

Боженко ЛР / АД5
.docxГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
старший преподаватель |
|
|
|
В.В. Боженко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №5 |
КЛАССИФИКАЦИЯ |
по курсу: ВВЕДЕНИЕ В АНАЛИЗ ДАННЫХ |
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
|
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2023
Цели работы: изучение алгоритмов и методов классификации на практике.
Ход работы
Вариант 5
Импортирован датасет с информацией о клиентах фитнес-клуба (Рисунок 1).
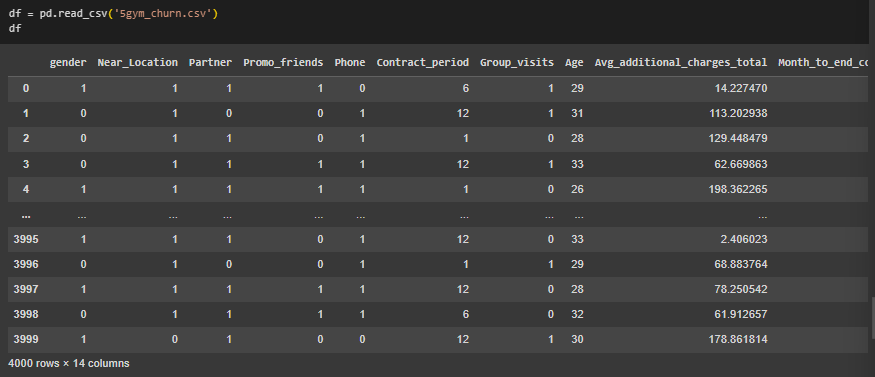
Рисунок 1 – Импорт датасета
Проведена предварительная обработка данных (Рисунок 2 - 5).

Рисунок 2 – Информация о столбцах датасета
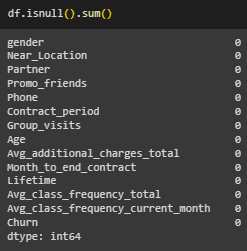
Рисунок 3 – Число пустых ячеек
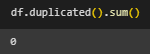
Рисунок 4 – Число дубликатов
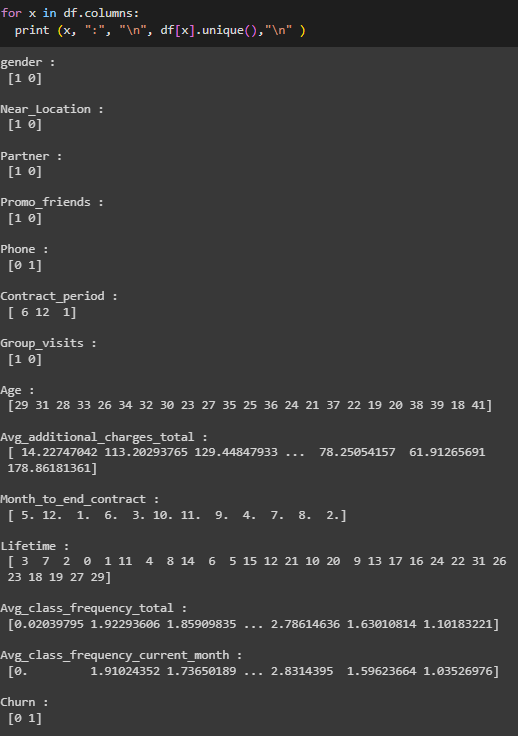
Рисунок 5 – Уникальные значения
Несоответствий типов данных, явных и неявных дубликатов не обнаружено.
Выбрана целевая переменная Churn, построена матрица диаграмм рассеяния (Рисунок 6).
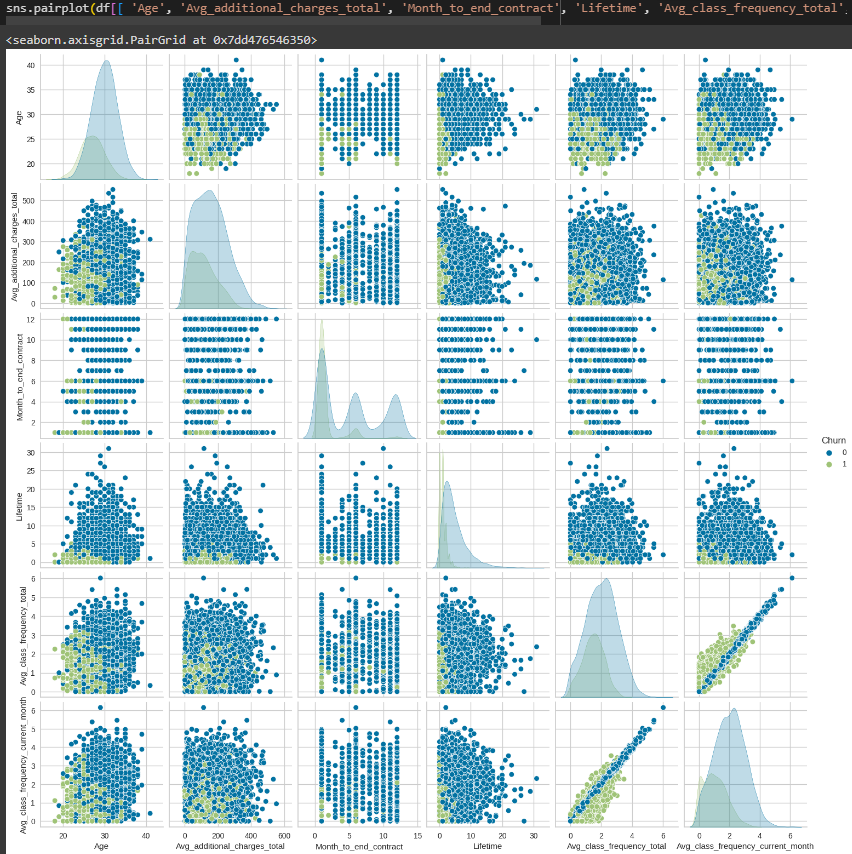
Рисунок 6 – Матрица диаграмм рассеяния
Большинство клиентов в этом наборе данных не покинули фитнес-клуб. Большая часть клиентов, у которых осталось меньше 5 месяцев до окончания контракта, покинули фитнес-клуб. Клиенты, покинувшие клуб, наиболее вероятно провели в нём меньше 3 месяцев.
Набор данных был разделен на тренировочный и тестовый датасеты (Рисунок 7).

Рисунок 7 – Разделение на тренировочный и тестовый датасеты
Выполнена стандартизация числовых данных с помощью StandardScaler (Рисунок 8).
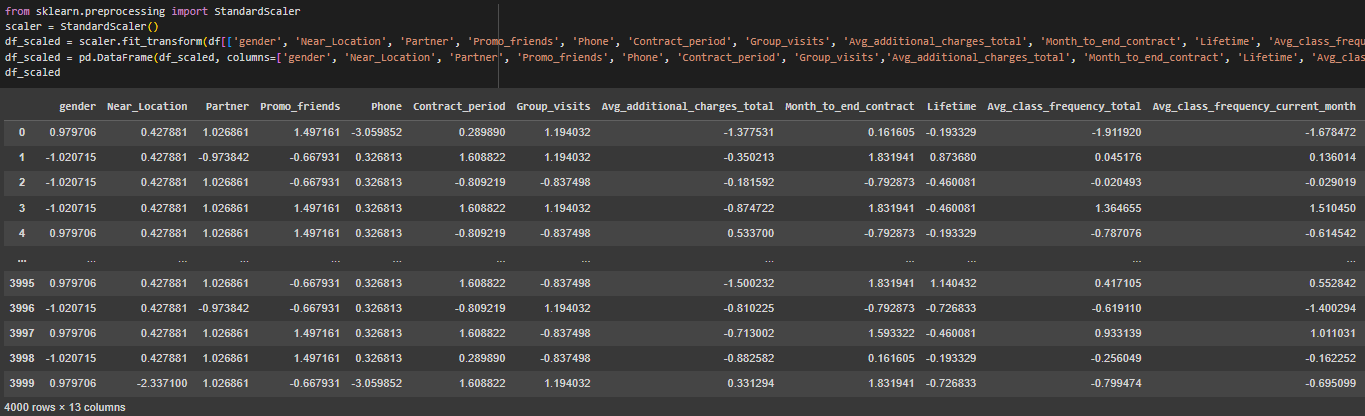
Рисунок 8 – Стандартизация
Выполнена классификация методом k-ближайших соседей (Рисунок 9). Основная идея KNN заключается в том, чтобы присвоить новому наблюдению класс или значение, исходя из классов или значений его k ближайших соседей в обучающем наборе данных.
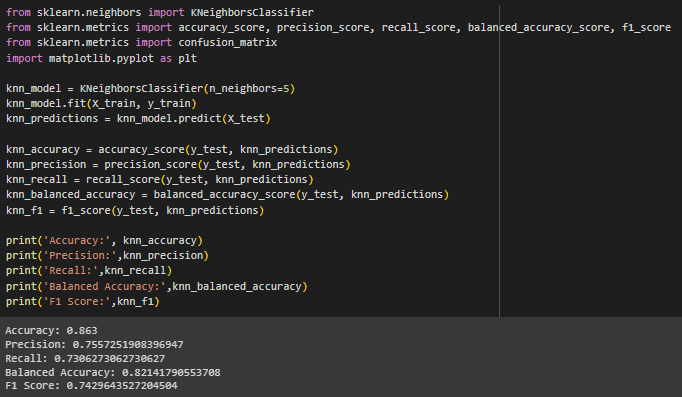
Рисунок 9 – Классификация методом KNN
Выполнена классификация методом дерева решений (Рисунок 10). Дерево решений представляет собой структуру, где каждый внутренний узел обозначает проверку одного из признаков, каждая ветвь представляет собой возможный результат этой проверки, а каждый листовой узел представляет собой конечный классификационный результат.
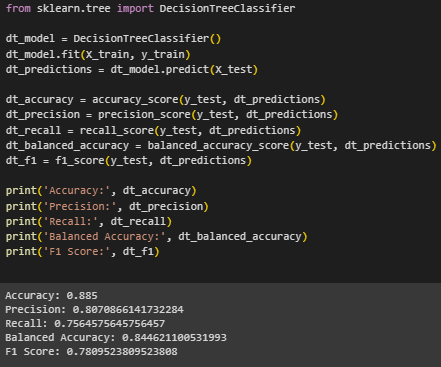
Рисунок 10 – Классификация методом Decision Tree
Выполнена классификация методом логистической регрессии (Рисунок 11). Логистическая регрессия предсказывает вероятность принадлежности объекта к классу с помощью логистической функции, также называемой сигмоидной функцией.
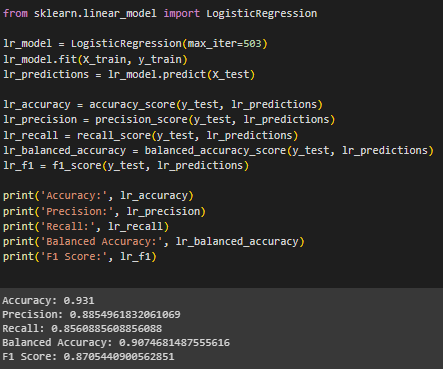
Рисунок 11 – Классификация методом Logistic Regression
Выполнена классификация методом случайного леса (Рисунок 12). Случайный лес комбинирует прогнозы нескольких деревьев решений для достижения более точного и стабильного результата.

Рисунок 12 – Классификация методом Random Forest
Была построена и выведена на экран таблица с метриками для каждого метода классификации (Рисунок 13).
Accuracy - отношение числа верных прогнозов к общему количеству прогнозов.
Precision – это доля объектов, называемые классификатором положительными и при этом действительно являющихся положительными.
Полнота (Recall) – это то, какую долю объектов положительного класса из всех объектов положительного класса нашёл алгоритм.
F1-мера – среднее гармоническое значение точности и полноты, обозначает, как много сделано правильных прогнозов, и сколько положительных объектов модель не пропустит.
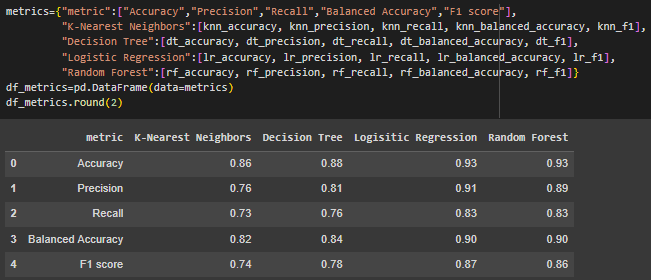
Рисунок 13 – Таблица с метриками
Logistic Regression и Random Forest показали лучшую общую производительность с точки зрения Accuracy (0.93). Это означает, что обе модели правильно предсказывают класс в 93% случаев.
Random Forest вышел немного вперед с точки зрения Precision (0.89 против 0.91 у Logistic Regression).
В то время как Logistic Regression показал лучший Recall (0.83), что означает, что модель нашла 83% всех реальных положительных случаев.
Logistic Regression и Random Forest также разделили первое место по Balanced Accuracy и F1 score, что указывает на хорошее сбалансированное представление обеих моделей в предсказании классов и хорошее сочетание Precision и Recall.
Decision Tree показал себя лучше, чем K-Nearest Neighbors по всем показателям, но уступил Logistic Regression и Random Forest. Это может указывать на некоторую переобучаемость или недостаточную обобщающую способность по сравнению с другими моделями.
K-Nearest Neighbors показал наименьшие значения метрик среди всех рассмотренных моделей, что говорит о том, что данный метод менее подходит для набора данных.
Была построена матрица ошибок для каждого метода классификации (Рисунок 14, 15).
Матрица ошибок отражает количество наблюдений в каждой группе и представляет собой таблицу с двумя измерениями – «Actual» и «Predicted», каждое из которых представлено множеством прогнозируемых классов. Столбцы являются фактическими результатами, а строки прогнозируемым результатом работы классификатора.
Левый верхний квадрат (True Negative, TN): количество негативных случаев, правильно идентифицированных моделью.
Правый верхний квадрат (False Positive, FP): количество негативных случаев, неправильно идентифицированных моделью как позитивные.
Левый нижний квадрат (False Negative, FN): количество позитивных случаев, неправильно идентифицированных моделью как негативные.
Правый нижний квадрат (True Positive, TP): количество позитивных случаев, правильно идентифицированных моделью.
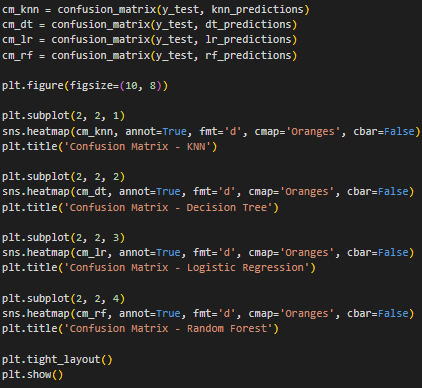
Рисунок 14 – Код для построения матриц ошибок
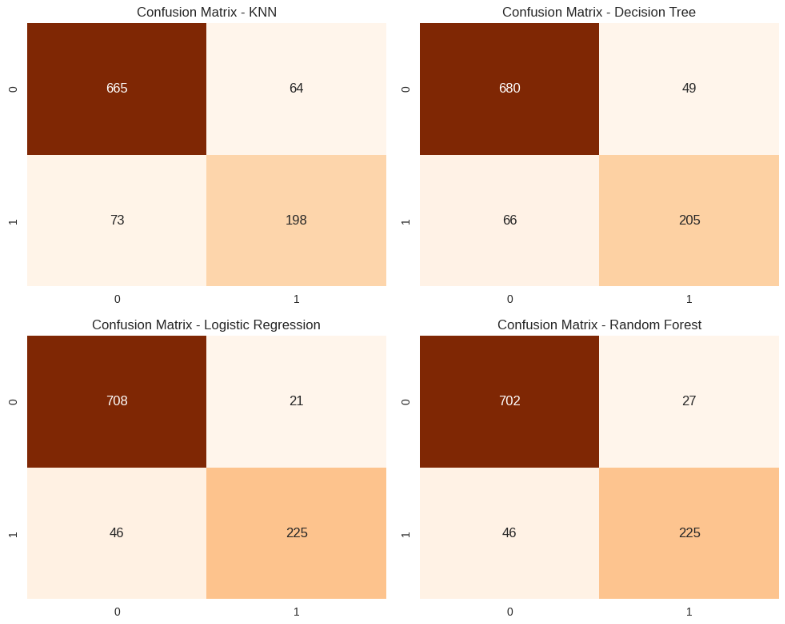
Рисунок 15 – Матрицы ошибок
Logistic Regression и Random Forest показывают наилучшее количество TP, что указывает на их способность лучше всего обнаруживать положительные случаи.
Logistic Regression имеет самое маленькое количество FP, что делает эту модель наиболее точной в отношении ложных срабатываний.
Decision Tree демонстрирует неплохой баланс между четырьмя категориями, но имеет более высокий уровень FP по сравнению с Logistic Regression и Random Forest.
K-Nearest Neighbors имеет самый высокий уровень FN, что говорит о том, что эта модель чаще всего неправильно пропускает положительные случаи.
Построена ROC-кривая (Рисунок 16, 17). ROC-кривая представляет собой график, который показывает изменение отношения между верными положительными (True Positive Rate) и ложными положительными (False Positive Rate) классификациями в зависимости от изменения порога классификации.
AUC, или площадь под ROC-кривой, измеряет способность модели классификации отличать между положительными и отрицательными классами. Значение AUC варьируется от 0 до 1, где 1 указывает на идеальную классификацию, а 0.5 — на отсутствие способности классификации.
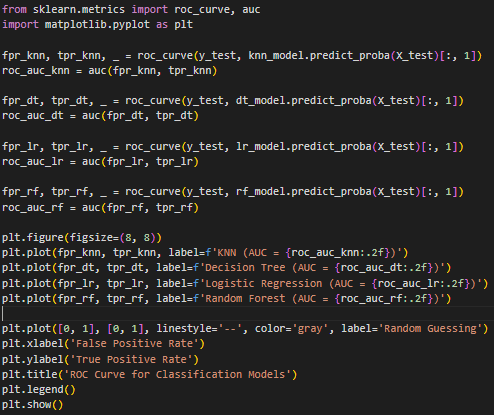
Рисунок 16 – Построение ROC – кривой
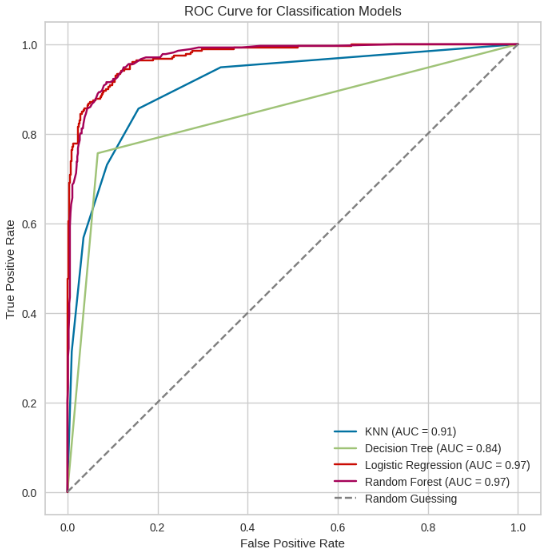
Рисунок 17 – ROC – кривая
KNN (AUC = 0.91): Эта модель имеет высокий AUC, что указывает на хорошую способность классификации между положительными и отрицательными классами. Кривая быстро поднимается вверх и приближается к левому верхнему углу, что свидетельствует о высоком качестве классификации.
Decision Tree (AUC = 0.84): Эта модель имеет более низкий AUC по сравнению с KNN и другими моделями, что может указывать на более слабую способность различать между классами. Кривая более пологая, особенно в начальной части графика, что означает более высокий уровень ложноположительных результатов при низких порогах.
Logistic Regression (AUC = 0.97): Эта модель показывает превосходную способность различения классов, с AUC, приближающимся к 1. Кривая находится близко к верхнему левому углу, что означает высокий True Positive Rate при низком False Positive Rate на протяжении различных пороговых значений.
Random Forest (AUC = 0.97): Подобно логистической регрессии, случайный лес показывает отличное качество классификации. Его кривая также проходит близко к верхнему левому углу и совпадает с кривой логистической регрессии, что говорит о схожей диагностической способности.
На основе графика, Logistic Regression и Random Forest являются лучшими моделями для классификации выбранного набора данных, так как их ROC-кривые и AUC значения показывают наивысшую диагностическую способность отличать классы. Decision Tree показывает худшую производительность среди всех, в то время как KNN занимает промежуточное положение.
Ссылка на Google Colab:
Вывод:
В ходе выполнения лабораторной работы был проведен тщательный анализ четырёх различных алгоритмов классификации — K-Nearest Neighbors, Decision Tree, Logistic Regression и Random Forest — на основе набора данных с информацией о посетителлях фитнес-клуба. Для оценки и сравнения производительности каждого из методов были рассчитаны такие метрики, как Accuracy, Precision, Recall, Balanced Accuracy и F1 score. Кроме того, были построены матрицы ошибок и ROC-кривая, что позволило оценить способность каждой модели к правильному классифицированию объектов.
В результате анализа было выявлено, что модели Logistic Regression и Random Forest демонстрируют отличные показатели по всем метрикам, отражая их высокую эффективность и надёжность в задачах классификации. Эти модели не только показали высокую точность в классификации, но и выделились своей способностью к минимизации ошибок, что делает их наиболее пригодными для применения.