADSHEET задано IRF [SB ]. Тому користувач Нік для цього об'єкта має в ефективних правах тільки [ B ]. Для групи ACCOUNTING взагалі задано порожній фільтр успадкування. Тому Нік для цієї групи ніяких прав не успадковує.
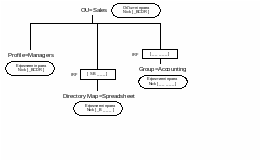
Рис. 6.20 Приклад успадкування та фільтрування прав.
Кожен об’єкт-користувач за правами може бути прирівняний до іншого об'єкта. Однією з властивостей об'єкта-користувача є список, який називають “еквівалентність прав” (security equivalence). У цьому списку задані інші об'єкти (користувачі, групи користувачів, посадові особи), які за правами еквівалентні правам цього користувача. Присвоєння прав через список еквівалентності - це найшвидший спосіб присвоєння прав користувачу, що не потребує глибокого обдумування деталей прав доступу; його використовують для тимчасового присвоєння прав. Вислідні права користувача, які формуються як комбінація прав ACL, успадкованих прав, прав, присвоєних через еквівалентність, називають ефективними правами.
Проектування eDirectory
Проектування eDirectory має на меті ефективну організацію ресурсів мережі, забезпечення можливостей її постійного розвитку, зручність адміністрування. Правильно спроектована eDirectory ліпше працює, у ній виникає менше помилок, і в цілому вона дешевша у підтримці. Під час проектування не можна просто скопіювати організаційну структуру підприємства в eDirectory, оскільки потрібно враховувати реальне розташування обладнання та вимоги доступу до нього. Наприклад, нехай принтер розміщено в одному з відділів, проте ним користуються декілька інших відділів. Тоді ліпше розмістити об’єкт „Принтер” у контейнері, спільному для всіх відділів. Перед початком інсталювання eDirectory треба розробити угоду про іменування об’єктів, схему дерева та стратегію його оновлення.
Проектування eDirectory можна розділити на такі етапи:
збирання документів про компанію;
проектування верхніх рівнів дерева;
проектування нижніх рівнів дерева.
Під час збирання документів вивчають та складають такі документи:
карту регіональної мережі з зазначенням маршрутизаторів, каналів, перепускних здатностей, окремих локальних мереж, з'єднаних цими каналами; схему кампусної мережі;
список ресурсів, серверів, робочих станцій, принтерів. Кожен ресурс записують у таблицю з зазначенням місця розміщення (відділу, організації);
організаційну структуру підприємства.
Проектування верхніх рівнів дерева враховує териториальний розподіл компанії, а також перепускну здатність каналів зв'язку, яким з'єднано окремі підрозділи. У цьому разі система має вигляд піраміди. Це означає, що на кожному наступному рівні відбувається поділ на дві-три гілки. Альтернативою є пласка система, в якій на одному з рівнів виникає розгалуження на багато гілок. У такій системі бувають проблеми з підтримкою реплік, вона незручна для адміністрування.
Окремий випадок – проектування eDirectory для невеликої фірми. Фірму вважають невеликою, якщо вона має до 1000 об’єктів та використовує надійні й високошвидкісні канали зв’язку. Для такої мережі ліпше:
зберігати базу даних в одному розділі;
мати тільки одне дерево каталогів та один об”єкт типу ‘організація’ у ньому.
Якщо фірма більша за розмірами або ж має повільні чи ненадійні канали зв’язку, то її ліпше розділити на частини, з’єднані цим каналами. Кожна частина повинна мати свої сервери eDirectory, де зберігатиметься інформація про локальні об’єкти. Якщо в кампусній мережі декілька будинків з’єднані повільними каналами, то треба розділити eDirectory на частини, які відповідають цим будинкам. Для ресурсів, об'єднаних локальною мережею, виділяють нижні рівні дерева. Структура дерева на нижніх рівнях відповідає організаційній структурі підприємства. Таке дерево легко перебудувати у випадку зміни структури.
3.5. Служба Active Directory
Служба каталогів Active Directory (AD) є складовою частиною ОС Windows у її серверних варіантах. Вона замінила застарілу концепцію доменних архітектур і покликана забезпечити роботу ОС Windows у великих корпоративних мережах. Подібно до інших СК AD формує каталог мережевих об’єктів; AD сумісна зі стандартом X.500 та протоколом LDAP. Cлужбу каталогів AD було запроваджено у Windows 2000.
Інформація про мережеві ресурси згрупована у вигляді дерева. Для сумісності з доменною архітектурою розробники Microsoft вирішили сумістити структуру дерева AD зі структурою дерева доменів DNS. Домени верхнього рівня AD та DNS співпадають. Але реалізація обслуговування користувачів імен в цих двох службах різна. Для визначення адреси контролера домена AD використовує DNS. На рис. 6.21 показано приклад дерева доменів AD. Дерево доменів – це сукупність доменів, що об’єднані відношеннями довіри та належать до неперервного простору імен.
У мережі може бути декілька дерев, які утворюють ліс. У цьому випадку відношення довіри між ними налагоджуються на рівні кореневих доменів з використанням Cerberos.
У Windows NT 4 інформація про користувачів домену зберігалася в базі даних SAM, яка становила частину системного реєстру. Тому можливості масштабування були обмежені можливістю масштабування реєстру. В AD функції SAM переймає DIT (Directory Information Tree). Для збереження даних застосовують процесор даних Jet, який діє у продукті Exchange Server. DIT зберігається у файлі ntds.dit. Цей файл копіюють усі сервери – контролери домену.
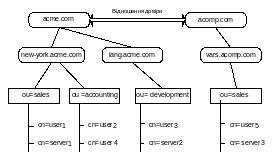
Рис. 6.21. Приклад дерева доменів AD
Однією з важливих служб AD є загальний інформаційний каталог Global Catalog. Цей каталог зберігає інформацію про наявні об’єкти БД AD та надає змогу швидкого пошуку потрібної інформації. Дані в каталогу зберігаються у вигляді окремого файлу-індексу, так що в разі звертання до каталогу не потрібно звертатися до контролера домену. У випадку встановлення системи сервером Global Catalog стає першим встановлений контролером домену.
AD дає змогу організовувати та групувати мережеві ресурси всередині DNS-вузла з використанням контейнера OU (підрозділ). Якщо призначити певні права доступу до об’єктів OU, то ці права можуть успадкувати всі вкладені об’єкти.
Дерево створюють та модифікують з використанням MMC (модуль Active Directory users and computers).
В операційній системі Windows NT 4 були два типи груп: локальні та глобальні. Ці групи могли містити тільки користувачів та були призначені винятково для контролювання доступу.
В AD збережено ці типи груп, однак додано ще універсальні групи (universal group). Ці групи працюють якщо в мережі не використовують резервні контролери доменів (BDC), успадковані від попередньої системи NT4 (тобто система працює винятково на наступних версіях Windows). Універсальні групи можуть складатися з глобальних груп та інших універсальних груп довільного домену лісу. Крім того, в групу AD допустимо вкладати не тільки об’єкти-користувачі, а й об’єкти- комп’ютери.
В AD змінено і механізм реплікації. В NT 4 головна доступна для запису копія БД SAM домену зберігається тільки на головному контролері домену. У наступних версіях Windows доступна до запису копія DIT міститься на кожному контролері. Система відстежує зміни, присвоюючи кожній такій зміні номер USN (Update sequence number) та часову позначку. В процесі реплікації між контролерами передається не вся база даних, а тільки інформація про зміни. Якщо надійшла інформація про зміни одного й того ж об’єкта, то контролер порівнює часові позначки та ухвалює рішення щодо змін. Такий механізм реплікації забезпечує мінімум інформації в разі передавання мережею та високі параметри продуктивності контролерів.
Якщо в NT4 були тільки головні те резервні контролери доменів, які надавали один і той же сервіс з автентифікації користувачів, то в AD контролери доменів виконують значно більше функцій. Один сервер може виконувати декілька функцій. Визначено такі функції:
Головний контролер домену (PDC). У мережах, де є станції з NT 4, надає сервіс головного контролера.
Контролер пулу відносних ідентифікаторів (RID Pool). Відносний ідентифікатор (relative identifier (RID)) є частиною ідентифікатора об’єкта. Контролер пулу відносних ідентифікаторів координує присвоєння унікальних ідентифікаторів контролерами системи.
Контролер інфраструктури. Підтримує узгодженість даних з загального каталогу, конфігурації вузлів та налаштувань реплікації.
Контролер назв доменів гарантує унікальність доменних імен.
Контролер схеми визначає контролер, на якому дозволено вносити зміни у схему БД AD.
Порівняємо AD з eDirectory. В AD контейнери не можуть бути принципалами безпеки. eDirectory дає змогу призначати права доступу на рівні контейнерів. Наприклад, контейнер ‘відділ розробки’ може отримати права доступ на певний прінтер”. В цьому випадку всі користувачі цього відділу зможуить користуватися ним.
В AD всі назви об’єктів повинні бути унікальними незалежно від місця їхнього розташування у дереві. В eDirectory ім’я об’єкта повинно бути унікальним тільки в межах свого безпосереднього контейнера.
У eDirectory успадкування прав динамічне: якщо користувачу призначене право доступу до контейнера, то оновлюється тільки ACL для цього контейнера. Водночас у разі перевіряння прав доступу враховують права у всіх контейнерах. В AD успадкування прав статичне: якщо змінюються права доступу до контейнера, то змінюються ACL для всіх вкладених об’єктів контейнера, що для великого та складного дерева може потребувати багато ресурсів.
Контролер AD може бути контролером тільки одного домену, тоді як сервер eDirectory може зберігати репліки декількох розділів. Отже потенційно за однакової кількості серверів NDS є стійкішою та надійнішою.
Значним недоліком AD є також її орієнтація на структуру доменів DNS, що обмежує користувачів. eDirectory не має таких обмежень, і дерево каталогів можна, наприклад, створювати згідно з організаційною структурою підприємства, філії якого розташовані в різних зонах DNS.
Сьогодні AD підтримує тільки ОС Windows, тоді як eDirectory – багато систем.
3.6. Cлужби NIS та NIS+
Мережеві інформаційні служби NIS та NIS+ (network Information Service) створені для роботи у середовищі UNIX.
NIS – це фактично доменна інформаційна служба, яка дає змогу об’єднати декілька серверів UNIX в один домен та використовувати для них один набір керівних файлів (etc/passwd, etc/group/ etc/hosts, etc/networks та ін.). Завдяки цьому користувач може автентифікуватися один раз – у домені.
У мережі є головний север NIS та декілька резервних, що працюють у режимі читання системних файлів. БД домену періодично копіюють на резервні сервери. Кожен домен адміністрований окремо. NIS також дає змогу об’єднувати користувачів, їхні групи, та гости у мережеві групи, та адмініструвати таку групу як одне ціле. Уся інформація в NIS передається відкрито, без шифрування. Таку мережу можна зламати з використанням фальшивого сервера NIS.
Служба NIS+ набагато ліпша ніж NIS, однак несумісна з нею. Вона дає змогу:
підтримувати ієрархію доменів та довірчі відношення між ними;
відмовитися від прямого використання системних файлів;
керувати репліками та застосовувати ефективніші механізми реплікації;
автентифікувати об’єкти та шифрувати.
На жаль, цю службу підтримують тільки продукти фірми Sun Microsystems, вона не має виходу на клієнтські комп’ютери.
Питання до самоконтролю
1. Дайте визначення служби каталогів
2. Які завдання у комп’ютерній мережі вирішує служба каталогів?
3. Перерахуйте стандарти служб каталогів.
4. Структура та принципи функціювання СК LDAP.
5. Спроектуйте дерево каталогу eDirectory для Вашої організації.
6. Що таке контекст в eDirectory і як його змінити ?
7. Які права доступу до об’єктів визначені в eDirectory ?
8. Яким чином в СК Active Directory відображена DNS ?
Лекція 4. Віртуалізація платформ та хмаркові сервіси у комп’ютерних мережах
4.1. Загальна характеристика та причини віртуалізації платформ
Якщо віртуалізація – це використання абстрактних ресурсів мережі замість та за рахунок використання її фізичних ресурсів, то віртуалізація платформ – це емуляція потрібної апаратно-програмної платформи засобами інших, реальних платформ, розгорнутих на серверах мережі.
У випадку віртуалізації платформ серверна ОС обслуговує кілька клієнтських, віртуальних машин (ВМ), які виглядають для цієї ОС як застосування, що споживають її ресурси. Концепція віртуальних машин була вперше розроблена фірмою IBM більш як сорок років тому. Віртуальні машини (тоді вони називалися “псевдо-машинами”) розгорталися на великих комп’ютерах і спеціальна програма призначала їм ресурси та ізолювала такі машини одна від іншої. Віртуалізація платформ на сьогодні широко застосовується в IT – згідно з дослідженнями фірми Gartner на віртуальних машинах виконується більш як 70% всіх серверних обчислень для процесорів в архітектурі команд x86.
Розглянемо основні причини та переваги використання віртуальних машин.
Скорочення часу поновлення системи. У випадку аварії, вірусної інфекції або спотворення системи зловмисниками пробувати відновити систему звичайним шляхом вимагає значних зусиль та триває неприпустимо довго. Набагато ефективніше мати копії працюючої та правильно налаштованої системи у вигляді файлів віртуальних машин. При цьому поновлення системи зводиться до копіювання файлу віртуальної машини та її запуску, що триває декілька хвилин.
Скорочення часу тестування. Підчас розробки програмного забезпечення деякі дефекти проявляються тільки у специфічних комбінаціях апаратного, програмного забезпечення, наявних налаштувань та даних. Для тестування такого дефекту необхідно створити конфігурацію, для якої цей дефект було виявлено. Створення потрібної тестової конфігурації може займати довгий час та суттєво впливає на трудомісткість тестування, особливо якщо після тестування середовище треба відновлювати з нуля, а тестувати дефект потрібно декілька разів. У цьому випадку доцільно створити тестове середовище у вигляді віртуальної машини та використовувати копії цієї машини для кожного наступного тестування.
Швидке застарівання апаратного забезпечення. Термін життя апаратного забезпечення в середньому складає декілька років. Статистика каже, що кількість збоїв різко зростає після чотирьох років роботи комп’ютерної системи. Багато інженерів визначають час використання комп’ютера як час його гарантійного обслуговування виробником. Однак, ці обмеження не стосуються віртуальних машин. Віртуальна машина працює якщо працює сервер на якому вона розміщена.
Використання застарілого програмного забезпечення. Компанії нерідко використовують програмне забезпечення, яке було розроблене багато десятків років тому, для якого немає адекватної документації чи вихідного коду та яке працює на застарілих версіях операційних систем та апаратних платформ. При цьому створення нової аналогічної програми занадто дорого і не розглядається як альтернатива. У цьому випадку стару програму запускають у режимі емуляції старої програмно- апаратної системи на віртуальній машині.
Ефективніше використання ресурсів. Розгортання декількох віртуальних машин на одному сервері порівняно з використанням декількох серверів економить кошти завдяки ефективнішому використанню ресурсів базового сервера.
Краща масштабованість. Додавати нові віртуальні сервера набагато дешевше та швидше ніж додавати реальні сервера.
4.2. Технології віртуалізації платформ та їх застосування
Віртуалізація на локальній ОС (Guest OS/Host OS)
Це класичне рішення віртуалізації, яке полягає у використанні ресурсів локального комп’ютера та його операційної системи для підтримки віртуальних машин (рис. 6.22). При цьому такі віртуальні машини сприймаються локальною ОС як застосування, яким потрібно виділити ресурси. Для запуску ВМ потрібно мати файл машини та файл визначення.
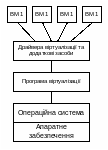
Рис. 6.22. Структура системи віртуалізації на локальній ОС
Перевагою систем на базі локальної ОС є дешевизна (більшість реалізацій таких систем – безкоштовні). Головним недоліком є різке зростання часу виконання дискових операцій порівняно з операціями, ініційованими локальною ОС. Для інших типів операцій такої різниці не спостерігають.
Прикладами реалізації такого підходу є продукти VMWare Server, Oracle Virtual Box. Рішення віртуалізації на базі локальної ОС доцільно використовувати для тестування, навчання, у невеликих лабораторіях та дома. Системи віртуалізації на базі локальної ОС класифікують як гіпервізори другого типу згідно з класифікацію розробленою Попеком та Голдбергом (Gerald J. Popek and Robert P. Goldberg) у статті "Formal Requirements for Virtualizable Third Generation Architectures".
Використання гіпервізорів (hypervisor)
У гіпервізорному підході не використовують ОС, що виконує програму віртуалізації, а будують сервер з самого початку для підтримки віртуалізації. Можна сказати, що у цьому підході програма віртуалізації є операційною системою (рис. 6.23).
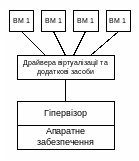
Рис. 6.23. Структура гіпервізорної системи віртуалізації
Гіпервізорні ОС не мають таких проблем з продуктивністю як системи, що базуються на локальних ОС та використовуються для промислових застосувань.
Прикладами реалізації цього підходу є Microsoft Hyper-V, Citrix Xen, VMWare ESX/ESXi. Гіпервізорні системи використовують у промислових системах, де вимоги до швидкодії є важливішими, ніж цінові обмеження. Такі системи визначають як гіпервізори першого типу.
Емуляція платформ
Емуляція передбачає можливість запропонувати певний тип програмного або апаратного забезпечення незалежно від особливостей базової системи. Аналогічно до системи віртуалізації на локальній ОС, програма емуляції працює як застосування під керуванням локальної ОС, але при цьому емулюють тільки одну визначену платформу (рис. 6.24).
Прикладом є продукт Microsoft Virtual PC та Virtual Server, що емулюють системи Windows.
Рішення віртуалізації на рівні ядра (Linux)
У цьому рішенні кожна віртуальна машина використовує свою копію ядра, незалежно від версії ядра базового сервера. Прикладами такого підходу є KVM (Linux Kernel Virtual machine), user-mode Linux.
Рис. 6. 24. Структура системи емуляції
Альтернативою є спільне використання ядра, яке використовує унікальну властивість Linux спільно використовувати ядро з іншими процесами системи. При цьому використовується команда chroot. Ця команда міняє кореневу файлову систему для процесу та ізолює його, так що він вважає, що виконується на окремій машині.
Перевагами використання підходу на основі chroot, крім кращого захисту є висока швидкодія системи – усі процеси виконуються з швидкостями локальних процесів. Більш того, такий підхід дає змогу розгорнути набагато більше віртуальних машин, порівняно з іншими підходами. Недоліком є те, що процеси у віртуальних машинах мають бути сумісні з версією базової ОС (Linux).
Використання контейнерів замість гіпервізорів
Недоліками гіпервізорних підходів є значне використання ресурсів на виконання рівня віртуалізації та окремих копій ОС на віртуальних машинах. За рахунок цього знижується швидкодія. Принципово інший підхід реалізовано у проекті Docker на базі машин з ОС Linux. Такий підхід отримав назву контейнерного. В контейнерному підході застосування та усі його залежні файли групують у контейнер. Такий контейнер визначає певне ізольоване середовище функціювання, яке виконується окремо від інших. Сформовані контейнери завантажують у репозиторій. Для виконання контейнер отримують з репозиторію та запускають (рис. 6.25).
Таким чином, контейнери не виконують функцій віртуальної ОС і тому вимагають менше ресурсів. Контейнери ідеально пристовані для паралельного виконання, кластеризації. Деякі великі компанії інтенсивно використовують контейнери, зокрема Google щотижня запускає більше двох мілліардів контейнерів. Недоліками є орієнтація на платформу Linux, слабкий захист, недостаньо пророблені засоби керування.
4.3. Хмаркові сервіси – визначення та властивості
Хмаркові обчислення – це новітня парадигма організації комп’ютингу, яка спирається на технології віртуалізації. Різноманітні визначення цієї парадигми підкреслюють такі її властивості – надання мережевих ресурсів як послуг, економічні аспекти, масштабованість та ін. Наведемо визначення зроблене Фостером (Foster).
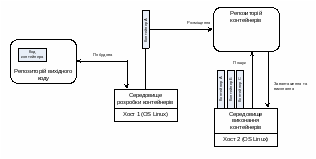
Рис. 6.25. Принципи використання контейнерів у проекті Docker
“Хмарковий комп’ютинг – це парадигма глобального комп’ютингу, в якій множина абстрагованих, віртуалізованих, динамічно масштабованих, керованих ресурсів у вигляді обчислювальних потужностей, пам’яті, платформ та сервісів надаються за запитом зовнішніх користувачів через Інтернет”
Таким чином, головні властивості хмаркового комп’ютингу такі:
ресурси (апаратне та програмне забезпечення, пам’ять) надаються користувачу у вигляді сервісів;
базуються на віртуалізації та динамічно масштабуються за запитом;
доступ до сервісів надається через Інтернет з використанням спеціалізованого API або через веб-переглядач.
Ці властивості проілюстровані на рис. 6.26 [12]
4.4. Архітектури хмаркових сервісів
Визначено три архітектурні рівні хмаркового комп’ютингу (рис. 6.27):
інфраструктура як сервіс (IaaS – Infrastructure as service);
платформа як сервіс (PaaS – Platform as Service);
програма як сервіс (SaaS - Software as Service)
Провайдери IaaS надають такі комп’ютерні ресурси як обчислювальні потужності або пам’ять у вигляді сервісів. Найчастіше ці ресурси подані у формі віртуалізованих апаратних ресурсів. Користувачі мають доступ до цих ресурсів через визначені сервісні інтерфейси. Прикладами таких сервісів є служби фірми Amazon Elastic Computer Cloud – для обчислювальних ресурсів та Simple Storage Service – для збереження даних.
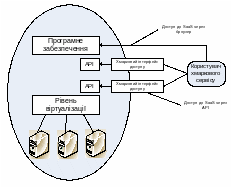
Рис. 6.26. Схема організації хмаркового комп’ютингу
Рівень PaaS розташовано між рівнями інфраструктури та програм. Головними споживачами послуг PaaS є розробники програмного забезпечення. Вони можуть створювати та тестувати програмне забезпечення для потрібних платформ не займаючись встановленням на налаштуванням відповідної інфрастуктури. Розробники завантажують розроблену програму на сервіс PaaS потрібної платформи та тестують його. При цьому система виконує автоматичне масштабування потужностей відповідно до потреб замовника. Прикладом сервісу PaaS є Google App Engine, який дає змогу виконувати програми на інфраструктурі фірми Google.
Послуги рівня SaaS надаються як можливість користування визначеними програмами з оплатою за кожну годину користування. З точки зору користувача перевагою використання такого сервісу є відсутність необхідності встановлювати та адмініструвати програмне забезпечення, а також відсутність одноразової передоплати за програму. Програмні послуги у парадигмі SaaS надаються фірмами Microsoft (Office 356), Google (Google Docs) та іншими.
Головні ризики використання хмаркових сервісів пов’язані з доступністю, безпекою, швидкодією, прив’якою до певного провайдера, складністю інтеграції з існуючими системами.
4.5. Різновиди хмаркових сервісів та їх сфери застосування
Хмаркові системи класифікують за різними ознаками. За ознакою власника системи розрізняють загальнодоступні (публічні) та приватні хмаркові системи. Загальнодоступні системи підтримуються великими провайдерами (такими як, наприклад, Google та Amazon) для довільних клієнтів. Оплата за послуги здійснюється за фактом їх використання. Публічні хмаркові сервіси працюють з клієнтами ринків B2B та B2C.
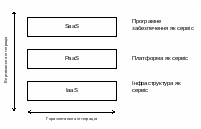
Рис. 6.27. Архітектурні рівні хмаркового комп’ютингу
Компанії, що бажають здійснювати повний контроль над своєю інфраструктурою можуть побудувати власні, приватні хмаркові сервіси, що працюють у межах компанії. Перевагою таких сервісів є використання усіх можливостей віртуалізації при збереженні повного контролю над своєю системою.
За способами сумісного використання хмаркових сервісів розрізняють гібридні хмари та федерацію хмар. Гібридні хмари – це сумісне використання приватних та публічних сервісів так, що одні застосування виконуються на приватній хмарі, а інші – на публічній. Як правило, таке використання додає новий рівень складності в адміністрування та підтримку системи. Термін “федерація хмар” використовується, коли багато хмаркових сервісів (як публічних, так і приватних) співпрацюють та обмінюються інформацією та послугами.
Хмарковий комп’ютинг має багато спільного з грід-комп’ютингом. Історично грід-комп’ютинг лежить в основі хмаркового та створює його інфраструктуру. Але на відміну від грід, хмарковий комп’ютинг надає ресурси та сервіси на вищому рівні абстракції і може розглядатися як розвиток грід-комп’ютингу.
Питання до самоконтролю
1. Назвіть варіанти застосування технологій віртуалізації платформ.
2. В яких програмних засобах реалізовано віртуалізацію на рівні локальної ОС?
3. В чому відмінності гіпервізорного вирішення від віртуалізації на рівні локальної ОС ?
4.В чому відмінності емуляції платформ від гіпервізорної віртуалізації ?
5. В чому відмінності використання контейнерів від гіпервізорної віртуалізації ?
6. Назвіть рівні хмаркового комп’ютингу та їх відмінності.
7. Наведить приклади сервісів SaaS.
8. Що таке гібридна хмара та федерація хмар ?
Лабораторна робота № 1
Тема: «Основи віртуальних машин. VirtualBox » Мета роботи: сформувати навички та вміння встановлювати операційну систему Windows XP на віртуальну машину Virtual PC Console, а також здійснювати настройку її параметрів. Теоретичні відомості
Технологія віртуальних машин дозволяє запускати на одному комп'ютері кілька різних операційних систем одночасно, або дозволяє оперативно переходити від роботи в середовищі однієї системи, до роботи в іншій, без перезавантаження комп'ютера. Причому, працюючи в середовищі, «гостьовий» операційної системи практично відсутні обмеження у використанні її можливостей. Тобто, віртуально проводиться робота з реальною системою. І при цьому є можливість виконувати в такій системі різні маловивчені або потенційно небезпечні для неї операції. Зростаючою популярністю віртуальних машин можна пояснити такими причинами:
• поява великої кількості різних операційних систем (ОС), пред'являють специфічні потреби до параметрів використовуваних апаратних компонентів комп'ютера; • великими витратами на адміністрування і складністю обслуговування комп'ютерів, на яких встановлено кілька різних операційних систем (в плані забезпечення необхідної надійності і безпеки роботи).
Сучасна віртуальна машина дозволяє приховати від встановленої на ній операційної системи деякі параметри фізичних пристроїв комп'ютера і тим самим забезпечити взаємну незалежність ОС та встановленого обладнання. Такий підхід надає користувачам (або адміністраторам обчислювальних систем) цілий ряд переваг. До них зокрема відносяться: • можливість встановлення на одному комп'ютері декількох ОС без необхідності відповідного конфігурування фізичних жорстких дисків; • робота з декількома ОС одночасно з можливістю динамічного перемикання між ними без перезавантаження системи; • скорочення часу зміни складу встановлених ОС; • ізоляція реального обладнання від небажаного впливу програмного забезпечення, що працює в середовищі віртуальної машини; • можливість моделювання обчислювальної мережі на єдиному автономному комп'ютері. Віртуальні машини дозволяють вирішувати цілий ряд завдань обслуговування обчислювальних систем. Таких як:
- освоєння нової ОС; - запуск додатків, призначених для роботи в середовищі конкретної ОС; - тестування однієї програми під управлінням різних ОС; - установка і видалення оціночних або демонстраційних версій програм; - тестування потенційно небезпечних додатків, щодо яких є підозра на вірусне зараження; - управління правами доступу користувачів до даних і програм в межах віртуальної машини. З точки зору користувача, віртуальна машина (ВМ) - це конкретний екземпляр віртуального обчислювального середовища (віртуального комп'ютера), створеного за допомогою спеціального програмного інструмента. Власне, інструмент, для створення ВМ (її іноді називають додатком віртуальних машин) це звичайна програма, встановлювана, як і будь яка інша, на конкретну реальну операційну систему. Ця реальна ОС іменується «хазяйською», або хостовою ОС (від англійського терміну host «головний», «базовий», «ведучий»). Усі завдання з управління віртуальними машинами вирішує спеціальний модуль у складі додатка ВМ монітор віртуальних машин (МВМ). Монітор відіграє роль посередника у всіх взаємодіях між віртуальними машинами і базовим обладнанням, підтримуючи виконання всіх створених ВМ на єдиній апаратній платформі і забезпечуючи їх надійну ізоляцію.
Користувач не має безпосереднього доступу до МВМ. У більшості програмних продуктів йому надається лише графічний інтерфейс для створення і налаштування віртуальних машин (Малюнок 1). Цей інтерфейс зазвичай називають консоллю віртуальних машин. «Всередині» віртуальної машини користувач встановлює, як і на реальному комп'ютері, потрібну йому операційну систему. Така ОС, що належить конкретній ВМ, називається гостьовою (guest OS). Перелік підтримуваних гостьових ОС є однією з найбільш важливих характеристик віртуальної машини. Найбільш потужні з сучасних віртуальних машин забезпечують підтримку близько десятка популярних версій операційних систем з сімейств Windows, Linux і Mac OS.
Меню управління віртуальною машиною в програмі VirtualBox У VirtualBox консоль розділена на 2 панелі. Ліва панель нагадує диспетчер пристроїв. Права панель містить набори вкладок, відповідні активному пункту лівій панелі. У нижній частині правої панелі - інтерактивна довідка. Розберемо кожну вкладку окремо. Вкладка "Загальні. Основні" містить значення основних параметрів нашої віртуальної машини.
Вкладка "Загальні. Додатково" містить наступні параметри: «Папка для знимків» приймає значення шляхів для знимків ВМ. Знимки ВМ - це файлові знимки стану, даних диска і конфігурації ВМ в певний момент часу. На одну ВМ можна створити кілька знимків, що містять відмінні один від одного налаштування і встановлені додатки. «Загальний буфер обміну» і "Drag'n'Drop" можуть приймати чотири значення: «вимкнено», «тільки з гостьової ОС в основну», «тільки з основної ОС в гостьову», «двонаправлений», які визначають, як буде працювати буфер обміну між Вашою host-системою і віртуальною машиною. "Змінні носії інформації" можуть "запам'ятовувати зміни в процесі роботи" (стан CD \ DVD - приводів, рекомендується) або ні. «Міні тулбар» - це невелика консоль, що містить елементи управління віртуальною машиною, рекомендується використовувати в повноекранному режимі, "розташувати знизу екрану" за замовчуванням. Вкладка "Загальні. Опис" містить опис налаштувань. Вкладка "Система. Материнська плата" містить інформацію: - про розмір оперативної пам'яті; - про порядок завантаження; - про набір мікросхем, яка використовує ВМ; - про значеннях інших параметрів, описаних у інтерактивному меню.
Вкладка "Система. Процесор" містить інформацію про кількість процесорів, доступних ВМ і деяких режимах їх роботи (опис режимів в інтерактивній підказці). Вкладка "Система. Прискорення" містить інформацію про підтримку апаратної віртуалізації AMD -V або VT-x. Вкладка "Дисплей. Віддалений дисплей" дозволяє включити режим роботи ВМ як сервер віддаленого робочого столу (RDP). Вкладка "Носії" відображає образи віртуальних дисків і приводи хоста. Вкладка "Аудіо" відображає інформацію про аудіодрайверах і аудіоконтролері. Вкладка "Мережа. Адаптер 1" відображає наступну інформацію: - включення мережевого адаптера; - тип підключення; - не підключений.
NAT (Network Address Translation) забезпечує підключення до зовнішнього світу (перегляд Web, загрузки файлів і перегляду повідомлень електронної пошти в гостьовій) за допомогою мережі хоста. Мережевий міст підключає ВМ до однієї з встановлених мережевих карт та обміну мережевими пакетами безпосередньо, в обхід мережевого стека вашої основної операційної системи. Внутрішня мережа може бути використана для створення програмного забезпечення на основі такої мережі, яку бачить обрана ВМ, а не застосунок, запущений на хості або отриманий із зовнішнього світу. Віртуальний адаптер хосту може бути використаний для створення мережі, що має господаря і множину віртуальних машин, без необхідності фізичного мережевого інтерфейсу хоста. Замість цього, віртуальний мережевий інтерфейс (схожий на інтерфейс зворотнього зв'язку) створюється на хості, забезпечуючи зв'язок між віртуальними машинами і хостом. Універсальний драйвер - рідко використовуваний режим і той же загальний мережевий інтерфейс, дозволяє користувачеві вибрати драйвер, який може бути включений в VirtualBox, або розподілений у розширенні пакета. "Ім'я" використовуваного контролера. "Нерозбірливий режим" задає політику режиму даного віртуального мережевого адаптера, якщо він підключений до внутрішньої мережі, віртуального адаптера або мережному мосту, підключення кабелю. Вкладка "COM-порти. Порт1" відображає інформацію про номер порту і його підключення.
Вибір "USB" на лівій панелі дозволить підключити USB-пристрої, підключені до хосту. Вибір "Загальні папки" на лівій панелі дозволить підключити папки хоста з регульованими параметрами доступу.
Вказівки до виконання лабораторної роботи. (Зразок)
П ісля
кліка по кнопці "Створити" з'явиться
діалогове вікно
ісля
кліка по кнопці "Створити" з'явиться
діалогове вікно
Малюнок 1. Діалогове вікно створення віртуальної машини • Ім'я ВМ буде пізніше відображатися в списку ВМ, також воно буде використовуватися для імені файлу налаштувань ВМ. Корисно використати інформативні імена, наприклад , "XP_SP2". • Тип виберете зі списка операційних систем. Якщо ви хочете встановити, щось інше, що не перераховане у списку, виберіть "Other". • Версія вибирається із запропонованого списку і повинна точно відповідати наявному дистрибутиву ОС.
У наступному вікні буде пропозиція вибору розміру оперативної пам'яті, яку VirtualBox виділятиме віртуальній машині при кожному запуску. Об'єм пам'яті вказаний тут буде не доступний для хоста і виділеного гостьовій операційній системі.
Малюнок 2. Вікно для вибору розміру пам'яті
У наступному вікні необхідно підключити віртуальний жорсткий диск. При цьому можна використати існуючий віртуальний жорсткий диск для раніше створеної ВМ.
Малюнок 3. Вікно для підключення жорсткого диску для ВМ
Після вибору "Створити новий віртуальний жорсткий диск" з'явиться вікно
Малюнок 4. Вікно створення віртуального жорсткого диску
Після кліка по кнопці "Next" наступне вікно запропонує вибрати формат зберігання.

Малюнок 5. Вікно вибору формату зберігання
Рекомендується динамічний формат. Після кліка по кнопці "Next" на лівій панелі відкритого вікна "Oracle VM VirtualBox Менеджер" з'явиться ім'я нової створеної ВМ. За замовчуванням, диск ВМ буде розташовуватися в папці c: \ Users \ Ім'я користувача \ VirtualBox VMs \, де «Ім'я користувача» ім'я вашого облікового запису в Windows 7. В інших ОС все буде трохи відрізнятися. Залишаємо запропонований обсяг диску ВМ без змін або змінюємо у випадку, якщо необхідно стиснути або виділити додаткове місце. Чергове натискання Next. Машина вже готова, для запуску ВМ залишилось підключити образ завантажувального диску до приводу ВМ або вказати, що ми будемо використовувати привід оптичних дисків, якщо інсталяційний диск у вас вже є на окремому оптичному носію.
 Запуск
віртуальної машини
Запуск
віртуальної машини
Є наступні методи запуску віртуальної машини: • двічі кликнути мишею на її найменуванні в списку вікна менеджера; • вибрати її в списку вікна менеджера і натиснути кнопку "Запустити". Ця команда відкриє нове вікно з ВМ, в якому з'явиться вікно "Виберіть завантажувальний диск" і віртуальна машина завантаження операційної системи, яку ви виберете для неї.
 Малюнок
6. Вікно вибору завантажувального
диску
Далі
все буде точно так само, як при звичайному
завантаженні операційної системи.
Після
установки декількох гостьових операційних
систем отримаємо наступне вікно:
Малюнок
6. Вікно вибору завантажувального
диску
Далі
все буде точно так само, як при звичайному
завантаженні операційної системи.
Після
установки декількох гостьових операційних
систем отримаємо наступне вікно:
Малюнок 7. Вікно з заголовком "Oracle VM VirtualBox Manager" після установки декількох ВM
 Налаштування
апаратної частини віртуальної машини.
Кожну віртуальну машину можна налаштувати
з урахуванням особливостей її використання.
Кліком по кнопці "Налаштувати"
відкриваємо вікно "Імя_ВМ Налаштування
".
Налаштування
апаратної частини віртуальної машини.
Кожну віртуальну машину можна налаштувати
з урахуванням особливостей її використання.
Кліком по кнопці "Налаштувати"
відкриваємо вікно "Імя_ВМ Налаштування
".
Малюнок 8. Вікно для зміни параметрів ВМ
Завдання 1. Ознайомитися з теоретичними відомостями.
2. Створити ВМ. 3. Провести підключення жорсткого диска з вже встановленою ОS Windows 4. Завантажитися з цього диску. Для цього необхідно провести підключення жорсткого диску з вже встановленою ОС
Контрольні питання 1. Чому зростає популярність віртуальних машин? 2. Що собою являє віртуальна машина? 3. Чим відрізняються операційні системи реального комп'ютера і віртуальної машини? 4. Що міститься у лівій панелі консолі VirtualBox? 5. Як перезавантажити віртуальний комп'ютер? 6. Як працює Диспетчер завдань в гостьовій ОС?
7. Опишіть етапи створення вашої віртуальної машини. 8. Опишіть етапи підключення жорсткого диску.
Список літератури: 1. http://windows.microsoft.com 2. http://netler.ru/ikt/microsoftvirtualpc.html
Лабораторна робота №2
Тема: ОС Linux. Знайомство з операційною системою
Мета роботи: навчитися основам роботи з файловою системою Linux, керування правами доступу користувача. Дослідити зміст та призначення стандартних каталогів Linux. Практично засвоїти базові операції з ОС