

Bilety_1-52_Os (2)
.pdf№24 Сегментно-страничная организация виртуальной памяти.
При сегментно-страничной организации виртуальной памяти происходит двухуровневая трансляция виртуального адреса в физический. В этом случае виртуальный адрес состоит из трех полей: номера сегмента виртуальной памяти, номера страницы внутри сегмента и смещения внутри страницы.
Соответственно, используются две таблицы отображения - таблица сегментов, связывающая номер сегмента с таблицей страниц, и отдельная таблица страниц для каждого сегмента.
Сегментно-страничная организация виртуальной памяти позволяла совместно использовать одни и те же сегменты данных и программного кода в виртуальной памяти разных задач (для каждой виртуальной памяти существовала отдельная таблица сегментов, но для совместно используемых сегментов поддерживались общие таблицы страниц).
№25 Концепция локальности и теория рабочего множества.
Концепция локальности
Изучая свойства локальности в пейджинговых системах, Деннинг (1968) сформулировал теорию рабочего множества программ (см. ниже).
Модель локальности состоит в том, что когда процесс выполняется, он двигается от одной локальности к другой. Локальность - набор страниц, которые активно используются вместе. Программа обычно состоит из нескольких различных локальностей, которые могут перекрываться. Например, когда вызвана процедура, она определяет новую локальность, состоящую из инструкций процедуры, ее локальных переменных, и множества глобальных переменных. После ее завершения процесс оставляет эту локальность, но может вернуться к ней вновь. Таким образом, локальность определяется кодом и данными программы. Заметим, что модель локальности - принцип, положенный в основу работы кэша. Если бы доступ к любым типам данных был случайным, кэш был бы бесполезным.
Если процессу выделять меньше кадров, чем ему нужно для поддержки его локальности он будет находиться в состоянии трешинга.
Модель рабочего множества (Working Set)
Вварианте чистого пейджинга процессы стартуют без необходимых страниц в памяти. Первая же машинная инструкции генерирует page fault. Другой page fault происходит при локализации глобальных переменных и тут же при выделении памяти для стека. После того как процесс собрал большинство страниц, page fault'ы далее редки. Эта все происходит в соответствии с выборкой по запросу (требованию) в отличие от выборки с упреждением. Конечно, легко написать тестовую программу, которая систематически работает с большим адресным пространством. К счастью, большинство процессов не ведут себя подобным образом, а проявляют свойство локальности. В течение любой фазы вычислений процесс работает с небольшим количеством страниц. Этот набор называется рабочим множеством. (Denning 1968,1980).
Внекотором смысле предложенный Деннингом подход является практически реализуемой аппроксимацией оптимального алгоритма (см. также [28]. Принцип локальности ссылок (недоказуемый, но подтверждаемый на практике) состоит в том, что если в период времени (T-t, T) программа обращалась к страницам (P1, P2, ..., Pn), то при надлежащем выборе t с большой вероятностью эта программа будет обращаться к тем же страницам в период времени (T, T+t). Другими словами, принцип локальности утверждает, что если не слишком далеко заглядывать в будущее, то можно хорошо его прогнозировать исходя из прошлого. Набор страниц (P1, P2, ..., Pn) и есть рабочее множество программы (или, правильнее, соответствующего процесса) в момент времени T. Понятно, что с течением времени рабочий набор процесса может изменяться (как по составу страниц, так и по их числу).
Наиболее важное свойство рабочего множества - его размер. ОС выделяет каждому процессу достаточное число кадров, чтобы поместилось рабочее множество. Если еще остались кадры, то может быть инициирован другой процесс. Если рабочие множества процессов не помещаются в память, и начинается трешинг, то один из процессов надо попридержать.
Решение о размещении процессов в памяти должно, следовательно, базироваться на размере его рабочего множества. Для впервые инициируемых процессов это решение может быть принято эвристически. Во время работы размер рабочего множества процесса динамически меняется. Система
должна уметь определять: расширяет процесс свое рабочее множество или перемещается на новое рабочее множество. Если память мала, чтобы содержать рабочее множество процесса, то page fault'ов много.
В системах с разделением времени процессы часто перемещаются на диск. Что делать, когда процесс возвращается в память. Опять ждать пока он соберет свое рабочее множество? Поэтому многие системы хранят информацию о рабочих множествах процессов и загружают их, даже если процесс еще не стартовал (стратегия выборки с упреждением).
Размер рабочего множества может быть фиксированным, а может динамически настраиваться. Рассмотрим один из алгоритмов динамической настройки рабочего множества. При создании каждому процессу назначается минимальный размер рабочего множества, определяющий число страниц процесса, гарантированно находящихся в физической памяти при его выполнении. Если процессу требуется физических страниц больше, чем минимальный размер рабочего множества, и в наличии имеется свободная физическая память, то система будет увеличивать размер рабочего множества, но, не превышая максимального размера. Если же процессу требуется еще больше страниц, то дополнительные страницы будут выделяться за счет свопинга, без увеличения рабочего множества. Поскольку замещаемые страницы рабочего множества в действительности еще некоторое время могут оставаться в физической памяти, то они при необходимости могут быть возвращены в рабочее множество достаточно быстро, не требуя дисковых операций.
Когда свободной физической памяти становится слишком мало, система будет стремиться увеличить ее количество, урезая рабочие множества, размеры которых превышают минимальные.
В установившемся состоянии система следит за количеством исключительных ситуаций не присутствия страницы, вызываемых процессом. Если процесс генерирует page fault, и память не слишком заполнена, то система увеличит размер его рабочего множества. Если же процесс не вызывает исключительных ситуаций в течение некоторого времени, то система будет урезать его рабочее множество. При использовании таких алгоритмов система будет пытаться обеспечить наилучшую производительность для каждого процесса, не требуя никакой дополнительной настройки системы пользователем.
Итак, идея алгоритма подкачки Деннинга (иногда называемого алгоритмом рабочих наборов) состоит в том, что операционная система в каждый момент времени должна обеспечивать наличие в основной памяти текущих рабочих наборов всех процессов, которым разрешена конкуренция за доступ к процессору. Полная реализация алгоритма Деннинга практически гарантирует отсутствие thrashing. Алгоритм реализуем (известна, по меньшей мере, одна его полная реализация, которая, однако, потребовала специальной аппаратной поддержки). На практике применяются облегченные варианты алгоритмов подкачки, основанных на идее рабочего набора.
http://cs.mipt.ru/docs/courses/osstud/10/ch10.htm
№26 Стратегии решения задачи замещения страниц при управлении виртуальной памятью.
1. Принцип оптимальности.
Надо выталкивать ту страницу, к которой дольше всего не будет обращений. Как это можно определить? Никак!
Стратегия не реализуется.
2. Выталкивание случайной страницы.
Достоинство: быстрое решение с маленькими накладными расходами. Недостатки: может возрасти частота прерываний (выталкиваем нужную страницу). Используется крайне редко.
3.Принцип FIFO. (первая партия на приход — первая в расход first in, first out) Красивое решение, обоснования нет.
Достоинство: достаточно быстрое решение. Недостатки: возможна т.н. аномалия FIFO. Используется достаточно часто.
4.Выталкивание дольше всего не использовавшейся страницы.
LRU (Least Recently Used)
Достоинство: временной анализ.
Недостатки: - накладные расходы на поддержку временных меток
-смотрит назад, а не вперед. Используется достаточно редко.
5. Выталкивание реже всего использовавшейся страницы.
LFU (Least Frequently Used)
Будем считать число обращений к странице на заданном интервале. Достоинство: временной анализ.
Недостатки: - накладные расходы на поддержку временных меток;
-можно вытолкнуть «свежую» страницу;
-трудно вытолкнуть «заслуженного ветерана», страницу которая сразу набрала много обращений Используется достаточно редко.
6. Выталкивание не использовавшейся в последнее время страницы.
NUR (Not Used Recently)
Будем периодически обновлять счетчик обращений. Достоинство: устраняем недостаток LFU. Недостатки:- можно вытолкнуть «свежую» страницу;
-Используется достаточно редко.
№27 Управление процессами, переключение контекста, приоритеты.
Планирование загрузки процессоров – это распределение процессоров (или процессорного времени) между процессами.
Дисциплины планирования делятся на:
-ДИСЦИПЛИНЫ БЕЗ ПЕРЕКЛЮЧЕНИЯ. После выделения процессу ЦП его нельзя отобрать до завершения.
-ДИСЦИПЛИНЫ С ПЕРЕКЛЮЧЕНИЕМ. У процесса можно отобрать ЦП используя таймер или с приходом другого процесса.
Приоритеты бывают:
-СТАТИЧЕСКИЕ – не меняются при работе процесса, жесткий алгоритм управления, низкая эффективность.
-ДИНАМИЧЕСКИЕ – могут учитывать показания системных «сенсоров» , гибкое управление, высокие издержки на обслуживание.
-ПОКУПНЫЕ – изменяется (повышается) по инициативе пользователя. Экзотика.
Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе пользовательски контекст, регистровый контекст и системный контекст. Ядро разрешает производить переключение контекста в четырех случаях: когда процесс приостанавливает свое выполнение, когда он завершается, когда он возвращается после вызова системной функции в режим задачи, но не является наиболее подходящим для запуска, или когда он возвращается в режим задачи после завершения ядром обработки прерывания, но так же не является наиболее подходящим для запуска.
Механизм переключения контекста:
1.Принять решение относительно необходимости переключения контекста и его допустимости в данный момент.
2.Сохранить контекст "прежнего" процесса.
3.Выбрать процесс, наиболее подходящий для исполнения, используя алгоритм диспетчеризации процессов.
4.Восстановить его контекст.

№28 Управление процессами. Основные стратегии.
-Планирование по сроку завершения. Все процессы должны закончиться к указанному сроку. Трудности: надо точно указать какие ресурсы нужны процессу (как узнать?), нельзя дискриминировать отдельные процессы, как учесть приход различных запросов во время выполнения процесса(как?), если процессов с «жесткими» сроками завершения несколько(как выбрать?), стратегия требует активного управления, а это дорого.
На практике редко используется, только для «закрытых» систем.
-Планирование по принципу FIFO(First Input First Output). Из очереди выбирается тот процесс, который раньше пришел в систему. БЕЗ ПЕРЕКЛЮЧЕНИЯ.
Особенности: простота реализации ( + ), длинные процессы блокируют ЦП( - ), нельзя использовать в интерактивных системах( - ).
Пусть задан поток запросов |
Порядок выполнения запросов |
- Планирование по принципу SJF(Shortest Job First). Из очереди выбирается процесс с наименьшим временем выполнения. БЕЗ ПЕРЕКЛЮЧЕНИЯ.
Особенности: сижает длину очереди( + ), сложно оценить время выполнения ( - ). Пусть задан поток запросов Порядок выполнения запросов
- Планирование по принципу SRTF(Shortest Remaining Time First ). Из очереди выбирается процесс с наименьшим временем завершения. С ПЕРЕКЛЮЧЕНИЕМ.
Особенности: минимальное время ожидания( + ), сложно оценить время выполнения( - ). Пусть задан поток запросов Порядок выполнения запросов
- Циклическое планирование (RR)(Round Robin). Каждый квант времени из очереди выбирается очередной процесс. Работавший процесс становится последним в очереди (цикл). С ПЕРЕКЛЮЧЕНИЕМ.
Особенности: для интерактивных систем( + ), любит ОЗУ( - ), размер кванта( - ). Пусть задан поток запросов Порядок выполнения запросов
- Планирование по принципу HRN(Highest Response ratio Next). Каждый квант времени из очереди выбирается процесс c наибольшим приоритетом. С ПЕРЕКЛЮЧЕНИЕМ.
Особенности: приоритет процесса – динамический. ПРИОРИТЕТ=(время ожидания +время обслуживания)/(время обслуживания) . Справедливая стратегия( + ), не определить размер кванта( - ).

- Многоуровневые очереди с обратными связями. Отношение системы к процессу зависит от его поведения. Адаптивная стратегия. Требует значительных ресурсов системы. Самая «правильная». С ПЕРЕКЛЮЧЕНИЕМ.
№29 Управление процессами. Цели и критерии.
Цели:
1.Быть справедливой ко всем процессам.
2.Повышать производительность системы (число процессов/время)
3.Уменьшать время реакции системы для пользователей
4.Быть предсказуемой (время решения задания не должно зависеть от нагрузки)
5.Минимизировать потери ресурсов
6.Загружать простаивающие ресурсы
7.Исключать бесконечное откладывание
8.Учитывать приоритеты
9.Выделять процессы, занимающие ключевые ресурсы (не прерывать)
10.Создавать хорошие условия для «правильных» процессов
11.Балансировать между min(время реакции) – max(загрузка ресурсов)
12.Иметь плавную зависимость параметров от нагрузки
Критерии:
1.Лимитируется ли процесс I/O операциями
2.Освобождает ли процесс ЦП до окончания кванта времени
3.Режим работы процесса – пакетный или интерактивный
4.Необходимость «немедленной» реакции на события (real time)
5.Приоритет процесса
6.Частоту прерываний из-за отсутствия страниц в памяти (раб. множество)
7.Частоту прерываний из-за низкого приоритета
8.Выделенное время
9.Время ожидания в очереди
10.Время, необходимое для завершения процесса

№30. Организация файлов. Функции файловой системы. Распределение внешней памяти.
Файл – поименованная совокупность данных.
Файловая система – часть ОС, отвечающая за работу с файлами.
Функции:
1.Создание, удаление, модификация файлов
2.Разделение файлов друг от друга, поддержание целостности
3.Совместная работа нескольких процессов с файлами
4.Изменение структуры файла
5.Восстановление после стирания
6.Обеспечение разных методов доступа и режима секретности
7.Обращение к файлу по символическому имени
8.Дружественный интерфейс.
Физическая запись или блок – единица информации, которую можно считать с носителя или записать на него.
Организация файлов:
-Последовательная – записи в файле располагаются в физическом порядке. Магнитные ленты, перфоленты, перфокарты. Возможно и на дисках.
-Индексно-последовательная – записи в файле располагаются в логическом порядке в соответствии со значением ключей, содержащихся в каждой записи. Имеется специальный файл – индексный, где расположены адреса записей, упорядоченные по значению ключа. Диски.
-Прямая – доступ к записям осуществляется прямо по их адресам. ЗУ прямого доступа.
-Библиотечная – файл представляется суммой последовательных подфайлов.
Распределение памяти:
Связное – каждому файлу выделяется непрерывная область памяти. Достоинства: высокая скорость доступа, простая директория.
Недостатки: файл можно записать на диск только при наличии подходящей по размеру непрерывной области. Необходимо использовать трудоемкую операцию «сжатие» (sque, а не defrag).
Несвязное – носитель разбивается на области (сектора). Файл представляется. Последовательностью секторов, может быть и не связанных.
Достоинства: не требует операции сжатия.
Недостатки: сложная директория, необходимость в операции defrag.
* Указатели на предыдущий и последующий секторы
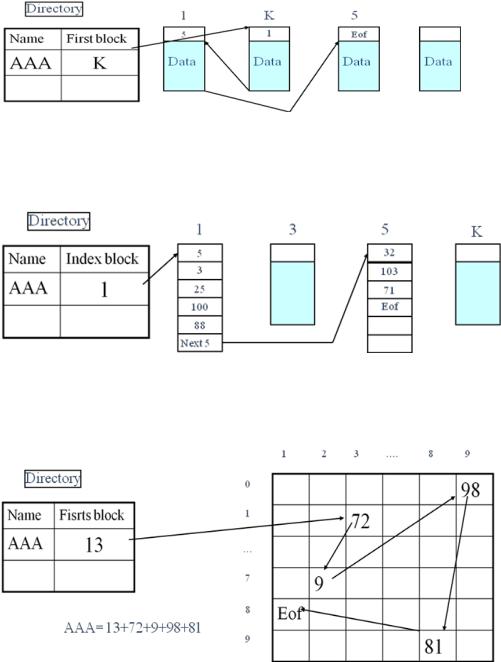
№31.Файловая система. Методы поблочного отображения.
Диск разбивается на блоки. Блок объединяет несколько последовательных секторов. Файл состоит из блоков (в общем случае несмежных).
Цепочка блоков.
AAA= K+1+5
Достоинства: не требует операции сжатия. Недостатки: долго, но можно ускорить
Цепочка индексов.
AAA= 5+3+25+100+88+32+103+71
Достоинства: быстрее цепочки блоков.
Недостатки: фиксированное число файлов, сложность вставки блоков.
Таблица поблочного распределения – FAT (File Allocation Table)
Достоинства: быстрее цепочки блоков.
Недостатки: фиксированное число файлов, сложность вставки блоков.

№32. HPFS, NTFS и CDFS. Управление доступом к файлам.
HPFS
Структура раздела HPFS
Основные особенности HPFS:
-Диск разбивается на блоки по 512 байт, а адрес кодируется 4 байтами, что позволяет адресовать диски до 2 ТБ и эффективно использовать дисковое пространство.
-Информация о местонахождении файлов хранится в B-деревьях, информация о каталогах хранится в центральной полосе диска.
-Информация в каталоге хранится в B-дереве, записи в котором отсортированы по алфавиту
-Имя файла не должно превышать 255 символов, а общая длина пути 260.
-Максимальный размер файла – до 7,68 Гбайт, но практически не более 2 Гбайт.
Позднее на основе HPFS была создана JFS – журналируемая файловая система, использующая транзакции. В настоящее время JFS - одна из самых быстрых файловых систем.
NTFS
Структура раздела NTFS
Отличия NTFS от FAT
-служебная информация хранится в файлах, а жестко определенным является положение только первых 16 записей MFT и их копии.
-наличие журнала операций над файлами, позволяющее эффективно устранять ошибки
-возможность создания нескольких потоков данных для файла
-NTFS 5.0 и 5.1 динамически изменяет ярлык при перемещении или переименовании файла
-управление избирательным доступом, позволяющее управлять правами доступа
-возможность аудита действий пользователя и квотирования пространства диска
-создание жестких связей и точек перехода
-шифрование и сжатие средствами на уровне файловой системы
CDFS
Структура диска с несколькими сессиями
Существующие файловые системы для CD:
-ISO 9660 – стандартная файловая система для записи данных на CD.
•El Torito – расширение для возможности загрузки с диска.
•Joilet – расширение, разрешающее длинные имена файлов (до 128 символов), символы unicode в названия файлов и директорий, вложенность директорий больше 8.
-UDF (Universal Disk Format или ISO 13346 ) – файловая система, поддерживающая длинные имена файлов (до 255) и файлы большого размера (более 2 Гбайт), длину пути до 1024 символов
-HFS – файловая система используемая в MacOS