

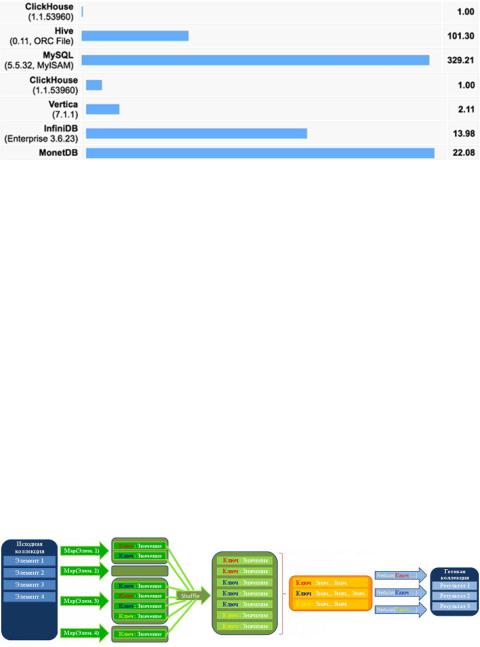
Посмотрев на график, видно, как различные базы данных отвечают на один и тот же запрос на одинаковой конфигурации: чем больше секунд, тем хуже. Самая классическая и популярная MySQL отвечает на запрос 329 секунд, при этом если посмотреть на не реляционные базы данных, типа Hive, Vertica, то они гораздо быстрее, но в том, что они так быстро работают, есть и свои негативные стороны.
Вообще, когда мы говорим про большие данные, мы говорим про принцип 3V: объём, скорость обработки и разнообразность (Volume, Variety, Velocity). Но когда мы говорим про реальный мир, нам важны ещё два пункта, которые очень важны — это лимит времени на ответ и отказоустойчивость.
Что такое MapReduce?
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера.
MapReduce — это разделение, параллельная обработка и свертка распределенных результатов
Как устроен MapReduce: принцип работы.
Прежде всего, еще раз поясним смысл основополагающих функций вычислительной модели:
•map принимает на вход список значений и некую функцию, которую затем применяет к каждому элементу списка и возвращает новый список;
•reduce (свёртка) — преобразует список к единственному атомарному значению при помощи заданной функции, которой на каждой итерации передаются новый элемент списка и промежуточный результат.