

6 семестр / ПР4
.docx

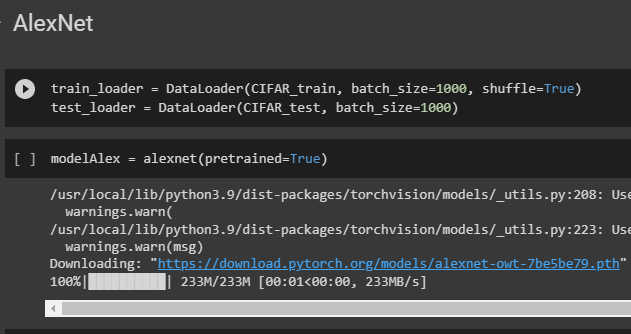
Перебираем все параметры модели modelAlex с помощью цикла for.
Устанавливаем значение False для свойства requires_grad.
Заменяем последний слой модели modelAlex на новый слой torch.nn.Linear(4096, 10), который является полносвязным слоем, принимающим входной тензор размерности (batch_size, 4096) и производящим выходной тензор размерности (batch_size, 10).
Оцениваем точность без дообучения.

Создаем оптимизатор opt — Adam — и функцию потерь loss — Cross Entropy Loss, которая используется для обучения многоклассовой классификации.
Каждый элемент в нашем векторе предсказаний будет соответствовать вероятности принадлежности к одному из десяти классов.
Выполняет дообучение последнего слоя с помощью стохастического градиентного спуска.
modelAlex.train() — модель будет обновлять свои веса и выполнять операции: инициализация dropout.
loss_history = [] создает список для хранения функции потерь.
for epoch in tqdm(range(10)): проходит по эпохам обучения.
for i, (batch, labels) in enumerate(train_loader): проходит по пакетам из обучающего набора данных.
batch = batch.to(device) переносит на устройство device
opt.zero_grad() обнуляет градиенты перед каждой итерацией.
loss_val = loss(modelAlex(batch), labels.to(device)) вычисляет функцию потерь между предсказаниями modelAlex(batch) и истинными метками labels.to(device). Затем loss_val используется для расчета градиента в следующей строке.
loss_val.backward() вычисляет градиенты
opt.step() обновляет веса
loss_history.append(loss_val.log().item()) добавляет значение в список loss_history.

Создает загрузчики данных для обучения и тестирования модели на наборе данных CIFAR-10
Создание модели VGG16 с предобученными весами
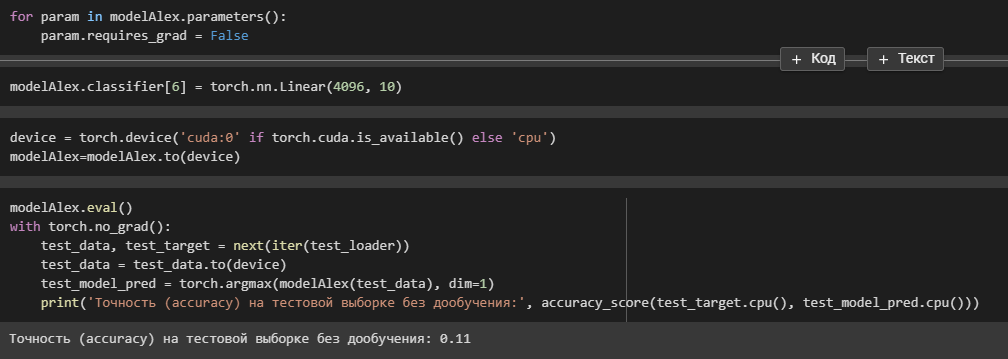
Замораживание всех параметров модели, чтобы они не обучались на новых данных: for param in modelVGG.parameters(): param.requires_grad = False
Замена последнего слоя на новый линейный слой, который будет адаптирован к количеству классов в CIFAR-10 (10): modelVGG.classifier[6] = torch.nn.Linear(4096, 10).

Оценивает точность модели на тестовом наборе данных без точной настройки.
modelVGG.eval(): отключает слои пакетной нормализации, чтобы гарантировать, что модель не изменяет свои параметры во время оценки.
torch.no_grad(): вычисление градиента отключено, уменьшая потребление памяти и ускоряя процесс оценки.
test_data, test_target = next(iter(test_loader)): загружает пакет тестовых данных и меток из test_loader dataloader.
test_model_pred = torch.argmax(modelVGG(test_data), dim=1): загружает тестовые данные в модель для получения прогнозируемых меток.
print('Точность на тестовой выборке без дообучения:', accuracy_score(test_target.cpu(), test_model_pred.cpu())): вычисляет и печатает точность модели в тестовом наборе данных.
Функция accuracy_score используется для сравнения предсказанных меток с истинными метками и вычисления точности.
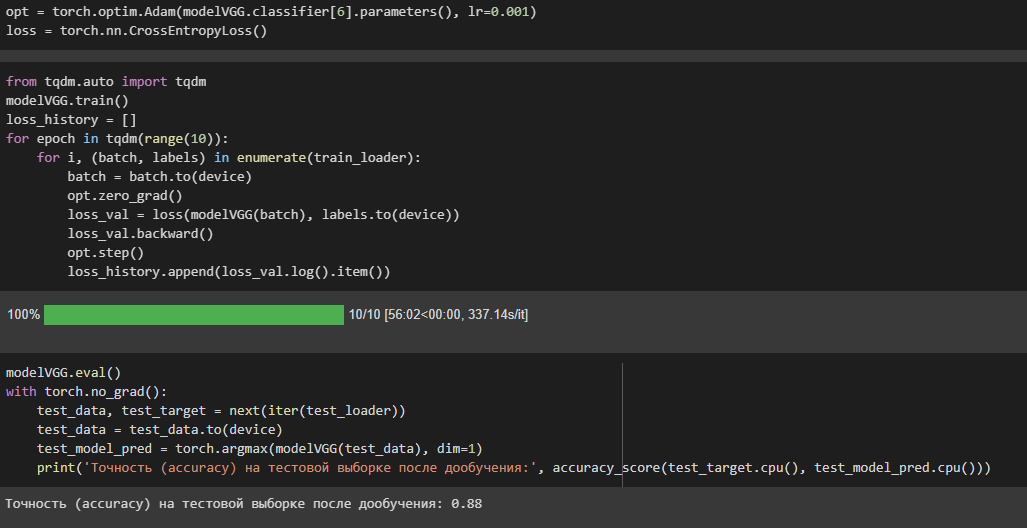
Инициализирует оптимизатор Adam со скоростью обучения 0.001 для оптимизации весов последнего полностью подключенного слоя. Определяет функцию потери Cross Entropy Loss для вычисления потерь во время обучения.
modelVGG.train(): модель может обновлять свои параметры во время обучения.
loss_history = []:список для хранения значений функции потерь.
for epoch in tqdm(range(10)): проходятся десять эпох обучения
opt.zero_grad(): обнуляются градиенты, вычисленные на предыдущей итерации.
loss_val = loss(modelVGG(batch), labels.to(device)): рассчитывается функция потерь.
loss_val.backward(): рассчитываются градиенты
opt.step(): обновляются параметры
loss_history.append(loss_val.log().item()): значение функции потерь добавляется в список значений функции потерь.
Проводит оценку точности модели VGG на тестовой выборке после дообучения.

Оптимизатором выбран Adam, функцией потерь CrossEntropyLoss.
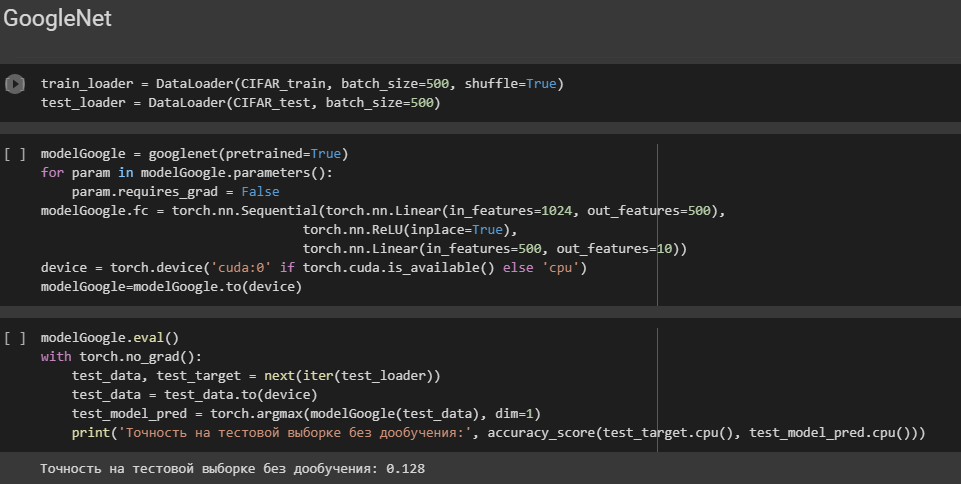
Cоздается объект модели с предварительно обученными весами (pretrained=True).
Циклом for проходим по параметрам модели и устанавливаем для каждого параметра requires_grad = False. Эти параметры не будут обучаться во время обратного распространения ошибки и не будут обновляться во время обучения.
Меняем последний слой модели с помощью атрибута fc. Создаем последовательность слоев из двух линейных слоев, принимающих входной тензор размерности 2048 и выходной тензор размерности 10.


Создает объект модели modelGoogle, который представляет нейронную сеть GoogleNet с предварительно обученными весами.
Меняем последний слой модели с помощью атрибута fc. Создаем последовательность слоев из двух линейных слоев, принимающих входной тензор размерности 1024 и выходной тензор размерности 10. Используем функцию активации ReLU между этими двумя линейными слоями.
Создаем новую архитектуру модели, которая соответствует задаче классификации изображений на 10 классов.

Графики ошибок.

Cравнение качества моделей до дообучения и после.
Модель |
Точность до дообучения |
Точность после дообучения |
AlexNet |
0.11 |
0.845 |
VGG |
0.11 |
0.88 |
ResNet |
0.08 |
0.82 |
GoogleNet |
0.128 |
0.714 |