

БД_Лабораторная_работа_2_БСТ2104_Мажукин_И_Н
.docxgМИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования
«Московский технический университет связи и информатики»
Кафедра «Математическая кибернетика и информационные технологии»
Дисциплина «Большие данные»
Лабораторная работа 2
Выполнил:
студент группы БСТ2104
Мажукин И.Н.
Проверила: Тимофеева А. И.
Москва, 2023 г.
Содержание
Цель работы 3
Ход выполнения работы 3
Hadoop streaming 12
Дополнительные задания 15
Вывод: 17
Цель работы 3
Ход выполнения работы 3
Hadoop streaming 12
Дополнительные задания: 15
Вывод: 17
Цель работы
Получить навыки работы с MapReduce и YARN.
Ход выполнения работы
Почистите свои директории после первой лабы. После очищение директорий будем работать с файлом yarn. Используем команду yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar

Рисунок 1 – Вывод всех доступных тестовых сценариев
Выберем сценарий для работы программы – pi, которая вычисляет число π с помощью метода Монте-Карло для заданного количества точек на плоскости. Используем команду yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar pi 5 123456789, где 5 – количество контейнеров, работающих параллельно, 123456789 – количество точек записанных для обработки в каждый контейнер.

Рисунок 2 – Вывод подсчета значения π с помощью метода Монте-Карло
Команда вычислила значение π за 317.741 секунд. Чему равно полученное значение? Ответ: 3.14159321930849829571

Рисунок 3 – Вывод результат работы команды для подсчета значения π
Увеличим количество точек в 10 раз и сравним точность. Используем команду yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar pi 5 1234567890
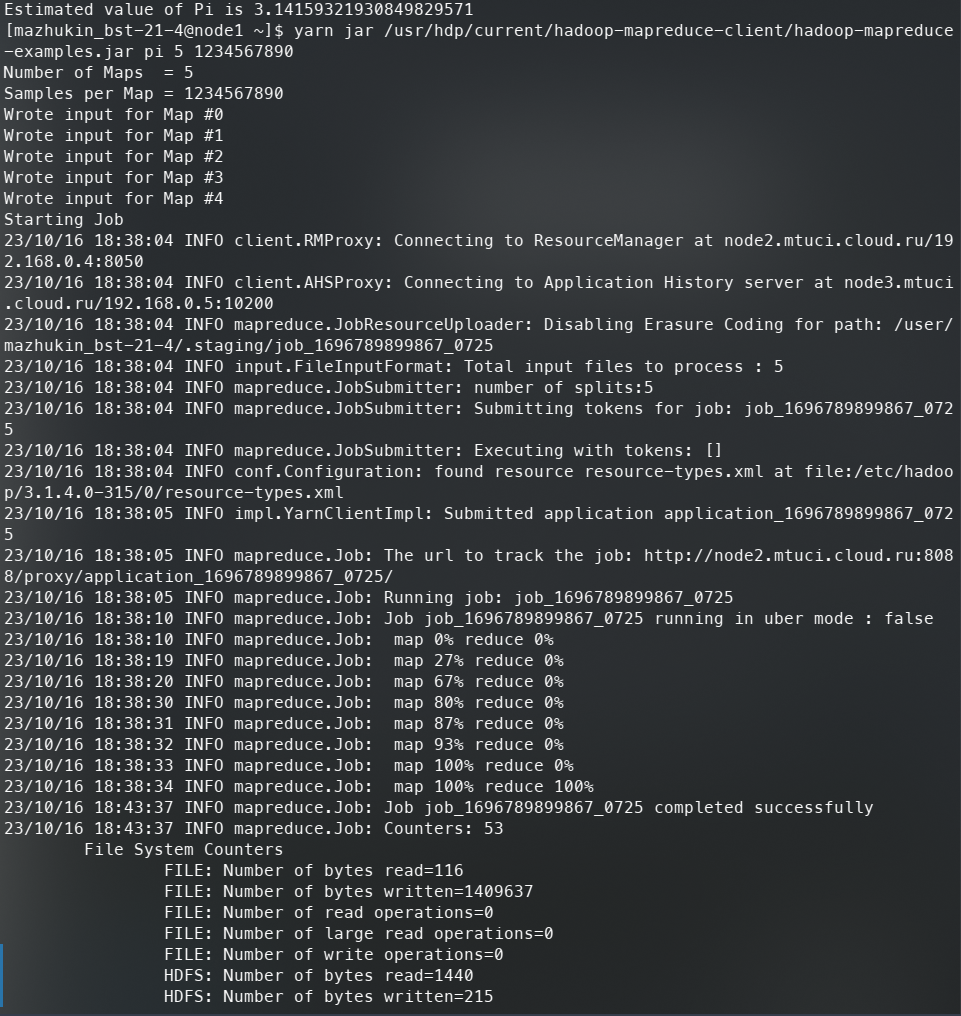
Рисунок 4 – Вывод подсчета значения π с помощью метода Монте-Карло
Команда вычислила значение π за 333.021 секунды. Чему равно полученное значение? Ответ: 3.14159277542849425640. Точность изменилась с 6 знака после запятой.

Рисунок 5 – Вывод результат работы команды для подсчета значения π
В Ambari в ResourceManager UI. Во вкладке Applications содержится история запуска всех YARN-приложений найдем свой запуск и кликните на его application ID.
![]()
![]()
Рисунок 6 – Вывод истории запусков

Рисунок 7 – Вывод информацию о статусе приложения

Рисунок 8 – Вывод информации о Job
Увеличим количество создаваемых точек и зайдём в UI, чтобы увидеть подробную информацию в процессе работы приложения. Используем команду yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar pi 5 12345678987

Рисунок 9 – Вывод информации об использовании памяти
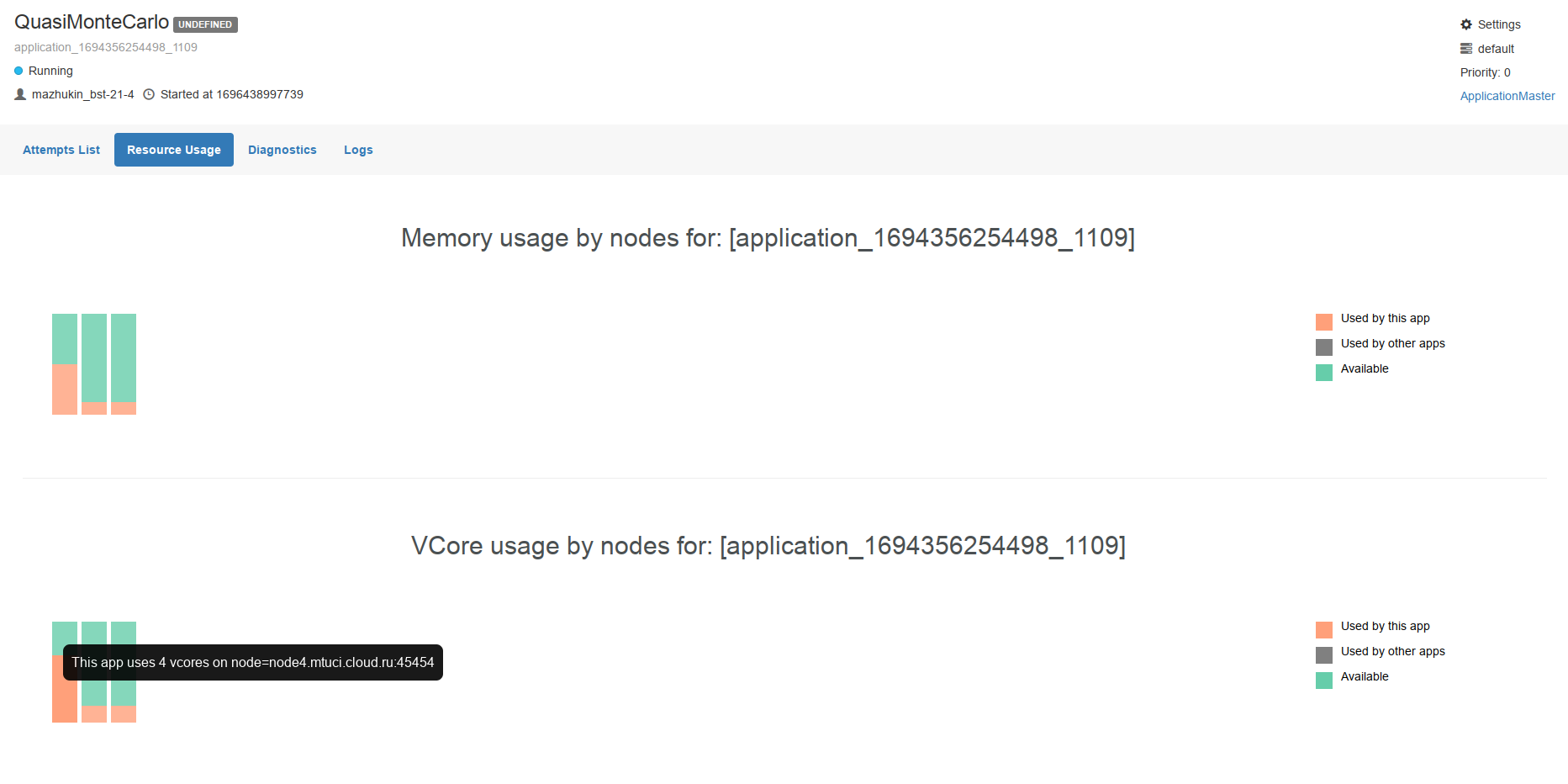
Рисунок 10 – Вывод информации об использовании VCore

Рисунок 11 – Вывод информации о запущенных контейнерах
Заполним таблицу:
Resource Usage |
Информация по нодам |
Сколько памяти занимает приложение на каждой ноде? |
1 – 4 GB 2 – 1 GB 3 – 1 GB |
Сколько виртуальных ядер выделено под задачу на каждой ноде? |
1 – 4 VCore 2 – 1 VCore 3 – 1 VCore |
Какое количество контейнеров создано для решения задачи на каждой ноде? |
1 – 4 containers 2 – 1 containers 3 – 1 containers |
Ответьте на вопрос: О серверах с каким запущенным сервисом YARN была получена информация? 4,5,6 node4.mtuci.cloud.ru:45454
Запустим задачу ещё раз и выполним команду yarn top.
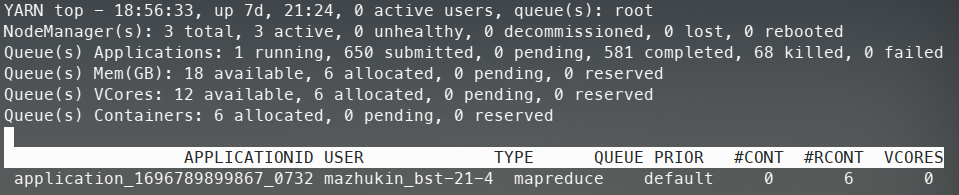
Рисунок 12 – Вывод информации yarn top

Рисунок 13 – Вывод команды yarn kill
Проверим статус нашей задачи
![]()
Рисунок 14 – Вывод информации yarn kill в yarn
Выполните запуск любого другого тестового сценария. Выберем сценарий teragen. Это команда нужна для создания данных для программы TeraSort.

Рисунок 15 – Выполнение сценария teragen
![]()

Рисунок 16 – Вывод информации Использование памяти

Рисунок 17 – Вывод информации Использование VCore

Рисунок 18– Вывод информации Запуск контейнеров
Заполним таблицу:
Resource Usage |
Информация по нодам |
Сколько памяти занимает приложение на каждой ноде? |
1 – 1 GB 2 – 0 GB 3 – 0 GB |
Сколько виртуальных ядер выделено под задачу на каждой ноде? |
1 – 1 VCore 2 – 0 VCore 3 – 0 VCore |
Какое количество контейнеров создано для решения задачи на каждой ноде? |
1 – 1 containers 2 – 0 containers 3 – 0 containers |

Рисунок 19– Результат работы teragen
Hadoop streaming
Создать Hadoop-streaming программу, которая бы удаляла из текста все вхождения следующих слов. Реализация программы будет на языке python.
Создадим файл, который будет использоваться для удаления слов

Рисунок 20 – Код для выполнения Hadoop-streaming
Запустим его в Hadoop

Рисунок 21 – Запуск команды
Вывод результата работы программы

Рисунок 22 – Вывод результата работы программы
Дополнительные задания
Напишите свою реализацию подсчёта числа PI
Создадим файл, который будет считать число Pi

Рисунок 23 – Код программы
Запустим его в Hadoop
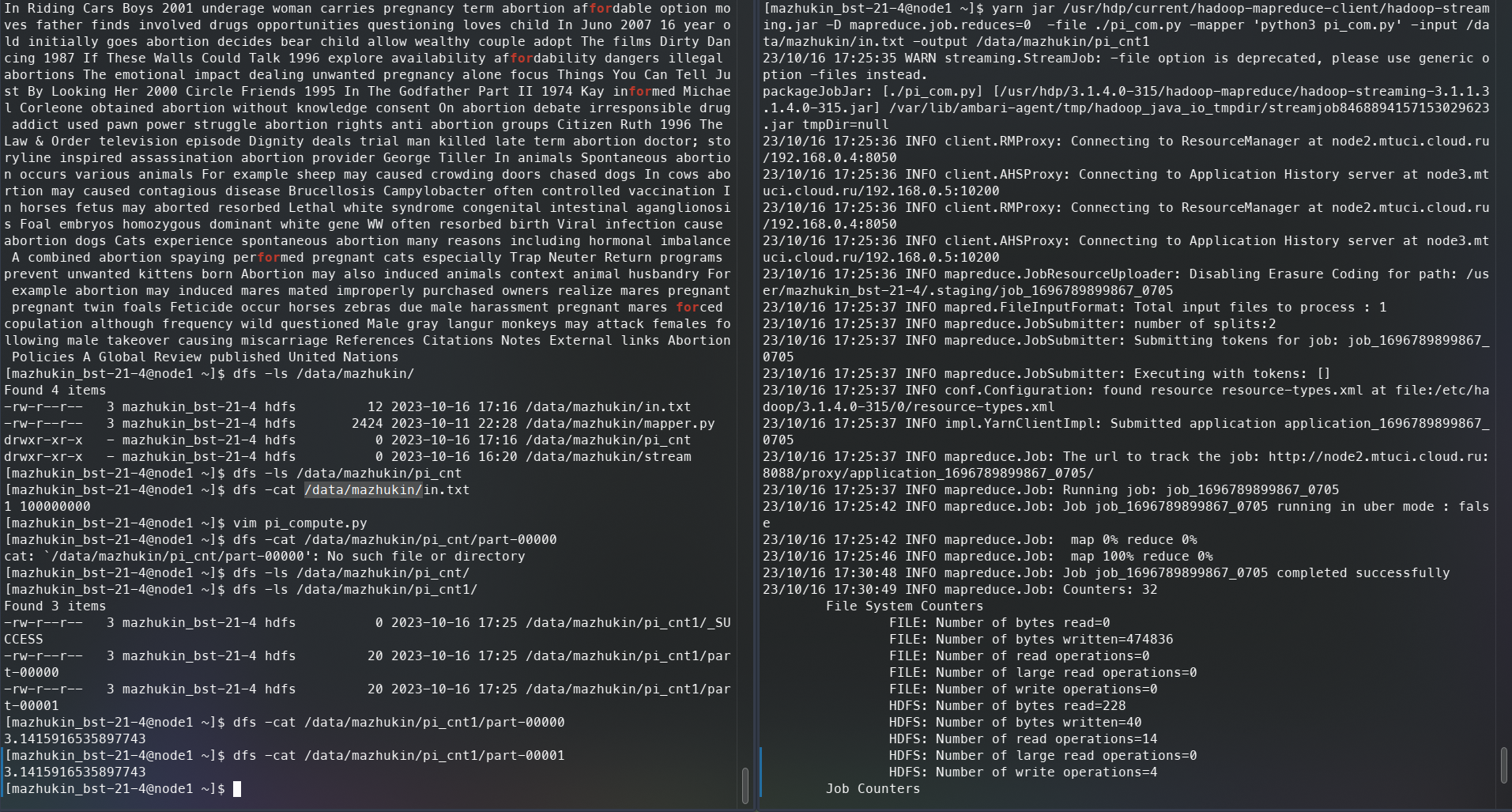
Рисунок 24 – Запуск программы в Hadoop
Рисунок 25 – Результат работы программы
2. Посчитайте число вхождений слов длиной от 6 до 9 символов. Результат приведите к нижнему регистру и отсортируйте по убыванию числа вхождений, в случае равенства – лексикографически.
Создадим файл, который будет подсчитывать слова

Рисунок 26 – Код для выполнения Hadoop-streaming

Рисунок 27 – Запуск команды
Рисунок 28 – Вывод результата работы программы
Вывод:
Получил навыки работы с MapReduce и YARN.