

Проверка на гомоскедастичность.
Одно из требований теоремы Гаусса-Маркова
- дисперсия случайной компоненты D(![]() )
=
)
=
![]() =const., т.е. предположение
о постоянстве дисперсии случайной
составляющей для всех наблюдений. Если
это условие соблюдается процессet
называется гомоскедастичным.
Если это не так, то процесс называется
гетероскедастичным. Для обнаружения
гетероскедастичности используется
метод Голдфельда-Квадта [1]. При проведении
проверки по этому тесту предполагается
, что стандартное отклонение σ
случайной составляющей
пропорционально значению независимой
переменной Xt
=const., т.е. предположение
о постоянстве дисперсии случайной
составляющей для всех наблюдений. Если
это условие соблюдается процессet
называется гомоскедастичным.
Если это не так, то процесс называется
гетероскедастичным. Для обнаружения
гетероскедастичности используется
метод Голдфельда-Квадта [1]. При проведении
проверки по этому тесту предполагается
, что стандартное отклонение σ
случайной составляющей
пропорционально значению независимой
переменной Xt

Рис.34
Прежде всего выделяем таблицу исходных
данных с помощью мышки, затем обращаемся
к меню «Данные», где выделяем элемент
меню «Сортировка» (см. рис.34). В ответ
на это действие появляется диалоговое
окно «Сортировка диапазона» (см. рис.35)
выбирается
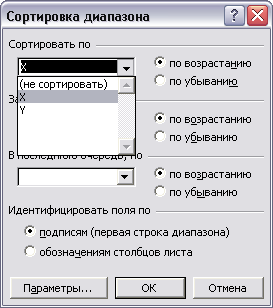
Рис.35
сортировка по возрастанию по столбцу Х. Важное условие такой сортировки – неразрывность пар (Xt,Yt), они могут перемещаться только вместе. В результате получаем новую таблицу, в верхней части которой сосредоточены меньшие значения Х, а в нижней – большие. При неравенстве дисперсий это неизбежно отразится наESSв верхней и нижней части.
Делим таблицу на две части поровну. Предлагаю брать верхнюю и нижние трети. А.И.Для каждой из частей определяем регрессию с помощью функции ЛИНЕЙН и выделяем значенияESS1 иESS2 (см. рис. 36).
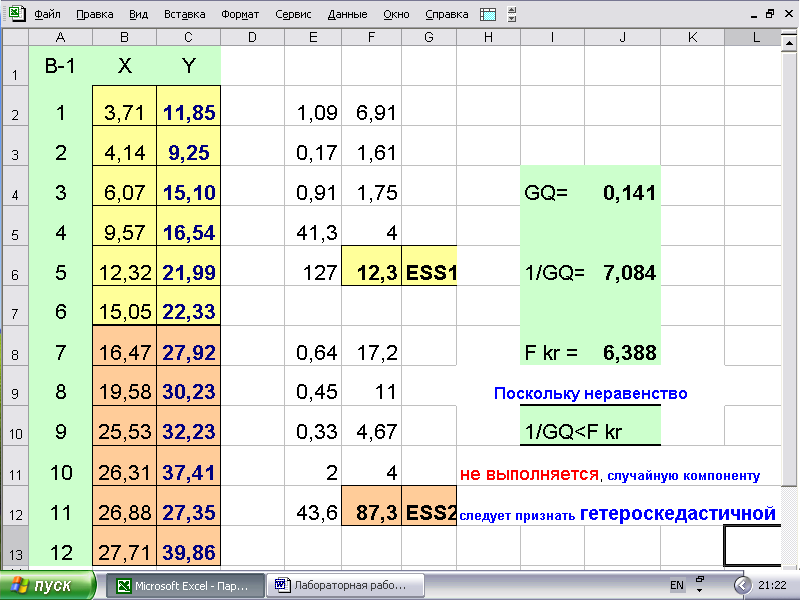
Рис.36
Вычисляем две статистики: статистку GQ=ESS1/ESS2 и 1/GQ=ESS2/ESS1. Затем по таблице или по функцииFраспробр определяем критическое значениеFkrдля уровня значимостиα=0,05, числа степеней свободы для уравнения регрессии верхней половины таблицы (ячейкаF5) и нижней половины (ячейкаF11). Если обе статистикиGQ<Fkrи 1/GQ<Fkr, то гипотеза о гомоскедастичности принимается с вероятностью 0,95. В противном случае, если хотя бы одно неравенство не выполняется, случайная компонента гетероскедастична. Описанная процедура иллюстрируется расчетами, приведенными на рис. 36.
Проверка адекватности модели.
Воспользовавшись двенадцатью парами значений (Xt,Yt),t= 1,2,3,…,12 оценили уравнение регрессии
![]() 7,863 + 1,022*Xt,
7,863 + 1,022*Xt,
где
![]() -
оценки коэффициентов регрессии, случайные
величины, для которых ранее вычислены
оценки стандартного отклонения:
-
оценки коэффициентов регрессии, случайные
величины, для которых ранее вычислены
оценки стандартного отклонения:![]() Поэтому и сама регрессия
Поэтому и сама регрессия![]() ,
как сумма случайных величин есть величина
случайная. С другой стороны у нас нет
другого инструмента для предсказания,
кроме как это уравнение регрессии. Пусть
за пределами 12-ти пар значений (Xt,Yt)
в нашем распоряжении имеется еще одна
пара (Х13,Y13).
Такую пару легко взять из
листа «Задание» файла «Парная регрессия
1» в папке «ЛабРаб». Все исходные данные
в вертикальных столбцах листа «Задание»
(варианты В-4, В-7, В-10) моделируются по
одним и тем же параметрам. Пусть это
будут значения из таблицы с индексами
Xp
и Yp,
и будем считать, что Yp
нам недоступно. Тогда единственная в
нашем случае возможность оценить
значение Yp
остается предсказать
,
как сумма случайных величин есть величина
случайная. С другой стороны у нас нет
другого инструмента для предсказания,
кроме как это уравнение регрессии. Пусть
за пределами 12-ти пар значений (Xt,Yt)
в нашем распоряжении имеется еще одна
пара (Х13,Y13).
Такую пару легко взять из
листа «Задание» файла «Парная регрессия
1» в папке «ЛабРаб». Все исходные данные
в вертикальных столбцах листа «Задание»
(варианты В-4, В-7, В-10) моделируются по
одним и тем же параметрам. Пусть это
будут значения из таблицы с индексами
Xp
и Yp,
и будем считать, что Yp
нам недоступно. Тогда единственная в
нашем случае возможность оценить
значение Yp
остается предсказать
|
Xp |
Yp |
|
3,38 |
13,59 |
его через уравнение регрессии,
подставив в него значение Xp
= 3,38.
Точечная оценка
![]() = 11,32. В данном случае
ошибка предсказания равна
= 11,32. В данном случае
ошибка предсказания равна
![]() и хотелось бы уяснить, является ли она
допустимой с точки зрения точности
использованной нами модели. Другое
дело, устроит ли эта точность заказчика
– лицо, принимающее решение. Но нам
следует убедиться пока лишь в том, что
эта ошибка укладывается в рамки
статистической точности, гарантированной
методом наименьших квадратов. Для этого
оценим числовые характеристики ошибки.
Убедимся, что математическое ожидание
ошибки имеет нулевое значение.
и хотелось бы уяснить, является ли она
допустимой с точки зрения точности
использованной нами модели. Другое
дело, устроит ли эта точность заказчика
– лицо, принимающее решение. Но нам
следует убедиться пока лишь в том, что
эта ошибка укладывается в рамки
статистической точности, гарантированной
методом наименьших квадратов. Для этого
оценим числовые характеристики ошибки.
Убедимся, что математическое ожидание
ошибки имеет нулевое значение.
![]()
Дисперсия ошибки прогноза запишется в следующем виде:
![]()
![]()
Так как
![]() и эта случайная величина состоит из
суммы двух случайных величин:
и эта случайная величина состоит из
суммы двух случайных величин:![]() и
и![]() ,
умноженной на константу
,
умноженной на константу![]() ,
то ее дисперсия
,
то ее дисперсия![]() равняется сумме дисперсий
равняется сумме дисперсий![]() и дисперсии
и дисперсии![]() ,
умноженной на квадрат константы
,
умноженной на квадрат константы![]() .
Оценки этих дисперсий известны [1]:
.
Оценки этих дисперсий известны [1]:![]() и
и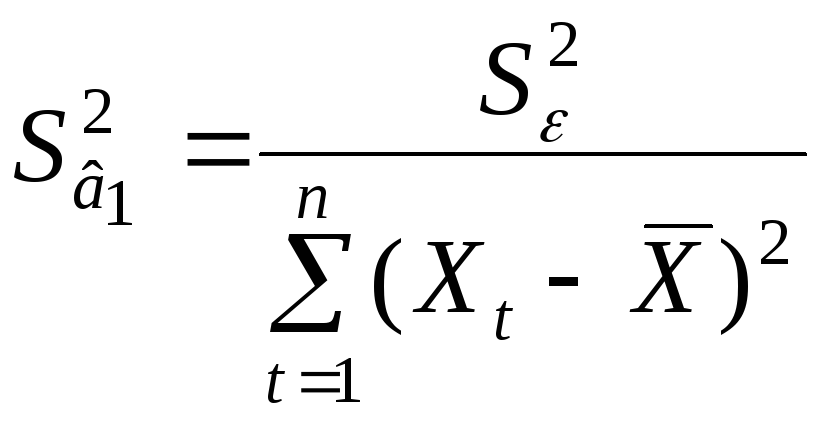 .
Тогда дисперсия
.
Тогда дисперсия![]() оценивается следующей формулой:
оценивается следующей формулой:
Дисперсия
![]() и ее оценка
и ее оценка![]() определена выше. Оценка дисперсии
прогноза определяется формулой:
определена выше. Оценка дисперсии
прогноза определяется формулой:
 (2)
(2)

Рис.37
Формулу (2) можно преобразовать к виду,
более удобному для расчета среднеквадратичного
отклонения прогноза
![]() .
Из обеих частей формулы (2) извлечем
квадратный корень:
.
Из обеих частей формулы (2) извлечем
квадратный корень:


.
Обозначим
 .
.
Тогда
![]()
Оценим дисперсию ошибки прогноза исходя из полученных ранее оценок:
![]() ,
n
=12,
Xp
= 3,38.
, среднее значение Х,
вычисленное с помощью функции СРЗНАЧ,
равно
,
n
=12,
Xp
= 3,38.
, среднее значение Х,
вычисленное с помощью функции СРЗНАЧ,
равно
![]() .,
.,
![]() .
.
Результаты оценки выполнены в Excelи представлены на рис. 37.
Литература.
1. Бывшев В.А. Введение в эконометрию. Часть 2.-М.: ФА при Правительстве РФ, 2003.