

ПР1
.docx
МИНОБРНАУКИ РОССИИ |
Федеральное государственное бюджетное образовательное учреждение высшего образования «МИРЭА Российский технологический университет» РТУ
МИРЭА
|


Институт информационных технологий (ИИТ)
Кафедра прикладной математики (ПМ)
ОТЧЕТ ПО ПРАКТИЧЕСКОЙ РАБОТЕ
по дисциплине «Методы анализа данных»
Практическое задание № 1
Студент группы ИНБО-01-17
|
ИНБО-06-20 |
(подпись)
|
|
|
Преподаватель
|
Буданцев А. В.
|
(подпись)
|
|
|
Отчет представлен |
«10» октября 2022 г. |
|
||
Москва 2022 г.
Постановка задачи: 1) Изучить HDFS и работу с ней с помощью команд и веб-интерфейса; 2) Изучить работу с YARN/MapReduce.
Ход работы:
Работа с HDFS
Чтобы начать использовать службу Hadoop, нужно запустить демоны службы Hadoop.
Пользователь терминала был изменен на «hadoop» с помощью команды su (Рисунок 1). в
![]()
Рисунок 1 – Изменение пользователя
Был изменен рабочий каталог на ~/hadoop/sbin и выполнен сценарий, запускающий службы HDFS (Рисунок 2).
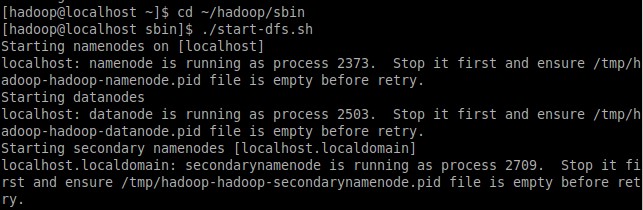
Рисунок 2 – Запуск служб HDFS
Аналогичным способом был запущены службы YARN (Рисунок 3).
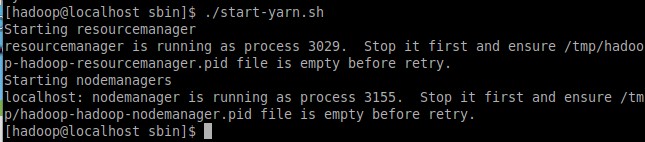
Рисунок 3 – Выход пользователя из сеанса
Демоны namenode и datanode для служб HDFS успешно запущены.
Далее был произведен выход из сеанса как пользователь «hadoop» с помощью команды exit (Рисунок 4).
![]()
Рисунок 4 – Выход пользователя из сеанса
В терминале от имени пользователя student была выполнена команда, представленная на Рисунке 5. На терминал вывелся список всех каталогов.

Рисунок 5 – Вывод каталогов
Далее был выведен список домашних каталогов в HDFS (Рисунок 6).
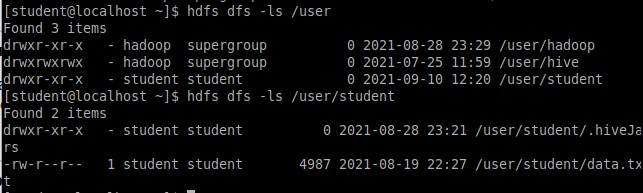
Рисунок 6 – Вывод домашних каталогов (HDFS)
Далее были исследованы домашние каталоги пользователей для Linux (Рисунок 7).

Рисунок 7 – Вывод домашних каталогов (Linux)
Распространенной задачей администратора Hadoop является создание новых пользователей. При этом обычно создается домашний каталог пользователя как для Linux, так и для HDFS.
Для создания нового пользователя требуются привилегии суперпользователя. Префикс команд sudo позволяет выполнять привилегированные команды. Использование sudo возможно потому, что студент является частью группы wheel, которой была предоставлена эта возможность. Затем был получен список домашнего каталога (пока пустой), выведен на печать текущий рабочий каталог и выведены на печать группы, к которым принадлежит student2.
Результат вышеперечисленной работы отображен на Рисунке 8.
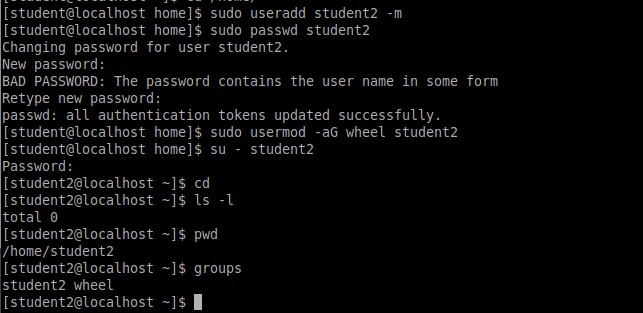
Рисунок 8 – Создание нового пользователя
Терминал student2 остался открытым, в то же время был открыт другой терминал, выполнен вход под именем hadoop. Был создан новый каталог в /user/student2. Далее с помощью команды chown был изменен владелец этого каталога на student2. При вызове каталога ничего не произошло, так как он пуст, однако он существует, потому что при вызове несуществующего каталога терминал выдает ошибку (Рисунок 9).
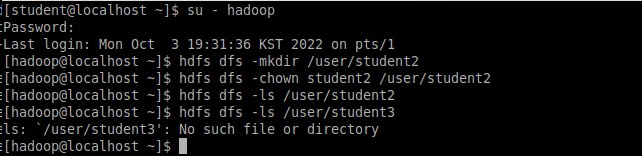
Рисунок 9 – Создание нового каталога и изменение владельца
Работа была сброшена путем выхода из всех терминалов.
После открытия нового терминала был создан подкаталог в домашнем каталоге студента HDFS и назван «MRtest» (Рисунок 10).
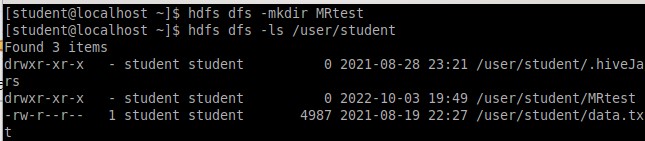
Рисунок 10 – Создание нового подкаталога
В каталоге /home/student/Data есть копия книги «Приключения Алисы в стране чудес» Льюиса Кэррола. В данном каталоге был найден и изучен файл alice_in_wonderland.txt (Рисунки 11-12).
![]()
Рисунок 11 – Поиск файла

Рисунок 12 – Файл «Алиса в стране чудес»
Данный файл был помещен в папку «MRtest» (Рисунок 13).
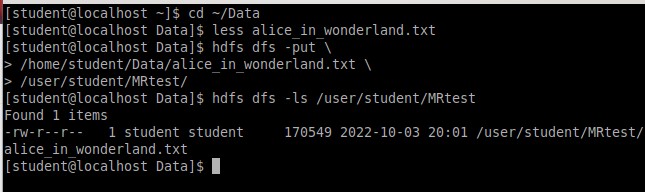
Рисунок 13 – Перемещение файла
В браузере Mozilla Firefox был открыт веб-интерфейс Namenode по сохраненной закладке и изучены основные вкладки (Рисунок 14).
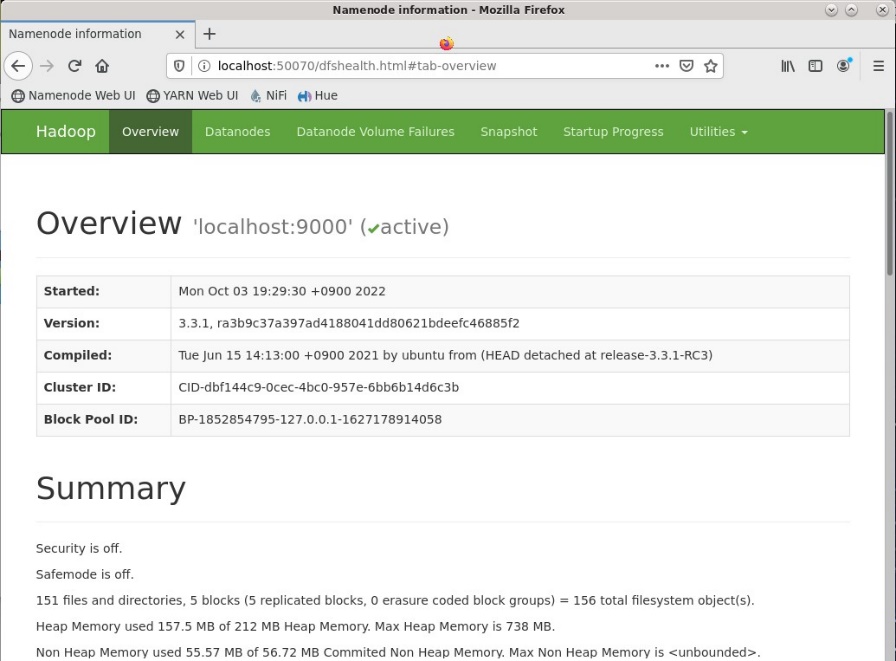
Рисунок 14 – Веб-интерфейс Namenode
В разделе Utilities («Утилиты») была выбрана файловая система, затем был осуществлен переход в каталог HDFS, куда ранее скопирован файл alice_in_wonderland.txt. Файл действительно существует в директории, это отображено на Рисунке 15.
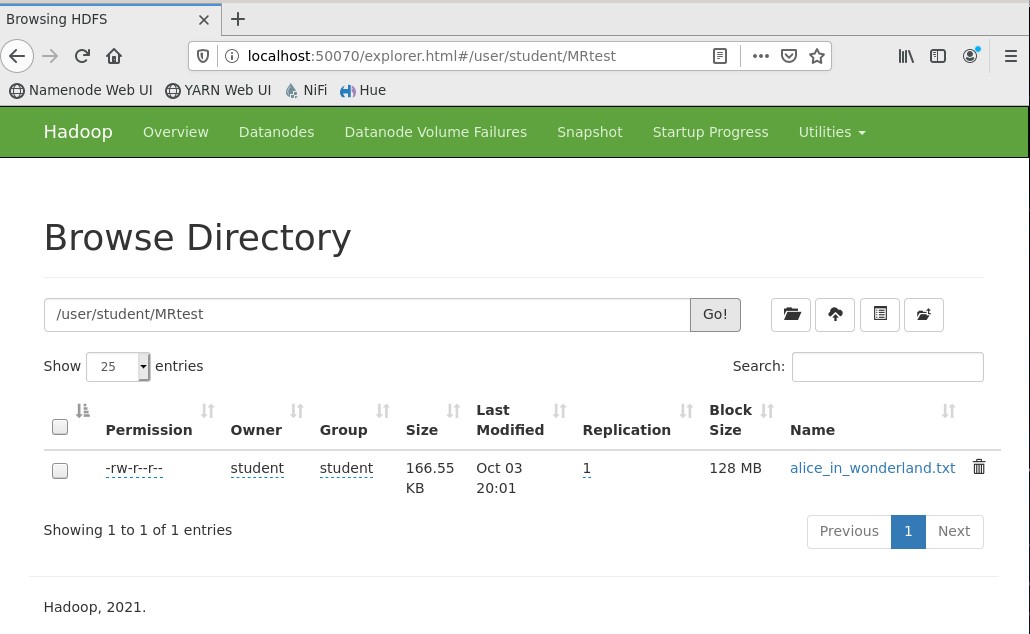
Рисунок 15 – Файл в директории
При открытии файла отображается информация о нем. Требуется запомнить Block ID и Block Pool ID (Рисунок 16).

Рисунок 16 – Данные файла
Вновь был открыт терминал, осуществлен вход под именем hadoop и поиск Block Pool ID с помощью команды find (Рисунок 17).

Рисунок 17 – Поиск идентификатора пула блоков
После перехода в каталог, где был найден Block Pool ID, вновь используем предыдущую команду, но для поиска Block ID (Рисунок 18).

Рисунок 18 – Поиск блоков данных
Далее была использована команда less для просмотра текстового файла (Рисунок 19). Содержание файла аналогично представленному на Рисунке 12.
![]()
Рисунок 18 – Команда для просмотра содержимого
Работа с YARN/MapReduce
Был открыт новый терминал, вход под именем hadoop, запущен historyserver (Рисунок 19).
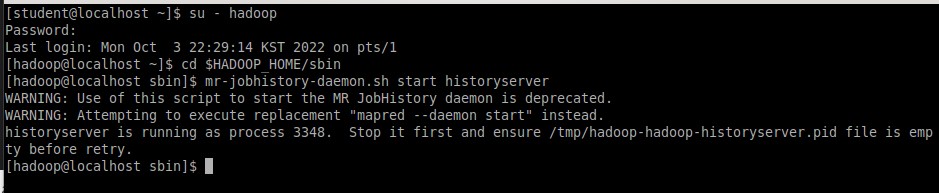
Рисунок 19 – Запуск historyserver
Далее был открыт новый терминал под именем student и осуществлен переход в каталог mapreduce и запущен jar-файл с параметром подсчета слов (Рисунок 20).
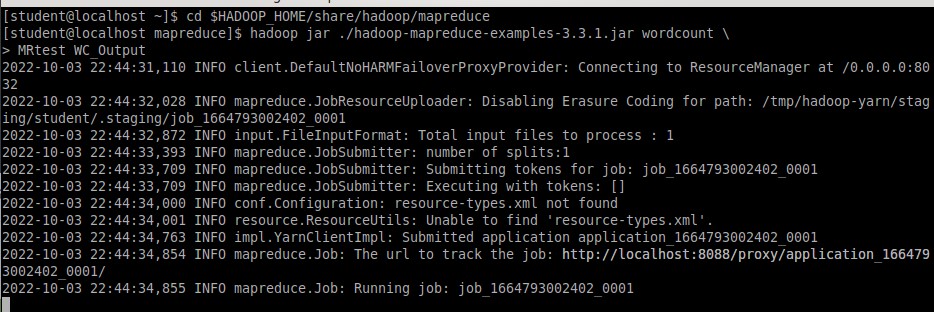
Рисунок 20 – Переход в mapreduce
Во время работы программы был запущен браузер Firefox и открыт веб-интерфейс YARN (Рисунок 21).
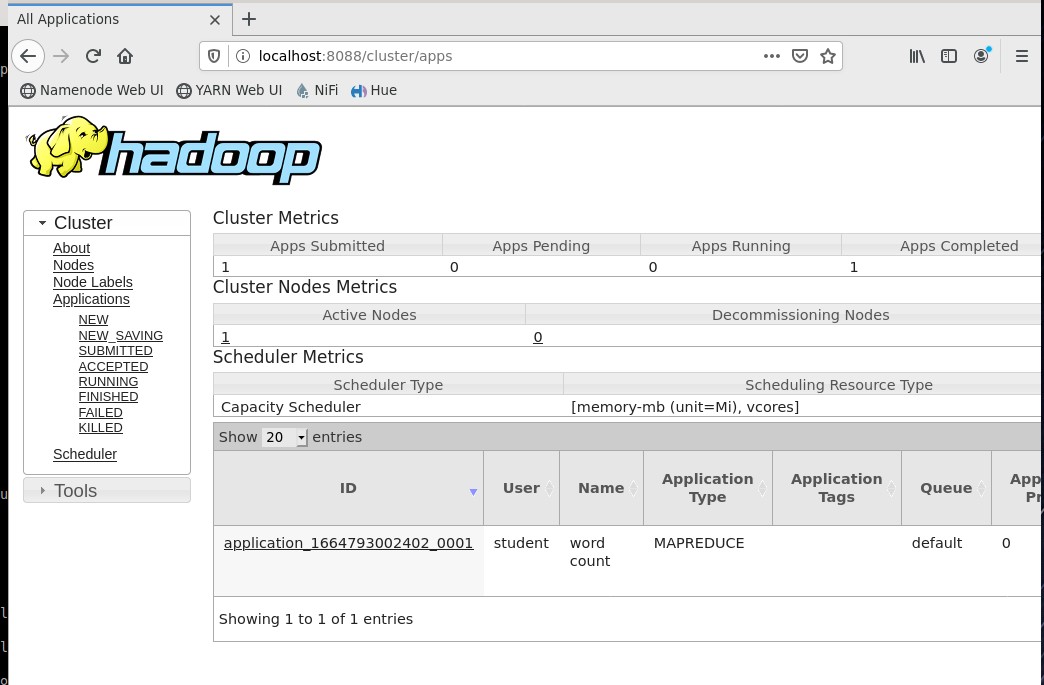
Рисунок 21 – Веб-интерфейс YARN
При нажатии на ID приложения можно изучить Application Master (Рисунок 22).
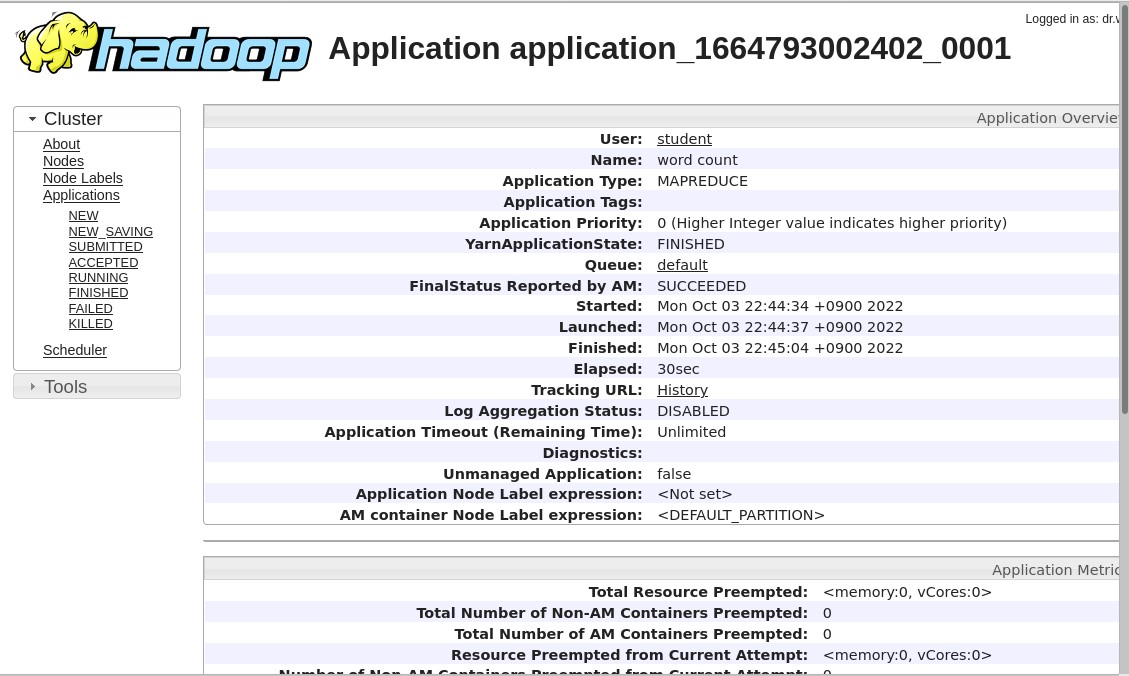
Рисунок 22 – Application Master
Так как задание еще выполнено, ниже показан узел, выполнивший его (Рисунок 23).
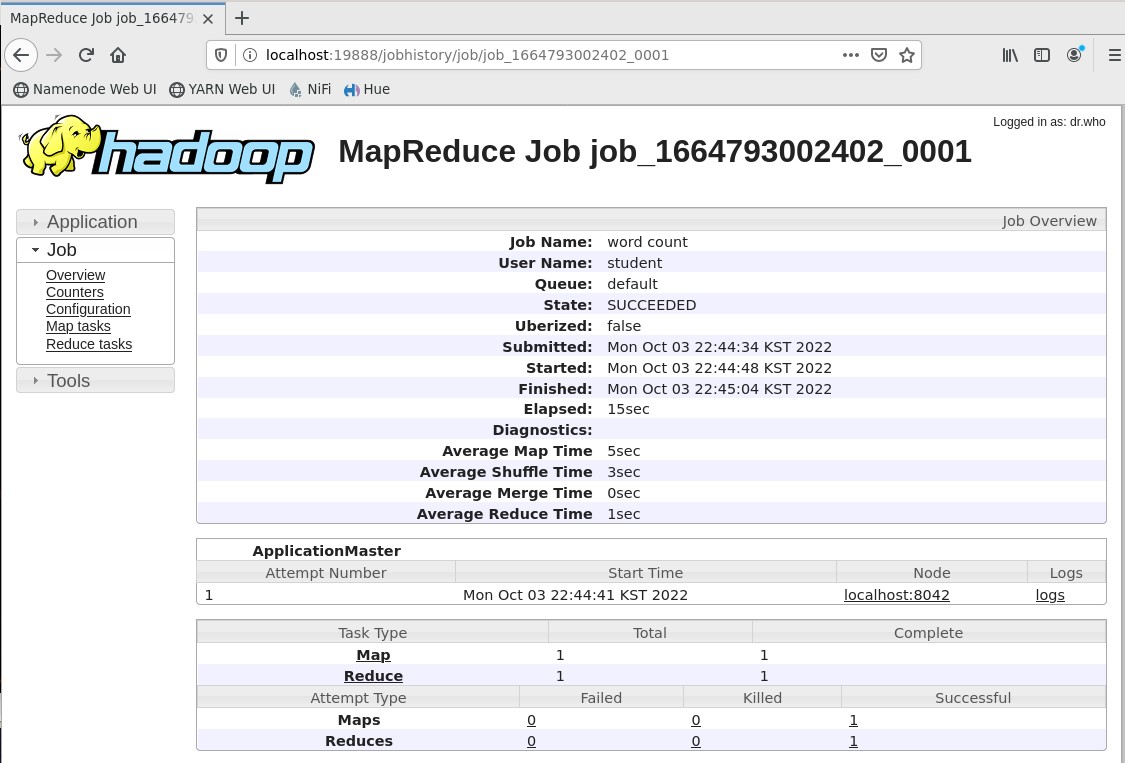
Рисунок 23 – Данные приложения при выполненном задании
При нажатии на хост узла можно узнать ресурсы контейнера, выделенные для задания (Рисунок 24).
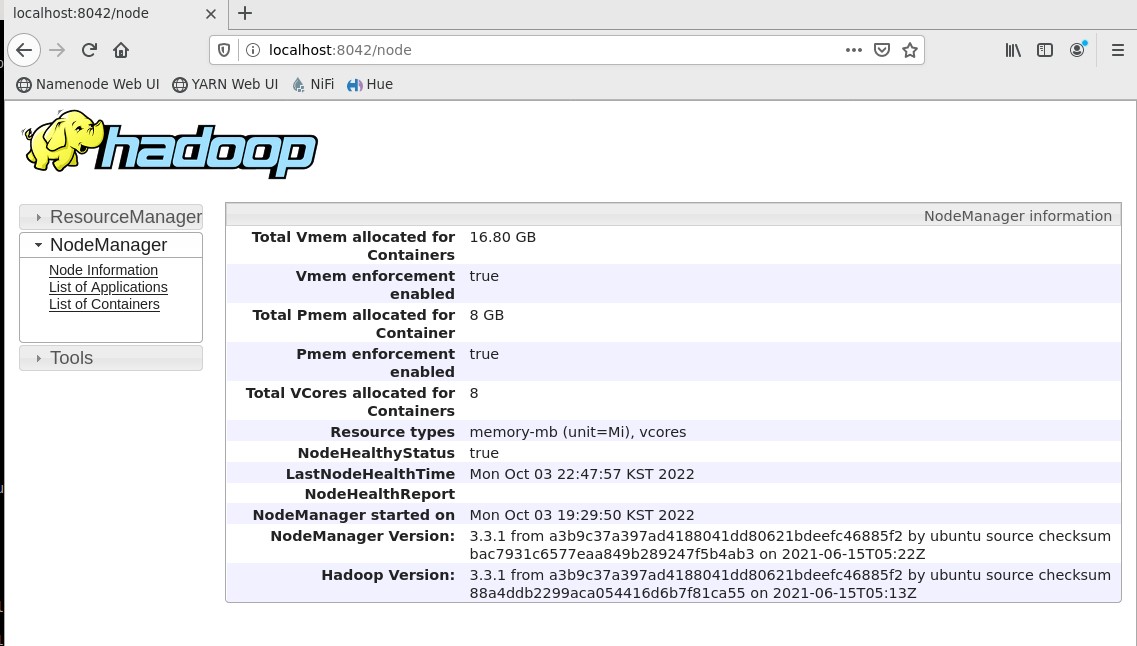
Рисунок 24 – Ресурсы контейнера
Вывод: при выполнении лабораторной работы №1 было осуществлено знакомство с службами Hadoop – HDFS и YARN в соответствующих веб-интерфейсах и среде для виртуализации VirtualBox.