

Методические указания / Специальные структуры данных
.pdf1891
Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования
«Липецкий государственный технический университет»
Кафедра автоматизированных систем управления
О.А. Назаркин, М.Г. Журавлева
СПЕЦИАЛЬНЫЕ СТРУКТУРЫ ДАННЫХ
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
для студентов к индивидуальному домашнему заданию по курсу
«Структуры и алгоритмы компьютерной обработки данных»
Липецк 2009
УДК 681.3.01 (07)
Н 191
Назаркин, О.А. Специальные структуры данных: методические указания к ин-
дивидуальному домашнему заданию по курсу «Структуры и алгоритмы компь-
ютерной обработки данных» / О.А. Назаркин, М. Г. Журавлева. – Липецк:
ЛГТУ, 2009. – 22 с.
Предназначены для студентов направлений подготовки бакалавров 230100.62, 200500.62 и инженеров 230101.65; 230102.65; 230104.65; 230105.65; 220501.65; 230401.65; 010503.65.
Рассмотрены принципы построения и алгоритмы обработки связных блоковых,
индексированных и индексированных блоковых списков.
Табл. 1. Рис. 10. Библиогр.: 2 назв.
Рецензент В. А. Алексеев.
2 |
2 |
1.Теоретические положения
1.1.Линейные связные блоковые списки
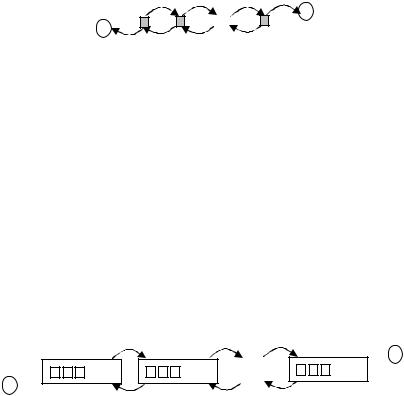
Связные линейные структуры могут быть узловыми и блоковыми. Наибо-
лее широко известны узловые списки – в них каждый элемент содержит ин-
формацию об отношениях порядка, т.е. указатели на предыдущий и следующий узлы (см. рис. 1).
... |
0 |
|
|
0 |
|
Рис. 1. Узловой связный список
Узлы списков могут быть размещены в памяти любого типа, в том числе в статической и внешней, т.е. не оперативной памяти. Так, типичным односвяз-
ным списком является структура данных FAT одноименной файловой системы,
размещаемой на внешних носителях.
В блоковых структурах элементы объединяются в группы - блоки. Явная информация "предыдущий/следующий" определяется для блока, а не для каж-
дого элемента. Элементы внутри блока содержат неявную связь, т.е. образуют массив (см. рис. 2).
 0
0
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
... |
... |
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 
Рис. 2. Блоковый связный список
Появление структуры данных, изображенной на рис. 2, обусловлено, в
основном, потребностью минимизировать время доступа к данным. Списки применяются в случаях, когда требуются частые и быстрые операции встав-
ки/удаления в произвольную позицию последовательности. Векторы же ориен-
тированы на задачи, в которых требуется эффективный доступ к элементу в произвольной позиции по индексу. Несмотря на то, что для списка можно эму-
лировать произвольный доступ, любая его реализация будет малоэффективной.
В то же время вставка/удаление в вектор тем менее эффективна, чем ближе к
3 |
3 |
началу находится позиция вставки: "хвост" приходится сдвигать на одну пози-
цию. В контейнерах профессионального уровня, например, файловых системах,
структурах данных компиляторов и интерпретаторов, часто используются связ-
ные блоковые списки. Рассмотрим организацию двусвязного блокового списка с заданным постоянным размером блока М:
const int M = 16;
...
struct Block { int cnt;
int cells[M]; Block *previous; Block *next;
};
Здесь приведена структура на языке Си для представления блока размером 16
ячеек (cells), каждая из которых хранит целое число. Интерфейс блокового спи-
ска мало чем отличается от интерфейса линейного списка любого другого вида.
Таким образом, блочная структура становится скрытой особенностью реализа-
ции. С некоторыми упрощениями определим интерфейс так:
1.Вставить элемент в голову списка (InsertToHead).
2.Удалить элемент из головы списка (DeleteFromHead).
3.Вставить элемент в хвост списка (InsertToTail).
4.Удалить элемент из хвоста списка (DeleteFromTail).
5.Вставить элемент в произвольную позицию i (Insert(i)).
6.Удалить элемент из произвольной позиции i (Delete(i)).
7.Получить значение элемента в голове (GetHeadElement).
8.Получить значение элемента в хвосте (GetTailElement).
9.Получить значение элемента в произвольной позиции i (GetElement(i)).
10.Установить значение элемента в голове (SetHeadElement).
11.Установить значение элемента в хвосте (SetTailElement).
4 |
4 |
12.Установить значение элемента в произвольной позиции (SetElement(i)).
13.Очистить список (Clear).
С узловыми списками применяют итераторы (iterator) – абстракции, сход-
ные с указателями на узлы. В зависимости от степени связности, итератор по-
зволяет переходить к следующему и/или предыдущему узлу, изменяя свое зна-
чение на новый адрес. Часто используются термины инкремент/декремент ите-
ратора – переход к следующему и предыдущему узлам соответственно. Помимо навигации по списку, итератор используется для чтения/изменения значений данных, хранящихся в узлах. С блоковым списком поэлементный итератор применяться не может, так как для граничных элементов блока семантика ите-
ратора отличается от семантики для внутренних элементов. Иными словами,
переход к предыдущему/следующему для итераторов первого, некоторого внутреннего и последнего элементов должен осуществляться по разным прави-
лам. Такое разнообразие было бы чрезвычайно неудобным в работе. Поэтому в приведенном выше интерфейсе нет функций вида "получить адрес элемента", в
отличие от широко использующегося в узловых списках соответствующего на-
бора операций. Можно было бы отказаться от функций "установить/получить значение", заменив их функциями получения адресов элементов в голове, хво-
сте и произвольной позиции, а операции чтения/изменения производить через эти указатели, которые не являются итераторами, так как не обеспечивают на-
вигацию. С другой стороны, нежелательно предоставлять доступ к внутренним данным блока из соображений надежности. Помимо надежности, всегда акту-
альна проблема повышения производительности. Представим ситуацию, что пользователь контейнера реализует просмотр элементов с изменениями, при необходимости, т.е. выполняет нечто подобное:
for (int i = 0; i < n; ++i) {
a = GetElement(i); //прочитать ячейку
...
// использовать а, возможно, изменить значение
5 |
5 |
if (некоторое условие) SetElement(i, a);
}
По законам пространственной и временной локальности, эмпирически выведенным для типичных случаев доступа к данным, вероятность того, что обращения, разделенные небольшим промежутком времени, будут осуществ-
ляться к близким в адресном пространстве ячейкам, выше вероятности обраще-
ния к разнесенным данным. Иными словами, если в указанном цикле мы обра-
щаемся к одному и тому же элементу на чтение/запись (логическое расстояние
0), то могли бы с высокой вероятностью использовать предыдущий/следующий элементы (логическое расстояние 1). И наоборот, значительно реже может по-
надобиться доступ "через один" (логическое расстояние 2) и т.д. элементы. Реа-
лизация функций GetElement/SetElement будет, в общем случае, просматривать в блоковом списке блок за блоком, начиная, например, от головы и наращивая счетчик пройденных элементов каждый раз на значение счетчика занятых эле-
ментов в текущем блоке, пока не остановится на том блоке, в котором находит-
ся запрашиваемая позиция. Это весьма длительный итеративный процесс, не-
смотря на то, что по сравнению с узловыми списками здесь происходит ускоре-
ние за счет "скачков" через блоки. Эффективная реализация функций доступа к произвольному элементу должна вести нечто вроде кэш-таблицы, содержащей два поля – номер позиции, адрес блока, в котором находится элемент, индекс элемента в массиве. При каждом обращении к некоторому элементу i сначала просматривается кэш-таблица. Если в поле "номер позиции" найдено значение i, то сопутствующая информация на этой строке используется для быстрого доступа; если же кэш не содержит позицию i, происходит общая процедура скачкообразной итерации по блокам. Когда элемент будет найден, индекс эле-
мента в массиве и адрес блока, в котором остановился поиск, следует занести в кэш.
6 |
6 |
Размер кэш-таблицы должен выбираться относительно небольшим. Сле-
дует постоянно держать в кэше записи для головы и хвоста. Так как поиск в та-
кой таблице будет, скорее всего, линейным, ее размер ограничен единицами строк (3-5). Она может включать, например, записи о голове, хвосте, последнем из запрашивавшихся элементов, предыдущем и последующем – для последнего из запрашивающихся. Как будет показано ниже, подобный кэш может эволю-
ционировать в индексную таблицу, ускоряющую доступ. Следует также иметь в виду, что кэш перестраивается при каждой операции вставки/удаления и при каждом новом обращении, что является еще одним аргументом в пользу его ог-
раниченного размера.
Вставка элемента в блок реализуется по следующему правилу:
если блок содержит свободные ячейки (т.е. cnt < M), то вставить элемент (воз-
можно, со сдвигом содержимого блока на одну позицию); увеличить счетчик;
иначе // т.е. блок заполнен до конца
создать новый блок и вставить его как узел в двусвязном списке, настроив указатели previous и next там, где необходимо. Осуществить сдвиг в ста-
ром блоке, хвостовой элемент поместить в нулевой позиции нового бло-
ка, добавляемый элемент - в освободившуюся позицию, счетчику нового блока присвоить единицу;
конец_если
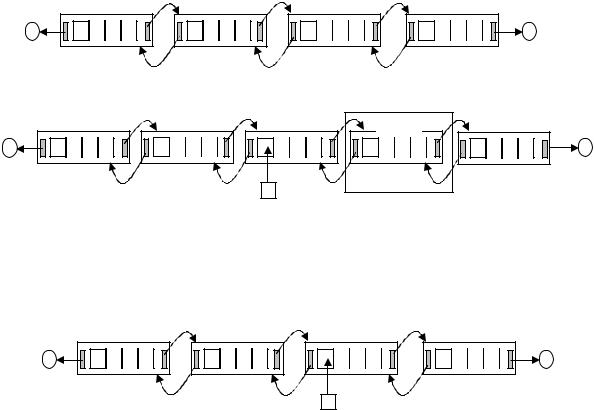
Если реализован кэш, следует обновить соответствующие позиции и ад-
реса. Графический пример вставки элемента в блоковый список приведен на рис. 3. Несмотря на то, что в блоке D (рис. 3) оставалось свободное место и мож-
но было не создавать новый блок C', а сдвинуть блок D на одну позицию вправо и разместить там "вытесняемую" из блока С букву m, был добавлен новый блок.
Очевидно, что допустимы обе стратегии (рис. 4). Назовем первый вариант встав-
ки (рис. 3) стратегией 1, а второй (рис. 4) – стратегией 2.
7 |
7 |
а
М = 4 |
A |
|
cnt = 4 |
|
|
|
0 |
а b c d |
|||
|
0 |
1 |
2 |
3 |
B
cnt = 4 |
|
|
|
e |
f |
g h |
|
4 |
5 |
6 |
7 |
C
cnt = 4 |
|
|
j |
k |
l m |
8 |
9 10 11 |
|
D
cnt = 1 |
|
n |
0 |
12 |
|
б
|
|
A |
|
|
B |
|
|
C |
С' |
D |
|
|
cnt = 4 |
|
cnt = 4 |
cnt = 4 |
cnt = 1 |
cnt = 1 |
|
||||
|
|
|
|
|
|
|
|
|
cnt = 1 |
|
|
0 |
а b c d |
e f g h |
|
j k l |
m |
n |
0 |
||||
|
0 |
1 |
2 3 |
4 |
5 |
6 7 |
8 |
9 10 11 |
12 |
13 |
|
|
|
|
|
|
|
|
i |
|
новый блок |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 3. Пример вставки элемента: а – исходный блоковый список;
б – блоковый список после вставки в позицию 8 буквы "i"
A
|
cnt = 4 |
|
|
|
0 |
а b c d |
|||
|
0 |
1 |
2 |
3 |
B
cnt = 4 |
|
|
|
e |
f |
g h |
|
4 |
5 |
6 |
7 |
|
C |
|
|
cnt = 4 |
|
|
|
|
j |
k |
l |
8 |
9 10 11 |
||
i |
|
|
|
D
cnt = 2 |
|
m n |
0 |
12 13 |
|
Рис. 4. Вставка элемента без создания нового блока
В случае использования стратегии 2 правило вставки таково:
если блок содержит свободные ячейки (т.е. cnt < M), то вставить элемент (воз-
можно, со сдвигом содержимого блока на одну позицию); увеличить счетчик;
иначе // т.е. блок заполнен до конца
если следующий блок содержит свободные ячейки, то сдвинуть содер-
жимое следующего блока на одну позицию вправо, поместить в ну-
левую позицию последний элемент текущего блока; увеличить счетчик следующего блока; сдвинуть содержимое текущего блока на одну позицию вправо, начиная с позиции вставки, разместить новый элемент;
иначе // следующий блок тоже заполнен до конца
создать новый блок и вставить его как узел в двусвязном списке,
настроив указатели previous и next там, где необходимо. Осущест-
8 |
8 |
вить сдвиг в старом блоке, хвостовой элемент поместить в нулевой позиции нового блока, добавляемый элемент - в освободившуюся позицию, счетчику нового блока присвоить единицу;
конец_если
конец_если
В зависимости от того, насколько интенсивно происходит вставка эле-
ментов, можно выбирать одну из указанных стратегий. Если вставки происхо-
дят часто, лучше добавлять новые блоки, невзирая на наличие свободного мес-
та в соседних. Если список сильно фрагментирован, предпочтительно исполь-
зовать стратегию с вытеснением в соседний, не до конца заполненный блок.
При удалении существует только одна стратегия. Общий принцип реали-
зации удаления из блока таков:
если в текущем блоке остаются элементы (т.е. cnt > 1), то сдвинуть содержимое блока на одну позицию влево, начиная с последней заполненной ячейки,
до позиции удаляемого элемента; уменьшить счетчик на единицу
иначе // удаляется последний элемент
исключить опустевший блок полностью, удалив узел в двусвязном спи-
ске, настроив указатели previous и next, где необходимо
конец_если
Графический пример удаления элементов приведен на рис. 5.
Преимущества блоковых списков перед узловыми:
1. Ускорение доступа к произвольной позиции в списке.
Для доступа к нужной позиции итерации совершаются по блокам, кото-
рых меньше, чем элементов списка, в то время как в узловых списках итерации осуществляются по узлам, которых ровно столько же, сколько элементов.
2. Снижение накладных расходов на служебные описатели динамической памяти.
9 |
9 |
а
М = 4 |
A |
|
cnt = 4 |
|
|
|
0 |
а b c d |
|||
|
0 |
1 |
2 |
3 |
B
cnt = 3 |
|
|
e |
f |
g |
4 |
5 |
6 |
б
A
|
cnt = 4 |
||
0 |
а b c d |
||
|
0 |
1 |
2 3 |
B
cnt = 2 |
|
|
f |
g |
0 |
4 |
5 |
|
C
cnt = 1 |
|
h |
0 |
7 |
|
cnt =1



 h
h 



уничтоженный блок
Рис. 5. Удаление элементов: а – исходный блоковый список; б – блоковый спи-
сок после удаления элементов из позиций 4 и 7
Каждый участок динамической памяти, занятый или свободный, содер-
жит примерно следующие дополнительные атрибуты: признак занятости, раз-
мер, указатель на следующий участок в цепочке. Известно, что описатель уча-
стка динамической памяти занимает от восьми до шестнадцати и более байт.
Объявление типичного узла занимает 12 байт: struct Node {
Node *previous; //как правило, указатель занимает 4 байта
Node *next;
int data; // размер данных целого типа, как правило, 4 байта
};
Возможно, что структура будет выровнена на параграф, т.е. границу 16
байт. Когда такой элементарный узел нужно будет разместить в куче, описате-
ли фрагмента потребуют еще от восьми до шестнадцати байт. Видно, что по-
лезная информация узла (поле int data) "тонет" среди обилия сопутствующих служебных полей.
Для блоковых списков ситуация с накладными расходами значительно улучшается. Для блока, являющегося узлом двусвязного списка, потребуются два указателя (8 байт), дополнительно – счетчик целого типа (4 байта) и уже не
10 |
10 |