

Информационные технологии шиян / Отчет Лаба 3 (1)
.docxМИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ,
СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«САНКТ–ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ. М.А. БОНЧ–БРУЕВИЧА»
(СПбГУТ)
Факультет: Инфокоммуникационных сетей и систем
Кафедра: Защищенных систем связи
Дисциплина: Информационные технологии
ОТЧЕТ
Направление/специальность подготовки
10.03.01 Информационная безопасность
(код и наименование направления/специальности)
Студенты:
Козурман А., Лимонов М., Немчинов А., ИКБ-23
Преподаватель:
Доцент кафедры ЗСС
Шиян А.А.
(Ф.И.О. преподавателя) (подпись)
Санкт–Петербург
2023
Первая модель
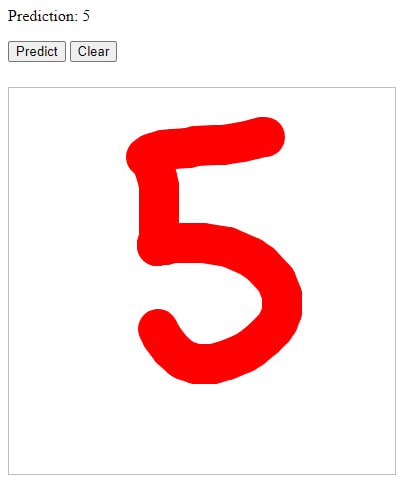
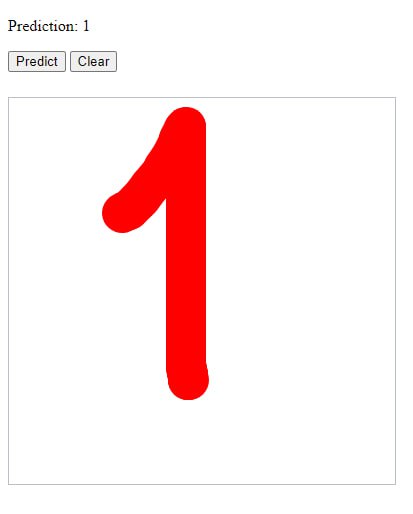
Первая модель (1 час обучения).
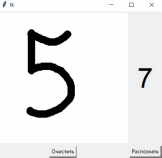
Всё распознано верно кроме “7” - 2 ошибки из 4 проверок:


















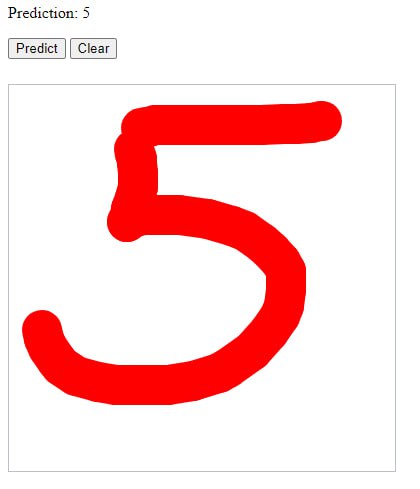
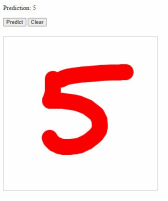
Первая модель (2,5 часа обучения).
Всё распознано верно кроме “7” - 2 ошибки из 4 проверок:

















Первая
модель (4 часа обучения). Всё
распознано верно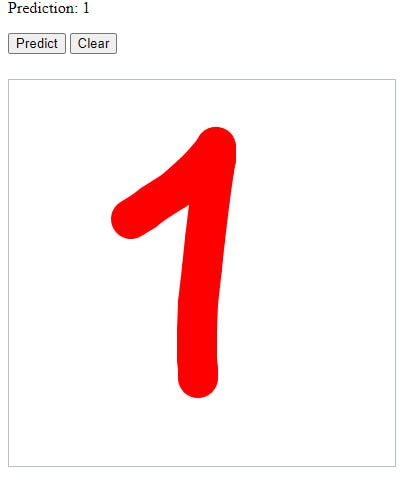





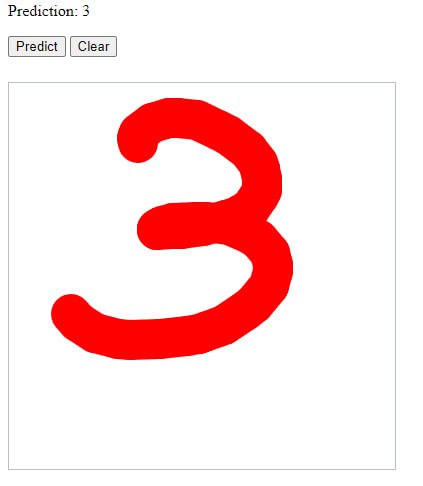














Рисунок 1. Гистограмма распознания первой моделью
Вторая модель
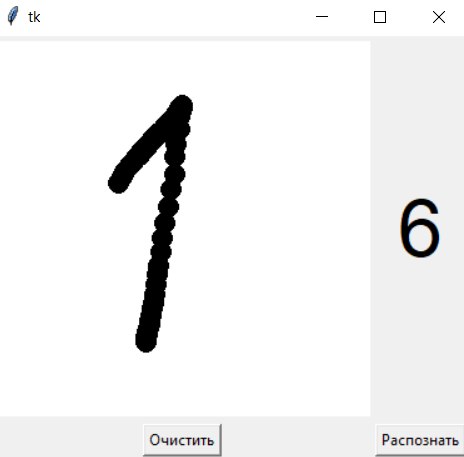
Вторая модель (40 минут обучения):
 1
1

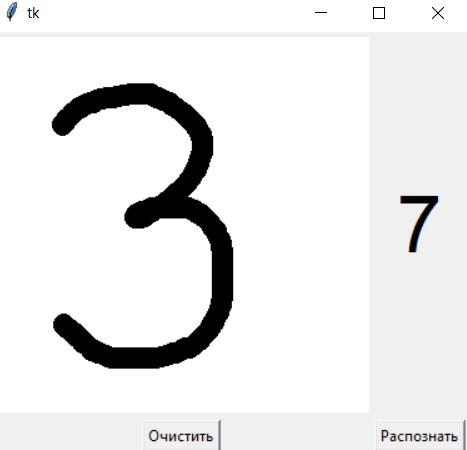
 - 2 раза распозналась как 7, по 1 разу - как
3 и 6; 5 - 1 раз распозналась как 7; 7 - 1 раз
распозналась правильно; во всех остальных
случаях цифры распознавались как 6.
- 2 раза распозналась как 7, по 1 разу - как
3 и 6; 5 - 1 раз распозналась как 7; 7 - 1 раз
распозналась правильно; во всех остальных
случаях цифры распознавались как 6.





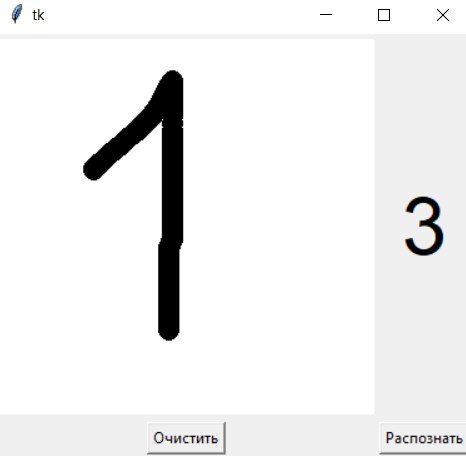









Вторая модель (1,5 часа обучения):
3
- 1 раз распозналась правильно; 5 - 1 раз
распозналась как 3; во всех остальных
случаях цифры распознавались как 7.


















Вторая модель (4,5 часа обучения):
Распознана верно цифра 7 – 2 раза, в остальных случает цифры распознаны неверно.













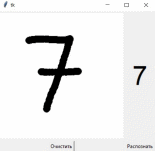
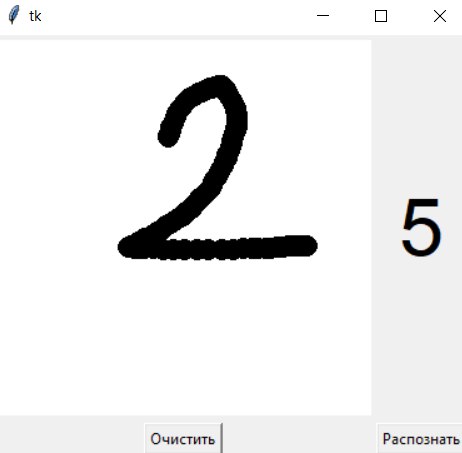






Рисунок 2. Гистограмма распознания второй моделью
Вывод:
При разработке данного проекта было установлено на практике, что реализация программы возможна как с использованием сверточной, так и полносвязной нейронной сети. Несмотря на то, что сверточная сеть проявляет более высокую эффективность в обработке изображений, полносвязная сеть также является выполнимым вариантом, но очень неоптимальная для этой задачи, так как статистика показывает правильность выполнения лишь 6%.
Защита лабораторной работы
Первая модель
Изменения:
def improvedConvBlock(filters, kernel_size=3, pool_size=2, name=None):
return [
tf.keras.layers.Conv2D(filters, kernel_size, padding='same', activation='relu', name=name+'_conv'),
tf.keras.layers.BatchNormalization(name=name+'_bn'),
tf.keras.layers.Conv2D(filters, kernel_size, padding='same', activation='relu', name=name+'_conv2'),
tf.keras.layers.BatchNormalization(name=name+'_bn2'),
tf.keras.layers.MaxPooling2D(pool_size, name=name+'_mpool'),
tf.keras.layers.Dropout(0.25, name=name+'_drop')
]
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu', input_shape=(28, 28, 1), name='input_conv'))
model.add(tf.keras.layers.BatchNormalization(name='input_bn'))
model.add(tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu', name='input_conv2'))
model.add(tf.keras.layers.BatchNormalization(name='input_bn2'))
model.add(tf.keras.layers.MaxPooling2D(2, name='input_mpool'))
model.add(tf.keras.layers.Dropout(0.25, name='input_drop'))
model.add(improvedConvBlock(64, name='b1'))
model.add(improvedConvBlock(128, name='b2'))
model.add(improvedConvBlock(256, name='b3'))
model.add(tf.keras.layers.Flatten(name='flat'))
model.add(tf.keras.layers.Dense(512, activation='relu', name='dense'))
model.add(tf.keras.layers.BatchNormalization(name='dense_bn'))
model.add(tf.keras.layers.Dropout(0.5, name='dense_drop'))
model.add(tf.keras.layers.Dense(10, activation='softmax', name='logit'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Проведённые
тесты:




Статистика после обновления модели:

Вторая модель
Изменения:
model = Sequential([
Conv2D(32, (3, 3), activation=LeakyReLU(alpha=0.1), padding='same', input_shape=(32, 32, 3)),
BatchNormalization(),
Conv2D(64, (3, 3), activation=LeakyReLU(alpha=0.1), padding='same'),
BatchNormalization(),
MaxPooling2D((2, 2)),
Dropout(0.25),
Conv2D(128, (3, 3), activation=LeakyReLU(alpha=0.1), padding='same'),
BatchNormalization(),
Conv2D(256, (3, 3), activation=LeakyReLU(alpha=0.1), padding='same'),
BatchNormalization(),
MaxPooling2D((2, 2)),
Dropout(0.25),
Flatten(),
Dense(512, activation=LeakyReLU(alpha=0.1)),
BatchNormalization(),
Dropout(0.5),
Dense(10, activation='softmax')
])
model.compile(optimizer=”adam”,
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train,y_train_cat, batch_size=64, epochs=100, validation_split=0.5)
 П
П
 роведённые
тесты:
роведённые
тесты:


Статистика после обновления:

Вывод:
После обновлений кода каждой модели, проведения нескольких тестов и подведения статистики вывод, сказанный ранее, подтвердился. Первая модель показала почти 100-процентную статистику распознавания цифр. Статистика же второй модели не смогла сдвинуться с 6%. Кроме этого, было установлено, что время обучения данной модели увеличивается в несколько раз. Этот фактор является одним из главных аргументов против полносвязной нейросети и в сторону выбора свёрточной нейросети.