

Вопросы к экзамену 2023
.pdf1.Реляционные СУБД. Понятие реляционной БД и СУБД. Примеры РСУБД.
РБД (Реляционная БД) – это структура, в которой математические и логические отношения формируются в виде таблицы, и некоторые столбцы в ней дублируются другими таблицами для определения соотношения между каждой из таблиц.
>Преимущества: высокая приспосабливаемость к изменениям; простота в использовании и обслуживании, что повышает производительность.
>Недостатки: высокая нагрузка на систему, из-за использования большего количества данных, по сравнению с другими СУБД.
СУБД (Система управления базами данных) – это программа, состоящая из множества приложений, которые легко создают и управляют базами данных.
Примеры: Oracle, MySQL, SQLServer, MariaDB и др.
2. Реляционные СУБД. Понятие транзакции. Свойства АСИД.
Транзакция — это осуществление одного или нескольких изменений базы данных. Например, создание, обновление или удаление записи из таблицы.
Свойства ACID – Атомарность, Согласованность, Изолированность, Надежность.
Атомарность гарантирует, что каждая транзакция будет выполнена полностью или не будет выполнена совсем. Не допускаются промежуточные состояния.
Транзакция, достигающая своего нормального завершения и, тем самым, фиксирующая свои результаты, сохраняет согласованность базы данных. Другими словами, каждая успешная транзакция по определению фиксирует только допустимые результаты.
Изолированность – во время выполнения транзакции параллельные транзакции не должны оказывать влияния на её результат.
Надежность – если пользователь получил подтверждение от системы, что транзакция выполнена, он может быть уверен, что сделанные им изменения не будут отменены из-за какого-либо сбоя.
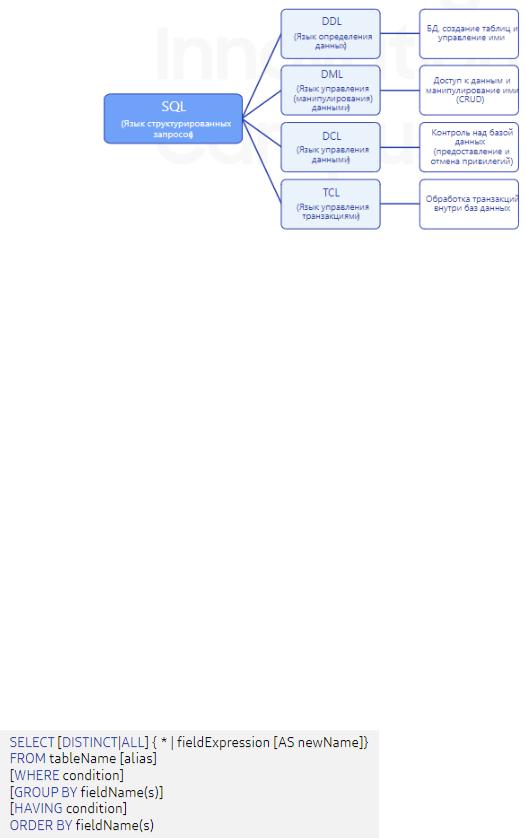
3.Реляционные СУБД. Язык запросов. Основные операторы DML и DDL.
Язык запросов – это искусственный язык, на котором делаются запросы к базам данных и информационно-поисковым системам.
В контексте SQL, язык определения данных или язык описания данных DDL
представляет собой синтаксис для создания и изменения объектов в базах данных, таких как таблицы, индексы и пользователи
Общий пример выражений включает CREATE, ALTER: и DRОР.
DML – язык манипулирования данными, который используется для управления самими данными. Например, вставка, обновление, удаление. Используется для добавления, извлечения или обновления данных. Добавляет или обновляет строку таблицы. Эти строки называются кортежами.
Основными командами DML являются UPDATE, INSERT, SELECT, DELETE и другие.
4.Реляционные СУБД. Язык запросов. Оператор SELECT. Агрегирование данных с помощью GROUP BY.
SELECT – ключевое слово SQL, которое сообщает базе данных, что вы хотите получить данные (кортежи).

5.Реляционные СУБД. Оператор JOIN, его виды и принцип действия.
Оператор JOIN служит для объединения двух и более таблиц на основе общих столбцов.
Виды соединения:
Внутреннее соединение (INNER JOIN) – столбцы таблиц в точности совпадают.
Левое/правое внешнее соединение (LEFT/RIGHT LOIN) – объединение строк таблиц, возврат NULL, если в правой/левой таблице нет данных.
Полное внешнее соединение (FULL JOIN) - считывание и вывод всех данных из таблиц.
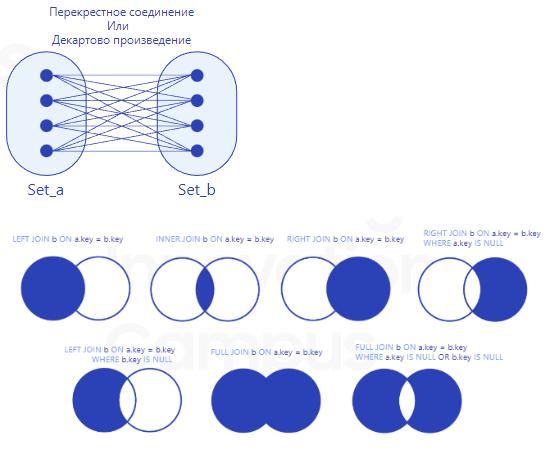
Перекрестное соединение (CROSS JOIN) – возвращает декартово произведение всех строк таблиц. Декартово произведение – это результат первой строки, сцепленный
6. Apache Pig. Задачи и общий принцип работы Apache Pig.
Apache Pig – это механизм для выполнения программ поверх Hadoop. Альтернатива Java-коду и низкоуровнему коду MapReduce. для обработки больших данных. Обеспечивает высокоуровневую обработку данных. Особенно хорош при предварительной обработки неструктурированных данных. Использует язык Pig Latin.
Используется для:
>Выборки данных
>Процессов извлечения, трансформации и загрузки (ETL).
>Извлечения полезных данных из журнала.
Преимущества:
Может обрабатывать любые по структуризации данные
Может работать на любой платформе обработки данных
Процедурный язык высокого уровня
Не требует компиляции, конвертируется в задачу MapReduce

7. Apache Pig. Язык запросов. Основные принципы и операторы.
Pig Latin – язык потока данных. Запускается в интерактивной оболочке Grunt Shell.
Основные операторы:
LOAD – загрузка данных
PigStorage – функция загрузки, разбивающая строки с помощью символа табуляции (… USING PigStorage(‘,’) AS…)
DUMP – отправляет выходные данные на экран
STORE – отправляет выходные данные на диск (HDFS)
DESCRIBE – показывает структуру данных, в т.ч. имена и типы
FILTER – создает кортеж по указанным критериям (как WHERE)
FOREACHE… GENERATE – работает с каждой записью в наборе данных (как SELECT age, salary)
DISTINCT/LIMIT

ORDER BY
GROUP … BY …
UNION (как JOIN)
8. Apache Hive. Задачи и общий принцип работы Apache Hive.
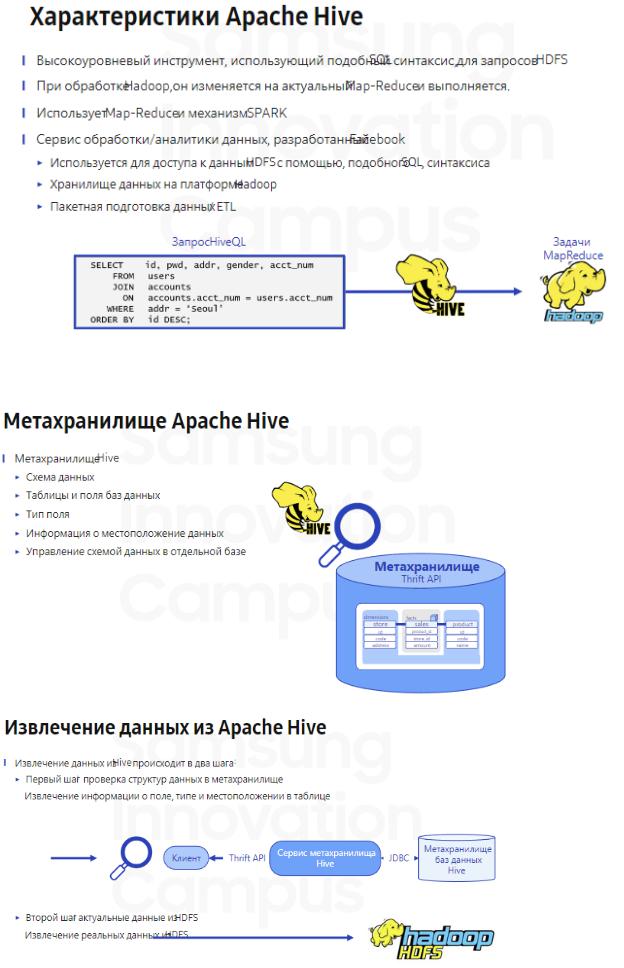
9.Apache Hive. Назначение метахранилища. Понятия внешней и управляемой таблиц.

10.Apache Hive. Язык запросов. Основные операторы DML и DDL.
11.Apache Hive. Цели и принципы разбиения таблиц на разделы
(Partitions). Предложение CLUSTERED BY. Цели и принципы разбиения таблиц на бакеты (Buckets).
Можно разбить на партиции и бакеты, но в чем между ними разница? Партицирование разделяет большие данные на множество частей на основе значений столбца(ов).
Бакетирование разбивает данные на части, количество которых задается пользователем. Вместо уникальных значений столбца бакетирование стремится разделить данные на равные части, где каждой части присваивается свой ключ на основе вычисления хэш-функции. Это делается путем написания функции CLUSTERED BY.

12.Apache Hive. Оконные функции. Оператор OVER.
13.Apache Spark. Задачи, основные фоновые процессы и общий принцип работы Apache Spark.

14.Apache Spark. Сравнение с Hadoop MapReduce. Работа на кластере.