

МИНОБРНАУКИ РОССИИ
Федеральное государственное бюджетное образовательное учреждение высшего образования
«МИРЭА — Российский технологический университет»
РТУ МИРЭА
Институт информационных технологий Кафедра прикладной математики
КУРСОВАЯ РАБОТА
по дисциплине Системы управление данными
Тема курсовой работы: Сбор, предобработка и анализ данных о продажах сети чайных за всё время работы в РФ.
Студент группы ИНБО-06-20
Руководитель курсовой работы |
ст. преп. каф. ПМ Буданцев А.В. |
Постановка задачи
Цель курсовой работы — разработать конвейер для предобработки и маршрутизации данных с помощью VirtualBox.
Задачи, решаемые в данной курсовой работе:
•найти и выбрать данные из предоставленных источников;
•построить конвейер на основе изученных технологий для предобработки и маршрутизации выбранных данных;
•применить методы визуализации и анализа подготовленных данных для ответа на сформулированные преподавателем вопросы;
•подготовить отчет о проделанной работе.
Перечень вопросов, подлежащих разработке, и обязательного графического материала:
1.В какие дни были наибольшие продажи за всё время?
2.Какие чайные были лучшими по продажам за январь 2023 года?
3.В какие дни чайная «Афимолл Сити» имела итоговую выручку более 140 тыс. рублей?
Актуальность
Большие данные относятся к огромному количеству данных, которые превосходят возможности обработки традиционных систем баз данных. Эти данные часто неструктурированы, разнородны и генерируются из большого количества распределенных источников.
Способность обрабатывать и анализировать такие огромные объемы данных, а также извлекать ценную информацию, привело к росту организаций, управляемых данными. Области науки о данных,
искусственного интеллекта и машинного обучения играют важную роль в этой тенденции и меняют способы работы организаций и принятия решений.
Большие данные дают организациям возможность глубже понять своих клиентов, оптимизировать свою деятельность, улучшить свои маркетинговые стратегии и
повысить свое конкурентное преимущество на рынке.
Обзор используемых утилит
Apache Hadoop — это программный фреймворк с открытым исходным кодом, используемый для распределенного хранения и обработки больших данных с использованием программной модели MapReduce.
Apache Hive — это проект программного обеспечения для хранилища данных, созданный на основе Apache Hadoop для обеспечения суммирования, запроса и анализа данных. Hive предоставляет SQL-подобный интерфейс для запроса данных, хранящихся в различных базах данных и файловых системах, которые интегрируются с Hadoop.
Apache Sqoop — это инструмент, разработанный для эффективной передачи больших объемов данных между Apache Hadoop и структурированными хранилищами данных, такими как реляционные базы данных. Sqoop автоматизирует большую часть этого процесса, полагаясь на базу данных для описания схемы данных, которые необходимо передать.
Обзор используемых утилит
Apache Spark — это единый аналитический движок для обработки данных в масштабе больших объемов. Он предоставляет высокоуровневые API на Java, Scala, Python и R, а также оптимизированный движок, который поддерживает общие графы выполнения. Также он поддерживает обширный набор высокоуровневых инструментов.
Apache Flume — это распределенная, надежная и доступная система для эффективного сбора, агрегирования и перемещения больших объемов данных журналов из множества разных источников в централизованное хранилище данных.
Apache Kafka — это распределенная платформа для потоковой обработки, позволяющая пользователям публиковать и подписываться на потоки записей, сохранять потоки записей в отказоустойчивом режиме и обрабатывать потоки записей по мере их поступления. Kafka часто используется для построения конвейеров данных в режиме реального времени.
Обзор используемых утилит
В курсовой работе рассматривается также продукты, которые работают с Apache, но не входят в него.
MariaDB — это система управления базами данных SQL с открытым исходным кодом, разрабатываемая сообществом. MariaDB — это форк MySQL и была создана как замена MySQL, когда ее приобрела компания Oracle Corporation.
Spool — это временное пространство хранения, используемое для буферизации данных между различными частями компьютерной системы или между компьютером и внешним устройством. Данные обычно записываются на жесткий диск или другой тип носителя информации, ожидая дальнейшей обработки.
VirtualBox — продукт виртуализации для использования в домашней и корпоративной среде. Он предназначен как для серверных, так и для настольных сред, и работает на множестве операционных систем. VirtualBox позволяет пользователям запускать несколько гостевых операционных систем (виртуальных машин) на одном хост-компьютере, позволяя им получить доступ к ряду сред из одного устройства.
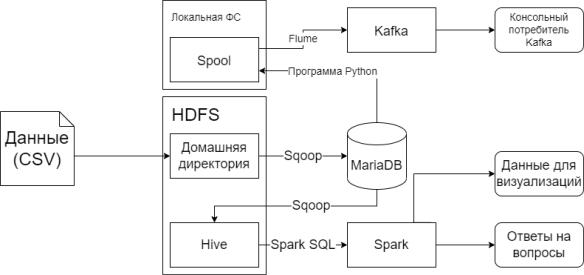
Архитектура конвейера
В данной курсовой работе будет создан конвейер для сбора, предобработки и анализа данных о
продажах сети чайных в РФ.
Схема конвейера
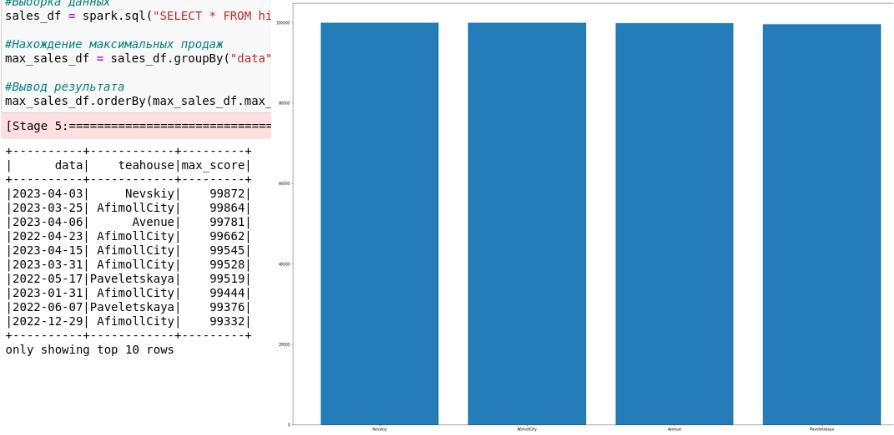
Результаты анализа данных
Необходимо выявить топ десять смен с наилучшими продажами за всё время. Итоговая таблица
должна содержать дату, чайную и итоговую сумму за смену.

Результаты анализа данных
Необходимо выявить топ чайных по продажам за январь 2022 года. Итоговая таблица должна
содержать название чайной и сумму продаж за вышеуказанный год.
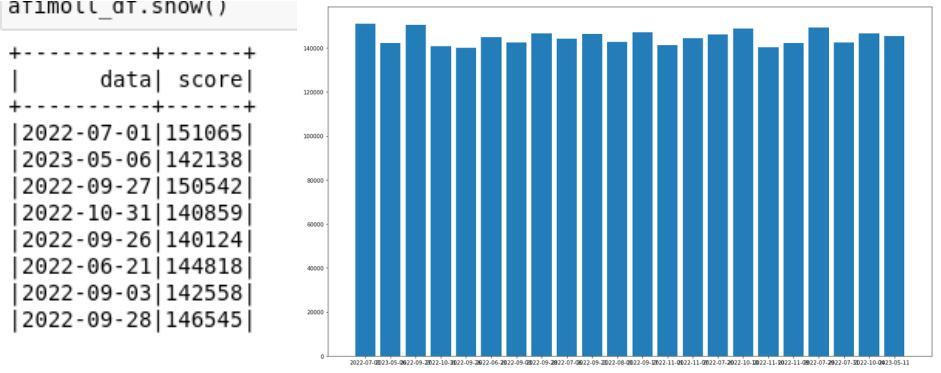
Результаты анализа данных
Необходимо вывести информацию о днях, в которые чайная «Афимолл Сити» имела общую сумму продаж более 140 000 рублей. В ходе такого анализа можно выявить наиболее
прибыльные дни или сезоны для составления планов продаж.