

M852_Antonova_1
.pdfФедеральное государственное бюджетное образовательное учреждение высшего образования
«Московский государственный технический университет имени Н.Э. Баумана (национальный исследовательский университет)»
В.А. Антонова, В.М. Антонова
Введение в анализ больших информационных массивов
Учебно-методическое пособие


 1
1

УДК 004.041 ББК 16.333.22 А72
Издание доступно в электронном виде по адресу https://bmstu.press/catalog/item/7121/
Факультет «Информатика и системы управления» Кафедра «Защита информации»
Рекомендовано Научно-методическим советом МГТУ им. Н.Э. Баумана в качестве учебно-методического пособия
Рецензент канд. техн. наук, доцент Н.Е. Богомолова
|
Антонова, В. А. |
А72 |
Введение в анализ больших информационных массивов : учебно-ме- |
тодическое пособие / В. А. Антонова, В. М. Антонова. — Москва : Издательство МГТУ им. Н. Э. Баумана, 2021. — 50, [2] с. : ил.
ISBN 978-5-7038-5558-4
Учебно-методическое пособие предназначено для студентов высших учебных заведений, изучающих дисциплину «Введение в анализ больших информационных массивов», и содержит указания к выполнению пяти лабораторных работ для формирования у студентов навыков использования программного обеспечения и программных средств для структурирования больших массивов данных. Приведены краткие теоретические сведения, необходимые для выполнения лабораторных работ, контрольные вопросы и задания для подготовки к защите.
УДК 004.041 ББК 16.333.22
|
© МГТУ им. Н.Э. Баумана, 2021 |
|
ISBN 978-5-7038-5558-4 |
© Оформление. Издательство |
|
МГТУ им. Н.Э. Баумана, 2021 |
||
|
ПРЕДИСЛОВИЕ
Учебно-методическое пособие разработано в соответствии с учебными планами и программой дисциплины «Введение в анализ больших информационных массивов», изучаемой на втором курсе факультета «Информатика и системы управления» МГТУ им. Н.Э. Баумана, кафедра «Защита информации». Непременным условием успешного проведения практических занятий по анализу больших информационных массивов является предварительное усвоение студентами курса лекций и литературы по дисциплине.
Цель учебно-методического пособия — формирование у студентов умений и навыков в использовании программного обеспечения и программных средств для структурирования больших массивов данных. В курсе практических занятий по анализу больших информационных массивов наряду с изучением общих структур их организации предполагается практическое овладение технологиями анализа, структурирования и классификации большого количества информации с помощью специализированных средств среды MATLAB, в частности, освоение алгоритмов машинного обучения, таких как наивный байесовский классификатор, регрессионный анализ и нейронные сети. Данные средства дают представление о работе отказоустойчивых систем массового обслуживания, а также выборки данных (датасет) — множества из множеств признаков для качественной и количественной оценки.
Успешному проведению занятий должно предшествовать подробное изучение студентами некоторых теоретических данных и практических рекомендаций, включенных в настоящее пособие. Кроме того, проведение практических занятий предусматривает решение студентами контрольно-обучающих задач и самопроверку знаний по контрольным вопросам.
В учебно-методическом пособии приведены рекомендации к выполнению пяти лабораторных работ, содержащихся в курсе «Введение в анализ больших информационных массивов». Лабораторные работы позволяют студенту применить на практике полученные знания и исключить неточности в понимании принципов работы классифицирующих алгоритмов.
После выполнения лабораторных работ студент получает развернутое представление о задачах, решаемых специалистами в области анализа больших информационных массивов, а также применяет на практике некоторые методы их решения.
Полученные навыки работы с программной средой MATLAB помогут студентам в освоении других дисциплин, где потребуется смоделировать процесс, предсказать последующее поведение построенной модели, рассчитать данные, связанные сложной зависимостью со многими параметрами.
3
ВВЕДЕНИЕ
Под большими данными понимают значительное увеличение количества и скорости передачи данных, доступных для анализа.
Вкачестве примеров источников возникновения больших данных можно привести непрерывно поступающие данные с измерительных устройств, события от радиочастотных идентификаторов, потоки сообщений из социальных сетей, метеорологические данные, данные дистанционного зондирования Земли, потоки данных о местонахождении абонентов сетей сотовой связи, устройств аудио- и видеорегистрации.
Следует отметить возрастающее оцифровывание информации. Количество
иразнообразие устройств сбора и механизмов генерации данных возрастает из года в год.
Большие данные дают возможность аналитикам и специалистам по обработке данных получать более полное представление о задаче и принимать обоснованные решения. Однако работа с большим объемом данных сопряжена с некоторыми проблемами: информация таких объемов может не помещаться в доступную оперативную память, обработка может занимать слишком много времени, поступление данных — слишком быстрое для их сохранения и обработки. Стандартные алгоритмы обычно не подходят для обработки больших данных в приемлемое время или в доступной памяти. Универсального подхода для таких данных не существует. Поэтому в среде MATLAB имеется несколько инструментов для решения этих задач.
Машинное обучение используется для извлечения важной информации и разработки предсказательных моделей на больших данных. Широкий спектр алгоритмов машинного обучения включает в себя различные деревья принятия решений (в том числе boosted и bagged), метод k-средних, иерархическую кластеризацию, поиск k-ближайших соседей, гауссовы смеси, ЕМ-алгоритм, скрытые марковские модели, нейронные сети. Они доступны в пакете прикладных программ Statistics Toolbox и Neural Network Toolbox в среде MATLAB.
Внастоящем учебно-методическом пособии рассмотрено решение одной из задач классификации и описаны различные способы построения прогнозных моделей по набору исходных данных с помощью трех известных методов: наивного байесовского классификатора NaiveBayes, регрессионных деревьев TreeBagger и нейронных сетей Neural Network.
ТРЕБОВАНИЯ К ВЫПОЛНЕНИЮ И ЗАЩИТЕ ЛАБОРАТОРНЫХ РАБОТ
Лабораторная работа выполняется студентом индивидуально в соответствии с вариантом согласно списку группы.
Для выполнения лабораторных работ студентам рекомендуется:
1)изучить теоретическую часть работы;
2)подготовить к работе персональный компьютер с необходимым программным обеспечением;
3)ознакомиться с примером выполненного задания;
4)выполнить самостоятельную работу согласно варианту, выданному преподавателем;
5)составить отчет о проведении лабораторной работы;
6)подготовиться к защите отчета, ответив на контрольные вопросы, приведенные в конце каждой лабораторной работы.
Допуск к зачету предусмотрен после выполнения всех лабораторных работ. За каждую незащищенную лабораторную работу добавляется по одному дополнительному вопросу при получении зачета.
Оформлять отчет по лабораторной работе следует в соответствии с общими требованиями оформления лабораторных работ в МГТУ им. Н.Э. Баумана. Защита лабораторной работы происходит в установленное для этого время, назначенное преподавателем для всей группы. Каждая лабораторная работа оценивается от 0 до 7 баллов:
0 баллов — работа не выполнена; 1–3 балла — не полностью выполнена или отсутствует требуемое оформ-
ление; 4–6 баллов — полностью выполнена, но студент недостаточно полно отве-
чает на вопросы преподавателя; 7 баллов — студент полностью выполнил и защитил работу.

ЛАБОРАТОРНАЯ РАБОТА № 1 ВИЗУАЛИЗАЦИЯ И ОБРАБОТКА БОЛЬШИХ МАССИВОВ ДАННЫХ
В СРЕДЕ MATLAB
Цель лабораторной работы — найти оптимальное положение ветровой турбины, при котором ее коэффициент полезного действия (КПД) имеет максимальное значение при самостоятельно сгенерированных начальных данных.
Теоретическая часть
Задача проведения анализа заключается в решении интеграла, в результате чего будет найдено значение средней мощности ветровой турбины. Сначала требуется построить функцию плотности распределения. Кривую мощности турбины следует разбить на четыре региона (участка) I–IV (рис. 1.1).
Рис. 1.1. Кривая мощности ветровой турбины в среде MATLAB
Практическая часть
Для достижения поставленной цели необходимо выполнить моделирование при следующих условиях (процесс моделирования описан ниже): в трех точках на высоте 80 м установлены по три датчика скорости ветра (для усреднения данных) и один датчик температуры.
6

Моделируем случайные числа в программе Microsoft Excel, используя команду СЛЧИС(), или в любой другой программе (рис. 1.2). Для этого создаем пять столбцов: столбец 1 — время, столбцы 2–4 — скорость ветра, измеренная в одной точке тремя разными датчиками, столбец 5 — температура. Далее данные записываются в файле с расширением .txt (можно переместить таблицу в блокнот). Начинать следует
в00.00.00, заканчивать в 24.00.00, с шагом, равным 1 мин.
Импорт данных в среде MATLAB выполняется из вкладки «Home» нажатием на вкладку «Import data». В появившемся окне следует выбрать необходимый файл (.txt). После этого появится интерактивный инструмент,
вкотором можно изменить диапазон выбора данных в поле «Range». Данные можно импортировать следующими
способами: колонкой векторов (Column vector); численной матрицей (Numeric matrix); как набор из массивов ячеек
(Cell Array); как одну таблицу (Table); во вкладке «Import», с помощью которой можно просто импортировать данные (Import data), или сгенерировать скрипт (Generation Script, это удобно в случае, когда имеется один файл) либо сгенерировать функцию (Generation function в случае, когда нужно получить разные файлы, имеющие одну структуру). Необходимо также выбрать формат импорта переменных: как текст, дату или численные переменные. По умолчанию в среде MATLAB предлагается столбец 1 импортировать как текст, остальные — как численные переменные (рис. 1.3).
В столбце 1 формат следует изменить с текста на время. В качестве примера можно сгенерировать скрипт (Generation Script). Полученный скриптовый файл следует сохранить, например, назвав его «myImport». Набрав в командной строке «myImport», получим в окне рабочей области «workspace» те переменные, которые содержались в файле «myImport» (рис. 1.4).
После этого для анализа данных необходимо выполнить их визуализацию. Для этого требуется построить зависимость времени от скоростей. Выбирая требуемые переменные, переходим во вкладку «plot» и строим зависимость температуры от времени аналогично действиям с предыдущей командой. Получившиеся графики для точного анализа данных необходимо усреднить. Усреднение в среде MATLAB проводится с помощью команды «mean» по второму измерению. Для этого необходимо создать новую переменную и записать все скорости:
7

Рис. 1.3. Импорт данных
Рис. 1.4. Импортированные переменные
пользовать логические индексы
••x=[1 2 3 4 5 0] y=x>2
••V=[speed1, speed2, speed3];
••mV=mean(V,2)
Далее следует удалить информацию, которая может исказить результаты анализа. Для этого необходимо использовать критический диапазон. В качестве примера рассмотрим удаление в среде MATLAB переменных, не удовлетворяющих определенным условиям. Для этого необходимо ис-
В результате получим числа 3, 4, 5.
Возможна одновременная работа с двумя логическими условиями:
••y= x>2&x<5;
или в более простом виде
••x(x>2&x<5)
После этого с помощью команды «hold on» на ранее построенных графиках необходимо показать те значения, которые удовлетворяют предъявленным условиям (см. рис. 1.4):
••V=[speed1, speed2, speed3];
••mV=mean(V,2);
••iT=temp<2;
••iV=mV<1;
••i=iT|iV
••plot(time, temp)
••hold on
••plot(time(i), temp(i), ‘r*’)
8

Рис. 1.5. График КПД воздушной турбины
Для большей наглядности график следует выполнить в другом цвете (r — red и маркерами — *) (рис. 1.5).
Построим график зависимости средней скорости ветра при минимальной температуре от времени. Чем меньше температура воздуха и выше скорость ветра, тем больше КПД турбины.
График строится по числу точек-измерений, входящих в критический интервал. Отношение красных точек, удовлетворяющих расчетам, к синим точкам критического интервала и будет определять эффективность турбины.
После выделения лишних данных их следует удалить. Для этого можно воспользоваться командой пустых скобок «time (i)=[];». Переменные, попавшие в критический интервал, будут заменены пустым множеством, т. е. удалены из расчета. Запишем данную команду для температуры и для средней скорости.
Для решения интеграла построим гистограмму изменения температуры и с помощью численных методов определим среднюю мощность турбины.
Код, позволяющий создать гистограмму и задать ее параметры, имеет следующий вид:
••tempS(i)=[];
••mV(i) =[];
••dv=0.5;
••vb=0:dv:max(mV);
••hist(mV,vb)
Здесь dv=0.5 — строка, определяющая шаг измерений; vb=0:dv:max(mV)— строка, определяющая начало и предел гистограммы. Графически это можно представить в виде гистограммы hist(mV,vb) (рис. 1.6).
После проведения анализа и получения требуемых данных необходимо перейти с командной строки в скрипт, для того чтобы систематизировать
9
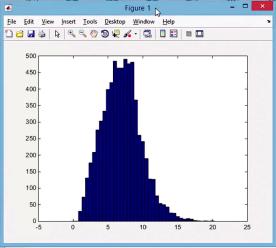
Рис. 1.6. Гистограмма, иллюстрирующая работу программы
решение. В правой части программы следует открыть вкладку «command History». Далее выбрать команды, которые важны, и перенести их в скрипт, например:
••myImport;
••plot(time,tempS);
••V=[velS1, velS2, velS3];
••mV=mean(V,2);
••iT=tempS<2;
••iV=mV<1;
••i=iT|iV;
••plot(time, tempS);
••hold on;
••plot(time(i), tempS(i),‘r*’);
••time(i)=[;
••termS(i)=[];
••mV(i)=[];
••dv=0.5;
••vb=0:dv:max(mV);
••hist(mV,vb)
В результате будут выведены все команды, которые использовались в течение работы. Желательно выбирать их вручную, отбрасывая лишние. Затем нажать правой кнопкой мыши и выбрать пункт «Create Script».
Далее необходимо назвать каждый этап работы, создавая разделение скрипта на отдельные главы с помощью знака «%%» (рис. 1.7).
Для завершения расчетов необходимо ввести некоторые команды. Отдельной главой вводятся команды, позволяющие построить и рассчитать кривую мощности турбины.
10