

Отчёт 4 лабораторная
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №4
по дисциплине
«Управление данными»
Выполнила: студентка гр. БСТ2104
Первухина Алиса Александровна
Проверила:
Тимофеева Анна Ивановна
Москва
2024
Разбор алгоритма Decision Tree
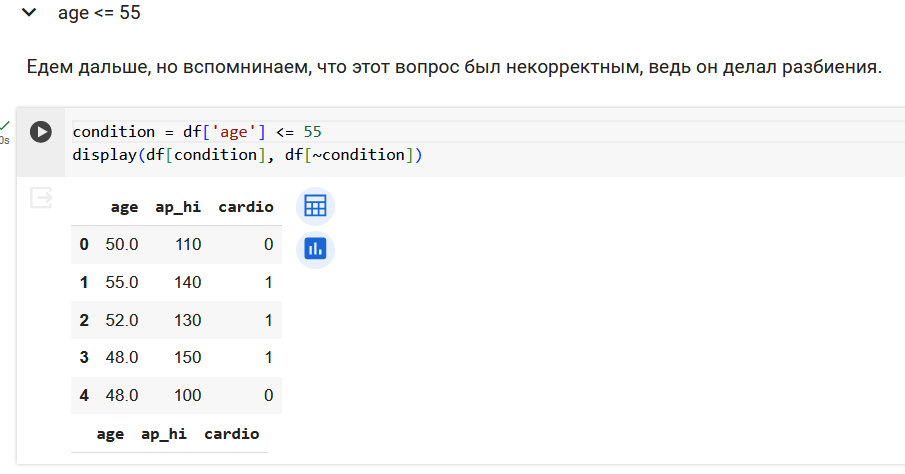
В первой части лабораторнрой работы мы будем работать с набором данных для задачи классификации - данные по сердечно сосудистым заболеваниям.
Ссылка на датасет: https://drive.google.com/file/d/1Si4EJ_RexI3Q7yZU8eLjgp4ORe_BXr4G
В задаче предалагается предсказать наличие сердечно-сосудистых заболеваний по результатам классического врачебного осмотра.
Датасет сформирован 3 групп признаков:
Объективные признаки:
Возраст (в днях)
Рост
Вес
Пол
Результаты измерения:
Артериальное давление верхнее и нижнее
Холестерин (три группы: норма, выше нормы, значительно выше нормы)
Глюкоза (три группы: норма, выше нормы, значительно выше нормы)
Субъективные признаки (бинарные):
Курение
Употребление Алкоголя
Физическая активность
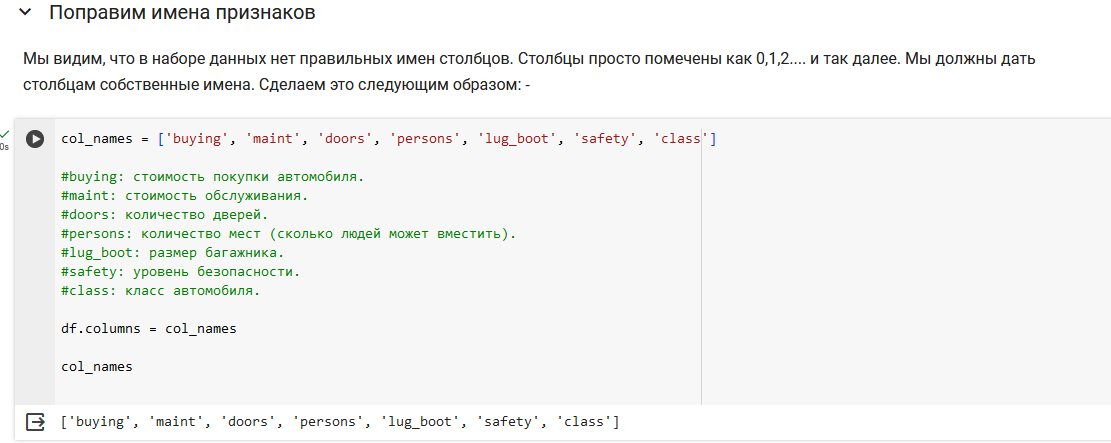
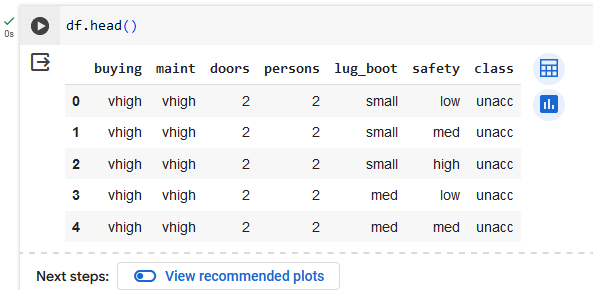
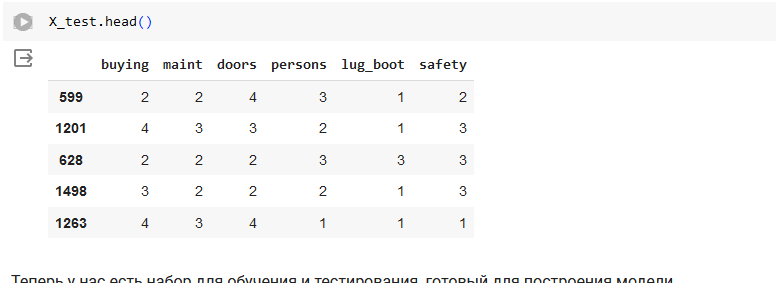
Выведем первые строчки датасета
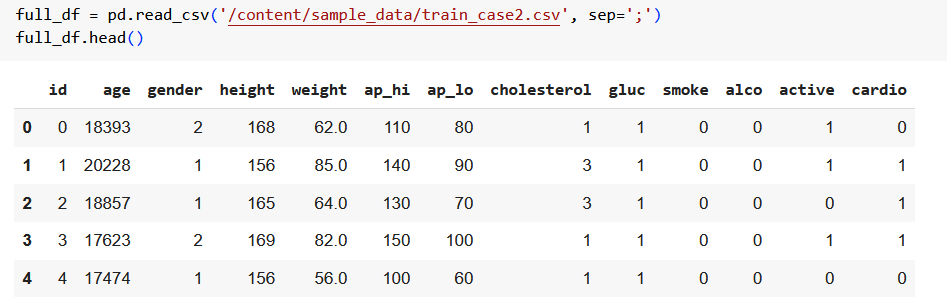
Определим имена столбцов, которые будут использоваться как признаки для обучения модели. Также преобразуем возраст в днях в возраст в годах.
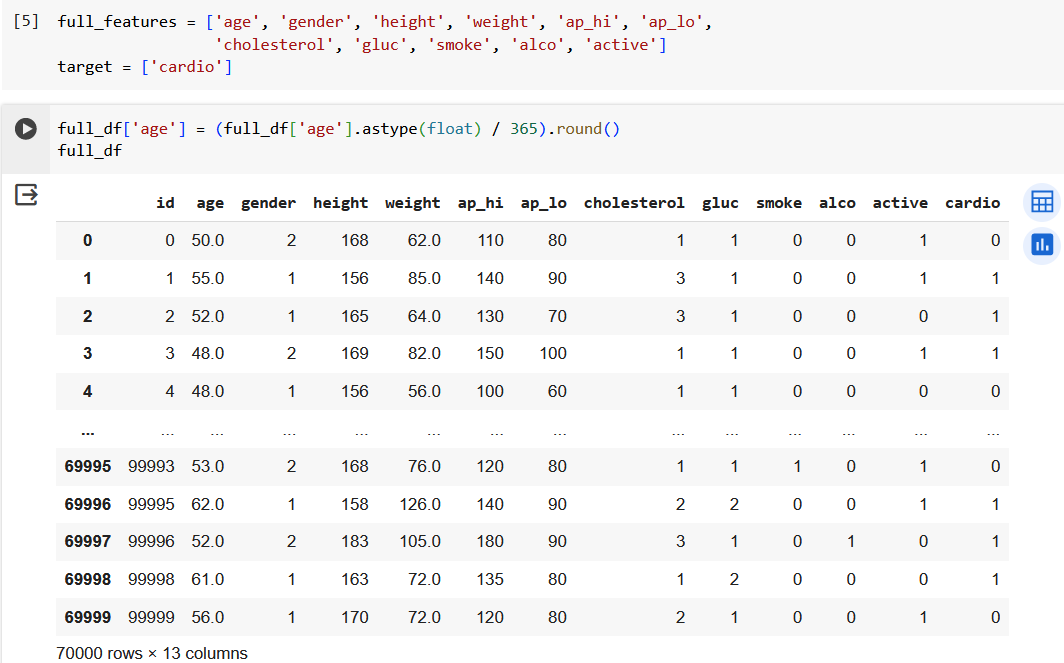
Чтобы более наглядно смотреть, как обучается дерево решений возьмем только 5 объектов и 2 признака.
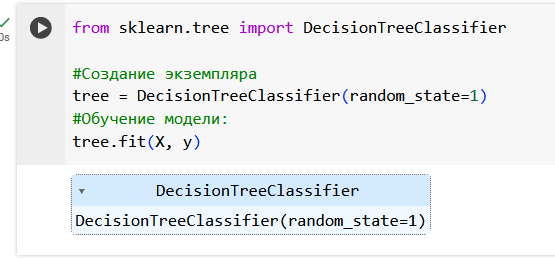
Обучим одно дерево решений с помощью sklearn’a. Инициализируем его для задачи классификации и обучим на признаках (X) и целевой переменной (y). По признакам модель будет запоминать закономерности, которые больше влияют на наличие сердечно-сосудистого заболевания.
Теперь
визуализируем наше обученное дерево
решений. Из себя дерево решений представлет
набор вопросов к данным. Узлы (ноды), где
как раз-таки находится вопрос - называются
вершинами,
в этом дереве у нас есть одна вершина,
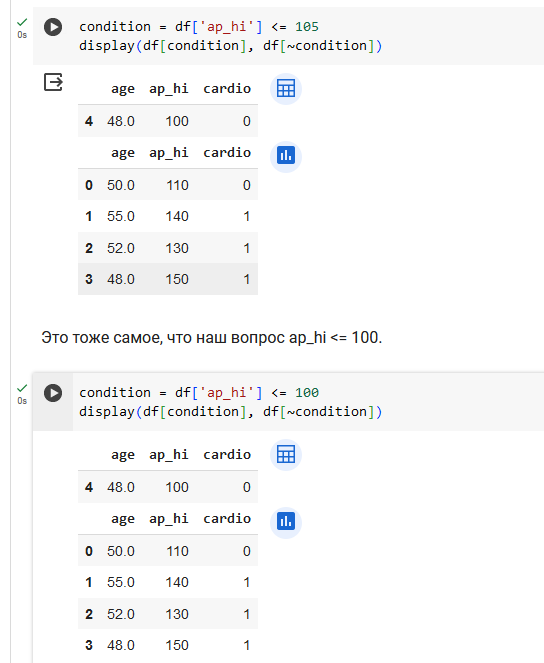
где хранится вопрос ap_hi <= 120.

Пояснение:
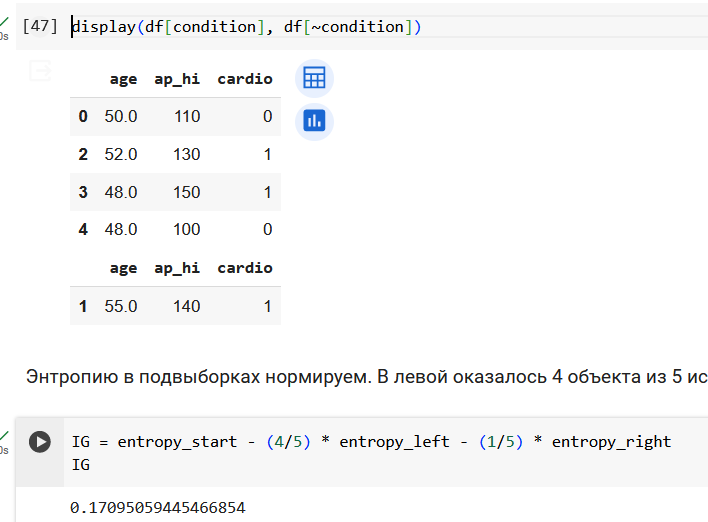
ap_hi <= 120.0: Это условие разделения (или узел решения), где ap_hi обозначает артериальное давление верхнее. Если значение ap_hi у объекта меньше или равно 120, то объект будет направлен в левую ветку дерева, в противном случае — в правую.
gini = 0.48: Индекс Джини — это мера неопределённости или чистоты узла. Значение 0.48 указывает на то, что узел довольно смешанный (значение 0 означает полную чистоту и отсутствие неопределённости).
samples = 5: В узле находится 5 объектов из набора данных.
value = [2, 3]: Это распределение классов в узле. У нас есть 2 объекта класса 'No Cardio' (предполагаемое значение 0) и 3 объекта класса 'Cardio' (предполагаемое значение 1). Левый листовой узел (оранжевый цвет):
gini = 0.0: Индекс Джини, равный 0, указывает на то, что все объекты в этом листе принадлежат одному классу, что делает его полностью "чистым".
samples = 2: В левой ветке находятся 2 объекта.
value = [2, 0]: Все 2 объекта в этом узле принадлежат классу 'No Cardio'. Правый листовой узел (жёлтый цвет):
gini = 0.0: Аналогично, индекс Джини, равный 0, указывает на полную чистоту этого листа.
samples = 3: В правой ветке находятся 3 объекта.
value = [0, 3]: Все 3 объекта в этом узле принадлежат классу 'Cardio'.
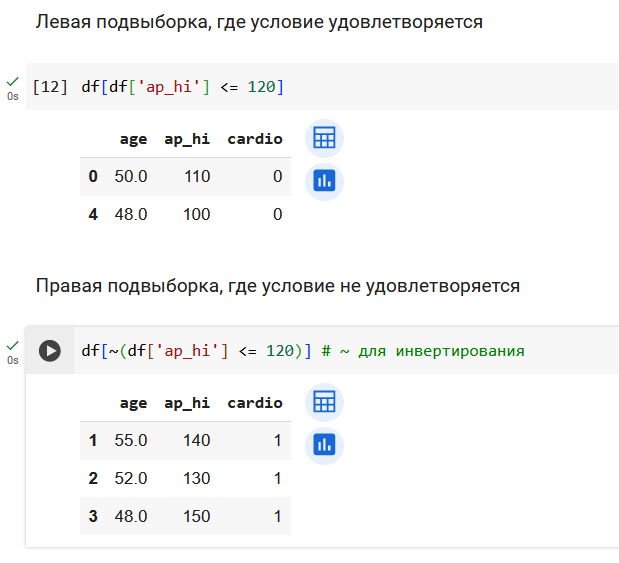
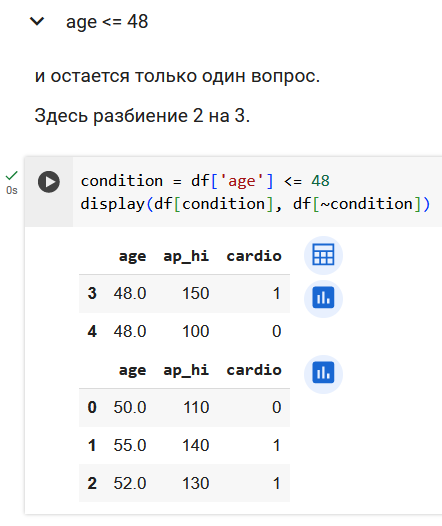
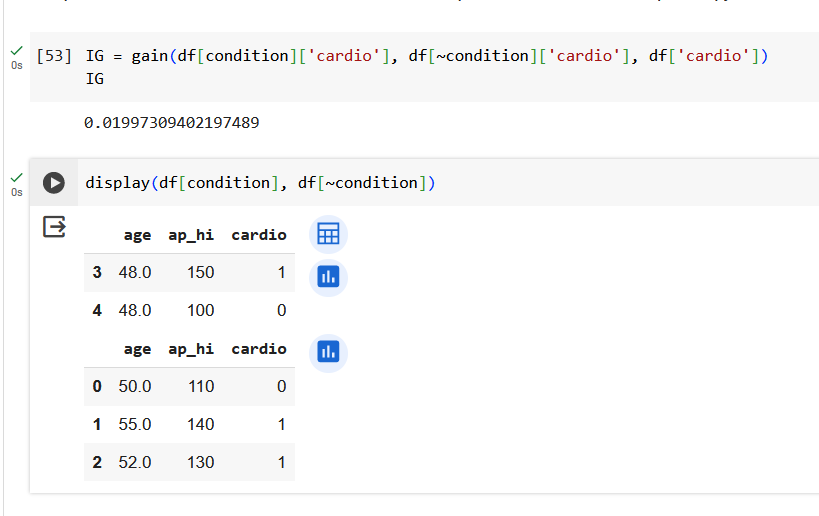
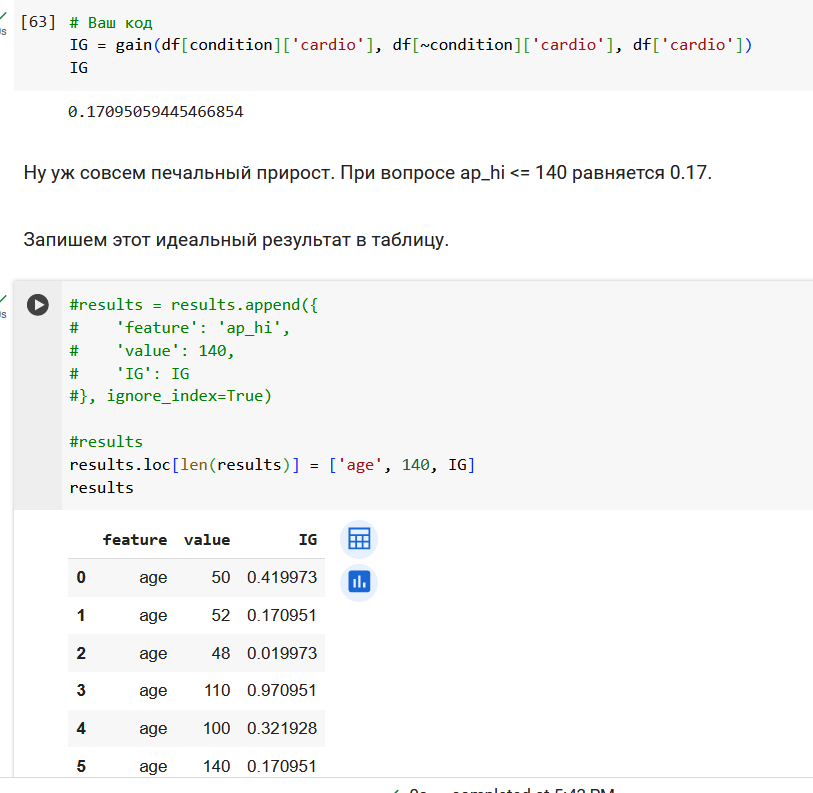
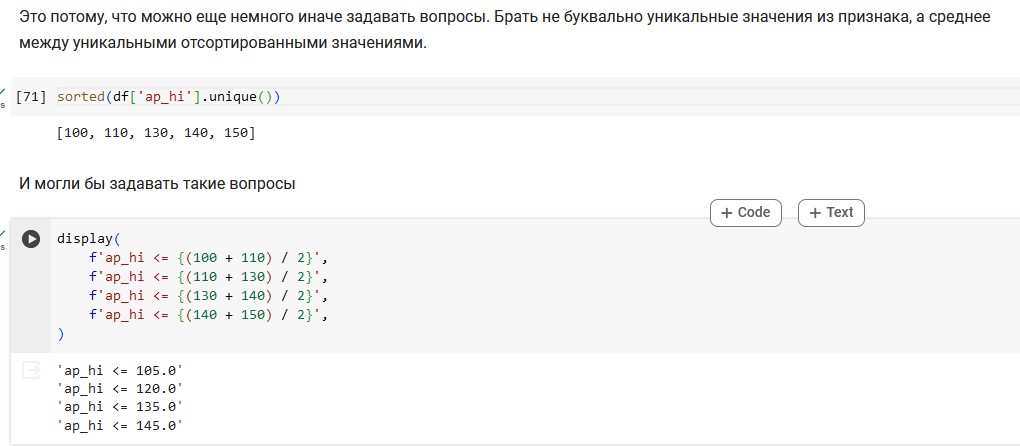
Определим, какие вопросы задает дерево решений.
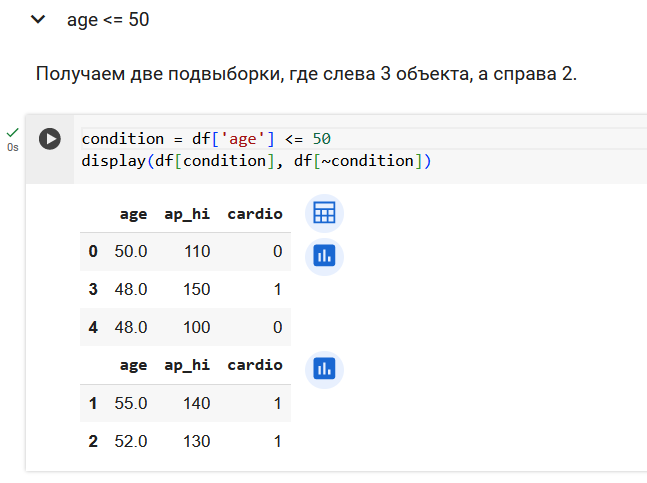
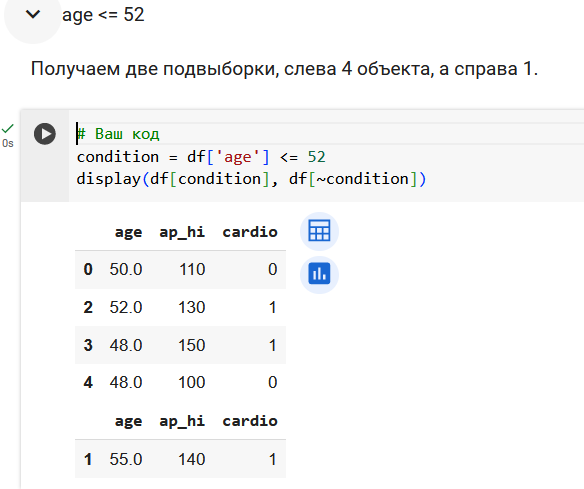
Поработаем с признаком возраста.
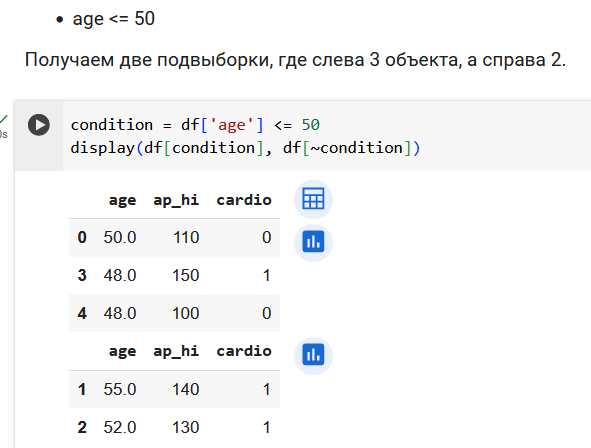
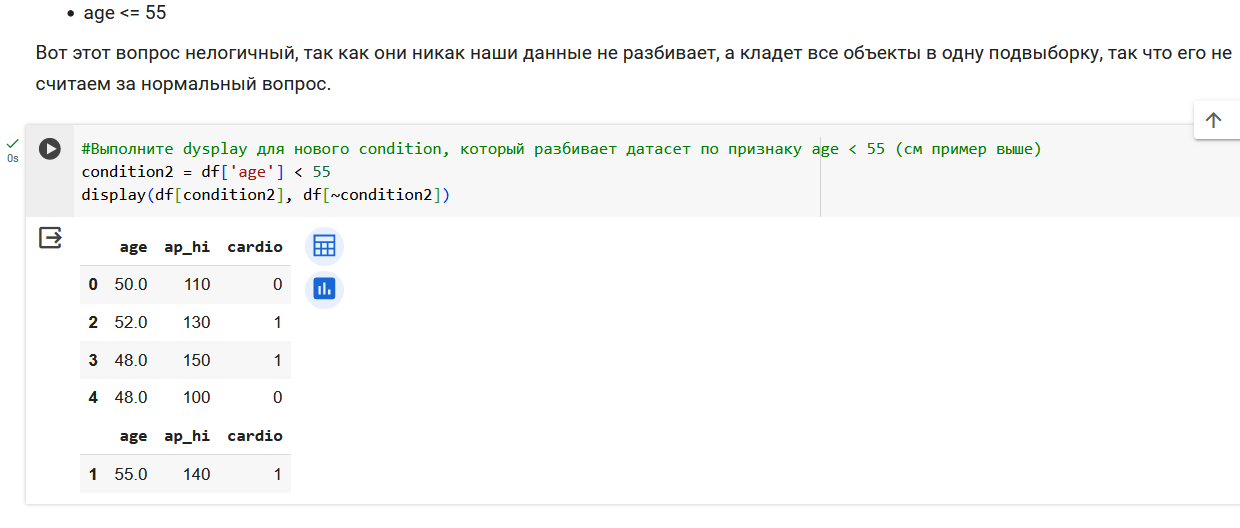
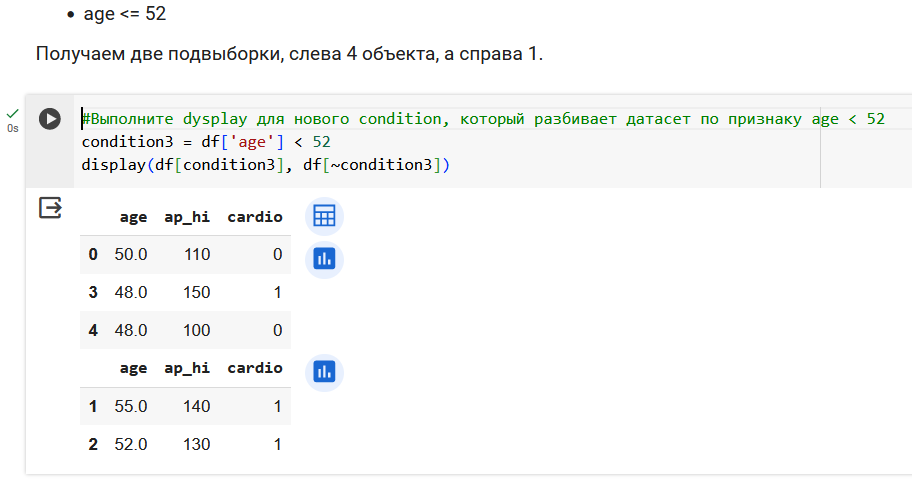
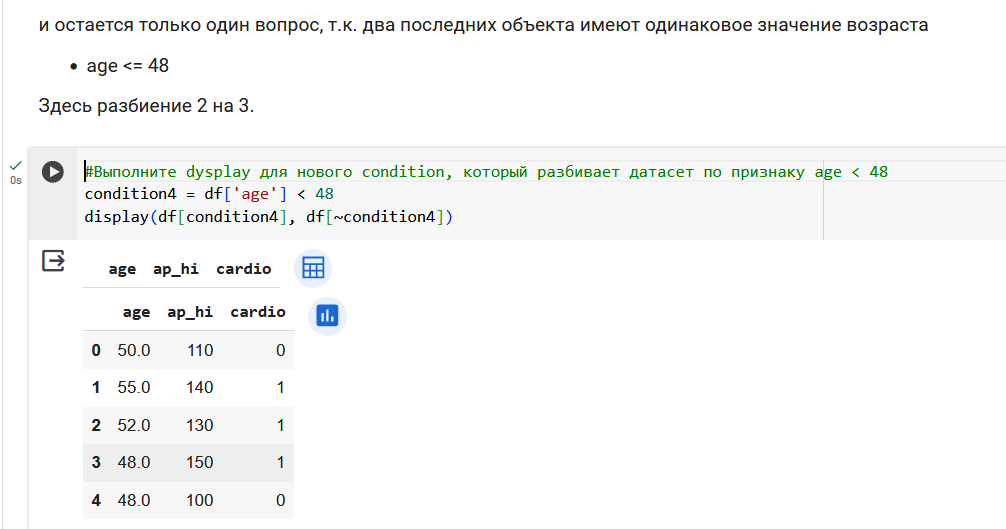
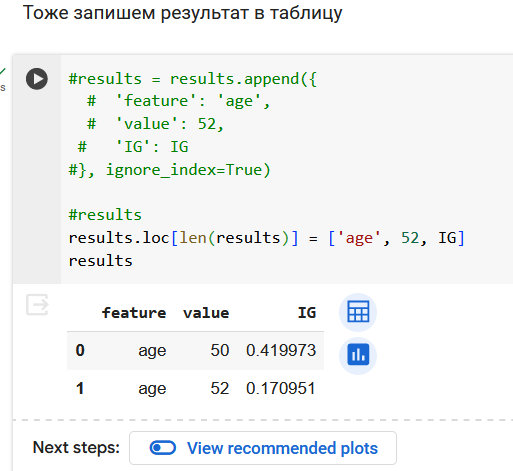
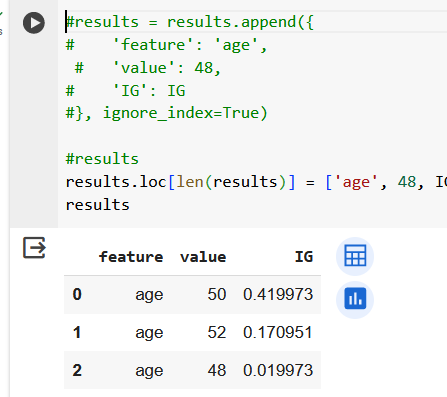
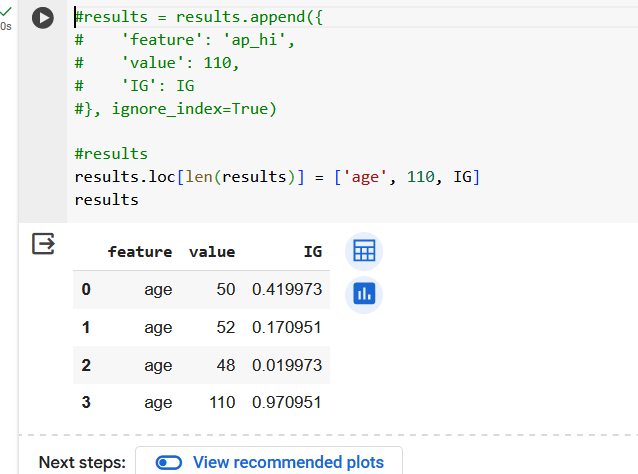
Резюмируем по признаку возраста. Получили 3 валидных вопроса.
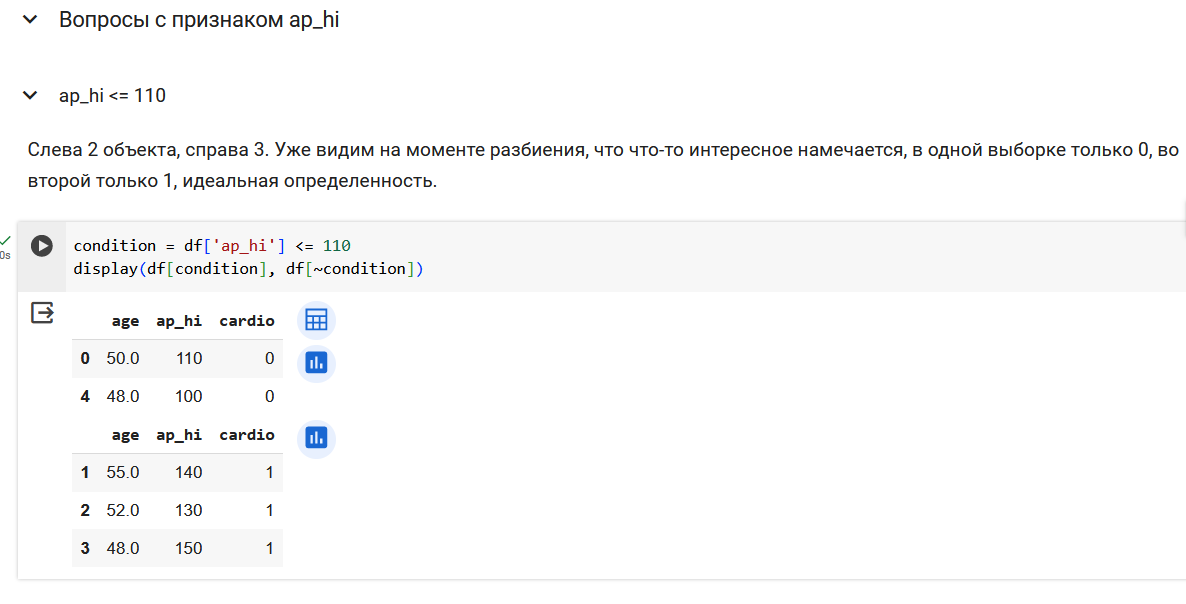
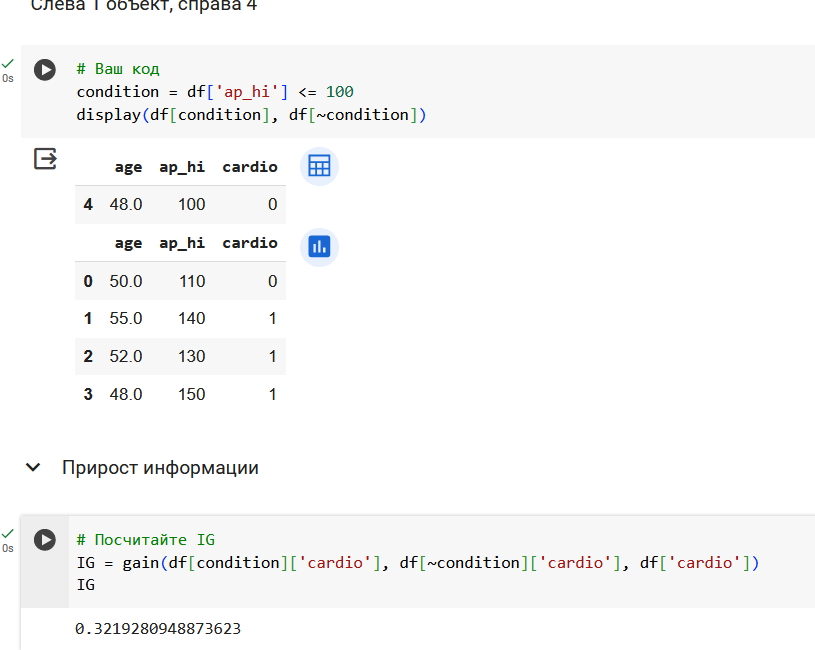
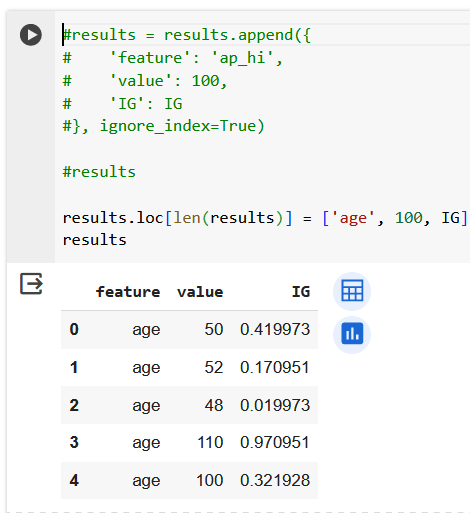
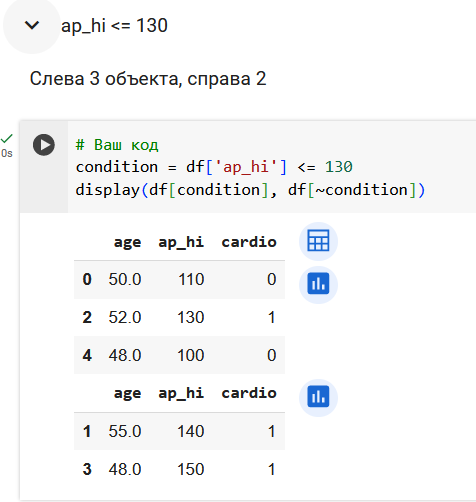
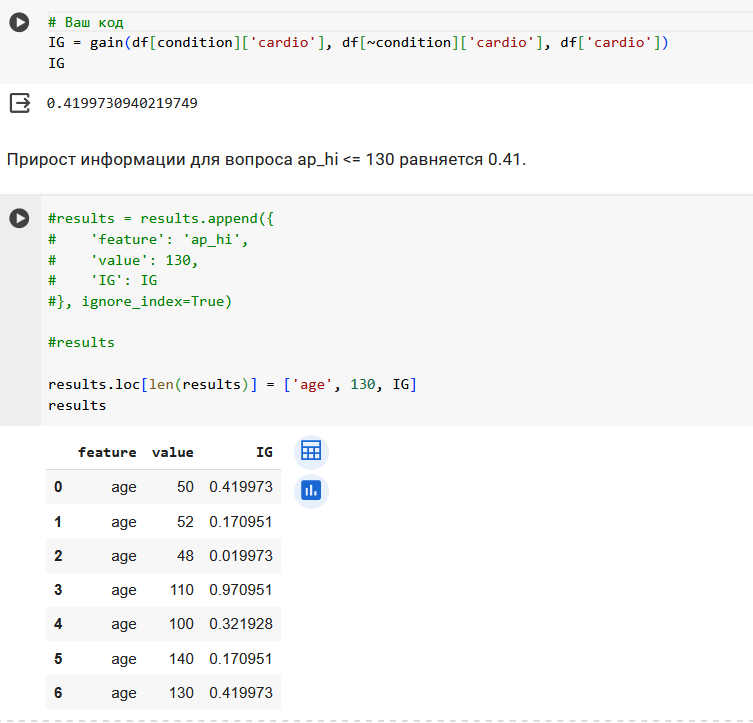
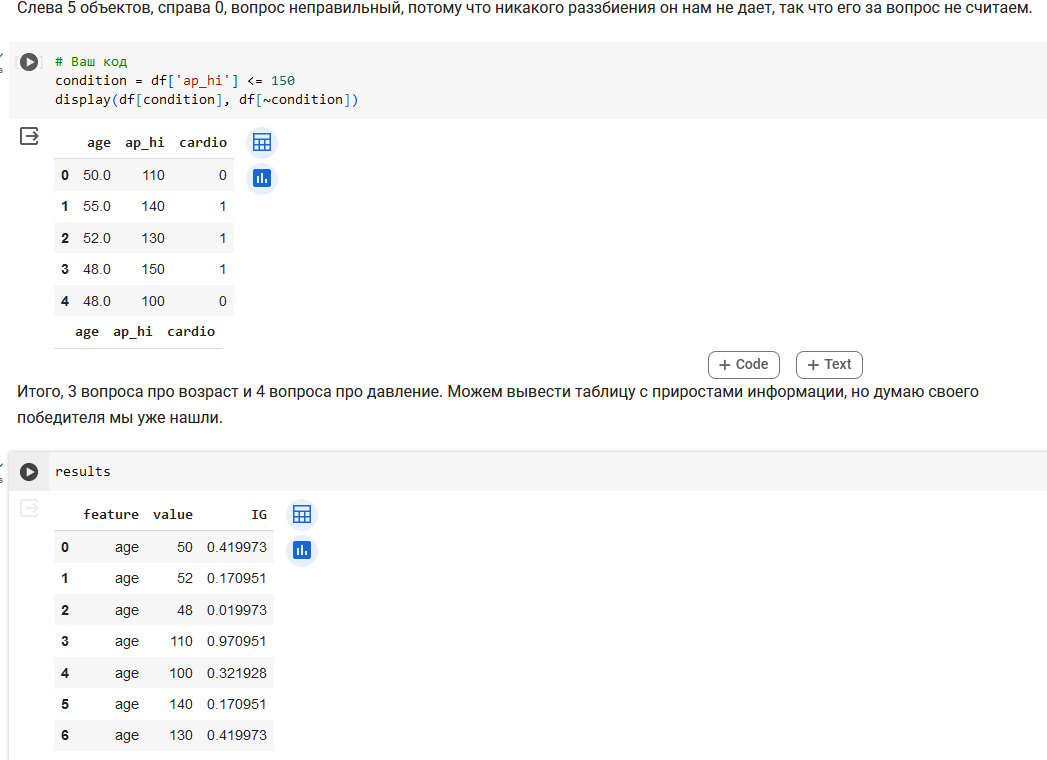
Поработаем с признаком ap_hi.
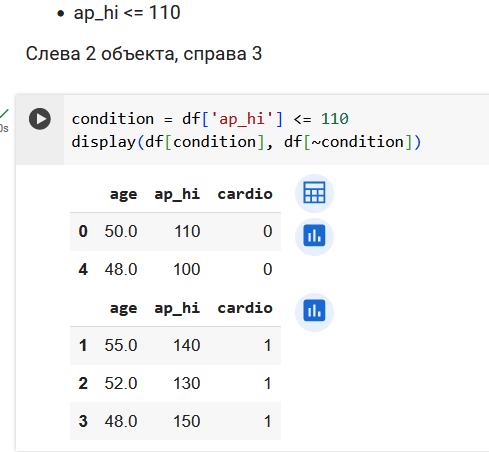
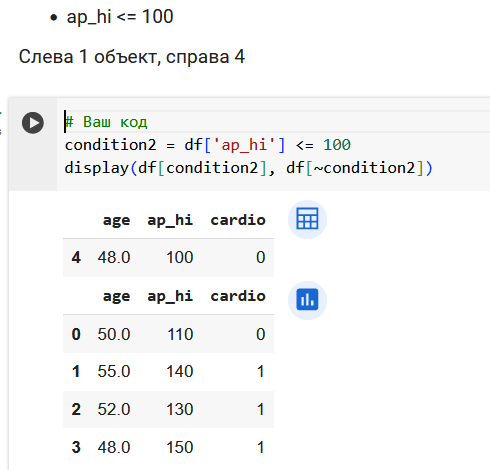
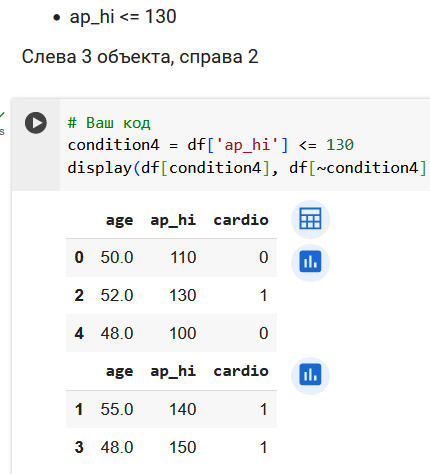
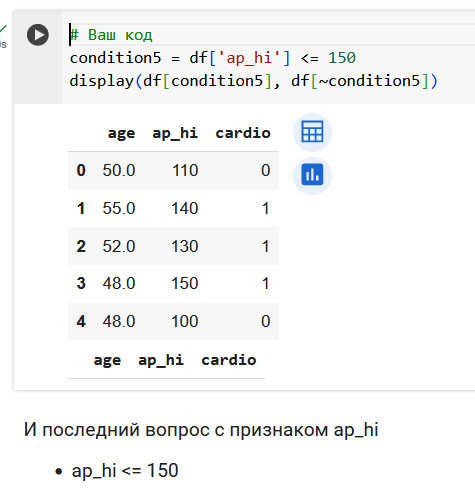
Итого, 3 вопроса про возраст и 4 вопроса про давление.
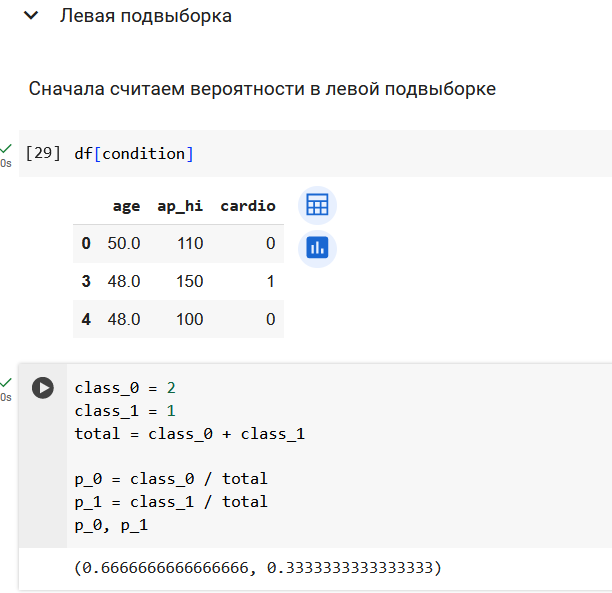
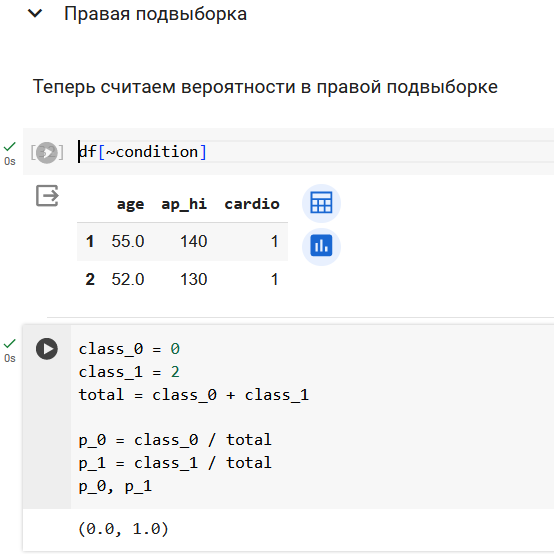
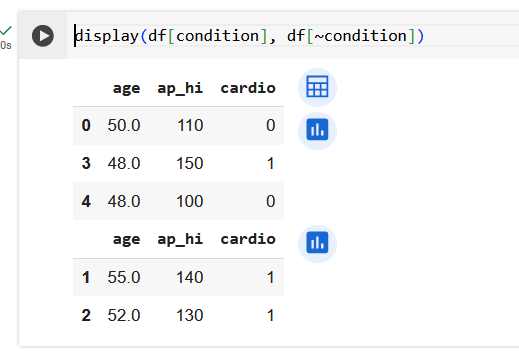
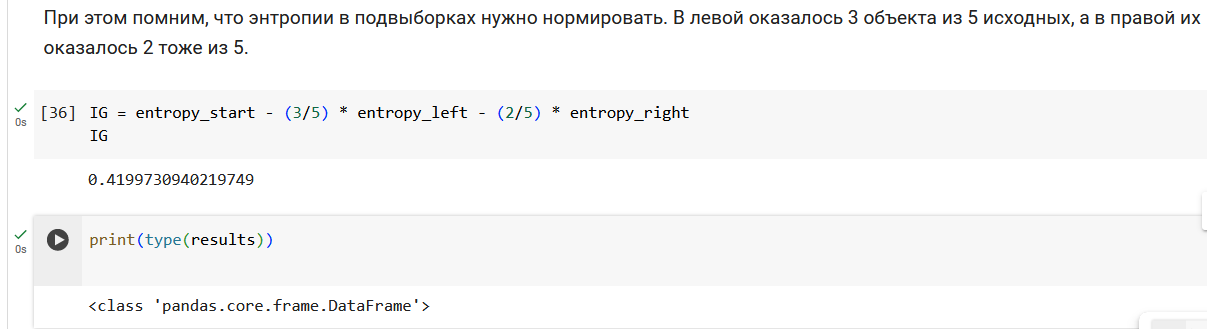
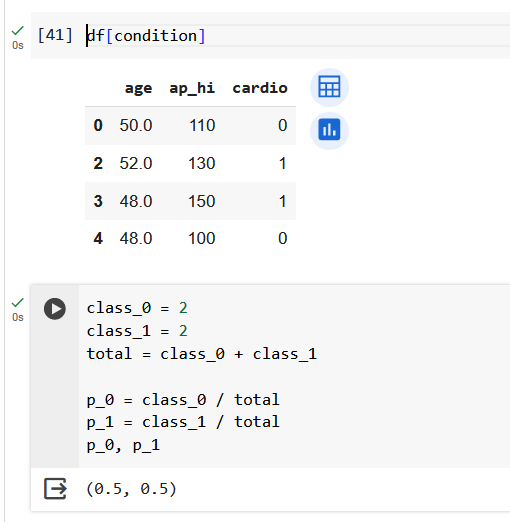
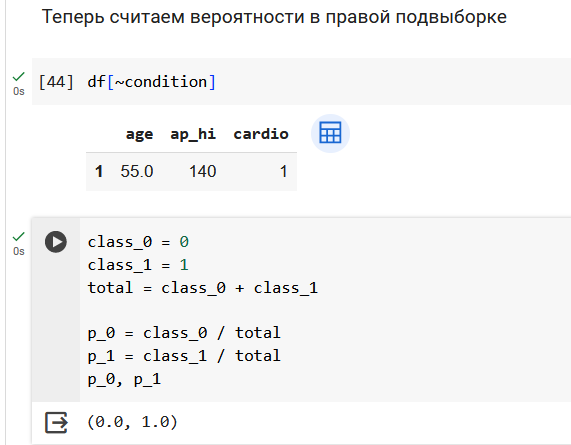
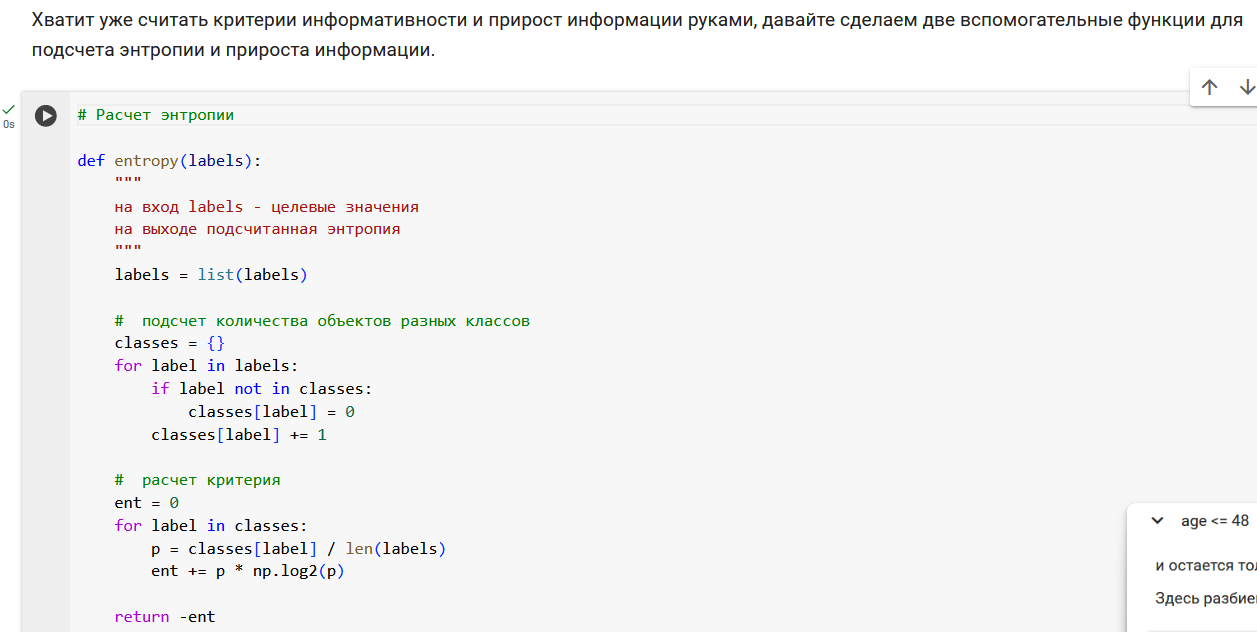
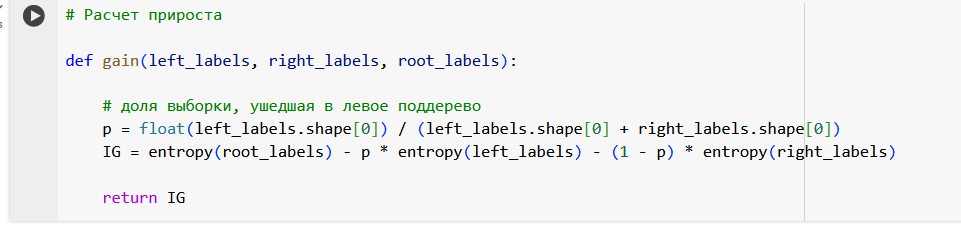
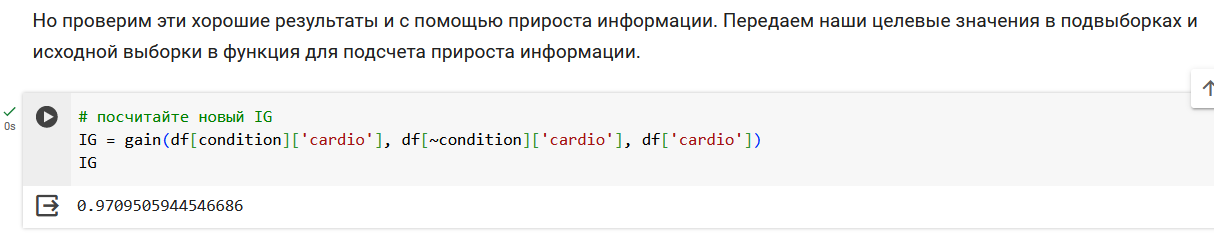
Начнем с подсчета энтропии в исходной выборке из 5 объектов. У нас два объекта 0 класса и три объекта 1 класса.











Разбор алгоритма Random Forest
Во второй части лабораторной работы мы будем работать с набором данных для задачи классификации - данные по автомобилям.
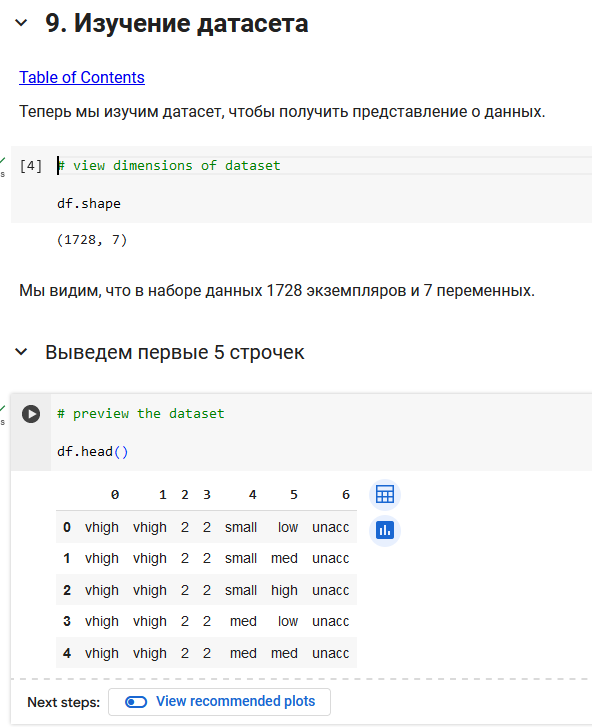
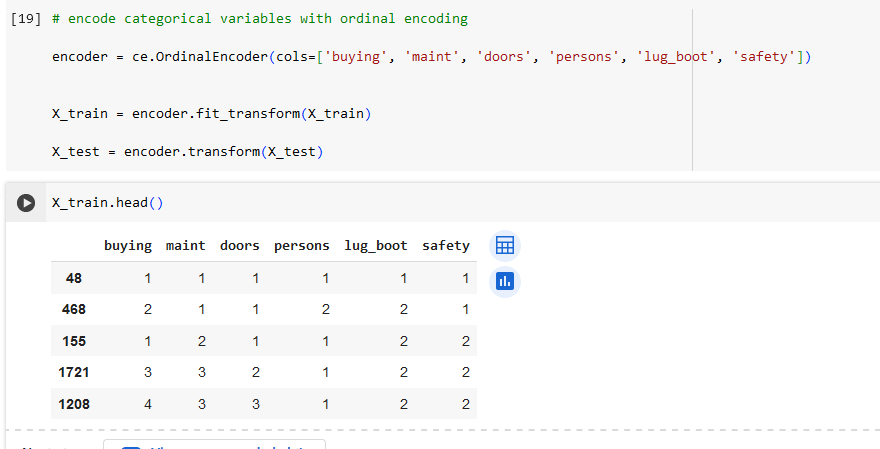
В этой части мы предсказывали переменную class для предсказания классов автомобилей (unacc, acc, good, vgood).
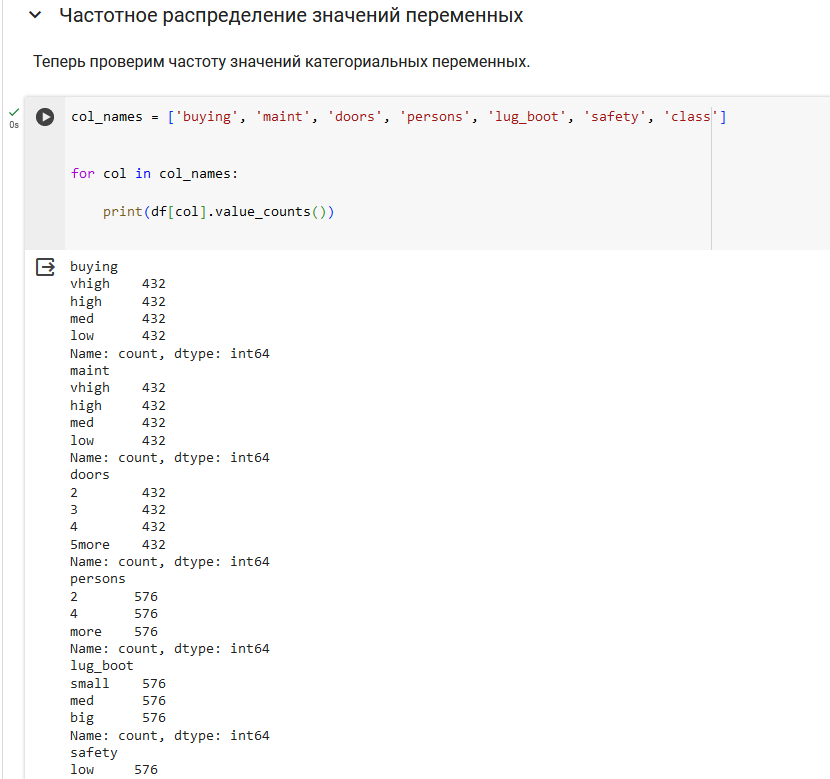
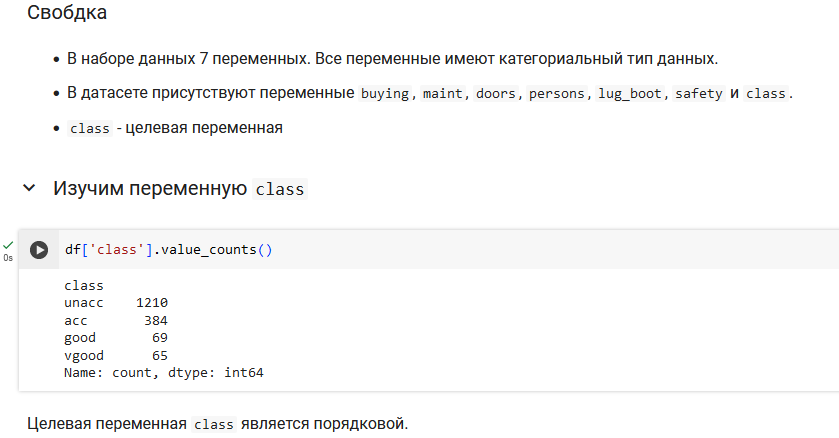



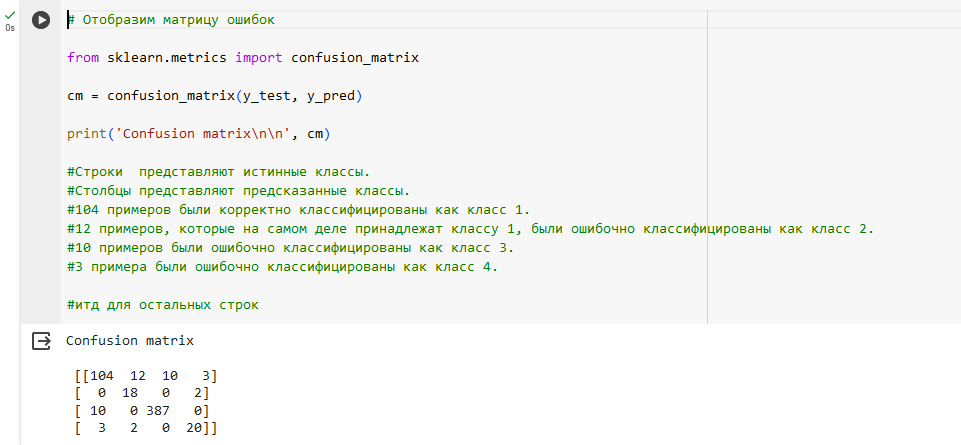

Precision (Точность): показывает, какая доля объектов, отнесённых моделью к данному классу, действительно относится к этому классу.
Recall (Полнота): показывает, какая доля объектов из реально относящихся к данному классу была выявлена моделью.
F1-score: гармоническое среднее между точностью и полнотой, позволяет учесть обе характеристики одновременно.
Support: количество реальных случаев данного класса в вашем тестовом наборе.
accuracy: общая точность модели, показывает долю всех правильно классифицированных объектов.
macro avg (Среднее макро): среднее значение метрик, рассчитанное по всем классам, где каждый класс имеет равный вес.
weighted avg (Среднее взвешенное): среднее значение метрик, взвешенное в соответствии с количеством объектов в каждом классе.
acc: Точность 89%, полнота 81%, что говорит о том, что модель достаточно хорошо классифицирует этот класс, но пропускает около 19% истинных случаев.
good: Низкая точность 56% при высокой полноте 90%, что указывает на то, что многие объекты, не являющиеся good, ошибочно классифицируются как good.
unacc: Высокие значения точности и полноты (97%), модель очень хорошо справляется с этим классом.
vgood: Баланс между точностью и полнотой с обоими значениями 80%, довольно хороший результат, но есть пространство для улучшения.
Метрики macro avg и weighted avg выявляют разницу в производительности между классами, подсказывая, где возможно нуждаются улучшения.
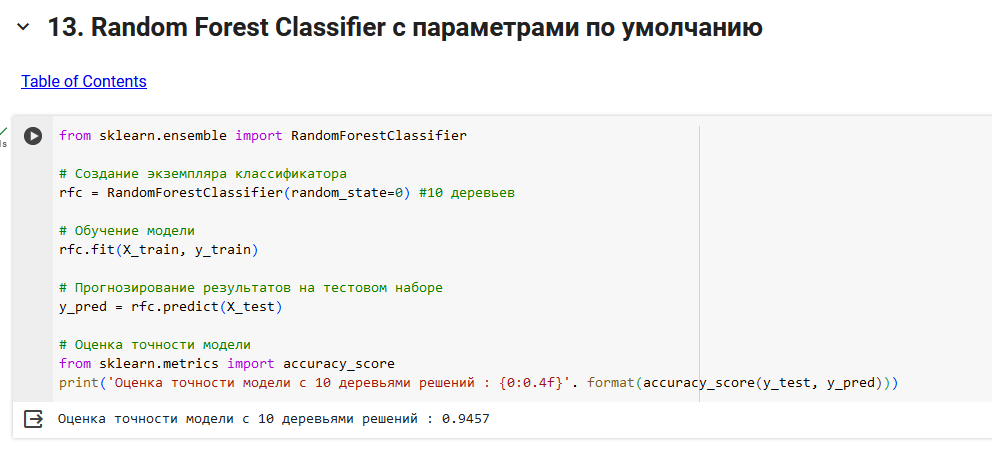
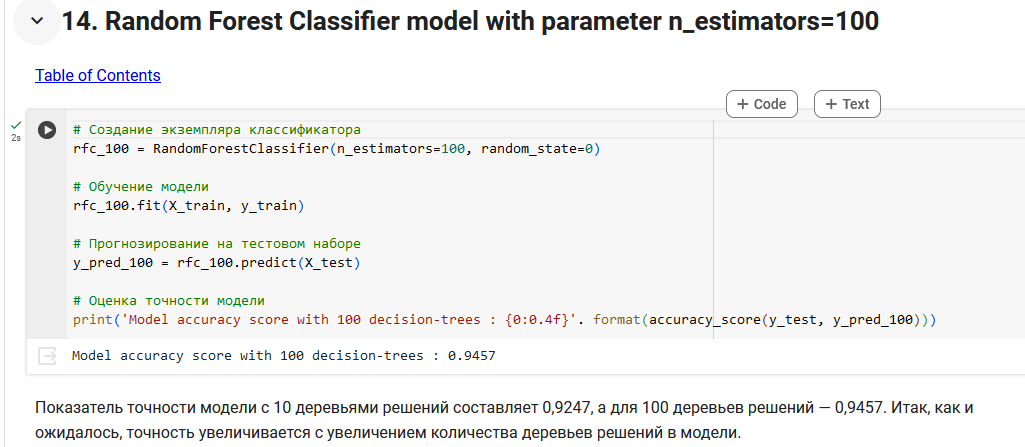
В этом проекте мы создали Random Forest Classifier для прогнозирования безопасности автомобиля. мы строим две модели: одну с 10 деревьями решений, другую со 100 деревьями решений.
Показатель точности модели для 10 деревьев решений составляет около 0,92, а для 100 деревьев решений — 0,94. Итак, как и ожидалось, точность увеличивается с увеличением количества деревьев решений в модели.
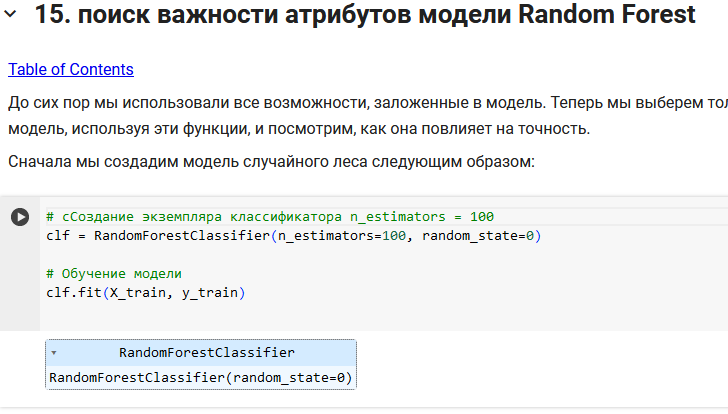
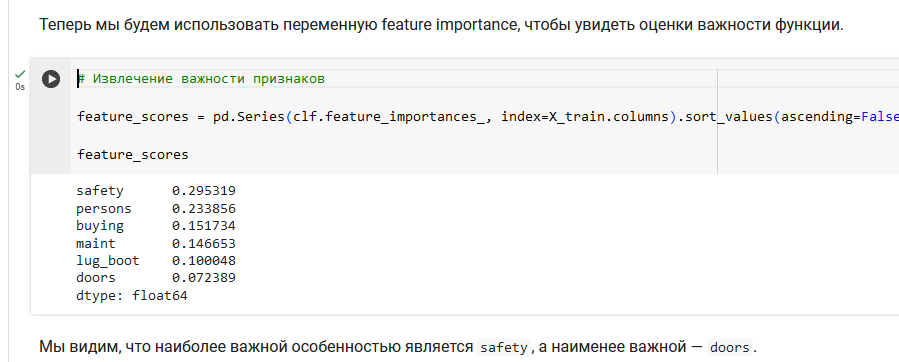
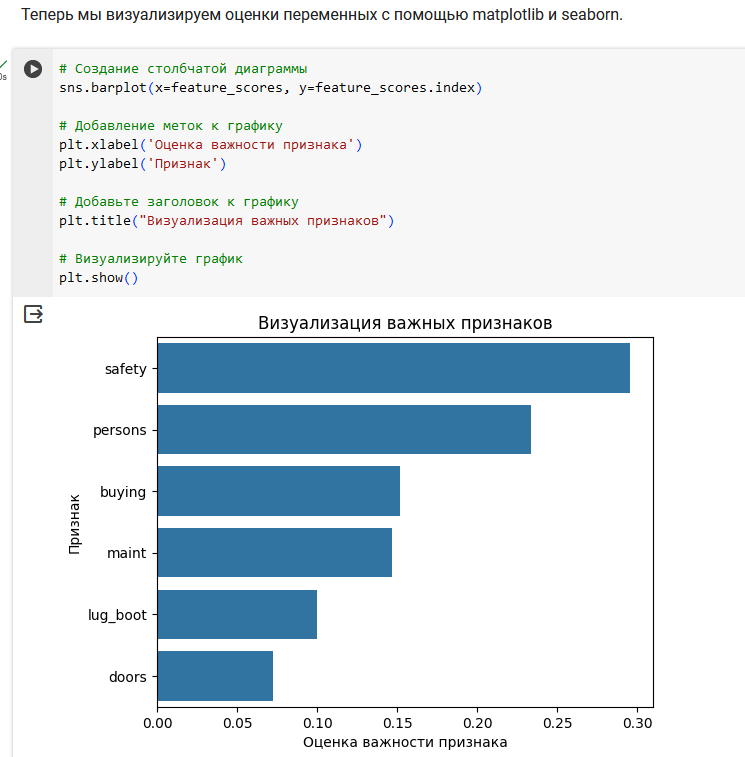
Мы использовали модель случайного леса, чтобы найти только важные функции, построить модель, используя эти функции, и увидеть ее влияние на точность. Самая важная особенность — safety, а наименее важная — doors.
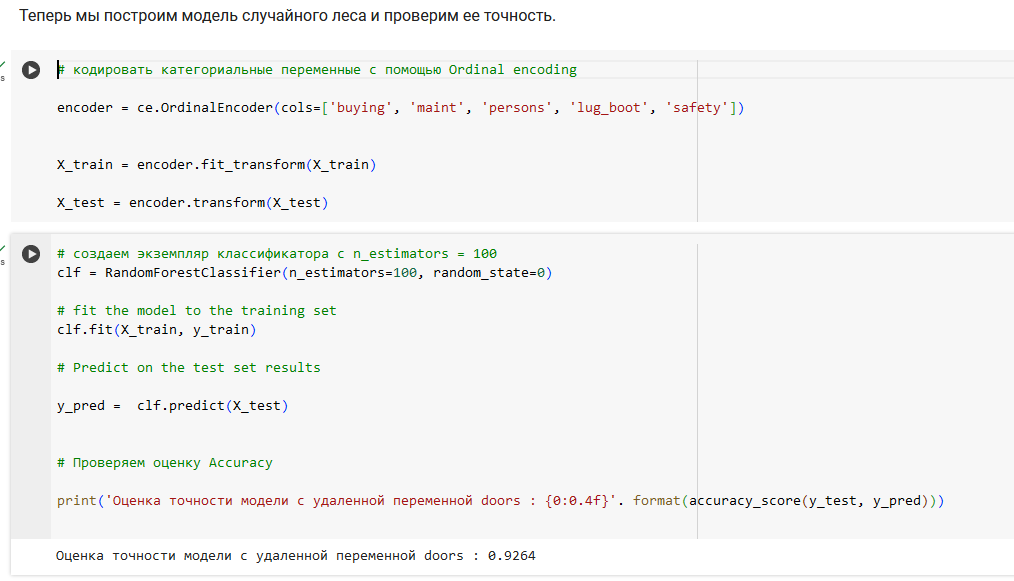
Мы удалили переменную doors из модели, перестроили ее и проверили точность модели.
Вторая наименее важная модель — lug_boot. Если мы удалим его из модели и перестроим модель, то точность окажется равной в районе 0,85. Это существенное снижение точности. Поэтому мы не будем удалять его из модели.