

Отчёт 2 лабораторная
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №2
по дисциплине
«Управление данными»
Выполнила: студентка гр. БСТ2104
Первухина Алиса Александровна
Проверила:
Тимофеева Анна Ивановна
Москва
2024
Цель работы: Изучить и применить методы аналитики данных для исследования набора данных об учениках, используя Python и библиотеки pandas, matplotlib, seaborn. Расчёт z-score, выбросов, пропущенных значений и корреляции для файла с данными о велосипедных арендах с различными метеорологическими и временными параметрами.
Задание:
1. Подготовка данных
2. Анализ данных
4. Применение Z-score
5. Расчёт выбросов
6. Работы с пропущенными значениями
7. Вычисление корреляции
8. Визуализация данных
Ход работы:
Z-оценка
Загрузим датасет eng_csv, уберем ‘;’ через сепаратор и получим датафрейм, состоящий из 4 столбцов: id ученика, Exam, Score и Advanced

Рис. 1 – вывод датафрейма eng_test
Построим гистограмму по оценкам студентов.

Рис. 2 – создание гистограммы по всем оценкам студентов
Создадим переменную, содержащую информацию только об оценках TOEFL и выведем гистограмму и основные статистики.

Рис. 3 – создание гистограммы для оценок TOEFL
Основные характеристики TOEFL:
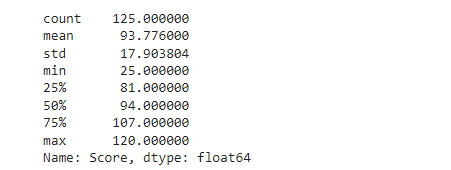
Рис. 4 – основные характеристики TOEFL
Аналогично создадим переменную, содержащую информацию только об оценках IELTS и выведем гисограмму и основные статистики
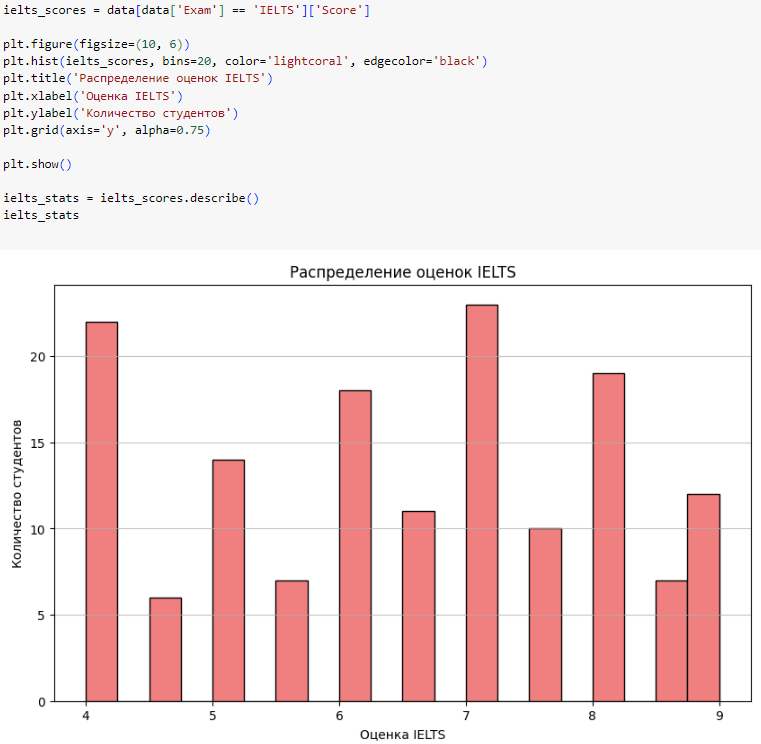
Рис. 5 – создание гистограммы для оценок IELTS
Основные характеристики IELTS:
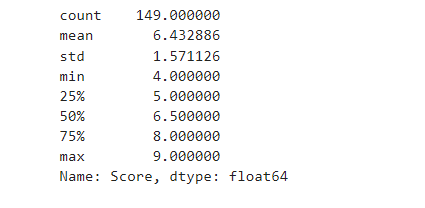
Рис. 6 – основные характеристики IELTS
Посчитаем z-score для первого студента в списке toefl. Также выведем стандартное отклонение, среднее и само кол-во баллов.

Рис. 6 – подсчёт характеристик
Сохраним в переменные Z-score для IELTS и TOEFL, соберем полученные результаты обратно в один датафрейм.

Рис. 7 – z-scores для IELTS и TOEFL
Рассчитаем, кто написал экзамен хуже, чем 3 стандартных отклонения.

Рис. 8 – расчёт оценки
Рассчитаем, кто сдал экзамен лучше? Те, кто брали продвинутый курс или нет?

Рис. 9 – расчёт
Выбросы
Разберем, как выбросы влияют на меры центральной тенденции.
Выгрузим файл в датафрейм bikes, содержащий информацию о велосипедных арендах, собранные за определённый период времени. Датафрейм включает в себя следующие колонки:
Date: Дата наблюдения.
Hour: Час дня, когда производилось наблюдение.
Temperature: Температура воздуха в градусах Цельсия.
Humidity: Влажность воздуха в процентах.
Wind speed: Скорость ветра в м/с.
Rainfall: Количество осадков в мм.
Snowfall: Высота снежного покрова в см.
Seasons: Время года (например, Зима).
Holiday: Индикатор праздничного дня (0 - не праздник, 1 - праздник).
Functioning Day: Логическое значение, указывающее, является ли день рабочим для службы велосипедных аренд (True - да, False - нет).
Rental Count: Количество велосипедов, арендованных в течение данного часа.
Normal Humidity: Индикатор нормальной влажности (0 или 1), возможно, определённый на основе некоторого порогового значения.
Temperature Category: Категория температуры (например, "Freezing" для очень низких температур).
Good Weather: Индикатор хорошей погоды (0 или 1), возможно, основанный на комбинации условий погоды, таких как осадки, температура и ветер.

Рис.10 – вывод датафрейма bikes
Выведем статическое описание колонки Rental count.

Рис.10 – вывод статического описания
Найдём
интерквартильный размах по атрибуту
'Rental
Count',
а также выведем значения q1
- 1.5 * iqr,
q3
+ 1.5 * iqr.
Рис.11 – расчёт значений

Рис.12 – расчёт значений
Определим, в какие часы какое количество выбросов было зафиксировано. (value_counts).
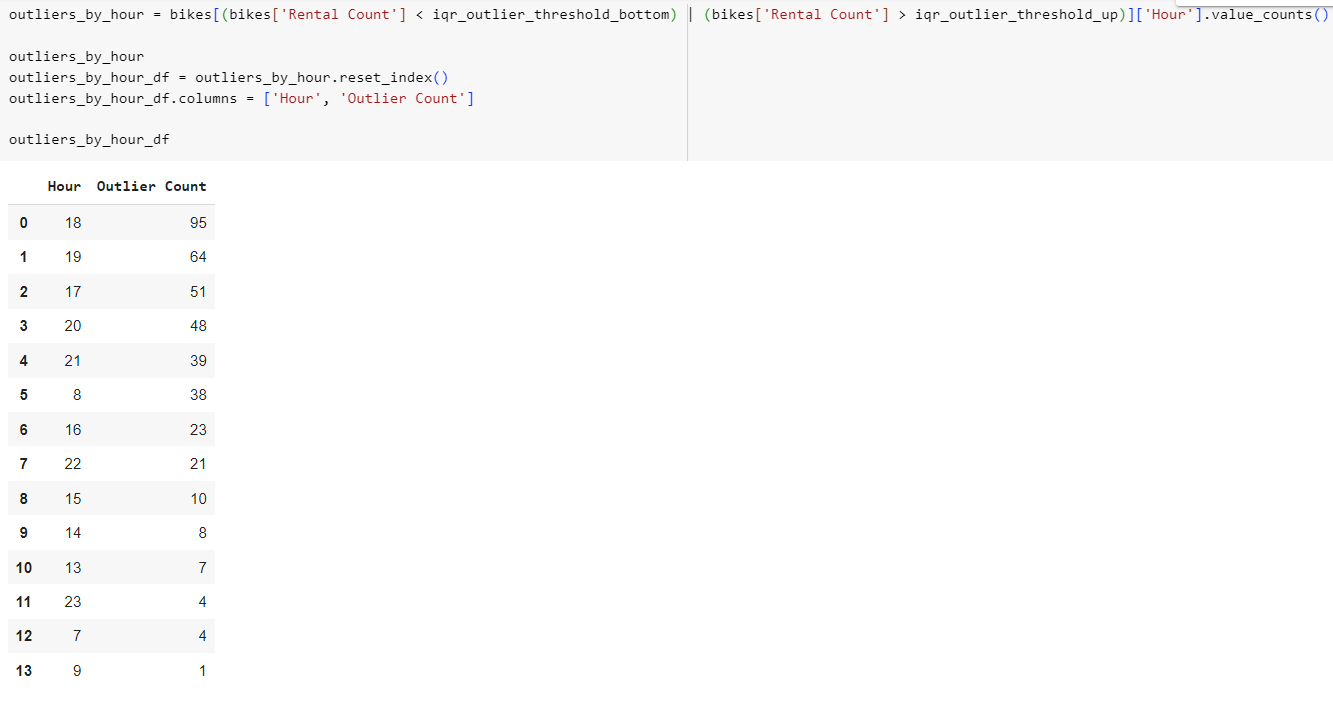
Рис.13 – расчёт значений
Выведем количество выбросов по сезонам.

Рис.14 – расчёт значений
Выведите среднее, среднеквадратичное отклонение и пороги для атрибута Rental Count (+- 2.5 стандартных отклонений)

Рис.15 – расчёт значений
Определим количество выбросов по данной метрике (Rental Count с shape)

Рис.16 – расчёт значений

Рис.17 – расчёт значений
Вывод: медиана — это более надежный показатель для описания нашего набора данных, когда в данных есть выбросы, потому что она менее подвержена их влиянию .Медиана изменится меньше, если вообще изменится, потому что она более устойчива к выбросам. Медиана — это значение, которое делит ваши данные пополам, и она не зависит от того, насколько экстремальны значения за пределами середины.
Пропущенные значения
Выгрузим
файл в датафрейм
bikes,
содержащий информацию о велосипедных
арендах, собранные за определённый
период времени.

Рис.18 – выгрузка файла
Выведем информацию о столбцах датафрейма.
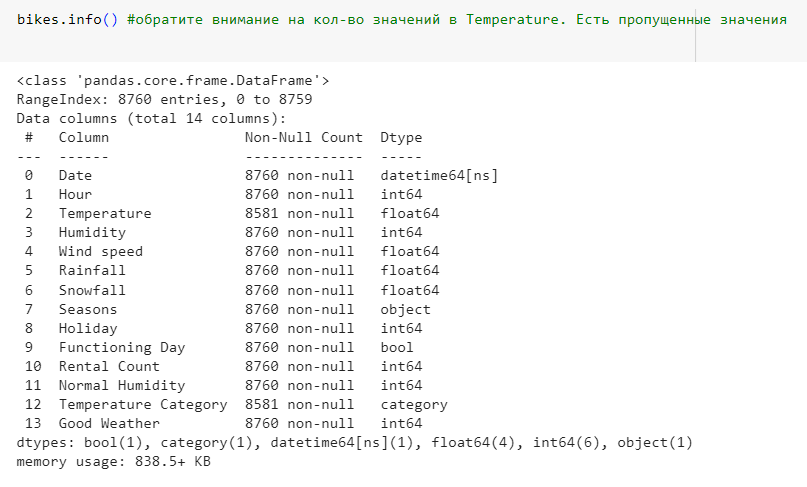
Рис.19 – вывод информации о столбцах

Рис. 20 – информация о пустых ячейках датафрейма

Рис.21 – информация о заполненных ячейках
Заполним пустые ячейки числом 42.
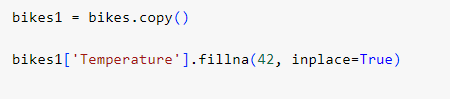
Рис.22 – заполнение пустых ячеек
Заполним
пустые ячейки в bikes
медианой. (но сохраняем в другую колонку)
Рис.23 – создание новой колонки
Заполним пустые ячейки рандомными значениями. Из доступных значений температур без пропусков случайным образом выбираются 8760 значений, которые могут повторяться. Для генерации случайных значений используются только заполненные (не пропущенные) значения температуры.

Рис.24 – заполнение рандомными значенями
Создадим новую колонку 'Temperature_Random', заполним пустые значения из Temperature, сохранив новые значчения в Temperature_Random. Значения взяты из temps.

Рис.25 – создание новой колонки
Выбираем столбец Date и преобразуем его в дату/время (если он уже не в таком формате)
Из этой даты/времени извлекается номер недели по ISO календарю. (ISO неделя начинается с понедельника, и первая неделя года — та, которая содержит первый четверг года)
Группируем по двум критериям: номер недели и часу
Для каждой каждой уникальной пары неделя-час вычисляется медианное значение температуры
В результате для первой недели года медианные значения температуры варьируются от -4.3°C в 0 часов до -5.5°C в 3 часа ночи.

Рис.26 – группировка по номеру недели и часы и медианное значение
Группировка данных по двум критериям: неделя по ISO и час.
Выбор столбца 'Temperature' для анализа
Применение трансформации к каждой группе, вычисление медианного значения температуры для этой группы. (с аргументом 'median')
Пояснение вывода: значение 2.75 для индекса 0 означает, что медианная температура для первого часа недели (по ISO календарю), к которому относится запись с индексом 0, составляет 2.75°C.

Рис.27 – группировка значений
Заполнение пропущенных значений в столбце Temperature медианными значениями температуры для каждой группы, сформированной по неделе и часу.
Сохраняем результат в новом столбце Temperature_Median_Group
Фильтруем bikes, чтобы вывести первые пять записей, где значения в столбце Temperature изначально были пропущены (NaN).
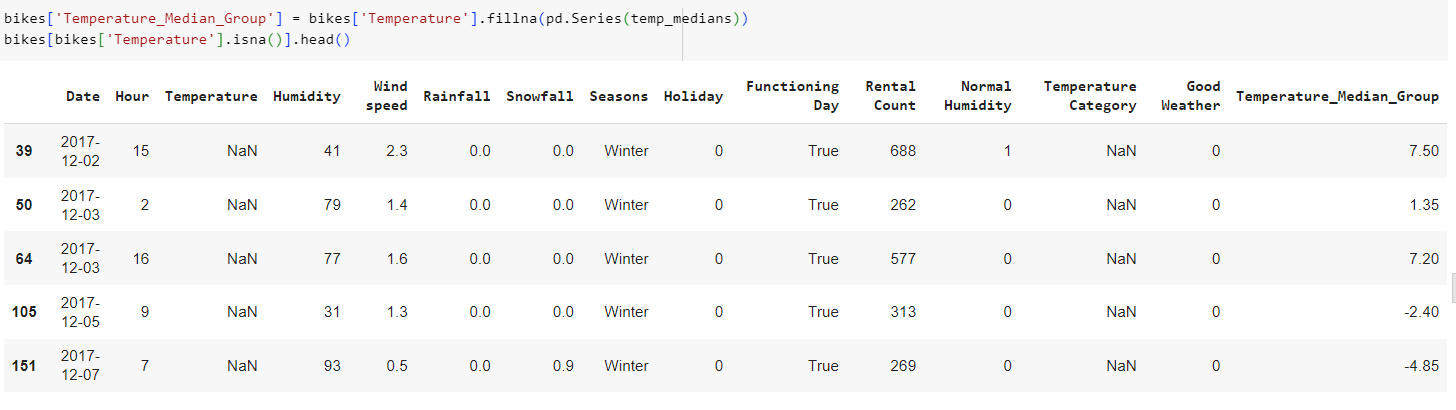
Рис.28 – группировка значений
Загрузка нового датафрейма из файла
Заполнение пропущенных значений в Temperature медианными значениями

Рис.29 – загрузка нового датафрейма
Определение функции get_temp_cat
Применяет функцию к каждому значению в столбце Temperature датафрейма
Создание нового категориального столбца (переменные с фиксированным числом категорий)
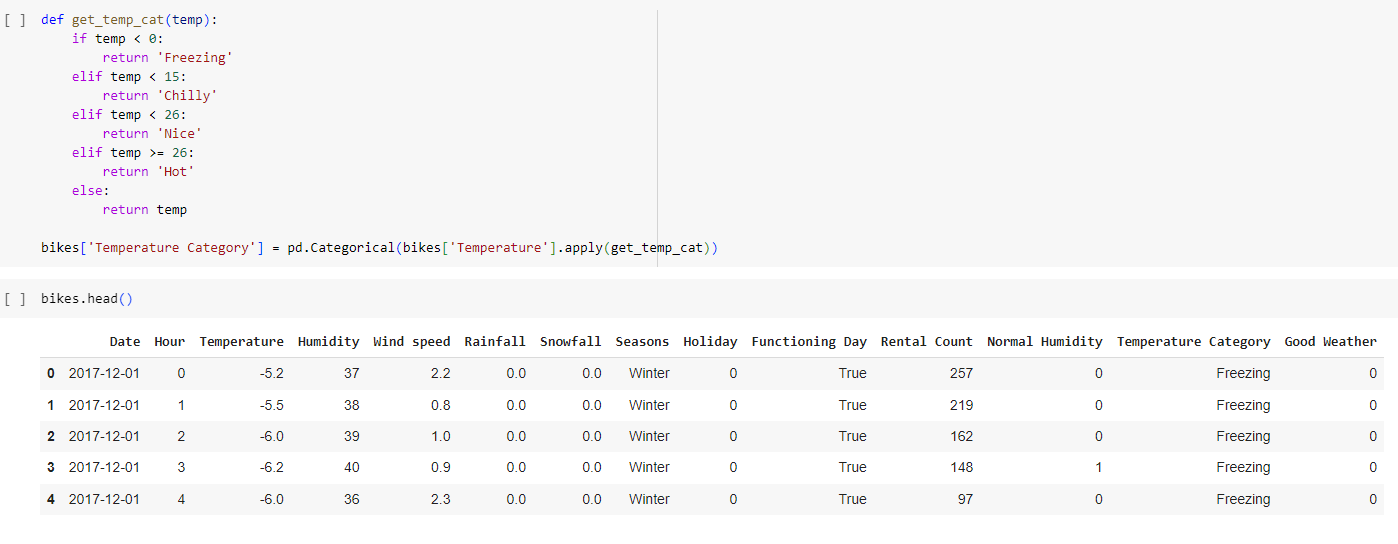
Рис.30 – создание нового категориального столбца.
Корреляция
Сохраним новый файл как датафрейм в переменную.
Рис.31 – выгрузка нового фалйа

Рис.32 – агрегация
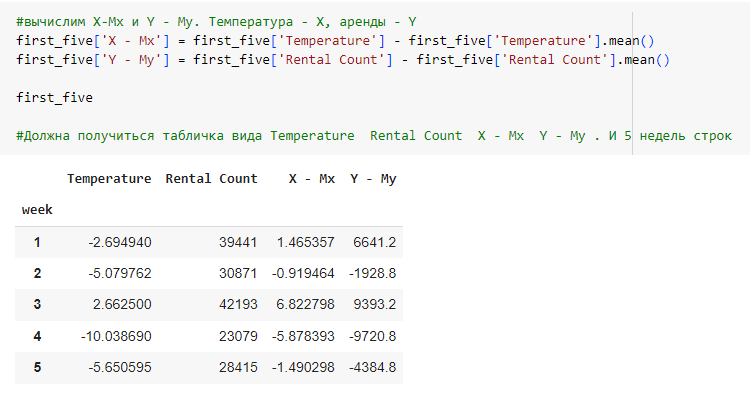
Рис.33 – подсчёт X-Mx и Y-My

Рис.34 – подсчёт значений

Рис.35 – корреляция генеральной совокупности
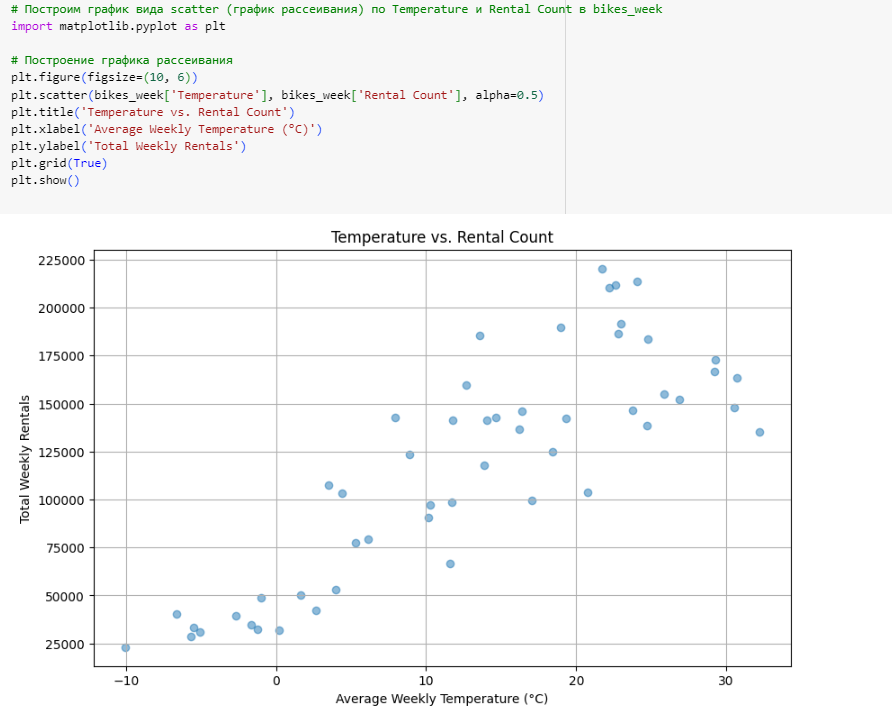
Рис.36 – построение графика рассеивания
Используем corr для вычисления коэффициента корреляции Пирсона между всеми парами столбцов в датафрейме. Каждая ячейка датафрейма будет содержать значение коэффициента корреляции между соответствующими парами столбцов. Полезно для быстро оценки, какие переменные связаны между собой и как сильно.
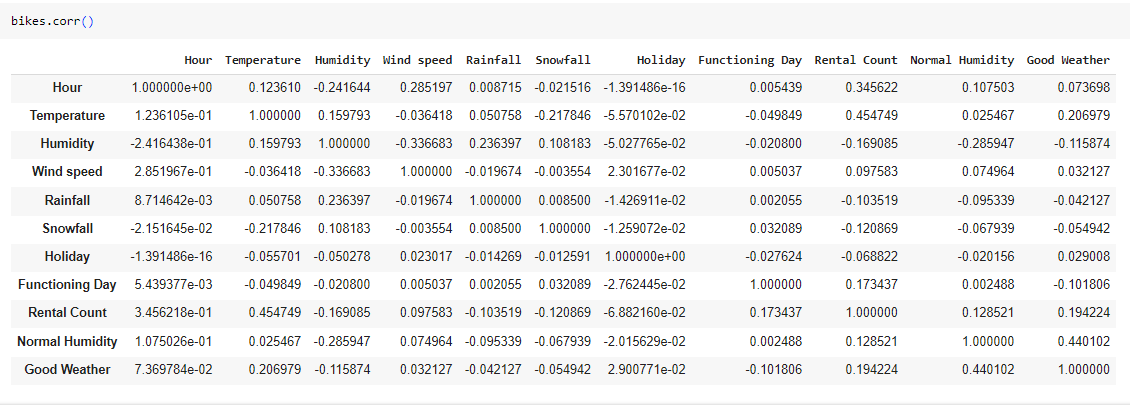
Рис.37 – корреляция между всеми стобцами
Группируем записи по неделям на основе даты, а затем вычисляем среднее значение влажности для каждой недели.
Затем группируем записи по неделям и вычисляет среднюю скорость ветра для каждой недели.

Рис.38 – группировка
Получим агрегированные данные по неделям, включая среднюю температуру, общее количество аренд, среднюю влажность и среднюю скорость ветра. Можно оценить, как эти погодные условия взаимосвязаны друг с другом и как они связаны с количеством аренд велосипедов.

Рис.39 – корреляция
Вычислим коэффициент корреляции Пирсона между всеми парами столбцов в bikes_week.
Извлечем корреляцию для Rental Count.
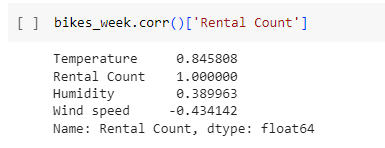
Рис.40 – корелляция

Рис. 40 – убывающий список корреляции.
Вывод