

ЛР1
.docxГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
старший преподаватель |
|
|
|
В.В. Боженко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №1 |
ПОЛНОСВЯЗНЫЕ НЕЙРОННЫЕ СЕТИ |
по курсу: МАШИННОЕ ОБУЧЕНИЕ |
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
|
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2024
Цель работы: обучить нейронную сеть для выполнения задачи регрессии и классификации.
Ход работы
Вариант 5
Импортирован датасет с информацией об автомобилях (Рисунок 1).
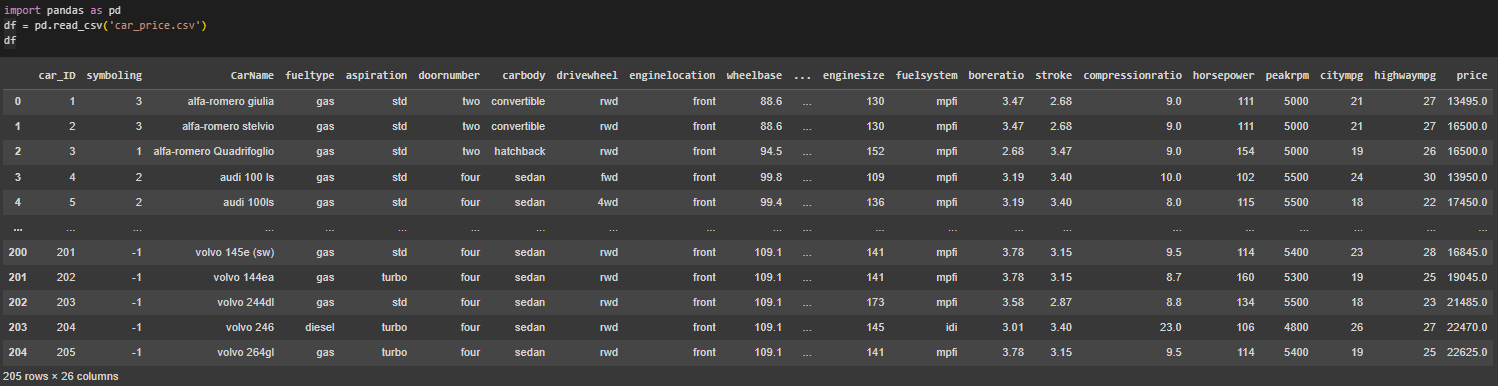
Рисунок 1 – Импорт car_price
Проведена предварительная обработка, выведено число явных дубликатов, пустых ячеек, уникальные значения в столбцах (Рисунок 2 - 4).
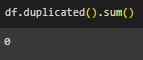
Рисунок 2 – Вывод явных дубликатов
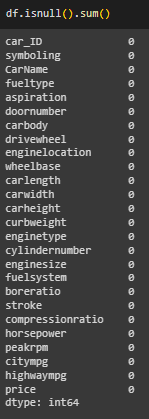
Рисунок 3 – Вывод пустых ячеек
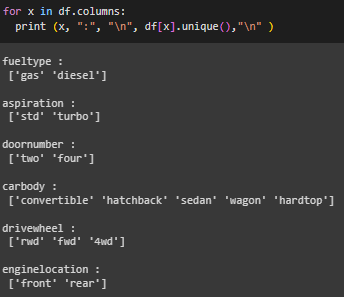
Рисунок 4 – Вывод уникальных значений
Выведена корреляция каждого признака и целевой переменной (Рисунок 5).
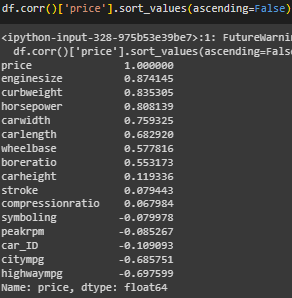
Рисунок 5 – Вывод корреляции
Переменные, которые имеют сильную положительную корреляцию с ценой автомобиля: enginesize (0.87), curbweight (0.84), horsepower (0.81), carwidth (0.76), carlength (0.68). Это означает, что более крупные, тяжелые и мощные автомобили, стоят дороже.
Отрицательная корреляция: citympg (-0.69) и highwaympg (-0.70) Это означает, что автомобили с более высоким расходом топлива обычно дешевле.
Были отобраны наиболее значимые признаки, созданы два энкодера: StandardScaler для стандартизации числовых данных и OneHotEncoder для категориальных, данные были стандартизированы (Рисунок 6).
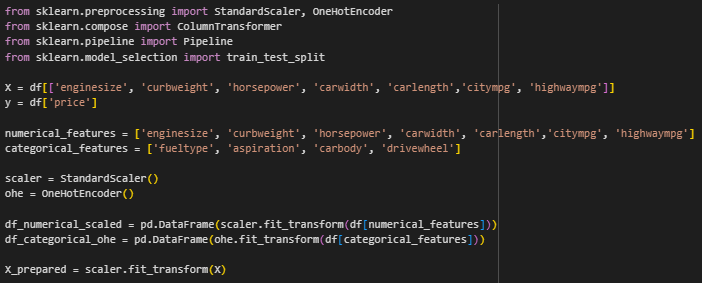
Рисунок 6 – Отбор признаков и стандартизация
Набор данных был разделен на обучающую и валидационную выборки (Рисунок 7).
![]()
Рисунок 7 – Разделение на выборки
Была создана, скомпилирована и обучена модель с одним скрытым слоем (Рисунок 8, 9). Для вывода структуры модели использовался метод summary, он позволяет увидеть структуру модели, включая количество слоев, типы активаций, и общее количество параметров (весов), которые модель будет обучать.
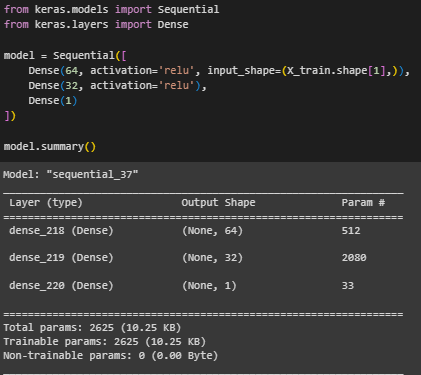 Рисунок
8 – Создание модели с 1 скрытым слоем и
её структура
Рисунок
8 – Создание модели с 1 скрытым слоем и
её структура

Рисунок 9 – Компиляция и обучение модели
Аналогично создана модель с 5 скрытыми слоями (Рисунок 10).
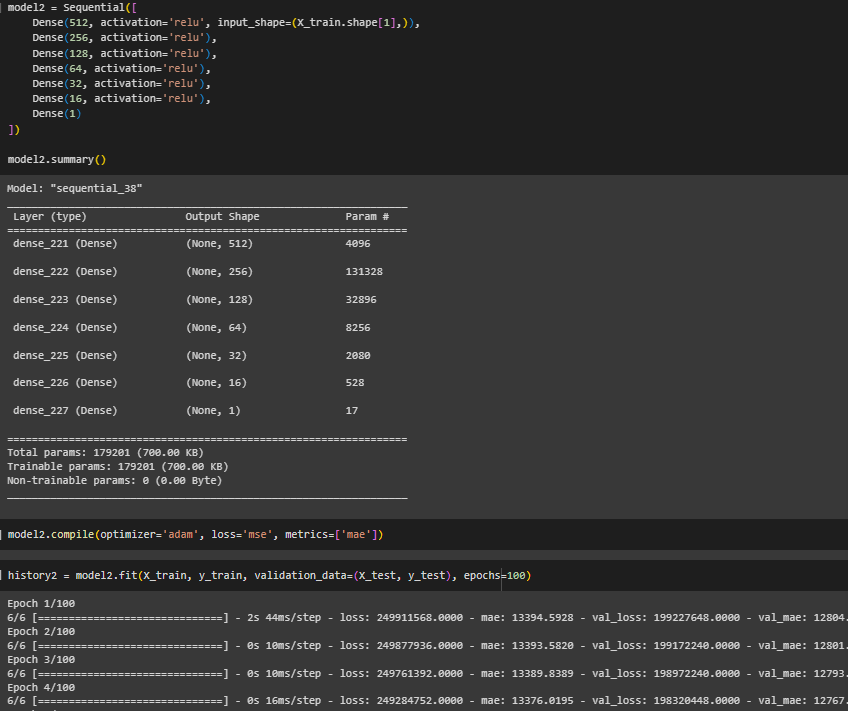
Рисунок 10 – Создание модели с 5 скрытыми слоями
С помощью evaluate выведены метрики для сравнения работы двух моделей (Рисунок 11).

Рисунок 11 – Сравнение моделей
Модель с 5 скрытыми слоями показала намного лучший результат.
Выполнены предсказания, они представлены в виде датафрейма (Рисунок 12).
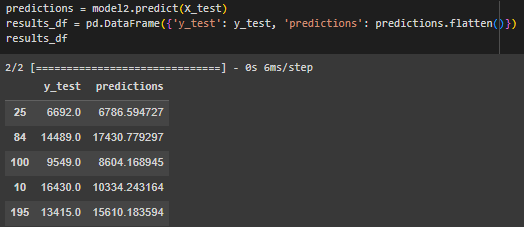
Рисунок 12 – Предсказания
Построен график истинных и предсказанных значений (Рисунок 13).
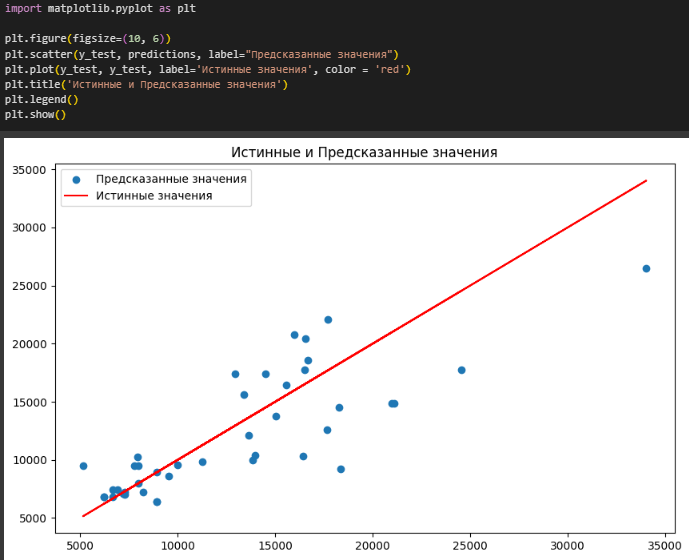
Рисунок 13 – График истинных и предсказанных значений
По граифику видно, что с увеличением значения целевой переменной разброс предсказаний увеличивается.
Построены графики зависимостей Loss и MAE от числа эпох (Рисунок 14, 15).
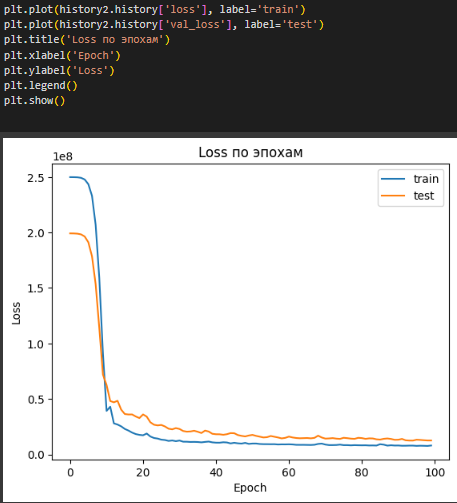
Рисунок 14 – Loss по эпохам
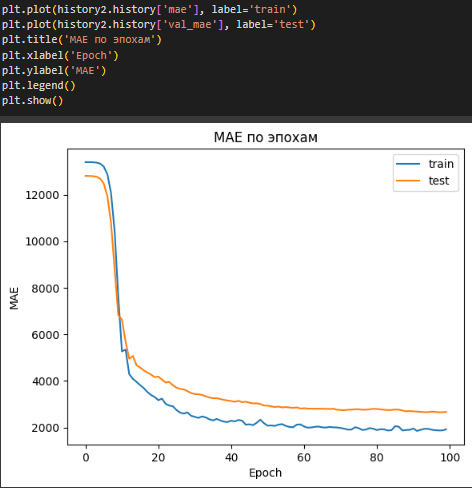
Рисунок 15 – MAE по эпохам
По графикам можно заметить, что после 15 эпох обучение происходит не так эффективно как в начале, после 40 эпох модель не становится заметно лучше.
Импортирован датасет с информацией о клиентах фитнес-клуба (Рисунок 16).
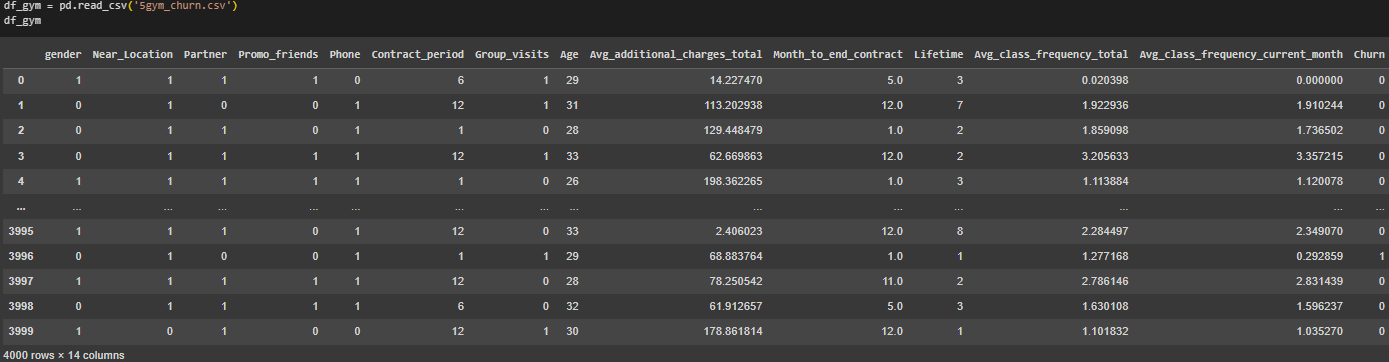
Рисунок 16 – Импорт 5gym_churn
Проведена предварительная обработка, выведено число явных дубликатов, пустых ячеек, уникальные значения в столбцах (Рисунок 17).
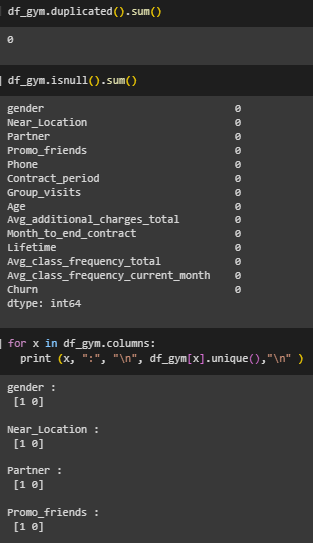
Рисунок 17 – Предварительная обработка
Пустые ячейки, дубликаты, некорретные значения не обнаружены.
Выведена корреляция признаков и целевой переменной (Рисунок 18)
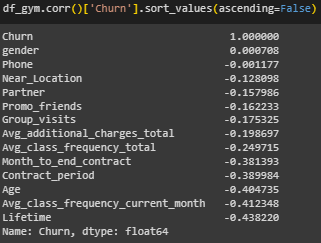
Рисунок 18 – Корреляция
Сильной корреляции не обнаружено, влияние признаков gender и Phone практически равно нулю, поэтому исключим их из выборки.
Данные были стандартизированы, разделены на тренировочную и тестовую выборки (Рисунок 19).

Рисунок 19 – Стандартизация и разделение на выборки
Создана, скомпилирована и обучена модель с 5 скрытыми слоями. Так как стоит задача классификации, на выходном слое используется сигмоидная функция активации (Рисунок 20).
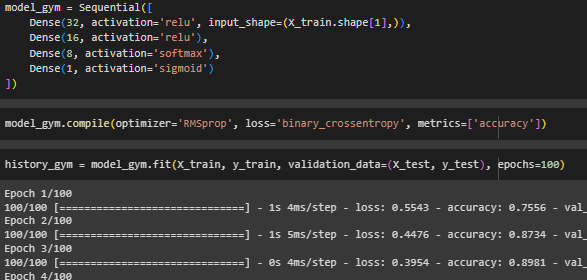
Рисунок 20 – Создание, компиляция и обучение модели
Выведены метрики (Рисунок 21).

Рисунок 21 – Метрики model_gym
Точность модели составила 0.94, значит модель хорошо предсказывает класс.
Выполнены предсказания, представлены в виде датафрейма (Рисунок 21).
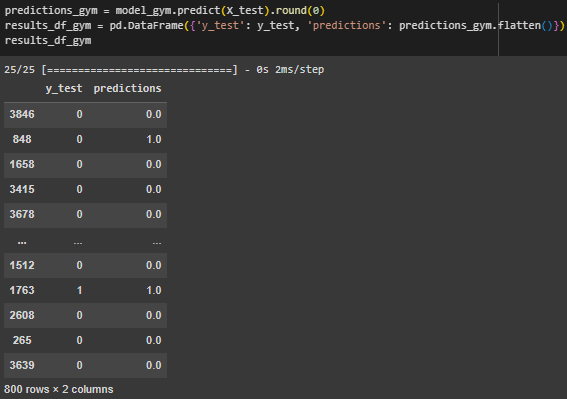
Рисунок 21 – Предсказания model_gym
Построены графики зависимостей Accuracy и Loss от числа эпох (Рисунок 22, 23).
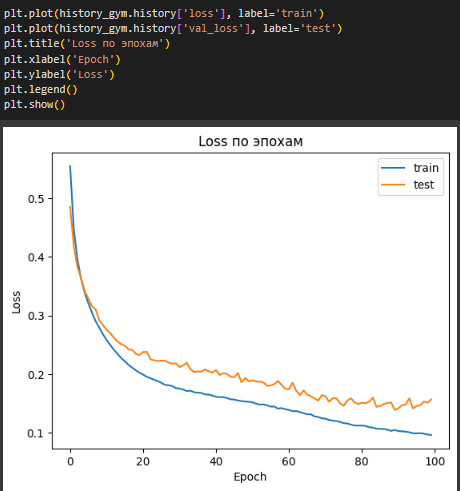
Рисунок 22 – Loss по эпохам
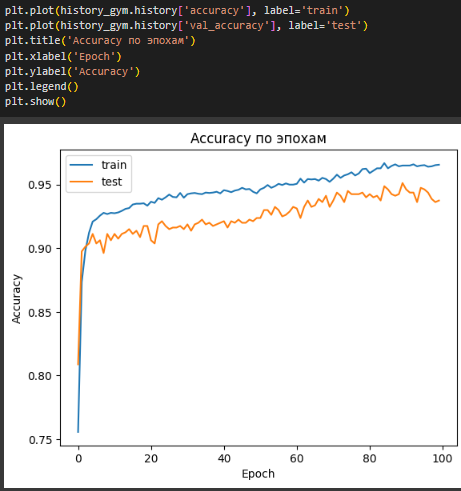
Рисунок 23 – Accuracy по эпохам
Оба графика показывают, что на первых 10 эпохах модель учится очень быстро, затем эффективность обучения снижается. В конце графики и начинают расходиться, что свидетельствует о начале переобучения.
Была построена ROC-кривая, она представляет собой график, который показывает изменение отношения между верными положительными (True Positive Rate) и ложными положительными (False Positive Rate) классификациями в зависимости от изменения порога классификации.
AUC, или площадь под ROC-кривой, измеряет способность модели классификации отличать между положительными и отрицательными классами. Значение AUC варьируется от 0 до 1, где 1 указывает на идеальную классификацию, а 0.5 — на отсутствие способности классификации.
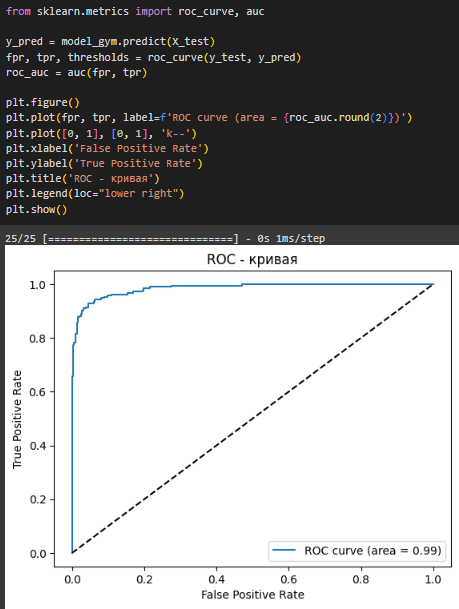
Практически все значения были предсказаны верно.
Ссылка на Google Colab:
Вывод:
В ходе выполнения лабораторной работы были созданы и обучены модели для решения задач регрессии и классификации. При решении задачи регрессии более эффективной оказалась модель с 5 скрытыми слоями. Средняя ошибка составила 2667.
Модель, созданная для решения задачи классификации показала точность 0.94, после округления точность составила 0.99, что говорит о практически идеальном предсказании класса. Построена ROC-кривая для визуализации эффективности модели.
Для решенных задач построены графики ошибок и потерь в зависимости от эпох, с увеличением числа эпох эффективность обучения снижается.