

Нотация Питера Чена.
Независимая сущность отображается на диаграммах прямоугольником с одинарной рамкой, зависимая – с двойной.
|
|
|
а) независимая |
|
б) зависимая |
Рис.7.22. Отображение сущностей в нотации П. Чена
Атрибуты, в отличие от IDEF1X, отображаются за пределами графического обозначения сущности в виде эллипсов, связанных одинарной линией с ним.
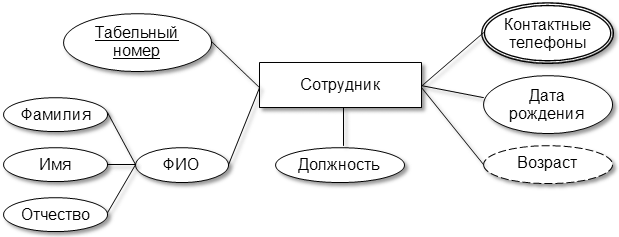
Рис.7.23. Отображение атрибутов в нотации П. Чена
Атрибуты, входящие в первичный ключ сущности, выделяются подчеркиванием имени. Эллипс многозначных атрибутов изображается с двойным контуром, производных – пунктирным. Если атрибут является составным, то атрибуты-компоненты отображаются в виде присоединенных к нему эллипсов.
Связь между сущностями показывается в виде ромба с указанием имени связи внутри него. При этом, если ромб имеет двойную рамку, то связь – идентифицирующая, одинарную – неидентифицирующая. Обязательность связи отображается двойной линией. В частности (рис.7.24б) отдел обязательно должен состоять из сотрудников, а сотрудник (например, руководитель) необязательно входить в штат отдела. Т.е. понятие обязательности в данной нотации, в отличие от IDEF1X, носит двухсторонний характер.
а) идентифицирующая связь

б) неидентифицирующая связь

Рис.7.24. Отображение связей в нотации П. Чена
Связь, как и сущность, может иметь собственные атрибуты, отображаемые в виде присоединенных к ней эллипсов.

Рис.7.25. Связь с атрибутами
Мощность (кардинальность) связи обозначается числами или буквами:
- 1 – один;
- N или M – многие;
- <число> – конкретное количество экземпляров;
- (<Min>, <Max>) – диапазон экземпляров, где в качестве <Min> и <Max> могут использоваться предыдущие обозначения мощности. В этом случае интерпретация мощности выполняется в «обратную сторону», т.е. со стороны родительской сущности указывается: сколько экземпляров дочерней сущности связано с экземпляром родительской сущности, а со стороны дочерней сущности – сколько экземпляров родительской сущности связано с экземпляром дочерней сущности.
Примеры указания мощности связи показаны на следующем рисунке.
а) односимвольное обозначение

б) диапазонное обозначение

Рис.7.26. Отображение мощности связей в нотации П. Чена
В первом случае мощность связи (один-ко-многим) указывается традиционно, как в большинстве нотаций. Т.е. экземпляр родительской сущности (конкретный отдел) связан с 0, 1 или более экземплярами дочерней сущности (конкретными сотрудниками). Во втором случае ее следует понимать следующим образом: экземпляр родительской сущности должен быть связан с 5 или более экземплярами дочерней сущности (отдел состоит из 5 или более сотрудников), а экземпляр дочерней сущности связан с 0 или 1 экземпляром родительской сущности (сотрудник либо не входит, либо входит в отдел).
Расширением ER-модели Чена является EER-модель (Enhanced ER, улучшенная ER), которая позволяет моделировать отношения наследования между суперклассами и подклассами. Основу расширения составляют концепции специализации, генерализации и категоризации.
Специализация – процесс увеличения различий между отдельными сущностями за счет выделения их отличительных характеристик.
Генерализация – процесс сведения различий между сущностями к минимуму путем выделения их общих характеристик. Процесс обратный специализации.
Категоризация – моделирование сущности путем включения в нее характеристик других сущностей (множественное наследование).
Графически наследование отображается кругом, соединенным линиями с суперклассами и подклассами. Внутри круга указывается символ, характеризующий тип наследования:
- d – непересекающаяся специализация/генерализация. Отдельная сущность может быть членом только одного из подклассов;
- o – пересекающаяся специализация/генерализация. Отдельная сущность может быть членом нескольких подклассов;
- U – категоризация.
Примеры наследования показаны на следующем рисунке.
а) непересекающаяся специализация

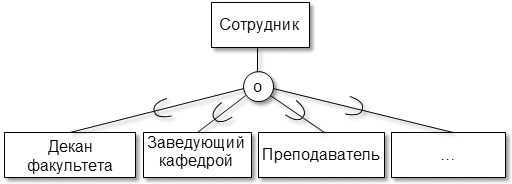
б) пересекающаяся специализация
в) категоризация
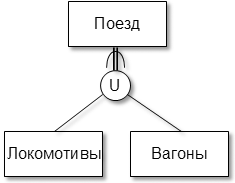
Рис.7.27. Отображение суперклассов и подклассов
В первом случае используется непересекающаяся специализация (d), т.к. локомотив (экземпляр сущности), может быть, только одной из разновидностей тяговых средств. Во втором случае используется пересекающаяся специализация (o), т.к. сотрудник может занимать сразу несколько должностей (выполнять несколько обязанностей).
Если характеристики (набора атрибутов) суперкласса достаточно для описания экземпляра сущности, то суперкласс и круг соединяются одинарной линией (например, для рис.7.27б – сотрудниками могут быть уборщица или охранник). Такая специализация называется частичной. Если экземпляр сущности обязательно должен быть одной из разновидностей подкласса, т.е. описывается набором атрибутов как суперкласса, так подкласса, то суперкласс и круг соединяются двойной линией. Такая специализация называется полной. Аналогичная ситуация возникает и при моделировании категоризации. Если экземпляр сущности при множественном наследовании обязательно должен характеризоваться (включать) атрибутами суперкласса и всех подклассов, то категоризация – полная, иначе – частичная.
В заключение следует отметить, что вынесение атрибутов за пределы графического изображения сущности делает нотацию Чена похожей на семантические сети.