

Spark. Назначение и принцип работы. Отличия от MapReduce. Архитектура. Основные api. Виды планировщиков в Spark.
Apache Spark - это мощный и распределенный фреймворк, назначение которого заключается в обработке больших объемов данных параллельно на кластерах. Он предоставляет API на Scala, Java, Python и R, что делает его удобным для разработчиков с разным опытом.
Принцип работы Apache Spark основан на двух абстракциях: Resilient Distributed Dataset (RDD) и Directed Acyclic Graph (DAG).
RDD - это группа элементов данных, которые могут храниться в памяти на узлах рабочего процесса. (аналог сплитов в Hadoop). RDD делится на партиции, которые являются атомарными частями данных RDD поддерживает параллелизм данных и терминирование ошибок.
DAG - это конечный прямой граф, который выполняет последовательность вычислений над данными. Каждый узел является репликой RDD, а кривая - это преобразование над данными. Для управления запуском и распределением задач между узлами используются различные типы менеджеров кластера, такие как Hadoop YARN, Apache Mesos или Standalone Scheduler.
Отличия Spark от MapReduce:
Скорость обработки данных:
Spark запускает приложения в 100 раз быстрее в памяти и в 10 раз быстрее на диске, чем Hadoop MapReduce благодаря уменьшению количества чтения-записи на диск и хранения промежуточных данных в памяти.
MapReduce требует чтения и записи на диск после каждого шага, что снижает скорость обработки.
Простота использования:
Spark предоставляет множество библиотек для выполнения основных высокоуровневых операций при помощи RDD, в то время как в MapReduce разработчикам нужно писать вручную каждую операцию, что усложняет процесс.
Обработка больших наборов данных:
Spark оптимизирован относительно скорости и вычислительной эффективности при помощи хранения основного объёма данных в памяти, а не на диске. Однако, при огромных объемах данных, когда недостаточность RAM становится проблемой, Hadoop MapReduce может сработать лучше, поскольку он позволяет обрабатывать огромные наборы данных параллельно, разбивая их на небольшие отрезки для обработки на разных узлах данных.
Функциональность:
Spark превосходит MapReduce в итеративной обработке, обработке в почти реальном времени и обработке графов.
MapReduce изначально проектировался только для Map и Reduce функций, в то время как Spark создавался как универсальный движок для разнообразных алгоритмов.
Spark может обрабывать данные в реальном времени, в отличие от MapReduce
Архитектура Spark состоит из нескольких компонентов:
Driver Program: Это программа, которая определяет наборы данных на кластере и применяет операции к ним.
SparkContext: Это основной объект, с помощью которого мы взаимодействуем со Spark. Можно создать только 1 SparkContext внутри приложения. Знает всё о нашем приложении (версия спарка, какой менеджер ресурсов используется, как называется наше приложение)
Cluster Manager: Это внешний служебный модуль, который используется для получения ресурсов в кластере. Spark поддерживает несколько типов менеджеров кластера, включая Hadoop YARN, Apache Mesos и Standalone Scheduler.
Executor: Это процесс, который запускается на узле в кластере и выполняет задачи, которые отправляет драйвер.
Task: Это единица работы, которую драйвер отправляет на исполнителей.
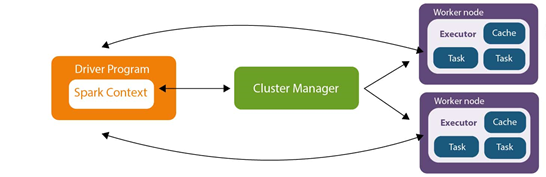
Рисунок 2 — Архитектура Apache Spark
Основные API:
Spark Core: Это компонент для обработки данных, который лежит в основе всей платформы. Ядро взаимодействует с системами хранения, управляет памятью, планирует и распределяет нагрузку в кластере.
SparkSQL: Это компонент, поддерживающий запрашивание данных либо при помощи SQL, либо посредством Hive Query Language. Он не только обеспечивает поддержку различных источников данных, но и позволяет переплетать SQL-запросы с трансформациями кода.
Spark Streaming: Это компонент, поддерживающий обработку потоковых данных в реальном времени. Такими данными могут быть файлы логов рабочего веб-сервера (напр. Apache Flume и HDFS/S3), информация из соцсетей, а также различные очереди сообщений вроде Kafka. Spark Streaming получает входные потоки данных и разбивает данные на пакеты. Далее они обрабатываются Spark, после чего генерируется конечный поток данных (в пакетной форме)
MLlib: Это библиотека для машинного обучения, предоставляющая различные алгоритмы, разработанные для горизонтального масштабирования на кластере в целях классификации, регрессии, кластеризации, совместной фильтрации и т.д.
GraphX: Это библиотека для манипуляций над графами и выполнения с ними параллельных операций. Библиотека предоставляет универсальный инструмент для ETL, исследовательского анализа и итерационных вычислений на основе графов.
В Spark существует несколько видов планировщиков, которые управляют выполнением задач и распределением ресурсов. Вот некоторые из них:
Планировщик задач (Task Scheduler): Распределяет задачи на исполнение по вычислительным узлам (executor'ам) в кластере, учитывает доступность ресурсов на узлах и старается минимизировать время выполнения задач.
Планировщик ресурсов (Resource Scheduler): Управляет выделением ресурсов для приложений Spark в кластере. Поддерживает интегрирование с различными системами управления ресурсами, такими как YARN, Mesos или Kubernetes.
Планировщик работы (Job Scheduler): Отвечает за планирование и выполнение задач в рамках конкретного приложения Spark, определяет порядок выполнения операций и оптимизирует выполнение задач для достижения лучшей производительности.
Планировщик DAG (Directed Acyclic Graph Scheduler): Управляет выполнением операций, описанных в Directed Acyclic Graph (DAG), а также оптимизирует порядок выполнения операций для улучшения производительности и эффективности.