

pandas 71
датафрейма. Ранее, при создании серии emps_names, мы не указали имя явно, поэтому присвоим значение names свойству name . Затем объединим emps_names с серией emps_emails . Укажем axis=1, чтобы выполнить конкатенацию по столбцам.
В результате должен получиться следующий датафрейм:
|
|
names |
emails |
9001 |
Jeff |
Russell |
jeff.russell |
9002 |
Jane |
Boorman |
jane.boorman |
9003 |
Tom Heints |
tom.heints |
|
|
|
|
|
УПРАЖНЕНИЕ № 3: ОБЪЕДИНЕНИЕ ТРЕХ СЕРИЙ
В предыдущем разделе мы создали датафрейм путем объединения двух серий. Используя этот же подход, попробуйте создать датафрейм из трех серий. Для этого вам потребуется создать еще один объект Series (скажем, emps_phones).
pandas DataFrame
Объект pandas DataFrame — это двумерная маркированная структура данных, столбцы которой могут содержать значения разных типов. DataFrame можно рассматривать как контейнер для объектов Series. Он похож на словарь, где ключ — метка столбца, а значение — серия.
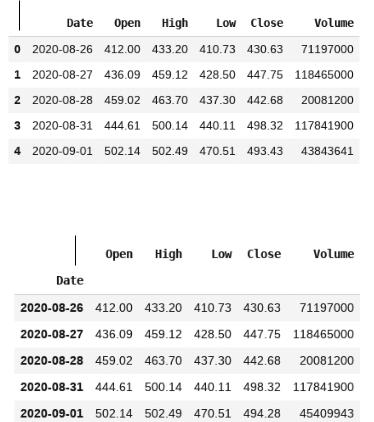
Если вы знакомы с реляционными базами данных, то заметите, что pandas DataFrame похож на обычную таблицу SQL. На рис. 3.2 показан пример pandas DataFrame.
Обратите внимание, что в датафрейме есть столбец с индексами. Для структуры данных DataFrame по умолчанию использует целочисленную индексацию с нуля так же, как для Series. Однако индекс, установленный по умолчанию, можно заменить одним или несколькими существующими столбцами. На рис. 3.3 изображен тот же DataFrame, но в качестве индекса выбран столбец Date.
В данном конкретном примере индекс представляет собой столбец типа date. На самом деле в pandas можно устанавливать для датафрейма индексы любого типа. Чаще всего используют целые числа и строки. Однако вы не ограничены использованием простых типов данных. Можно выбрать в качестве индекса
72 Глава 3. Библиотеки Python для data science
последовательность, например список или кортеж, или даже использовать объектный тип, который не встроен в Python, то есть любой сторонний тип, даже собственный.
С а
Рис. 3.2. Пример pandas DataFrame
С а
Рис. 3.3. pandas DataFrame со столбцом в качестве индекса
Создание pandas DataFrame
Мы разобрали, как создать pandas DataFrame путем объединения нескольких объектов Series. Также создать DataFrame можно, загрузив данные из базы данных, файла CSV, запроса API или из другого внешнего источника с помощью одного из методов для чтения из библиотеки pandas. Эти методы позволяют читать различные типы данных, такие как JSON и Excel, и преобразовывать их в датафрейм.

pandas 73
Рассмотрим датафрейм на рис. 3.2. Вероятно, он создан в результате запроса к Yahoo Finance API через библиотеку yfinance. Чтобы создать этот датафрейм самостоятельно, установите yfinance с помощью команды pip следующим образом:
$ pip install yfinance
Затем запросите данные биржевого рынка, как показано ниже:
import yfinance as yf
tkr = yf.Ticker('TSLA')
hist = tkr.history(period= "5d")
hist = hist.drop("Dividends", axis = 1) hist = hist.drop("Stock Splits", axis = 1)
hist = hist.reset_index()
В данном скрипте мы отправляем API запрос на данные о цене акций для заданного тикера и используем метод yfinance history(), чтобы указать, что нам нужны данные за пятидневный период . Полученные данные, хранящиеся в переменной hist, уже имеют вид pandas DataFrame. То есть yfinance создает датафрейм самостоятельно. После получения датафрейма нужно удалить некоторые столбцы и переиндексировать датафрейм . В итоге должна получиться структура как на рис. 3.2.
Чтобы в качестве индекса установить столбец Date, как было показано на рис. 3.3, нужно выполнить следующую строку кода:
hist = hist.set_index('Date')
ПРИМЕЧАНИЕ
yfinanceавтоматическипроиндексируетдатафреймпостолбцуDate.Впримерах вышемыперешликчисловойиндексации,азатемобратнокиндексацииподате, чтобы проиллюстрировать методы reset_index() и set_index().
Теперь попробуем преобразовать документ JSON в объект pandas. Используемый в примере датасет содержит данные о месячной заработной плате трех сотрудников. Каждому сотруднику присвоен уникальный идентификатор (ID) в столбце Empno:
import |
json |
import |
pandas as pd |
data = |
[ |

74 Глава 3. Библиотеки Python для data science
{"Empno":9001, "Salary":3000}, {"Empno":9002, "Salary":2800}, {"Empno":9003, "Salary":2500}
]
json_data = json.dumps(data)
salary = pd.read_json(json_data)
salary = salary.set_index('Empno') print(salary)
Используем метод pandas read_json()для чтения и превращения JSON-строки в DataFrame . Для простоты в данном примере используется строка JSON, преобразованная из списка с помощью json.dumps() . Как вариант, можно передать в метод чтения объект path (путь до нужного JSON-файла) или URL-адрес HTTP API, который публикует данные в формате JSON. Наконец, выбираем столбец Empno в качестве индекса датафрейма и тем самым заменяем числовой индекс, установленный по умолчанию.
В результате получим следующий датафрейм:
|
Salary |
Empno |
|
9001 |
3000 |
9002 |
2800 |
9003 |
2500 |
|
|
Еще одна распространенная практика — создание pandas DataFrame из стандартных структур данных Python, представленных в предыдущей главе. Например, можно создать датафрейм из списка списков:
import pandas as pd
data = [['9001','Jeff Russell', 'sales'], ['9002','Jane Boorman', 'sales'], ['9003','Tom Heints', 'sales']]
emps = pd.DataFrame(data, columns = ['Empno', 'Name', 'Job'])column_types = {'Empno': int, 'Name': str, 'Job': str}
emps = emps.astype(column_types)
emps = emps.set_index('Empno') print(emps)
Сначала мы инициализируем список списков из данных, которые хотим отправить в датафрейм . В нем каждый вложенный список станет строкой. Затем мы явно создаем датафрейм, определяя названия столбцов . Далее используем словарь column_types, чтобы изменить типы данных, установленные для столбцов по умолчанию . Этот шаг необязателен, но он может иметь решающее значение при объединении одного датафрейма с другим, поскольку сделать это

pandas 75
можно только со столбцами, содержащими данные одного типа. Наконец, мы устанавливаем столбец Empno в качестве индекса датафрейма . Полученный датафрейм будет выглядеть так:
|
|
Name |
Job |
Empno |
|
|
|
9001 |
Jeff |
Russell |
sales |
9002 |
Jane |
Boorman |
sales |
9003 |
Tom Heints |
sales |
|
|
|
|
|
Обратите внимание, что в обоих датафреймах — emps и salary — столбец Empno используется в качестве индекса, то есть для уникальной идентификации каждой строки. Это необходимо, чтобы упростить процесс объединения двух этих датафреймов в один. Разберем данную операцию в следующем разделе.
Объединение датафреймов
pandas позволяет объединять датафреймы подобно тому, как мы объединяем различные таблицы в реляционной базе данных. Это позволяет собирать данные для анализа вместе. Методы объединения, поддерживаемые структурой данных DataFrame, напоминают операции при работе с базами данных: merge()и join(). Эти методы содержат несколько разных параметров, но так или иначе могут выступать как взаимозаменяемые.
Для начала объединим датафреймы emps и salary, объявленные в предыдущем разделе. Такой тип объединения называется один-к-одному (one-to-one join), где каждая строка одного датафрейма связана с соответствующей строкой другого датафрейма. На рис. 3.4 показано, как это работает.
emps_salary
9001 |
Jeff Russell |
sales |
3000 |
|
|
|
|
emps
9001 |
Jeff Russell |
sales |
|
|
|
salary
9001 3000
Рис. 3.4. Объединение двух датафреймов методом one-to-one

76 Глава 3. Библиотеки Python для data science
Здесь мы видим запись из датафрейма emps и запись из датафрейма salary. Обе записи имеют значение индекса 9001, поэтому их можно объединить в одну запись в новом датафрейме — emps_salary. В терминологии реляционных баз данных столбцы, с помощью которых таблицы связаны между собой, называются ключевыми. Хотя в pandas существует термин index для таких столбцов, на рис. 3.4 используется значок ключа для визуального отображения объединения.
С помощью метода join() проводить объединение довольно просто:
emps_salary = emps.join(salary) print(emps_salary)
Он предназначен для простого объединения датафреймов на основании их индексов. В этом конкретном примере нам даже не нужно было предоставлять дополнительные параметры; объединение по индексу — поведение по умолчанию. В результате получаем следующий датасет:
|
|
Name |
Job |
Salary |
Empno |
|
|
|
|
9001 |
Jeff |
Russell |
sales |
3000 |
9002 |
Jane |
Boorman |
sales |
2800 |
9003 |
Tom Heints |
sales |
2500 |
|
|
|
|
|
|
На практике бывает необходимо объединить два датафрейма, в одном из которых есть строки, не имеющие совпадений в другом датафрейме. Предположим, у нас есть еще одна строка в датафрейме emps, а в salary соответствующей строки нет:
new_emp = pd.Series({'Name': 'John Hardy', 'Job': 'sales'}, name = 9004) emps = emps.append(new_emp)
print(emps)
В этом случае создадим объект pandas Series, а затем добавим его к датафрейму emps с помощью метода append(). Это популярный способ добавления новых строк.
Обновленный датафрейм emps будет выглядеть следующим образом:
|
Name |
Job |
Empno |
|
|
9001 |
Jeff Russell |
sales |
9002 |
Jane Boorman |
sales |
9003 |
Tom Heints |
sales |
9004 |
John Hardy |
sales |
|
|
|

pandas 77
Если мы снова применим операцию join:
emps_salary = emps.join(salary) print(emps_salary)
то получим такой датафрейм:
|
Name |
Job |
Salary |
Empno |
|
|
|
9001 |
Jeff Russell |
sales |
3000.0 |
9002 |
Jane Boorman |
sales |
2800.0 |
9003 |
Tom Heints |
sales |
2500.0 |
9004 |
John Hardy |
sales |
NaN |
|
|
|
|
Обратите внимание: строка, добавленная в emps, появляется в итоговом датасете, даже если в salary нет связанной с ней строки. Запись NaN в поле Salary последней строки означает, что значение оклада отсутствует. В некоторых случаях пустые значения в строках допустимы, как в данном примере, однако в других ситуациях может понадобиться исключить строки, которые не имеют соответствий в другом датафрейме.
По умолчанию метод join() использует индексы вызывающего датафрейма в результирующем, объединенном датафрейме, выполняя таким образом left join. В примере выше вызывающим датафреймом был emps. Он считается левым датафреймом в операции объединения, и поэтому все строки из него включаются в результирующий датасет. Это поведение можно изменить, передав параметр how в метод join(). Данный параметр принимает следующие значения:
left Использует столбец с индексами вызывающего датафрейма (или другой столбец, если указан параметр on), возвращая все строки из вызывающего (левого) датафрейма и только совпадающие строки из другого (правого) датафрейма.
right Использует индекс другого (правого) датафрейма, возвращая из него все строки и только совпадающие строки из вызывающего (левого) датафрейма.
outer Создает комбинацию индексов вызывающего датафрейма (или иного столбца, если указан параметр on) и индексов другого датафрейма, возвращая все строки из обоих датафреймов.
inner Формирует пересечение индексов вызывающего датафрейма (или иного столбца, если указан параметр on) с индексами другого датафрейма,

78 Глава 3. Библиотеки Python для data science
возвращая только те строки, индексы которых встречаются в обоих дата фреймах.
На рис. 3.5 показаны примеры всех способов объединения методом join.
|
|
|
left |
|
|
|
|
right |
||||||||||
|
|
+ |
|
= |
|
|
|
|
|
|
|
+ |
|
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
inner |
|
|
|
|
outer |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
+ |
|
= |
|
|
|
|
|
|
|
+ |
|
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С , а а а
С , а а а
Рис. 3.5. Результаты различных способов объединения
Если необходимо, чтобы итоговый датафрейм включал только те строки из emps, которые имеют соответствия в salary, выберите значение inner для параметра how в методе join():
emps_salary = emps.join(salary, how = 'inner') print(emps_salary)
В результате должен получиться такой датафрейм:
|
|
Name |
Job |
Salary |
Empno |
|
|
|
|
9001 |
Jeff |
Russell |
sales |
3000 |
9002 |
Jane |
Boorman |
sales |
2800 |
9003 |
Tom Heints |
sales |
2500 |
|
|
|
|
|
|
Еще один способ получить такой же результат — передать right в параметр how. В этом случае join() вернет все строки из датафрейма salary, добавив к ним