

LR3_CSP
.docxМИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования
Московский технический университет связи и информатики
Кафедра многоканальных телекоммуникационных систем
Лабораторная работа № 3
по дисциплине
Цифровые системы передачи и методы их защиты
РЕАЛИЗАЦИЯ ПРИНЦИПОВ КРИПТОЗАЩИТЫ НА ОСНОВЕ СРЕДСТВ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Бригада №
Выполнил: студент гр. бкк2001
Проверила: Зуйкова Т.Н.
Москва 20
1 Цель работы
Лабораторная работа выполняется в среде автоматизированного проектирования программного обеспечения VisualDSP++. В ходе выполнения лабораторной работы изучается архитектура и система команд сигнального процессора ADSP-2181 для выполнения операций с массивами. Для реализации операций в простых полях Галуа используется подпрограмма деления целых чисел, разработанная в лабораторной работе №2.
2 Постановка задачи
1) Средствами сигнального процессора ADSP-2181 реализовать базовую операцию умножения в простых полях Галуа в соответствии с индивидуальным заданием:
![]()
2) Средствами сигнального процессора ADSP-2181 реализовать базовую криптографическую операцию XOR в соответствии с индивидуальным заданием:
![]()
3 Ход выполнения
В ходе подготовки и выполнения лабораторной работы
1. Проанализировать поставленные задачи и исходные данные. Изучить теоретический материал по учебным пособиям.
2. Продумать логическую последовательность операций для реализации задач.
3. Составить блок-схемы алгоритмов подпрограмм.
4. Написать тексты подпрограмм.
5. Отладить ход выполнения подпрограмм.
6. Оформить бланк отчета.
7. Записать лаконичные и продуманные выводы.
Учебные пособия
1. Шаврин С.С., Мельник С.В. Технологии микропроцессорных систем в инфокоммуникациях [Электронный ресурс] : учебное пособие для магистров. - М.: ЭБС МТУСИ, 2020.- 92 с. Количество книг в библиотеке МТУСИ – 5. URL: https://lms.mtuci.ru/lms/local/mtt/elib_download.php?book_id=2374 (обложка КРАСНОГО цвета)
2. Архитектура и система команд цифровых сигнальных процессоров семейства ADSP-21XX [Электронный ресурс] / А.А. Дурнаков, Н.А. Дядьков. - УрФУ. URL: https://study.urfu.ru/Aid/Publication/11082/1/Dyrnakov_Dyadkov.pdf
4 Исходные данные
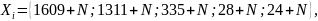
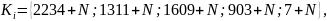
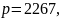
где
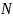 – последняя цифра номера студенческого
билета.
– последняя цифра номера студенческого
билета.
5 Краткая теория
Массивы и адресация ячеек в массивах
Система команд сигнального процессора ADSP-2181 для выполнения операций с массивами, использует прямую и косвенную адресацию (смотрите с. 40-46 учебного пособия [1].
Организация циклов
Смотрите с. 48-49 учебного пособия [1].
6 Порядок выполнения
Анализ исходных данных и выбор режима для АЛУ и умножителя
ena ar_sat или dis ar_sat
ena m_mode или dis m_mode
(ss) или (uu)
Предварительный расчет
Представление данных в 10-чной, 2-чной и 16-чной системе счисления.
Исходные данные |
Результат в десятичной |
Результат в шестнадцатеричной |
|||||||||||
N |
p |
x |
k |
X |
K |
K*X |
K*X/p |
K*X mod p |
K*X |
K*X/p |
K*X mod p |
||
1 |
2267 |
1609 |
2234 |
1610 |
2235 |
3598350 |
1587,27393 |
1974 |
376076 |
640 |
7B6 |
||
1 |
2267 |
1311 |
1311 |
1312 |
1312 |
1721344 |
759,304808 |
1344 |
1A9640 |
300 |
540 |
||
1 |
2267 |
335 |
1609 |
346 |
1610 |
557060 |
245,725628 |
1177 |
87E30 |
F5 |
499 |
||
1 |
2267 |
28 |
903 |
29 |
904 |
26216 |
11,5641817 |
2006 |
83D0 |
E |
7D6 |
||
1 |
2267 |
24 |
7 |
25 |
8 |
200 |
0,08822232 |
528 |
210 |
0 |
210 |
||
Разработка блок-схем подпрограмм.
Блок-схемы алгоритмов должны быть представлены в графическом виде в соответствии с действующими стандартами.
Разработка кода основной программы.
Шаг 1. Создать проект LAB3
Шаг 2. Объявить в памяти данных (dm) линейные массивы:
X[5], K[5], Z[5] , Y[5]
Инициализировать начальные значения X и K.
Объявить и инициализировать в dm переменные p и N.
Шаг 3.
Инициализировать для массивов указатели и модификатор генератора адреса данных:
X[5] с указателем I0;
K[5] с указателем I1;
Z[5] с указателем I2
Y[5] с указателем I3 и с общим модификатором m1=1.
Шаг 4. Выбрать режимы работы процессора.
Шаг 5. В векторе прерываний по RESET организовать переход к основной программе на метку START.
Шаг 6. Разместить подпрограмму деления в простых полях Галуа с возвратом в основную программу.
Шаг 7. В отдельной подпрограмме организовать цикл для умножения чисел из массивов X и K с последующим вызовом подпрограммы деления.
Шаг 8. В отдельной подпрограмме организовать цикл для выполнения операции сложения по модулю 2 чисел из массивов X и K с записью результата в массив Y.
Шаг 9. В отдельной подпрограмме организовать цикл для выполнения операции сложения по модулю 2 чисел из массивов Y и K с записью результата в массив M.
Шаг 10. Поставить метку START и записать основную программу с вызовом разработанных подпрограмм.
Шаг 11. Организовать конец основной программы.
7 Разработанные блок-схемы для трех подпрограмм и основной программы
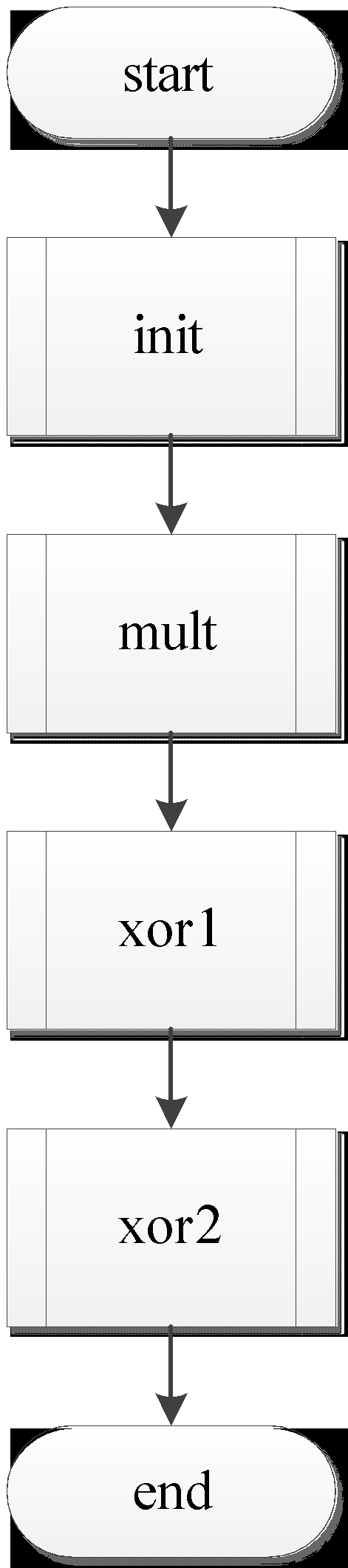
Рис 1 – блок-схема основной программы

Рис 2 – блок-схема подпрограммы init
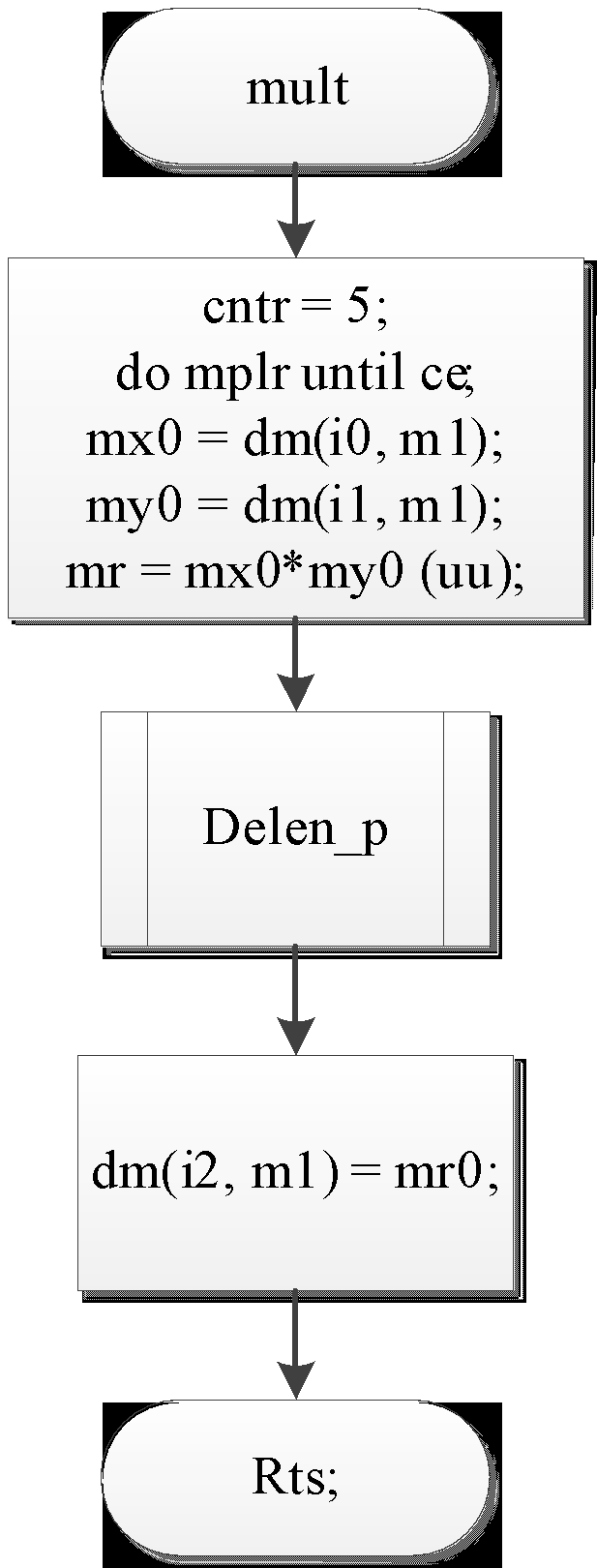
Рис 3 – блок-схема подпрограммы mult
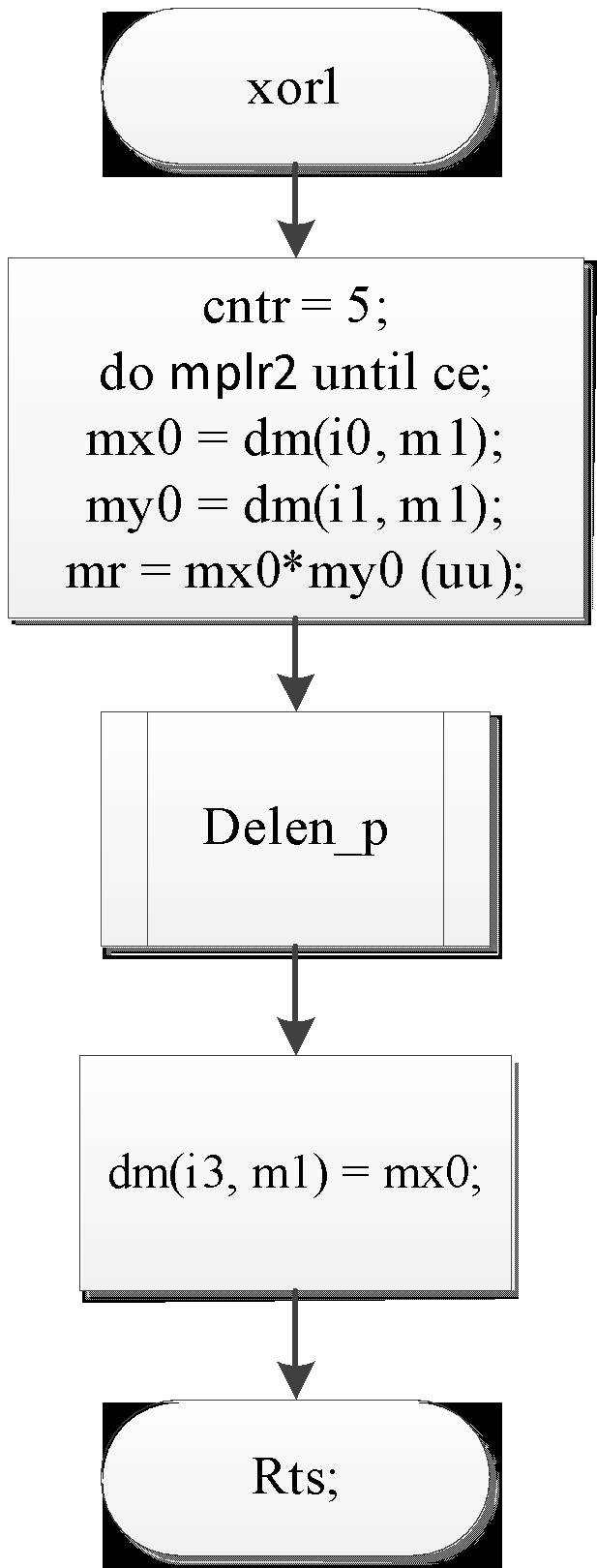
Рис 4 – блок-схема подпрограммы xor1
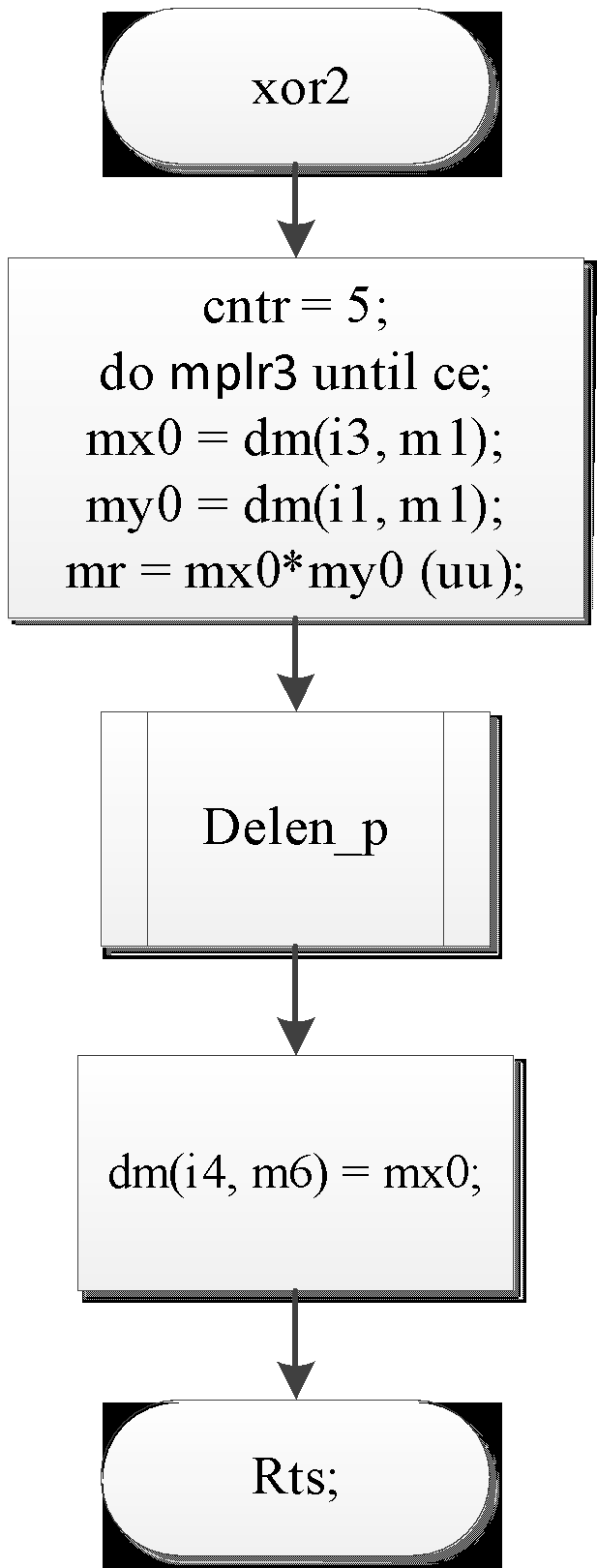
Рис 5 – блок-схема подпрограммы xor2
8 Разработанные тексты кода для трех подпрограмм и основной программы.
SECTION/DM vars;
.var p = 2267;
.var N = 1;
.var/circ Xi_[5] = 1611, 1313, 337, 30, 26
.var/circ Ki_[5] = 2236, 1313, 1611, 905, 9
.VAR Zi_ [5];
.VAR Yi_ [5];
.VAR Mi_ [5];
.SECTION/PM program;
jump start; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
rti; rti; rti; rti;
init:
I0=Xi_; L0=length(Xi_);
I1=Ki_; L1=length(Ki_);
I2=Zi_; L2=length(Zi_);
I3=Yi_; L3=length(Yi_);
I4=Mi_; L4=length(Mi_);
m1=1;
rts;
mult:
cntr = 5;
do mplr until ce;
mx0 = dm(i0, m1);
my0 = dm(i1, m1);
mr = mx0*my0 (uu);
call delen_p;
dm(i2, m1) = mr0;
mplr: nop;
rts;
xor1:
cntr = 5;
do mplr2 until ce;
mx0 = dm(i0, m1);
my0 = dm(i1, m1);
mr = mx0*my0 (uu);
call delen_p;
dm(i3, m1) = mx0;
mplr2: nop;
rts;
xor2:
cntr = 5;
do mplr3 until ce;
mx0 = dm(i3, m1);
my0 = dm(i1, m1);
mr = mx0*my0 (uu);
call delen_p;
dm(i4, m6) = mx0;
mplr3: nop;
rts;
delen_p:
nop;
af = pass mr1;
ay0 = mr0;
ax0 = dm(p);
ar = ax0;
astat = 0;
if eq jump qq;
if gt jump delen_g;
if lt jump delen_l;
qq:
astat = 4;
rts;
delen_g:
astat = 0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
divq ax0;
mr2 = 0;
my0 = ax0, ar = pass ay0;
mr = mr - ar * my0 (uu);
rts;
delen_l:
sr1 = ax0;
sr = lshift sr1 by -1(hi);
astat = 0;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
divq sr1;
mr2 = 0;
my0 = ax0, ar = pass ay0;
af = tstbit 0xf of sr0;
if ne ar = ar - 1;
ay0 = ar;
mr = mr - ar * my0 (uu);
rts;
start: nop;
dis ar_sat;
ena m_mode;
call init;
call mult;
call xor1;
call xor2;
end: nop;
jump end;
9 Результаты отладки подпрограмм
Xi_= 1611, 1313, 337, 30, 26
Ki_= 2236, 1313, 1611, 905, 9
Zi_=0x376076,0x1A9640,0x87E30,0x83D0,0x210;
Yi_=0x640, 0x300, 0xF5, 0xE, 0x0;
Mi_=0x7B6, 0x540, 0x499, 0x7D6, 0x210.
10 Анализ полученных результатов
В ходе выполнения лабораторной работы мы изучили архитектуру и систему команд сигнального процессора ADSP-2181 для выполнения операций с массивами. Для реализации операций в простых полях Галуа используется подпрограмма деления целых чисел, разработанная в предыдущей лабораторной работе.
В ходе отладки программы были получены определенные результаты. Для того, чтобы убедиться в том, что программа работает корректно, необходимо сравнить расчетные данные и данные, полученные экспериментально. При сравнении таблицы с расчетными данными и данных полученных в результате работы программы видно, что они совпадают. В ходе проверки, мы подтвердили правильность работы программы, делаем вывод что программа работает корректно.
11 Выводы