

6 семестр / пр1
.docx
Содержание
Введение
В практической работе 1 мы классифицируем изображения с помощью полносвязной нейронной сети, научимся ускорять вычисления с помощью переложения на GPU
Основная часть
Инициализацию random seed, чтобы эксперименты можно было воспроизводить. Далее скачиваем датасет MNIST, который содержит в себе картинки цифр от 0 до 9. Скачиваем с помощью библиотеки torchvision.datasets (Рисунок 1).
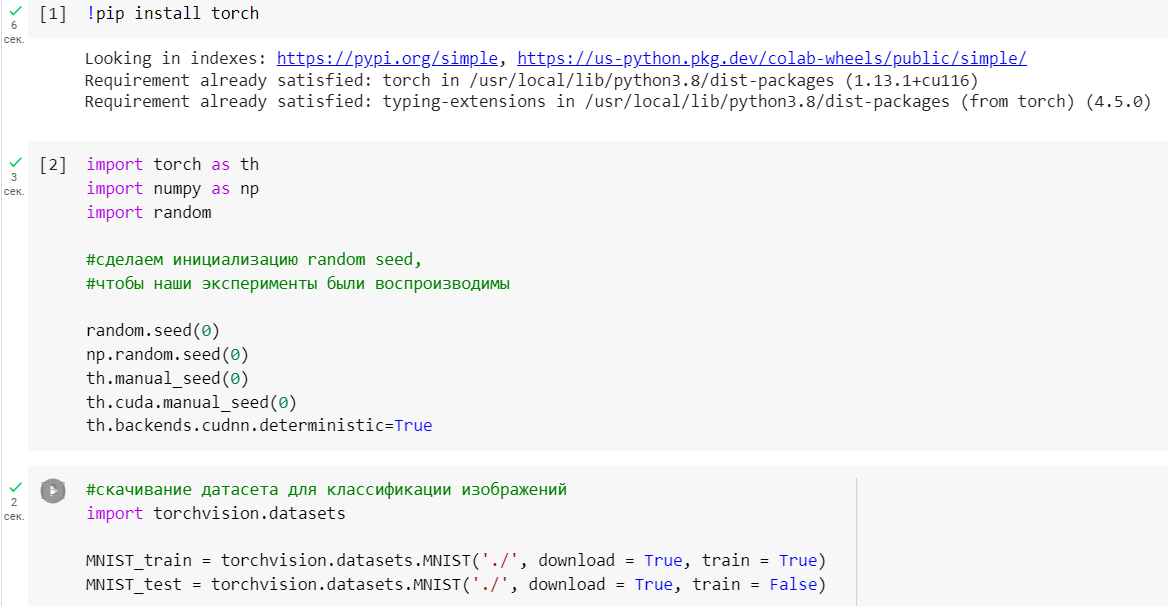
Рисунок 1 — Инициализация random seed и скачивание датасета
Инициализация X_train, X_test(картинки), y_train, y_test(лейблы) из тех данных, что мы скачали. Просмотр типа данных и перевод во float, чтобы данные были в дробных числах (Рисунок 2).
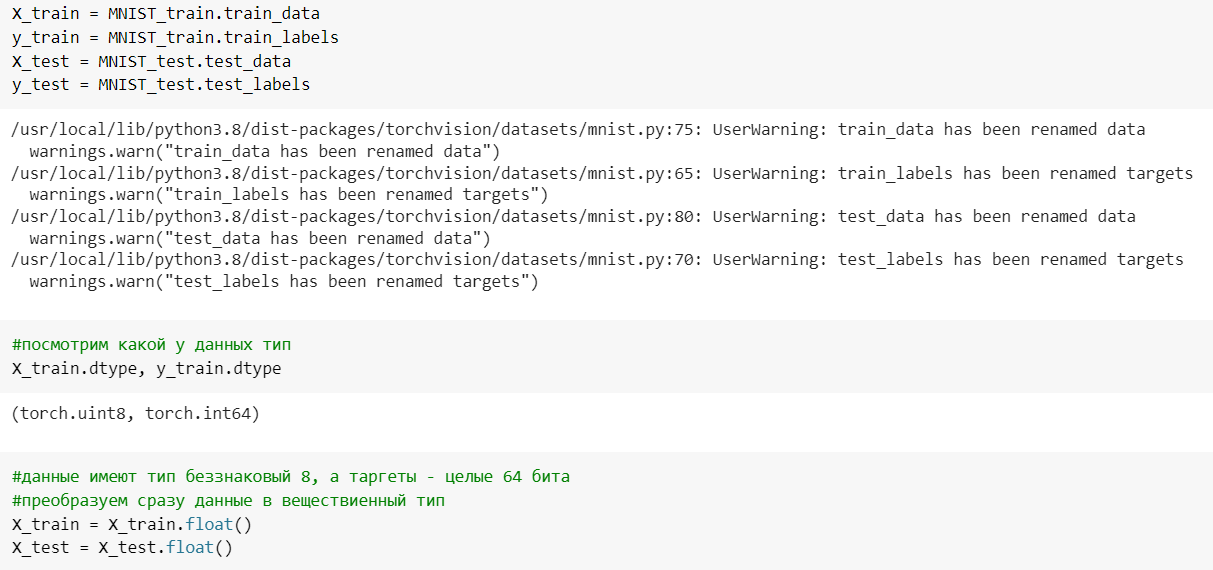
Рисунок 2 — Инициализация, просмотр типа данных, преобразование во float
Просмотр размерности датасета. Сами изображения размера 28*28. Вывод картинки (Рисунок 3).
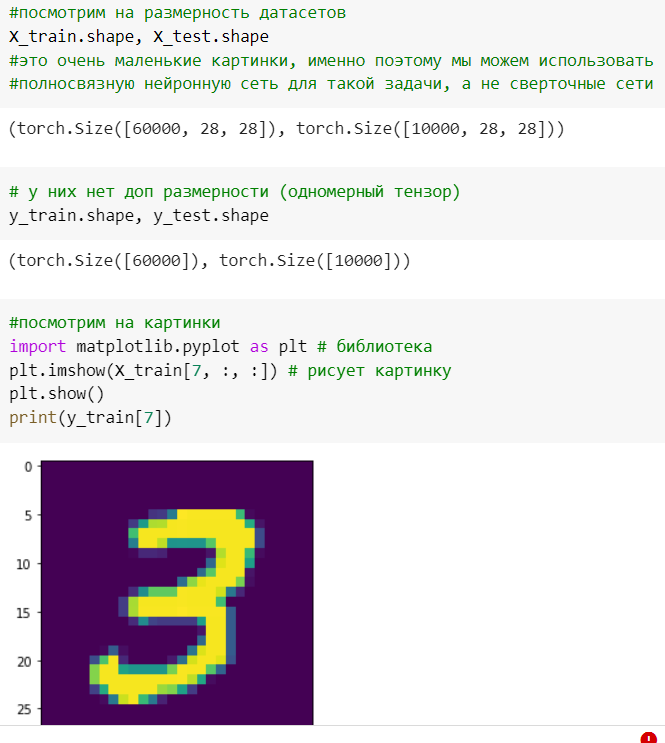
Рисунок 3 — Просмотр размерности датасета, вывод картинки
Т.к. у нас двумерный тензор, растягиваем картинку в вектор. Растягиваем с помощью функции reshape. В результате первая размерность сохранится и будет 60000, а вторая 784 пикселя (Рисунок 4).

Рисунок 4 — Растягиваем картинку в вектор
Создаем сеть, на вход которой подаются числа от 0 до 9, состоящая из нескольких полносвязных слоев (из 2х слоев нейронов). В итоге создадим сеть net из 100 скрытых нейронов(Рисунок 5).

Рисунок 5 — Создание сети
Проверка видимости и просмотр видеокарты(Рисунок 6).
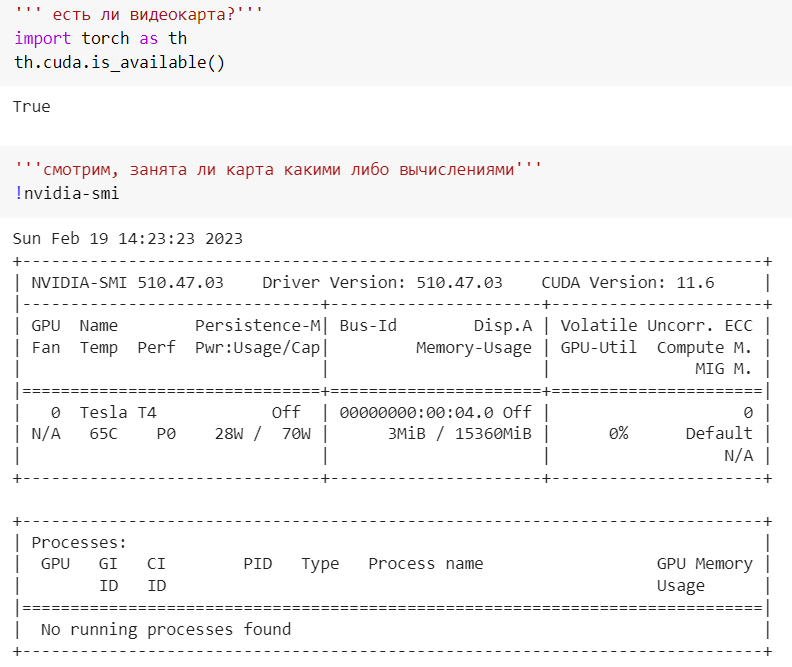
Рисунок 6 — Проверка видимости и просмотр видеокарты
Перекладываем вычисления на видеокарту. Далее пишем loss функцию и оптимизатор — метод градиентного спуска Adam, на вход которого поступают все параметры нейронной сети. Кросс-энтропия для классификации. Можно объединили софт макс и энтропию в одну ф-ию (Рисунок 7).

Рисунок 7 — Перекладываем вычисления на видеокарту. Далее пишем loss функцию и оптимизатор
Перемешиваем датасет, чтобы в эпохе не повторялись картинки. Выделяем последовательные участки из датасета. Прогоняем их через слои. Считаем лосс по выходным данным и по желаемым классам для предсказания. Считаем градиент. Делаем градиентный шаг. Смотрим на рост качества с каждой эпохой на всем тестовом датасете. Считаем долю правильных ответов в accuracy, наиболее вероятный класс предсказания (Рисунок 8).

Рисунок 8 — Код
Результаты прогона через нейронку (Рисунок 9).
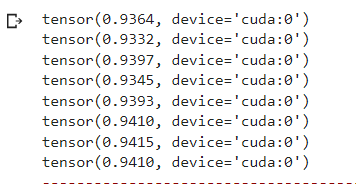
Рисунок 9 — Результаты прогона
Визуализируем результаты test_loss_history(Рисунок 10).
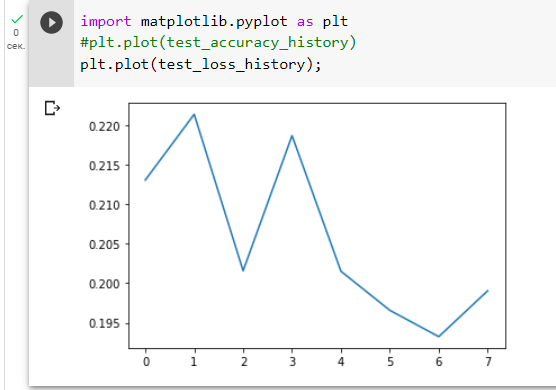
Рисунок 10 — Визуализация test_loss_history
Визуализируем результаты test_accuracy_history(Рисунок 11).
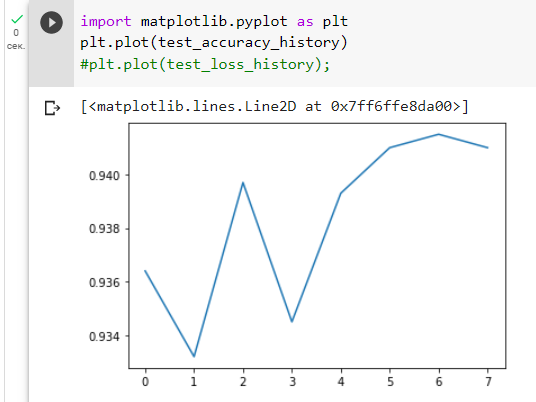
Рисунок 11 — Визуализация test_accuracy_history
Выводы
В результате выполнения практической работы были обработаны числа из библиотеки MNIST с помощью полносвязной нейронной сети.