20. Алгоритм процесса нормализации схем отношений
Процесс проектирования с использованием декомпозиции - процесс последовательной нормализации схем отношений, при этом каждая последующая итерация соответствует нормальной форме более высокого уровня и обладает лучшими свойствами по сравнению с предыдущей.
В теории реляционных БД выделяется последовательность:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса-Кодда (ВСNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма / форма проекции-соединения (5NF).
Алгоритм нормализации предполагает последовательную проверку БД на соответствии каждой нормальной форме. На практике, начиная с 4-ой нормальной формы плюсы нормализации заканчиваются, т.к. появляется большое количество таблиц, что приводит к снижению эффективности работы БД и повышенному потреблению памяти.
Декомпозиция должна сохранять эквивалентность схем БД при замене одной схемы на другую.
Основные свойства нормальных форм:
каждая следующая нормальная форма улучшает свойства предыдущей;
при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
21. Нормализация. Функциональная зависимость. Первая, вторая, нормальные формы
Функциональная зависимость — это связь, которая может возникнуть между сущностями, хранящимися в БД. Если сущность A функционально определяет сущность B, то такую зависимость принято обозначать следующим образом:
![]() ,
,
где A - детерминант отношения (атрибут или набор атрибутов, от которых зависит другой атрибут, если в отношении существует несколько функциональных зависимостей)
B - зависимая часть
Пример. Пусть дано отношение, которое определяет должностные оклады работников некоторого предприятия.
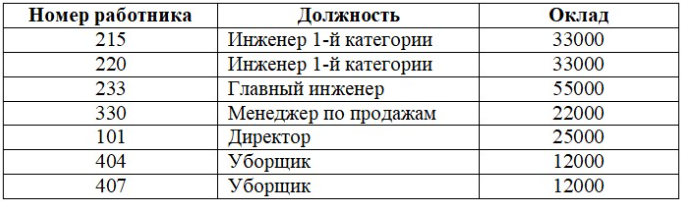
В вышеприведенной таблице оклад работника определяется должностью, которую он занимает. Если работник переходит на другую должность, то меняется и его оклад. Атрибут Должность функционально определяет атрибут Оклад.
![]()
Различают следующие степени функциональной зависимости между атрибутами:
частичная зависимость. Эта зависимость может возникать в случаях, когда таблица содержит составной ключ. Составной ключ — это ключ таблица, который состоит из нескольких атрибутов. Если ключ состоит из одного атрибута, то этот ключ является простым. При частичной зависимости один атрибут таблицы является зависимым от части ключа, т.е. от отдельного атрибута, входящего в ключ отношения;
полная зависимость. Это случай, когда между атрибутами существует зависимость друг от друга;
транзитивная зависимость. Это зависимость, когда два атрибута связаны между собой через третий атрибут. Этот третий атрибут выступает посредником;
Первая нормальная форма (1NF)
Таблицы должны соответствовать реляционной модели данных и соблюдать определенные реляционные принципы:
в таблице не должно быть дублирующих строк;
в каждой ячейке таблицы хранится атомарное значение (одно не составное значение);
в столбце хранятся данные одного типа;
отсутствуют массивы и списки в любом виде.
Таблица сотрудников в ненормализованном виде:
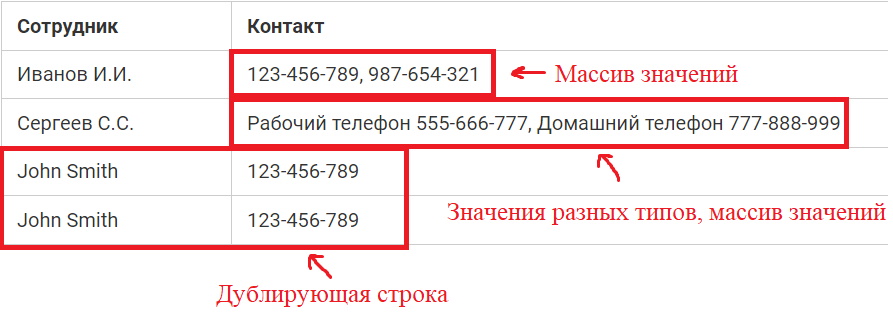
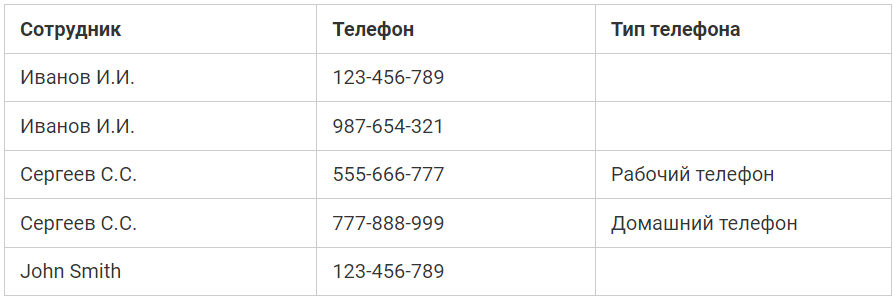
Таблица сотрудников в первой нормальной форме:
Вторая нормальная форма (2NF)
Требования ко второй нормальной форме:
таблица должна находится в 1NF;
таблица должна иметь ключ;
все неключевые столбцы таблицы должны зависеть от полного ключа (в случае, если ключ составной). Иными словами, отношение не содержит неполных функциональных зависимостей не первичных атрибутов от атрибутов первичного ключа
Таблица сотрудников в 1NF:
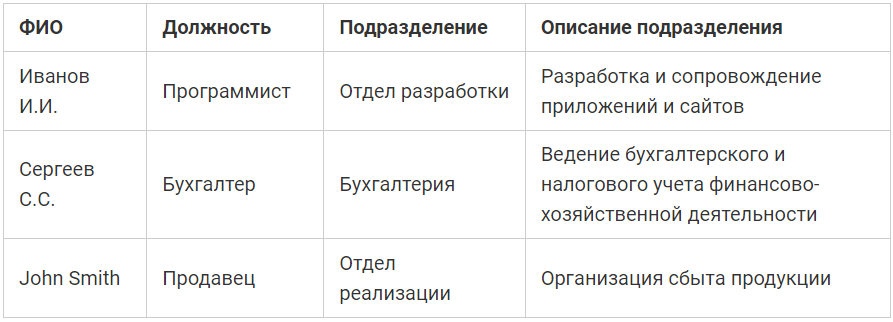
Поработав немного с предметной областью, мы выясняем, что в этой организации каждому сотруднику присваивается уникальный табельный номер, который никогда не будет изменен.
Поэтому очевидно, что для таблицы, которая будет хранить список сотрудников, первичным ключом может выступать табельный номер, зная который мы можем четко идентифицировать каждого сотрудника, т.е. каждую строку нашей таблицы. Если бы такого табельного номера у нас не было или в рамках организации он мог повторяться (например, сотрудник уволился, и спустя время его номер присвоили новому сотруднику), то для первичного ключа мы могли бы создать искусственный ключ с целочисленным типом данных, который автоматически увеличивался бы в случае добавления новых записей в таблицу. Тем самым мы бы точно также четко идентифицировали каждую строку в таблице.
Таким образом, чтобы привести эту таблицу ко второй нормальной форме, мы должны добавить в нее еще один атрибут, т.е. столбец с табельным номером.
Таблица сотрудников во второй нормальной форме с простым первичным ключом:
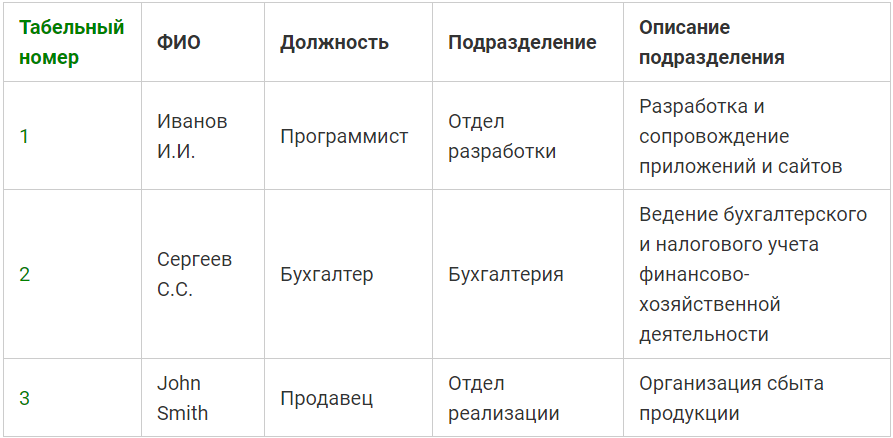
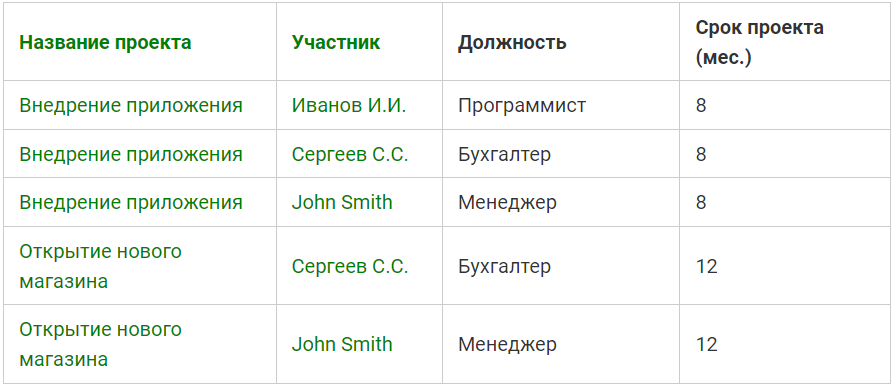
Таблица проектов организации в 1NF:
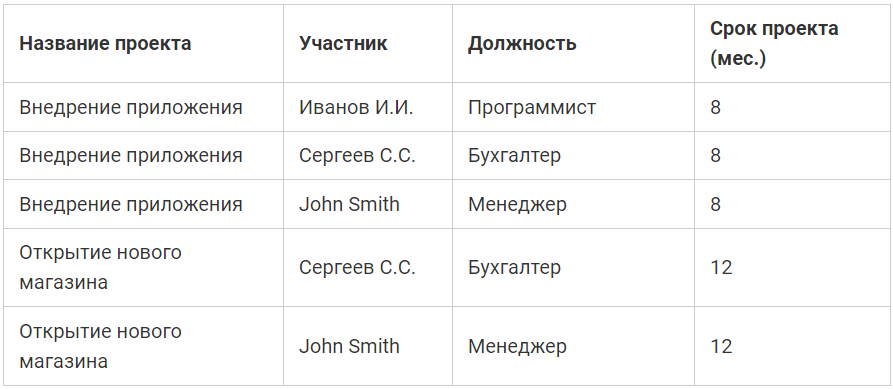
Посмотрев на эту таблицу, мы понимаем, что четко идентифицировать каждую строку мы можем только с помощью комбинации столбцов, например, «Название проекта» + «Участник», иными словами, зная «Название проекта» и «Участника», мы можем четко определить конкретную запись в таблице, т.е. каждое сочетание значений этих столбцов является уникальным.
Таким образом, мы определили первичный ключ, и он у нас составной, т.е. состоящий из двух столбцов.
Таблица проектов организации. Внедрен составной первичный ключ: