

9.2. Принципи та сфера застосування видів програмування: функціональне, логічне, подійне-орієнтоване, реактивне, узагальнене програмування
Функційне програмування — парадигма програмування, яка розглядає програму як обчислення математичних функцій та уникає станів та змінних даних. Функційне програмування наголошує на застосуванні функцій, на відміну від імперативного програмування, яке наголошує на змінах в стані та виконанні послідовностей команд.
Іншими словами, функційне програмування є способом створення програм, в яких єдиною дією є виклик функції, єдиним способом розбиття програми є створення нового імені функції та задання для цього імені виразу, що обчислює значення функції, а єдиним правилом композиції є оператор суперпозиції функцій. Жодних комірок пам'яті, операторів присвоєння, циклів, ні, тим більше, блок-схем чи команд переходу.
Ширша концепція функційного програмування визначає набір спільних правил та тем замість переліку відмінностей від інших парадигм. До таких, що часто вважаються важливими, належать функції вищого порядку[2] та функції першого класу: замикання, та рекурсія. До інших поширених можливостей функційних мов програмування належать продовження, система типізації Гіндлі — Мілнера[en], нечіткі обчислення (включно з, але, не обмежуючись, лінивими обчисленнями), та монади.
Основну увагу функційним мовам програмування, особливо, «чисто функційним», приділили академічні дослідники. Однак, до відомих функційних мов програмування, які використовуються в промисловості та комерційному програмуванні належить Erlang (паралельні програми), R (статистика), Mathematica (символьні обчислення), J та K (фінансовий аналіз), та спеціалізовані мови програмування наприклад XSLT. Істотний вплив на функційне програмування здійснило лямбда-числення, мова програмування APL, мова програмування Lisp та новіша мова програмування Haskell.
Функційне програмування часто називають «функціональним», хоча насправді функціонально-орієнтоване програмування — це інша категорія, де основою є компонування програм у ряд програмних продуктів.
Найвідомішими мовами функційного програмування є:
XQuery;
Haskell — чиста функційна мова. Названа на честь Гаскелла Каррі;
Lisp (Джон Маккарті, 1958, має безліч нащадків, найсучасніші з яких — Scheme і Common Lisp);
ML (Робін Мілнер, 1979, з нині використовуваних діалектів відомі Standard ML і Objective Caml);
Miranda (Девід Тернер, 1985, який згодом дав розвиток мові Haskell);
Erlang — (Joe Armstrong, 1986) функційна мова з моделлю акторів.
Nemerle — гібридна функційно/імперативна мова;
F# — функційна мова для платформи .NET;
Scala — гібридна об'єктно-орієнтована/функційна мова для платформи Java;
Clojure — функційна мова для платформи Java.
Ще не повністю функційні початкові версії Lisp і APL зробили особливий внесок до створення і розвитку функційного програмування. Пізніші версії Lisp, такі як Scheme, а також різні варіанти APL, підтримували властивості і концепції функційної мови.
Як правило, інтерес до функційних мов програмування, особливо чисто функційних, був більше науковий, ніж комерційний. Проте, таким примітним мовам як Erlang, OCaml, Haskell, Scheme (після 1986), а так само специфічним R (статистика), Mathematica (символічна математика), J і K (фінансовий аналіз), і XSLT (XML) знаходили застосування в індустрії комерційного програмування. Такі широко поширені декларативні мови як SQL і Lex/Yacc містять деякі елементи функційного програмування, вони остерігаються використовувати змінні.
Деякі концепції та парадигми специфічні для функційного програмування і в основному чужі імперативному програмуванню (включаючи об'єктно-орієнтоване програмування). Тим не менш, мови програмування звичайно являють собою гібрид декількох парадигм програмування, тому «здебільшого імперативні» мови програмування можуть використовувати які-небудь з цих концепцій.
Функції вищих порядків — це такі функції, які можуть приймати як аргументи і повертати інші функції.[9] Математики таку функцію частіше називають оператором, наприклад, оператор взяття похідної або інтегральний оператор.
Функції вищих порядків дозволяють використовувати каррінг — перетворення функції від пари аргументів у функцію, що бере свої аргументи по одному. Це перетворення отримало свою назву на честь Гаскелла Каррі.
Чистими називають функції, які не мають побічних ефектів вводу-виводу і пам'яті (вони залежать тільки від своїх параметрів і повертають тільки свій результат). Чисті функції володіють декількома корисними властивостями, багато з яких можна використовувати для оптимізації коду:
Якщо результат чистої функції не використовується, він може бути видалений без шкоди для інших виразів.
Результат виклику чистої функції може бути кешований, тобто збережений в таблиці значень разом з аргументами виклику. Якщо надалі функція викликається з цими ж аргументами, її результат може бути взятий прямо з таблиці без її повторного обчислення (іноді це називається принципом прозорості посилань). Кешування, ціною невеликої затрати пам'яті, дозволяє істотно збільшити швидкодію і зменшити глибину рекурсії в деяких алгоритмах.
Якщо немає ніякої залежності серед даних між двома чистими функціями, то порядок їх обчислення можна поміняти (інакше кажучи обчислення чистих функцій задовольняє принципам thread-safe)
Якщо вся мова не допускає побічних ефектів, то можна використовувати будь-яку політику обчислення. Це надає свободу компілятору комбінувати і реорганізовувати обчислення виразів у програмі (наприклад, виключити деревоподібні структури).
Хоча більшість компіляторів імперативних мов програмування розпізнають чисті функції і видаляють загальні підвирази для викликів чистих функцій, вони не можуть робити це завжди для попередньо скомпільованих бібліотек, які, як правило, не надають цю інформацію. Деякі компілятори, такі як gcc, з метою оптимізації надають програмісту ключові слова для позначення чистих функцій[10]. Fortran 95 дозволяє позначати функції як «pure»[11].
У функційних мовах цикл зазвичай реалізується у вигляді рекурсії. Власне, у функційної парадигми програмування немає такого поняття, як цикл. Рекурсивні функції викликають самі себе, дозволяючи операції виконуватися знову і знову. Для використання рекурсії може знадобитися великий стек, але цього можна уникнути в разі хвостової рекурсії. Хвостова рекурсія може бути розпізнана і оптимізована компілятором в код, одержуваний після компіляції, аналогічної ітерації в імперативній мові програмування.[12] Стандарти мови Scheme вимагають розпізнавати і оптимізувати хвостову рекурсію. Оптимізувати хвостову рекурсію можна шляхом перетворення програми в стилі використання продовжень при її компіляції, як один із способів.
Рекурсивні функції можна узагальнити за допомогою функцій вищих порядків, використовуючи, наприклад, катаморфізм і анаморфізм (або «згортка» і «розгорнення»). Функції такого роду відіграють роль такого поняття, як цикл в імперативних мовах програмування.
Підхід до обчислення аргументів. Функційні мови можна класифікувати по тому, як обробляються аргументи функції в процесі її обчислення. Технічно відмінність полягає в денотаційній семантиці виразу. Наприклад, при строгому підході до обчислення виразу
print (len ([2 +1, 3 * 2, 1/0, 5-4]))
на виході буде помилка, оскільки в третьому елементі списку присутнє ділення на нуль. При нестрогому підході значенням виразу буде 4, оскільки для обчислення довжини списку значення його елементів, строго кажучи, не важливі і можуть взагалі не обчислюватися. При строгому (аплікативному) порядку обчислення заздалегідь підраховуються значення всіх аргументів перед обчисленням самої функції. При нестрогому підході (нормальний порядок обчислення) значення аргументів не обчислюються до тих пір, поки їх значення не знадобляться при обчисленні функції.
Як правило, нестрогий підхід реалізується у вигляді редукції графа. Нестроге обчислення використовується за замовчуванням в декількох чисто функційних мовах, у тому числі Miranda, Clean і Haskell.[джерело?]
ФП в нефункційних мовах. Принципово немає перешкод для написання програм у функційному стилі на мовах, які традиційно не вважаються функційними, точно так само, як програми в об'єктно-орієнтованому стилі можна писати на структурних мовах. Деякі імперативні мови підтримують типові для функційних мов конструкції, такі як функції вищого порядку і спискові включення (list comprehensions), що полегшує використання функційного стилю в цих мовах. Прикладом може бути програмування на мові Python.
У мові C покажчики на функцію як типи аргументів можуть бути використані для створення функцій вищого порядку. Функції вищого порядку і відкладена списковому структура реалізовані в бібліотеках C++. У мові C # версії 3.0 і вище можна використовувати λ-функції для написання програми в функційному стилі. У складних мовах, типу Алгол-68, наявні засоби метапрограмування (фактично, доповнення мови новими конструкціями) дозволяють створити специфічні для функційного стилю об'єкти даних і програмні конструкції, після чого можна писати функційні програми з їх використанням.
Структури даних. Чисто функціональні структури даних часто представлені інакше, ніж їх процедурні аналоги.[15] Наприклад, масив з постійним доступом і часом оновлення є основним компонентом більшості імперативних мов, і багато імперативних структур даних, таких як геш-таблиця і двійкова купа, засновані на масивах. Масиви можна замінити асоціативними масивами або списками випадкового доступу, які допускають суто функціональну реалізацію, але мають логарифмічний доступ і час оновлення. Чисто функціональні структури даних мають стійкість, тобкто властивість зберігати попередні версії структури даних незмінними. У Clojure постійні структури даних використовуються як функціональні альтернативи їхнім імперативним аналогам.
Стилі програмування. Імперативні програми мають схильність акцентувати послідовності кроків для виконання якоїсь дії, а функційні програми до розташування і композиції функцій, часто не позначаючи точної послідовності кроків. Простий приклад двох рішень однієї задачі (використовується одна і та ж мова Python) ілюструє це.
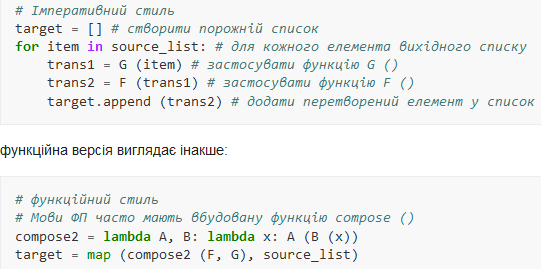
На відміну від імперативного стилю, що описує кроки, що ведуть до досягнення мети, функційний стиль описує математичні відносини між даними і метою.
Особливості. Основною особливістю функційного програмування, яка визначає як переваги, так і недоліки даної парадигми, є те, що в ній реалізується модель обчислень без станів. Якщо імперативна програма на будь-якому етапі виконання має стан, тобто сукупність значень всіх змінних, і виробляє побічні ефекти, то чисто функційна програма ні цілком, ні частинами стану не має і побічних ефектів не виробляє. Те, що в імперативних мовах робиться шляхом присвоювання значень змінним, в функційних досягається шляхом передачі виразів в параметри функцій. Безпосереднім наслідком стає те, що чисто функційна програма не може змінювати вже наявні в ній дані, а може лише породжувати нові, шляхом копіювання та / або розширення старих. Наслідком того ж є відмова від циклів на користь рекурсії.
Сильні сторони. Підвищення надійності коду. Приваблива сторона обчислень без станів — підвищення надійності коду за рахунок чіткої структуризації та відсутності необхідності відстеження побічних ефектів. Будь-яка функція працює тільки з локальними даними і працює з ними завжди однаково, незалежно від того, де, як і за яких обставин вона викликається. Неможливість мутації даних при користуванні ними в різних місцях програми виключає появу помилок, які тяжко виявити (таких, наприклад, як випадкове присвоювання невірного значення глобальній змінній в імперативній програмі).
Зручність організації модульного тестування. Оскільки функція у функційному програмуванні не може породжувати побічні ефекти, змінювати об'єкти не можна як усередині області видимості, так і зовні (на відміну від імперативних програм, де одна функція може встановити яку-небудь зовнішню змінну, що зчитується іншою функцією). Єдиним ефектом від обчислення функції є повернений їй результат, і єдиний чинник, який впливає на результат — це значення аргументів.
Таким чином, є можливість протестувати кожну функцію в програмі, просто обчисливши її від різних наборів значень аргументів. При цьому можна не турбуватися ні про виклик функцій в правильному порядку, ні про правильне формуванні зовнішнього стану. Якщо будь-яка функція в програмі проходить модульні тести, то можна бути впевненим у якості всієї програми. В імперативних програмах перевірка значення, що повертається функції, недостатня: функція може модифікувати зовнішній стан, який теж потрібно перевіряти, чого не потрібно робити в функційних програмах[16].
Можливості оптимізації при компіляції. Традиційно згадуваною позитивною особливістю функційного програмування є те, що воно дозволяє описувати програму в так званому «декларативному» вигляді, коли жорстка послідовність виконання багатьох операцій, необхідних для обчислення результату, в явному вигляді не задається, а формується автоматично в процесі обчислення функцій. Ця обставина, а також відсутність станів дає можливість застосовувати до функційних програм досить складні методи автоматичної оптимізації.
Можливості паралелізму. Ще однією перевагою функційних програм є те, що вони надають найширші можливості для автоматичного розпаралелювання обчислень. Оскільки відсутність побічних ефектів гарантовано, в будь-якому виклику функції завжди припустиме паралельне обчислення двох різних параметрів — порядок їх обчислення не може вплинути на результат виклику.
Недоліки функційного програмування випливають з тих же самих його особливостей. Відсутність присвоювання і заміна їх на породження нових даних призводять до необхідності постійного виділення та автоматичного звільнення пам'яті, тому в системі виконання функційної програми обов'язковим компонентом стає високоефективний збирач сміття. Нестрога модель обчислень призводить до непередбачуваного порядку виклику функцій, що створює проблеми при введенні-виведенні, де порядок виконання операцій є важливим. Крім того, очевидно, функції введення в своєму природному вигляді (наприклад, getchar із стандартної бібліотеки мови C) не є чистими, оскільки здатні повертати різні значення для одних і тих же аргументів, і для усунення цього потрібні певні хитрощі.
Для подолання недоліків функційних програм вже перші мови функційного програмування включали не тільки чисто функційні засоби, але і механізми імперативного програмування (присвоєння, цикл, «неявний PROGN» були вже в LISP'і). Використання таких засобів дозволяє вирішити деякі практичні проблеми, але означає відхід від ідей (і переваг) функційного програмування і написання імперативних програм функційними мовами. У чистих функційних мовах ці проблеми вирішуються іншими засобами, наприклад, в мові Haskell ввід-вивід реалізований за допомогою монади — нетривіальної концепції, запозиченої з теорії категорій.
Функціональне програмування – одна з найпопулярніших парадигм програмування, яка дедалі більше і більше привертає увагу розробників з усього світу. Це підхід, який базується на математичних функціях та їхніх комбінаціях для розв’язання задач. Але що таке функціональне програмування і чому воно таке важливе для сучасної розробки програмного забезпечення? У цій статті ми розберемося в основних принципах функціонального програмування, розглянемо популярні функціональні мови програмування та дізнаємося, як функціональне програмування допомагає розробникам створювати більш надійні та стійкі додатки.
Функціональне програмування – це парадигма програмування, заснована на використанні функцій як основного будівельного блоку програми.
У функціональному програмуванні дані вважаються незмінними, а функції – чистими, тобто такими, що не мають побічних ефектів і завжди повертають однаковий результат для заданих вхідних параметрів. Функціональне програмування дає змогу створювати надійніші та стійкіші програми, які простіше тестувати та підтримувати.
Основні особливості функціонального програмування включають у себе використання чистих функцій, незмінних даних, рекурсії та ледачих обчислень. Функціональне програмування також підтримує композицію функцій і роботу з функціями вищого порядку. Завдяки цим особливостям воно має низку переваг перед іншими парадигмами програмування, такими як підвищена надійність і стійкість програм, поліпшена паралелізація і можливість створення коду, який можна прочитати та який є модульним.
Функціональне програмування також має багато інших особливостей, таких як високий рівень абстракції, лаконічність і простота синтаксису, можливість паралельного виконання коду тощо. Усі ці особливості роблять функціональне програмування потужним і гнучким інструментом для розробки програмного забезпечення.
Основні концепції функціонального програмування являють собою набір методів і принципів, які дають змогу створювати чистіші, гнучкіші та масштабовані програми. Використання цих концепцій допомагає поліпшити якість коду і спростити процес розроблення програмних додатків. Перелічимо основні з них:
Чисті функції – це функції, які не мають побічних ефектів і завжди повертають однаковий результат для заданих вхідних параметрів. Такі функції надійніші та легше тестувати.
Незмінність даних – у функціональному програмуванні дані вважаються незмінними, і зміна даних відбувається шляхом створення нових об’єктів. Це дає змогу уникнути помилок, пов’язаних зі зміною одних і тих самих даних різними частинами програми.
Рекурсія – у функціональному програмуванні використовуються функції, які викликають самі себе. Рекурсія дає змогу описувати складні операції, як-от обхід дерев або обчислення факторіалу, більш просто й елегантно.
Функціональні типи даних – у функціональному програмуванні типи даних визначаються як множини значень, а не набори операцій. Такі типи даних забезпечують вищий ступінь абстракції та узагальнення, що спрощує написання коду.
Композиція функцій дозволяє створювати нові функції з існуючих, що є одним з основних принципів функціонального програмування - повторне використання коду.
Ліниві обчислення - це ще одна концепція, яка дозволяє обчислювати значення тільки в той момент, коли воно дійсно необхідне для виконання програми, що зменшує споживання ресурсів.
Currying – це ще один важливий концепт функціонального програмування, який дає змогу легко комбінувати функції та створювати нові функції за допомогою вже наявних.
Функціональні мови програмування – це ті мови, які ґрунтуються на функціональному програмуванні. Популярність функціональних мов програмування пояснюється їхньою здатністю створювати код, який простіше піддається аналізу, тестуванню та оптимізації. Крім того, вони дозволяють програмістам писати програми більш декларативно, що може призвести до підвищення продуктивності та скорочення часу розробки. Також функціональні мови програмування можуть використовуватися для створення паралельних і розподілених систем, що актуально в наш час. Перелічимо основні:
Haskell – чиста функціональна мова програмування, що використовується для розробки складних систем та алгоритмів. Вона популярна завдяки своїй виразності, потужності та безпеці. Haskell має безліч можливостей для абстракції та композиції функцій, а також для ледачих обчислень.
Clojure – динамічна функціональна мова програмування, що працює на платформі Java. Вона популярна завдяки своїй простоті та елегантності. Clojure підтримує незмінність даних, функції вищого порядку, ледачі обчислення та має потужні механізми для роботи з послідовностями даних.
Scala – об’єктно-орієнтована та функціональна мова програмування, яка працює на платформі Java. Scala популярна завдяки своїй гнучкості та можливості використання як функціонального, так і об’єктно-орієнтованого стилю програмування. Вона має потужну систему типів, підтримує ліниві обчислення та роботу з незмінними даними.
F# – функціональна мова програмування, розроблена компанією Microsoft для платформи .NET. Вона поєднує можливості функціонального та об’єктно-орієнтованого програмування і використовує сильну статичну типізацію.
Erlang – функціональна мова програмування, спочатку розроблена для створення розподілених систем. Вона підтримує паралельне та розподілене програмування, має високу відмовостійкість і масштабованість.
OCaml – функціональна мова програмування, що використовує статичну типізацію і підтримує об’єктно-орієнтоване програмування. Вона широко використовується в академічних колах і в індустрії.
Lisp – одна з найстаріших функціональних мов програмування, яку було розроблено 1958 року. Lisp використовується для розробки штучного інтелекту, комп’ютерної лінгвістики та інших галузей.
Крім іншого, ці мови програмування мають розвинені екосистеми, що включають бібліотеки та інструменти для розробки.
Переваги та недоліки функціонального програмування
У функціональному програмуванні основний акцент робиться на те, як програмувати, а не на те, що програмувати. Це означає, що у функціональному програмуванні код пишеться в термінах функцій, а не в термінах послідовності інструкцій. Такий підхід дає низку переваг, але й має деякі обмеження та недоліки;
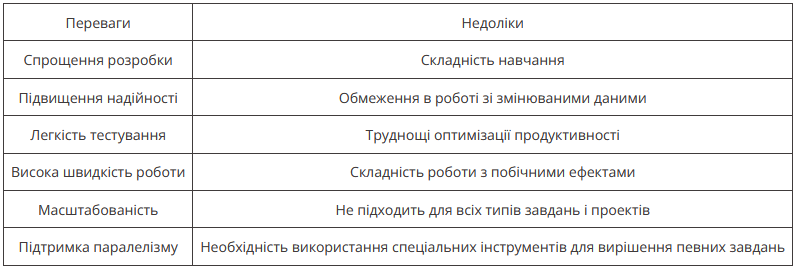
Зазначені в таблиці переваги та недоліки не стосуються кожної мови програмування, яка застосовує функціональний підхід, але вони представляють загальні ідеї, пов’язані з функціональним програмуванням загалом.
Концепції функціонального програмування давно використовуються в різних сферах та індустріях і привели до безлічі успіхів. Ось деякі з прикладів:
Мова програмування Haskell використовується у фінансовій індустрії для створення безпечних і надійних фінансових додатків. Наприклад, банк Standard Chartered використовує Haskell для створення своєї системи обробки транзакцій;
Spotify використовує функціональне програмування у своїй системі потокової передачі музики. Вони використовують мову програмування Erlang і його фреймворк OTP (Open Telecom Platform) для створення високоефективної та відмовостійкої системи.
Компанія Jane Street Capital, що займається торгівлею на фінансових ринках, використовує OCaml для створення високопродуктивних і безпечних торгових систем.
Мова програмування Clojure використовується в бекенді різних веб-сервісів, таких, як Amazon Web Services і Walmart.
Ще приклад застосування функціонального програмування в реальному світі – частина бекенда Facebook, яка була написана на Haskell, а також у модулі онлайн-спам-фільтра застосовували суміш Haskell/C++, яка обробляє до мільйона повідомлень на секунду;
Усі ці приклади демонструють, що функціональне програмування може бути ефективним і надійним рішенням для створення складних систем у різних сферах застосування.
Функціональне програмування є важливою парадигмою програмування, яка набуває дедалі більшої популярності. Переваги функціонального програмування, такі як спрощення розроблення, підвищення надійності та легкість тестування, роблять його привабливим вибором для багатьох проєктів (що демонструють реальні приклади проєктів). Однак, функціональне програмування також має свої обмеження і недоліки, і повинно бути застосовано з урахуванням контексту конкретного проєкту.
Логі́чне програмування — парадигма програмування, та також розділ дискретної математики, що вивчає методи і можливості цієї парадигми, засновані на виведенні нових фактів з даних фактів відповідно із заданими логічними правилами. Логічне програмування засноване на теорії математичної логіки. Найвідомішою мовою логічного програмування є Prolog, що є за своєю суттю універсальною машиною виводу, що працює в припущенні замкненості системи фактів.
Першою мовою логічного програмування була мова Planner, в якій була закладена можливість автоматичного виведення результату з даних і заданих правил перебору варіантів. Planner використовували для, зниження вимог до обчислювальних ресурсів (за допомогою методу пошуку з поверненням) і для виведення фактів без активного використання стеку. Потім була розроблена мова Prolog, яка не вимагала плану перебору варіантів і була, в цьому сенсі, спрощенням мови Planner.
На основі ідей Planner були створені такі мови логічного програмування, як: QA-4, Popler, Conniver і QLISP. Мови програмування Mercury[en], Visual Prolog[en], Oz[en] і Fril[en] були створені на основі Prolog. На основі мови Planner було розроблене також декілька альтернативних мов логічного програмування, не заснованих на методі пошуку з поверненням, наприклад, Ether.
Для будь-якої системи логічного програмування характерним є те, що для виконання програми (побудови виведення результату) використовується вмонтована система автоматичного пошуку. Механізм пошуку логічного висновку Prolog-у бере свій початок від методу резолюцій Робінсона. Правило резолюції виведення логічного висновку працює наступним чином: дві фрази можуть резольвувати між собою, коли одна з них має позитивний, а друга — негативний літерал з одним і тим самим позначенням предиката та однаковою кількістю аргументів і в разі, якщо аргументи обох літералів можуть бути уніфіковані (погоджені). Наприклад, фраза P(a, b) o Q(c, d) і фраза Q(c, d) o R(b, c) дають резольвенту P(a, b) o R(b, c). Якщо ж аргументом відношення є змінна, то вона уніфікується з константою, а резольвента буде мати дану константу на місцях попереднього розташування змінної. Розглянемо дві фрази спеціального вигляду: Р(а) — висловлювання без умови і oP(а) — умова без висловлювання. Наявність цих двох фраз в одній теорії є протиріччям. Якщо вони резольвуються між собою, тоді отримана резольвента називається порожньою фразою. Якщо при резолюції двох фраз, що входять до складу теорії, отримується порожня фраза, то теорія буде непослідовною.
Логічне програмування – це підхід до програмування, в якому основний наголос робиться на логічне слідування і декларативний характер опису програми. У цій статті ми розглянемо основні принципи логічного програмування, мову програмування Prolog і застосування логічного програмування в різних галузях.
Принципи логічного програмування. У логічному програмуванні програміст не описує послідовність дій, необхідних для розв’язання задачі, а скоріше описує знання і факти, які мають бути враховані для розв’язання задачі. Програма мовою логічного програмування являє собою набір правил і фактів, що описують відносини між об’єктами і причинно-наслідкові зв’язки.
Логічне слідування – це основний принцип логічного програмування. Воно дає змогу отримувати нові факти з уже відомих, а також робити висновки на основі наявної інформації. Під час виконання програми мовою логічного програмування система прагне отримати правильну відповідь, знаходячи логічні послідовності з фактів і правил.
У логічному програмуванні процедури і функції нерозрізнені, тобто вони описують відносини між об’єктами, а не послідовність дій. Обробка списків – це ще один принцип логічного програмування, який дає змогу програмі працювати з набором даних у вигляді списків.
Мова програмування Prolog – це мова, розроблена для логічного програмування. Вона використовується для розв’язання різних завдань, таких як обробка природних мов, розробка експертних систем і розв’язання завдань штучного інтелекту.
Синтаксис і структура програми в Prolog можуть бути незнайомими для програмістів, які використовують імперативні мови програмування. Програми на Prolog складаються з фактів і правил, що описують відносини між об’єктами. Терми і змінні – це основні елементи мови, що використовуються для опису фактів і правил. Уніфікація – це процес, що використовується для перевірки відповідності термів.
Рекурсія – це важливий елемент мови Prolog, який дає змогу програмі викликати саму себе для розв’язання задач. На відміну від імперативних мов, де рекурсія може призвести до переповнення стека, у Prolog вона часто використовується для організації циклів та ітерацій.
Мова Prolog містить безліч вбудованих предикатів, які розширюють її можливості. Деякі з найбільш часто використовуваних конструкцій:
assert — додає факт або правило в базу даних програми;
retract — видаляє факт або правило з бази даних програми;
cut — відсікає подальший пошук альтернативних рішень під час виконання програми;
fail — примусово перериває виконання програми і переходить до пошуку наступного рішення.
Логічне програмування застосовується в багатьох галузях, таких як:
Розробка експертних систем – систем, заснованих на знаннях експертів, які використовують логічні висновки для ухвалення рішень.
Обробка природних мов – галузь, пов’язана зі створенням систем, які можуть обробляти природну мову і відповідати на запитання.
Розв’язання задач штучного інтелекту – системи, що використовують логічне програмування для розв’язання задач у галузі штучного інтелекту.
Приклади реалізації в різних галузях: комп’ютерний зір, біоінформатика, планування тощо.
Переваги логічного програмування:
Декларативний підхід – програміст описує бажаний результат, а не послідовність команд для його отримання.
Автоматичне опрацювання деяких видів даних – багато завдань, пов’язаних з опрацюванням баз знань, можуть бути легко вирішені за допомогою логічного програмування.
Зручність розв’язання задач штучного інтелекту – логічне програмування дає змогу природно описувати знання і правила в галузі штучного інтелекту.
Недоліки логічного програмування:
Неефективність у деяких випадках – логічні мови програмування можуть бути менш ефективними, ніж імперативні або функціональні мови програмування, у розв’язанні певних завдань, особливо під час роботи з великими обсягами даних.
Труднощі у створенні складних програм – логічне програмування може бути складнішим для розуміння і створення складних програм, ніж інші мови програмування. Це пов’язано з особливостями логічного слідування та принципами декларативного програмування.
Проблеми з підтримкою і налагодженням – у деяких випадках, логічні програми можуть бути складними для налагодження, особливо коли вони працюють з великими обсягами даних. Крім того, програмістам можуть знадобитися спеціальні навички для розуміння і редагування логічних програм.
Загалом, незважаючи на свої недоліки, логічне програмування має багато переваг і широко використовується для розв’язання складних задач штучного інтелекту та розробки експертних систем.
Логічне програмування являє собою декларативний підхід до програмування, який використовує логічне слідування для виведення результатів. Мова програмування Prolog є однією з найпопулярніших логічних мов програмування, що використовується для розроблення експертних систем, опрацювання природних мов, розв’язування задач штучного інтелекту та інших галузей.
Переваги логічного програмування включають декларативний підхід, автоматичне опрацювання деяких видів даних і зручність розв’язання задач штучного інтелекту. Недоліки логічного програмування включають неефективність у деяких випадках, складність у створенні складних програм і проблеми з підтримкою та налагодженням.
Подійно-орієнтоване програмування (англ. event-driven programming; надалі ПОП) — парадигма програмування, в якій виконання програми визначається подіями — діями користувача (клавіатура, миша), повідомленнями інших програм і потоків, подіями операційної системи (наприклад, надходженням мережевого пакета).
ПОП можна також визначити як спосіб побудови комп'ютерної програми, при якому в коді (як правило, в головний функції програми) явним чином виділяється головний цикл програми, тіло якого складається з двох частин: отримання повідомлення про подію і обробки події.
Як правило, в реальних завданнях виявляється неприпустимим тривале виконання обробника події, оскільки при цьому програма не може реагувати на інші події. У зв'язку з цим при написанні подійно-орієнтованих програм часто застосовують автоматне програмування.
Подійно-орієнтоване програмування, зазвичай застосовують у трьох випадках:
При побудові користувацьких інтерфейсів (в тому числі графічних);
При створенні серверних застосунків у разі, якщо з тих чи інших причин небажано породження обслуговуючих процесів;
При програмуванні ігор, в яких здійснюється управління значною кількістю об'єктів.
Застосування в серверних програмах. Подійно-орієнтоване програмування застосовується в серверних програмах для вирішення проблеми масштабування на 10000 одночасних з'єднань і більше.
У серверах, побудованих за моделлю «один потік на з'єднання», проблеми з масштабованістю виникають з наступних причин:
Занадто великі накладні витрати на структури даних операційної системи, необхідні для опису однієї задачі (сегмент стану завдання, стек);
Занадто великі накладні витрати на перемикання контекстів.
Філософською передумовою для відмови від потокової моделі серверів може служити вислів Алана Кокса: «Комп'ютер - це кінцевий автомат. Потокове програмування потрібно тим, хто не вміє програмувати кінцеві автомати »[1].
Серверний застосунок при подійно-орієнтованому програмуванні реалізується на системному виклику, який отримує повідомлення події одночасно від багатьох дескрипторів (мультиплексування). При обробці подій використовуються виключно неблокуючі операції введення-виведення, щоб ні один дескриптор не перешкоджав обробці подій від інших дескрипторів.
Для мультиплексування (передача даних з багатьох каналів через один) сполук можуть бути використані наступні засоби операційної системи:
Select (більшість UNIX систем). Погано масштабується, через те, що список дескрипторів представлений у вигляді бітової карти;
Poll і epoll (Linux);
Kqueue (FreeBSD);
/Dev/poll ( Solaris);
IO completion port (Windows);
POSIX AIO на поточний момент тільки для операцій дискового введення-виведення;
Io submit і eventfd для операцій дискового введення-виведення.
Приклади реалізацій.
Вебсервери:
Nginx
Lighttpd
Проксі-сервери:
Squid
Серверні платформи
node.js
Застосування в настільних програмах. У сучасних мовах програмування події та обробники подій є центральною ланкою реалізації графічного інтерфейсу користувача. Розглянемо, наприклад, взаємодію програми з подіями від миші. Натискання правої клавіші миші викликає системне переривання, що запускає певну процедуру всередині операційної системи. У цій процедурі відбувається пошук вікна, що знаходиться під курсором миші. Якщо вікно знайдено, то дана подія надсилається в чергу обробки повідомлень цього вікна. Далі, в залежності від типу вікна, можуть генеруватися додаткові події. Наприклад, якщо вікно є кнопкою (у Windows всі графічні елементи є вікнами), то додатково генерується подія натискання на кнопку. Відмінність останньої події в тому, що вона більш абстрактна, а саме, не містить координат курсору, а говорить просто про те, що було вироблено натискання на цю кнопку.
Обробник події може виглядати наступним чином (на прикладі C #):
private void button1_Click (object sender, EventArgs e)
{
MessageBox.Show ("Була натиснута кнопка");
}
Тут обробник події є процедурою, в яку передається параметр sender, як правило містить покажчик на джерело події. Це дає змогу використовувати одну й ту ж процедуру для обробки подій від декількох кнопок, розрізняючи їх за цим параметром.
У мові C# події реалізовані як елемент мови і є членами класів. Механізм подій тут реалізує шаблон проектування Publisher / Subscriber. Приклад оголошення події:
public class MyClass
{
public event EventHandler MyEvent;
}
ТутEventHandler- делегат, що визначає тип процедури обробника подій. Підписка на подію проводиться таким чином:
myClass.MyEvent + = new EventHandler (Handler);
ТутmyClass- екземпляр класуMyClass,Handler- процедура-обробник. Подія може мати необмежену кількість обробників. При додаванні обробника події він додається до спеціального стек, а при виникненні події викликаються всі обробники за їх порядку в стеці. Відписка від події, тобто видалення обробника виконується аналогічно, але з використанням оператора «-=».
Різні мови програмування підтримують ПОП в різному ступені. Найповнішу підтримку подій мають наступні мови (неповний список):
Perl
Java
Delphi
C #
Інші мови, в більшості з них, підтримують події як обробку виключних ситуацій.
Реактивне програмування — це парадигма програмування, побудована на потоках даних і розповсюдженні змін. Це означає, що у мовах програмування має бути можливість легко виразити статичні чи динамічні потоки даних, а реалізована модель виконання буде автоматично розсилати зміни через потік даних.
Наприклад, в імперативному програмуванні вираз, a := b + c означає, що a отримує результат виконання b + c безпосередньо під час обчислення виразу, і потім, якщо значення b і c зміняться, це не впливатиме на вже обчислене значення a.
Проте, в реактивному програмуванні значення a буде автоматично оновлено за новими значеннями, що є протилежністю функційного програмування.
Сучасна програма електронної таблиці є прикладом реактивного програмування. Комірки електронної таблиці можуть мати буквальні значення, або формули типу «=B1+C1», що обчислюються за значеннями інших комірок. Коли б не змінилося значення іншої комірки, значення формули оновлюється автоматично.
Інший приклад — це мова опису апаратури типу Verilog. У цьому випадку, реактивне програмування дозволяє моделювати зміни по ходу їх розповсюдження по електричному ланцюгу.
Реактивне програмування спочатку пропонувалося як засіб простого створення інтерфейсів користувача, анімацій у системах реального часу, але стало загальною парадигмою програмування.
Наприклад, у архітектурі Модель-вид-контролер, реактивне програмування дозволяє змінам у моделі автоматично відображатися у виді, і навпаки.
Концепції. Ступені експліцитности. Реактивні мови програмування можуть різнитись від дуже явних, де потоки даних встановлюються через використання стрілок, до неявних, де потоки даних є похідними від мовних конструкцій, як у імперативному або функційному програмуванні. Наприклад, в неявно викликаному функціонального реактивному програмуванні (FRP) виклик функції може неявно спричинити побудову вузла в графі потоку даних. Реактивні бібліотеки програмування для динамічних мов (такі як «Cells» у Ліспі та «Trellis» для Python'у), можуть будувати граф залежностей через аналіз значень, зчитуваних під час виконання певної функції, дозволяючи специфікації потоку даних бути як неявною, так і динамічною.
Іноді термін «реактивне програмування» стосується архітектурного рівня розробки програм, де окремі вузли в графі потоку даних є звичайними програмами, які взаємодіють одна з одною.
Статика проти динаміки. Реактивне програмування може бути чисто статичними, де потоки даних встановлюються статично, або бути динамічним, де потоки даних можуть змінюватися під час виконання програми.
Використання умовних переходів в графі потоку даних може деякою мірою змусити статичний граф потоку даних виглядати як динамічний, і злегка затушувати відмінність. Проте, чисто динамічне реактивне програмування може використовувати імперативне програмування для реконструкції графа потоку даних.
Реактивне програмування вищого порядку. Реактивне програмування можна назвати програмуванням вищого порядку, якщо воно підтримує ідею про те, що потоки даних можуть бути використані для побудови інших потоків даних. Тобто, результуюче значення з потоку даних є інший потік даних, який виконується з використанням тієї ж самої моделі обчислення, що і перший.
Диференціація потоку даних. В ідеальному випадку всі зміни даних поширюються миттєво, що не може бути забезпечено на практиці. Замість цього може бути необхідно надати різні пріоритети обчислення різним частинам графу потоку даних. Це можна назвати диференційованим реактивним програмуванням.
Наприклад, в текстовому процесорі маркування орфографічних помилок не обов'язково має бути повністю синхронізованим зі вставкою символів. Тут диференційоване реактивне програмування потенційно може бути використане для перевірки орфографії з нижчим пріоритетом, що дозволяє перевірці бути відкладеною, зберігаючи при цьому миттєвість інших потоків даних.
Проте, така диференціація вносить додаткову складність у конструкцію. Наприклад, треба вирішувати, як визначити різні області потоку даних, а також як обробляти події, що проходять між різними областями потоку даних.
Моделі обчислення у реактивному програмуванні. Обчислення, чи оцінювання у реактивних програмах не обов'язково засновані на тому ж, що й обчислення у програмах, що будуються на стеках. Замість цього, коли якісь дані змінюються, то зміна поширюється на всі дані, які були залежали від змінених даних. Це поширення зміни може бути досягнуто кількома способами, серед яких, можливо, найприроднішим способом є схема інвалідація/лінива-ревалідація.
Просте наївне поширення змін через стек може викликати проблеми, тому що існує потенційно експонентна складність оновлення для структур даних певної форми. Одна з таких форм може бути описана як "форма повторюваних діамантів", і має наступну структуру: An → Bn → An + 1, An → Cn → An + 1, де n = 1,2... Ця проблема може бути подолана шляхом поширення інвалідації лише тоді, коли деякі дані ще не інвалідовано, з наступною ре-валідацією даних в разі потреби, використовуючи ледачі обчислення.
Одна проблема, притаманна реактивному програмуванню, це те, що більшість обчислень, які у звичайній мові програмування були б зроблені і забуті, мусять лишатися в пам'яті у вигляді структур даних. Це може зробити реактивне програмування дуже вимогливим до об'єму пам'яті. Проте, дослідження, що називається "зниженням", має потенціал вирішити цю проблему.
З іншого боку, реактивне програмування є формою того, що можна описати як "явний паралелізм", і, таким чином, може бути корисним для використання потужностей паралельного апаратного забезпечення.
Схожість з шаблоном спостерігач. Реактивне програмування має принципову подібність до шаблону спостерігач, що зазвичай використовується в ООП. Проте, інтеграція концепцій потоку даних в мову програмування полегшить їх висловлення, і, таким чином, може збільшити ступінь деталізації графа потоку даних. Наприклад, шаблон "Спостерігач" зазвичай описує потоки даних між цілими класами/об'єктами, в той час, як об'єктно-орієнтоване реактивне програмування може націлюватися на членів об'єктів і класів.
Модель обчислення на основі стеку у загальновживаному ООП також не зовсім підходить для поширення потоку даних, тому що випадки "зворотного зв'язку дерева ребер" в структурах даних можуть зробити програму експонентно складною. Але через його відносно обмежене використання і низьку зернистість, це рідко є проблемою для шаблону Спостерігача на практиці.
Реактивне програмування – це парадигма програмування, яка дає змогу розробляти системи, здатні відповідати на зміни в навколишньому середовищі;
Сучасний світ постійно рухається, все змінюється дуже швидко, і програми повинні реагувати на ці зміни. У цій статті ми поговоримо про особливості реактивного програмування, переваги та недоліки, а також про застосування в комерційній розробці.
Реактивне програмування (RP) – це парадигма програмування, у якій основна увага приділяється потокам даних та їхній автоматичній обробці в реальному часі. RP передбачає швидку реакцію програми на зміни, а також використання асинхронних операцій.
Основні принципи RP – це створення реактивних ункцій, управління подіями та їхнє опрацювання в реальному часі, а також використання патернів проєктування, як-от Observer, для зручного управління потоками даних.
Приклади використання RP – це веб-додатки з динамічними інтерфейсами, де дані оновлюються в реальному часі, ігри з інтерактивною графікою, а також додатки для опрацювання великих обсягів даних, наприклад, у фінансовій сфері. RP широко застосовується в мовах програмування, таких як Java, JavaScript, C# і Kotlin.
Основними концепціями реактивного програмування є потоки даних, обробка помилок і реактивні оператори.
Обробка помилок – ще один важливий аспект реактивного програмування. Реактивні системи мають бути готові до виникнення помилок і вміти їх обробляти. Для цього використовуються спеціальні механізми, як-от відкладені помилки (deferred errors) і стратегії повторного опрацювання (retry strategies).
Реактивні оператори дають можливість маніпулювати потоками даних, виконуючи на них різні операції, такі як фільтрація, трансформація, агрегація тощо. Реактивні оператори забезпечують гнучкість і потужність під час обробки потоків даних.
Разом ці концепції – ключ до створення складних реактивних систем високої продуктивності та чуйності. Це веб-фреймворки, мобільні додатки, системи моніторингу та управління, та інші додатки, які вимагають швидкого оброблення потоків даних.
Реалізація реактивного програмування. Незважаючи на зростаючу популярність реактивного програмування, воно потребує певної експертизи для його правильної реалізації та використання, зокрема знання бібліотек і фреймворків.
Одна з найпопулярніших бібліотек – RxJava, яка дає змогу створювати та комбінувати потоки даних, застосовувати різні реактивні оператори та обробляти помилки. Ще однією популярною бібліотекою є ReactiveX, яка підтримує безліч мов програмування, включно з Java, JavaScript і C#.
Список популярних фреймворків доповнюють Reactor для мови Java, RxJS для мови JavaScript та Akka для мови Scala. Вони надають різні можливості для роботи з реактивними потоками даних і обробки помилок.
Реактивне програмування має незаперечні переваги. Зокрема, за його допомогою створюються чуйні та ефективні програми завдяки використанню асинхронного програмування та “лінивого” завантаження даних. Це також спрощує реалізацію складних логічних операцій, таких як фільтрація, маппінг та об’єднання даних.
Однак, у RP є і недоліки. Зокрема, через складність архітектури та принципів реактивного програмування, його використання вимагає більш глибоких знань програмування, ніж прості та прямолінійні підходи. Також може бути складно діагностувати та виправляти помилки в реактивних програмах, особливо якщо використовується велика кількість потоків даних та операторів.
Проте сучасні інструменти та бібліотеки реактивного програмування допомагають справлятися з цими складнощами.
Реактивне програмування широко використовується в багатьох галузях, де важливе опрацювання потоків даних у режимі реального часу. Наприклад, це:
Веб-розробка. Веб-додатки, як-от онлайн-магазини та соціальні мережі, використовують реактивне програмування для опрацювання потоків даних, таких як оновлення статусу замовлення.
Мобільна розробка. Додатки для мобільних пристроїв використовують реактивне програмування для опрацювання користувацьких подій, таких як геолокація і мультимедіа.
IoT-додатки. Інтернет речей (IoT) – це сфера, де реактивне програмування може бути особливо корисним для опрацювання великої кількості потоків даних з різних пристроїв і датчиків.
Фінансові додатки. Торгові платформи і системи управління ризиками використовують реактивне програмування для обробки великої кількості даних про транзакції в режимі реального часу.
Великі дані (Big Data). Реактивне програмування підходить для обробки великих обсягів даних, таких як потоки логів і транзакцій, які можуть оброблятися на великих кластерах серверів.
Крім того, реактивне програмування може бути використане в багатьох інших галузях, як-от телекомунікації, медичні додатки тощо.
Архітектура програмного забезпечення, заснована на реактивному програмуванні, будується на принципах асинхронності та незмінності даних. У такій архітектурі система реагує на події, які відбуваються всередині неї або за її межами, і змінює свій стан за допомогою неблокувальних операцій.
У реактивній архітектурі компоненти взаємодіють один з одним через потоки даних, які можуть бути нескінченними й асинхронними. Це дає змогу легко додавати нові компоненти та масштабувати систему за потреби. Крім того, реактивна архітектура здатна обробляти помилки і збої, зберігаючи водночас працездатність системи в цілому.
Загалом, реактивне програмування й архітектура являють собою ефективний підхід до створення масштабованих і чуйних систем, здатних працювати з великими обсягами даних і швидко реагувати на зміни в навколишньому середовищі.
Отже, реактивне програмування – це потужний інструмент, який допомагає розробникам створювати більш ефективні та чуйні системи. За його допомогою створюються додатки, що реагують на зміни в навколишньому середовищі та швидко адаптуються до нових вимог. Однак, як і будь-яка інша технологія, реактивне програмування не є універсальним рішенням для всіх завдань і потребує ретельної оцінки та розуміння під час використання.
Узагальнене програмування (англ. generic programming) — парадигма програмування, що полягає в такому описі даних і алгоритмів, який можна застосовувати до різних типів даних, не змінюючи сам опис. У тому чи іншому вигляді підтримується різними мовами програмування.
Можливості узагальненого програмування вперше з'явилися в 1970-х роках у мовах CLU та Ada, а потім у багатьох об'єктно-орієнтованих мовах, таких як C++, Java, D і мовах для платформи .NET. Термін "Узагальнене програмування" вперше було введене Девідом Массером і Олександром Степановим, які описували парадигму програмування, яка заснована на тому, що типи даних і структури даних є абстрактними і не впливають на конкретну реалізацію алгоритмів, а загальні функції реалізовані з використанням узагальнених формалізованих типів.
Препроцесор мови C підтримує окремі можливості узагальненого програмування. Так, наприклад, функція обміну значень двох об'єктів даних може бути визначена як макрос:
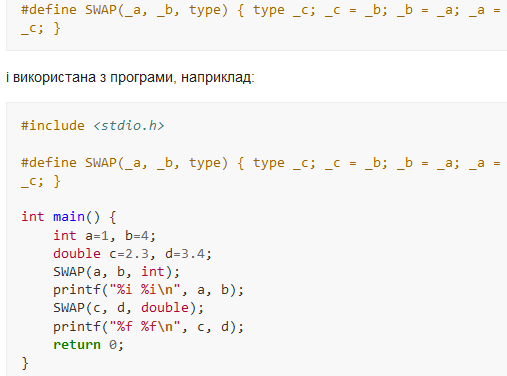
Узагальнене програмування сприймається як методологія програмування, заснована на поділ структур даних і алгоритмів через використання абстрактних описів требований[3]. Абстрактні описи вимог є розширенням поняття абстрактного типу даних. Замість опису окремого типу в узагальненому програмуванні застосовується опис сімейства типів, що мають загальний інтерфейс та семантичну поведінку (англ. semantic behavior). Набір вимог, що описує інтерфейс та семантичну поведінку, називається концепцією (concept). Таким чином, написаний в узагальненому стилі алгоритм може застосовуватися для будь-яких типів, що задовольняють його концепції. Така можливість називається поліморфізмом.
Кажуть, що тип моделює концепцію (є моделлю концепції), якщо він задовольняє її вимогам. Концепція є уточненням іншої концепції, якщо вона доповнює останню. Вимоги до концепцій містять таку информацию:
Допустимі вирази (англ. valid expressions) — вирази мови програмування, які мають успішно компілюватися для типів, що моделюють концепцію.
Асоційовані типи (associated types) - допоміжні типи, що мають деяке відношення до моделюючого концепцію типу.
Інваріанти (invariants) – такі характеристики типів, які мають бути постійно вірними під час виконання. Зазвичай виражаються як передумов і постумов. Невиконання передумови тягне за собою непередбачуваність відповідної операції і може призвести до помилок.
Гарантії складності (complexity guarantees) - максимальний час виконання допустимого виразу або максимальні вимоги до різних ресурсів під час виконання цього виразу.
У C++ об'єктно-орієнтоване програмування (ООП) реалізується у вигляді віртуальних функцій і наслідування, а узагальнене програмування (УП) — з допомогою шаблонів класів і функций. Проте суть обох методологій пов'язана з конкретними технологіями реалізації лише побічно. Говорячи формально, ООП засноване на поліморфізмі підтипів, а УП — на параметричному поліморфізмі. В інших мовах те й інше можна реалізувати інакше. Наприклад, мультиметоди в CLOS мають схожу з параметричним поліморфізм семантику.
Массер і Степанов виділяють такі етапи у розв'язанні задачі з методології УП:
Знайти корисний та ефективний алгоритм.
Визначити узагальнене уявлення (параметризувати алгоритм, мінімізувавши вимоги до даних, що обробляється).
Описати набір (мінімальних) вимог, задовольняючи які ще можна отримати ефективні алгоритми.
Створити каркас з урахуванням класифікованих вимог.
Мінімізація та створення каркасу ставлять за мету створення такої структури, при якій алгоритми не залежать від конкретних типів даних. Цей підхід відбито у структурі бібліотеки STL.[5]
Альтернативний підхід до визначення узагальненого програмування, який можна назвати узагальненим програмуванням типів даних (англ. datatype generic programming), було запропоновано Річардом Бердом та Ламбертом Меєртенсом. У ньому структури типів даних є параметрами узагальнених програм. Для цього в мову програмування вводиться новий рівень абстракції, а саме параметризація по відношенню до класів алгебр зі змінною сигнатурою. Хоча теорії обох підходів не залежать від мови програмування, підхід Массера — Степанова, який наголошує на аналіз концепцій, зробив C++ своєю основною платформою, тоді як узагальнене програмування типів даних використовують майже виключно Haskell та його варіанти [6].
Загальний механізм. Засоби узагальненого програмування реалізуються в мовах програмування у вигляді тих чи інших синтаксичних засобів, що дають можливість описувати дані (типи даних) та алгоритми (процедури, функції, методи), що параметризуються типами даних. У функції чи типу даних явно описуються формальні параметри-типи. Цей опис є узагальненим і у вихідному вигляді безпосередньо використано бути не може.
У тих місцях програми, де узагальнений тип чи функція використовується, програміст повинен явно вказати фактичний параметр-тип, який конкретизує опис. Наприклад, узагальнена процедура перестановки місцями двох значень може мати параметр-тип, що визначає тип значень, які вона змінює місцями. Коли програмісту потрібно поміняти місцями два цілі значення, він викликає процедуру з параметром-типом "ціле число" і двома параметрами - цілими числами, коли два рядки - з параметром-типом "рядок" і двома параметрами - рядками. У разі даних програміст може, наприклад, описати узагальнений тип «список» з параметром-типом, визначальним тип збережених у списку значень. Тоді при описі реальних списків програміст повинен вказати узагальнений тип і параметр-тип, отримуючи таким чином будь-який бажаний список за допомогою того самого опису.
Компілятор, зустрічаючи звернення до узагальненого типу чи функції, виконує необхідні процедури статичного контролю типів, оцінює можливість заданої конкретизації і за позитивної оцінки генерує код, підставляючи фактичний параметр-тип місце формального параметра-типа в узагальненому описі. Природно, що з успішного використання узагальнених описів фактичні типи-параметри повинні відповідати певним умовам. Якщо узагальнена функція порівнює значення типу-параметра, будь-який конкретний тип, використаний у ній, повинен підтримувати операції порівняння, якщо надає значення типу-параметра змінним – конкретний тип повинен забезпечувати коректне надання.
У мові C++ узагальнене програмування полягає в понятті «шаблон», позначеному ключовим словом template. Широко застосовується у стандартній бібліотеці C++ (див. STL), а також сторонніх бібліотеках boost, Loki.