9.3 Моделі паралельних обчислень: класифікація Флінна
Паралельне програмування пов'язане з додатковими труднощами – необхідно явно керувати роботою тисяч процесорів, координувати мільйони міжпроцесорних взаємодій. Для того щоб вирішити задачу на паралельному комп’ютері необхідно розподілити обчислення між процесорами системи так, щоб кожен процесор розв'язував частини задачі. Крім того, бажано, щоб як найменший обсяг даних передавався між процесорами, оскільки комунікації значно повільніші, ніж обчислення. Часто виникають конфлікти між ступенем розпаралелювання і обсягом комунікацій, тобто – чим більше процесорів використовуються для обчислення розпаралеленої задачі, тим більший обсяг даних необхідно передавати між ними. Середовище паралельного програмування має надавати адекватне керування розпаралелюванням і комунікаціями даних. Через складність паралельних комп’ютерів і їх значну відмінність від традиційних однопроцесорних комп’ютерів – не можна просто скористатись традиційними мовами програмування і очікувати високої продуктивності.
Методи паралельного програмування. Процес\канал. В цій моделі програми складаються з одного та більше процесів, розподілених по процесорах. Процеси виконуються одночасно, їх кількість може змінюватись протягом часу виконання програми. Процеси обмінюються даними через канали, які представляють собою одно направлені комунікаційні лінії, які з’єднують тільки два процеси. Канали можна створювати та видаляти. Модель процес\канал характеризується наступними властивостями: 1. Паралельне обчислення складається з одного та більше одночасно виконуваних процесів, число яких може змінюватись під час виконування програми 2. Процес – це послідовна програма з локальними даними. Процес має вхідні та вихідні порти, які служать інтерфейсом до середовища процесу. 3. В додаток до звичайних операцій процес може виконувати наступні дії: Надіслати повідомлення через вихідний порт, отримати повідомлення з вхідного порту, створити новий процес та завершити процес. 4. Операція відправлення асинхронна – вона завершується відразу, не очікуючи того, коли данні будуть отримані. Операція отримання синхронна – вона блокує процес до моменту отримання повідомлення. 5. Пари з вхідного та вихідного портів з’єднуються чергами повідомлень, які називаються каналами. Канали можна створювати та видаляти. Посилання на канали можна включати в повідомлення, так що зв’язність може змінюватись динамічно. 6. Процеси можна розподілю вати по фізичним процесорам різними способами, при чому відображення (розподілення) не впливає на семантику програми.
Поняття процесу дозволяє говорити про місцезнаходження даних : дані, які зберігаються в локальній пам’яті процесу – розміщуються «близько», інші дані «віддалені». Поняття каналу забезпечує механізм для вказування того, зо для того, щоб продовжити обчислення одному процесу необхідні дані іншого процесу (залежність по даним).
Обмін повідомленнями (Massage Passing). В цій моделі програми, написані на традиційній послідовній мові виконуються процесорами комп’ютера. Кожна програма має доступ до пам’яті виконуючого процесора. Програми обмінюються між собою даними, використовуючи підпрограми прийома\передачі даних деякої комунікаційної системи. Програми, які використовують обмін повідомленнями можуть виконуватись тільки на MIMD комп’ютерах. На сьогоднішній день модель обмін повідомленнями є найбільш широко використовуваною моделлю паралельного програмування. Програми цієї моделі подібно програмам моделі процес\канал, створюють множину процесів, з кожним з котрих асоційовані локальні дані. Кожен процес ідентифікуються унікальним іменем. Процеси взаємодіють, посилаючи та отримуючи повідомлення. З цієї точки зору модель «обмін повідомленнями» є різновидом моделі «процес\канал» і відрізняється лише механізмом, який використовується при передачі даних. Наприклад, замість відправки повідомлення в канал «channel 2» можна відправити повідомлення процесу «process 3». Модель «обмін повідомленнями» не накладає обмежень ні на динамічне створення процесів, ні на виконування декількох процесів одним процесором, ні на використання різних програм для різних процесів. Просто, формальний опис систем «обміну повідомленнями» не розглядає питань, які пов’язані з маніпулюванням процесами, однак при реалізації таких систем доводиться приймати якісь рішення в цьому відношенні. На практиці склалось так, що більшість систем «обміну повідомленнями» при запуску паралельної програми створює фіксоване число ідентичних процесів і не дозволяє створювати і знищувати процеси протягом роботи програми. В таких системах кожен процес виконує одну і ту саму програму(параметризовану відносно ідентифікатора процесу або процесора), але працює з різними даними, тому о таких системах кажуть, що вони реалізують SPMD(single program multiple data – одна програма багато даних) модель програмування. SPMD модель достатньо зручна для широкого діапазону додатків паралельного програмування, але вона ускладнює розробку деяких типів паралельних алгоритмів.
Паралелізм даних( Data Parallel). В цій моделі єдина програма задає розподілення даних між усіма процесорами комп’ютера і операції над ними. Розподілюваними даними зазвичай є масиви. Як правило, мови програмування, які підтримують дану модель допускають операції над масивами, дозволяють використовувати в виразах цілі масиви або окремі їх частинки. Розпаралелювання операцій над масивами, циклів обробки масивів дозволяє збільшити продуктивність програми. Компілятор відповідає за генерації коду, який розподіляє елементи масивів і обчислень між процесорами. Кожен процесор відповідає за ту підмножину елементів масиву, яка знаходиться в його локальній пам’яті. Програми з паралелізмом даних можуть бути трансльовані і виконуватись як на MIMD, так і на SIMD комп’ютерах. Модель паралелізм даних також часто використовується. Назва моделі походить від того, що вона експлуатує паралелізм, який полягає в використанні однієї операції до багатьох елементів структур даних. Програма з паралелізмом даних складається з послідовностей подібних операцій. Оскільки операції над кожним елементом даних можна розглядати як незалежні процеси, то ступінь деталізації таких обчислень дуже велика, а поняття «локальності» відсутнє. Тому компілятори мов з паралелізмом даних часто вимагають, щоб програміст надавав інформацію відносно того, як дані повинні бути розподілені між процесорами, іншими словами, як програма має бути розбита на процеси. Компілятор транслює програму з паралелізмом даних в SPMD програму, генеруючи комунікаційний код автоматично.
Загальна пам'ять (Shared Memory). В цій моделі всі процеси сумісно використовують загальний адресний простір. Процеси асинхронно звертаються до загальної пам’яті з запитами на читанні та з запитами на запис, що створює проблеми при виборі моменту, коли можна помістити дані в пам'ять, коли можна буде видалити їх. Для керування доступом до загальної пам’яті використовуються стандартні механізми синхронізації – семафори і блокування процесів. В моделі програмування з загальною пам’яттю, всі процеси сумісно використовують загальний адресний простір, до якого вони асинхронно звертаються з запитами на читання та запис. В таких моделях для керування доступом до загальної пам’яті використовуються різні механізми синхронізації типу семафорів та блокування процесів. Переваги цієї моделі з точки зору програмування полягає в тому, що поняття власності даних (монопольного володіння даними) відсутнє, тому не потрібно явно задавати обмін даними між виробниками даних та їх користувачами. Ця модель з однієї сторони спрощує розробку програми, але з іншої – ускладнює розуміння і керування локальністю даних, написання детермінованих програм. В загальному ця модель використовується при програмуванні для архітектур з загальнодоступною пам’яттю.
Паралельне програмування вже кілька десятиліть використовується в різних галузях, від наукових досліджень до бізнес-додатків та ігрової індустрії. Його застосування дає змогу прискорити обчислення, обробку великих обсягів даних і поліпшити продуктивність програмних систем. У цій статті ми розглянемо основні принципи, переваги та недоліки, а також мови програмування та бібліотеки, які використовуються в паралельному програмуванні.
Паралельне програмування – це процес поділу завдання на безліч дрібніших і незалежних підзадач, які можуть бути виконані одночасно на різних обчислювальних пристроях. Таким чином, прискорюється час виконання і підвищується продуктивність програми.
Основна мета паралельного програмування – це прискорення роботи додатків і обробки даних. Паралельне програмування активно використовується в галузях, де необхідно обробляти великі обсяги даних або обчислення потрібно виконати в найкоротші терміни.
При розробці паралельних програм існує кілька підходів, які можна використовувати для вирішення завдань. Розглянемо деякі з них:
Багатопотокове програмування: цей підхід використовує кілька потоків виконання, які працюють паралельно і виконують завдання. Це дозволяє збільшити продуктивність програми за рахунок використання кількох ядер процесора.
Розподілене програмування: у цьому підході завдання розподіляються між кількома комп'ютерами, які працюють у мережі. Це дає змогу розв'язувати завдання більшого обсягу та прискорювати виконання обчислень.
Асинхронне програмування: при використанні цього підходу потоки виконання не блокуються на очікуванні завершення завдання, а продовжують роботу над іншими завданнями. Це дає змогу збільшити ефективність використання ресурсів та зменшити час очікування.
Функціональне програмування: у цьому підході використовуються функції, які не мають стану та не змінюють зовнішні змінні. Це робить програми більш надійними та передбачуваними.
GPU-програмування: цей підхід використовує графічні процесори для виконання завдань. Це дає змогу прискорювати виконання операцій, пов'язаних із графікою та обробкою зображень.
Залежно від поставленого завдання і використовуваних технологій можна вибрати підхід, який найбільше підходить для вирішення конкретного завдання.
Застосування паралельного програмування є важливим інструментом у різних галузях, таких як наука, бізнес та ігрова індустрія. Це дає змогу ефективно використовувати ресурси комп’ютера та прискорити виконання завдань.
Розглянемо приклади використання паралельного програмування в різних галузях:
У науці паралельне програмування використовується для обробки великих обсягів даних, таких як моделювання клімату, генетичних даних і астрономічних спостережень.
У бізнесі паралельне програмування може бути використане для прискорення обчислень у сфері фінансів, банківської справи, маркетингу і торгівлі.
В ігровій індустрії паралельне програмування дає змогу створювати складніші та реалістичніші ігри, які можуть обробляти велику кількість інформації та взаємодій між гравцями.
Роль паралельного програмування в обробці великих об’ємів даних і прискоренні обчислень полягає в можливості розподілу роботи між кількома ядрами процесора. Це дає змогу прискорити виконання завдань, які можуть бути виконані паралельно, як-от обробка великих обсягів даних або виконання складних обчислювальних завдань. Паралельне програмування також дає змогу використовувати ресурси комп’ютера більш ефективно, що призводить до істотного прискорення виконання завдань.
Переваги:
Збільшення продуктивності та швидкості обробки даних завдяки використанню багатопотоковості та розподілених обчислень.
Зниження часу відповіді і підвищення чуйності системи, що особливо важливо для додатків реального часу.
Можливість обробки великих обсягів даних і виконання складних обчислень, які можуть бути неможливими в послідовній версії програми.
Недоліки:
Складність налагодження та тестування паралельних програм, пов’язана з потенційними проблемами синхронізації даних і конкуренцією за ресурси.
Необхідність знання специфічних технологій та алгоритмів для ефективного використання паралельного програмування.
Ускладнення структури програми та можливість появи помилок під час роботи з даними та ресурсами, що розділяються.
Як бачимо, переваги паралельного програмування, такі як збільшення продуктивності та зниження часу відповіді, роблять його важливим інструментом у розробці програмного забезпечення. Однак, розробники повинні враховувати можливі складнощі, такі як проблеми синхронізації даних і вимоги додаткових зусиль і знань.
Для паралельного програмування існує безліч мов і бібліотек. Деякі з найпопулярніших мов для паралельного програмування – це C++, Java, Python і Go.
Бібліотеки, які полегшують розробку паралельних додатків, включають OpenMP, MPI, CUDA та OpenCL. Кожен із цих інструментів має свої особливості, переваги та недоліки, і вибір залежить від конкретних потреб проєкту. Наприклад, OpenMP полегшує паралельне програмування на багатопроцесорних системах, тоді як CUDA і OpenCL оптимізовані для використання з графічними процесорами.
Порівняємо їхні особливості та приклади використання в табличці:
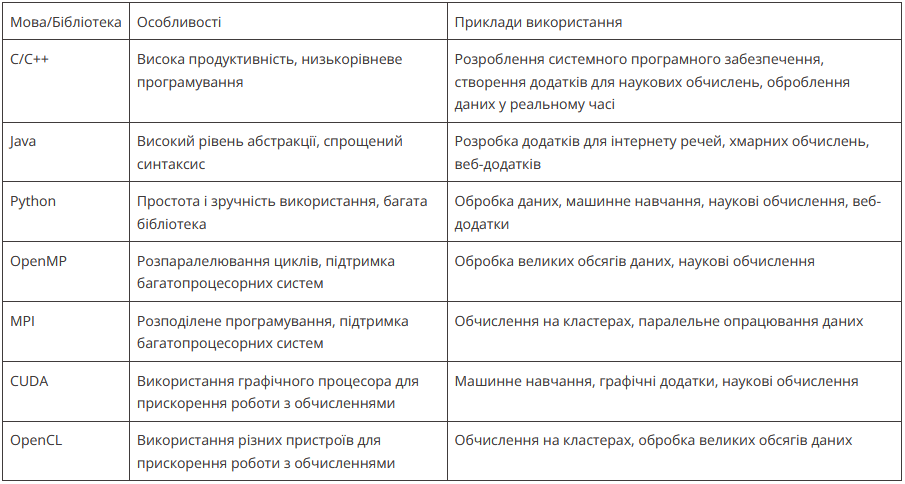
Приклади використання кожної мови та бібліотеки можуть варіюватися залежно від конкретного завдання, однак загалом усі вони надають інструменти для паралельного програмування та прискорення обчислень на багатопроцесорних системах.
Альтернативою паралельному програмуванню можна назвати різні методи оптимізації послідовного коду, наприклад, використання векторизації, оптимізацію пам’яті та профілювання. Також можна використовувати спеціалізовані процесори, як-от графічні процесори (GPU) та Field-Programmable Gate Arrays (FPGA), які здатні обробляти великі обсяги даних паралельно та забезпечувати високу продуктивність. Однак, паралельне програмування залишається найпотужнішим інструментом для опрацювання великих обсягів даних і розв’язання складних завдань.
Паралельне програмування – це важлива технологія, яка може підвищити продуктивність і прискорити обробку великих обсягів даних. Це може бути особливо корисно для проєктів, пов’язаних із науковими дослідженнями, машинним навчанням, аналізом даних та іншими обчислювально інтенсивними завданнями. Однак, воно також може бути складним і вимагати врахування багатьох факторів, включно з проблемами синхронізації даних і складнощами налагодження. Використання правильних моделей паралельного програмування, мов програмування і бібліотек може допомогти впоратися з цими проблемами і отримати максимальну вигоду від паралельних обчислень.
Загалом, правильне застосування паралельного програмування може значно поліпшити продуктивність проєктів програмного забезпечення.
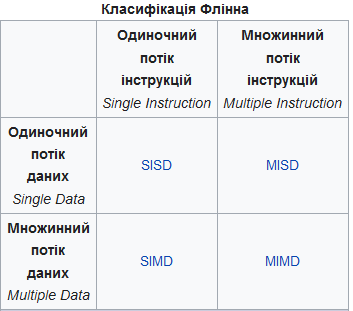
Таксономія (Класифікація) Флінна (англ. Flynn's taxonomy) — загальна класифікація архітектур ЕОМ за ознаками наявності паралелізму в потоках команд (інструкцій) і даних. Була запропонована 1966 року М. Флінном (M. Flynn)[1], означення розширене у публікації 1972 року[2]. Вся розмаїтість архітектур ЕОМ в цій таксономії Флінна зводиться до чотирьох класів:
SISD (single instruction — single data) — одиночний потік команд і даних. Паралелізм відсутній. До цієї категорії відносяться послідовні архітектури, у тому числі й фон-нойманівского типу.
SIMD (single instruction — multiple data) — одиночний потік команд і декілька потоків даних. Паралелізм в таких архітектурах полягає в можливості одночасного виконання однієї й тої ж операції над декількома елементами даних. Досягається це централізованою видачею команд декільком обчислювальним пристроям спільним для них пристроєм управління. Найпоширенішими представниками архітектур типу SIMD є так звані векторні ЕОМ, оптимізовані для паралельного виконання однотипних операцій над елементами векторів і матриць. Спеціалізовані векторні процесори іноді вбудовуються в комп'ютери загального призначення. Зокрема, в багатьох сучасних мікропроцесорах вбудовані обмежені можливості векторних обчислень для обробки мультимедіа.
MISD (multiple instruction — single data) — декілька потоків команд, одиночний потік даних. Фахівці дотепер не прийшли до єдиної думки щодо того, які архітектури відносити до даного класу. Деякі включають у нього конвеєрні обчислювачі, в яких цілісна операція розбивається на послідовність простіших етапів з суміщенням різних етапів для різних порцій даних у часі. Таким чином, в певному кожна порція даних від моменту завантаження з пам'яті до запису результату обробки проходить через декілька етапів обробки (стадій конвеєра). Подібні принципи покладені в основу систолічних архітектур, які також належать до цього класу.
MIMD (multiple instructions — multiple data) — декілька потоків команд і даних. Найпоширеніший на сьогодні клас паралельних архітектур, у яких кожний процесор здатний працювати незалежно від інших над своїм завданням.