

8879
.pdfРис. 25. Задание вариантов обработки пропусков Параметры восстановления задаются на первом шаге Мастера. Для каждого
поля на выбор предлагается три варианта обработки пропусков (рис. 25). В нашем примере все поля с пропусками относятся к типу неупорядоченных. Остальные два шага Мастера пропустим, т.к. они относятся к очистке и сглаживанию временных рядов.
После выполнения обработчика в таблице можно убедиться, что значения восста-
новлены (рис. 26).
Рис. 26. Восстановленные значения
61
Алгоритм подставил наиболее вероятное значение (строится плотность рас-
пределения вероятностей, и отсутствующие данные заменяются значением, соответ-
ствующим ее максимуму).
Шаг 4 – выявление аномалий
Анализ визуализатора Статистика (минимальные и максимальные значения полей) позволил сделать вывод об отсутствии аномальных выбросов в данных файла
сотовые операторы.txt.
Перед выявлением аномалий полезно также изучить распределение данных
(гистограмму), и те поля, в которых оно нормальное, проанализировать на выбросы методом «сигм»: любые значения ряда, отличающиеся от среднего больше чем на три среднеквадратических отклонения, являются потенциальными аномалиями.
Потенциальные аномалии можно обнаружить и на графике, для чего исполь-
зуют визуализатор Диаграмма (для аномальных точек используют один цвет,
например, красный цвет, для не аномальных – белый).
Шаг 5 – фильтрация
Фильтрация в очистке и предобработке используется для получения очищен-
ной выборки после принятия решений о судьбе «грязных» записей и для вспомога-
тельных действий.
В рассматриваемом примере фильтрация использовалась для исключения дуб-
ликатов и противоречий (см. сценарий на рис. 2.17).
Шаг 6 – совокупная оценка качества
Всего записей: до очистки – 607, после очистки – 557, удалено 8,24%.
Выводы: в целом качество данных можно признать очень хорошим; проблемы, воз-
никшие с пропущенными и аномальными данными, были решены стандартными ме-
тодами.
Задания для раздела 2.
Задание 1. Требуется разработать систему аналитической отчетности в Deductor на основе созданного ранее хранилища данных ВОДА. Все требуемые отчеты
62
должны быть вынесены на Панель отчетов.
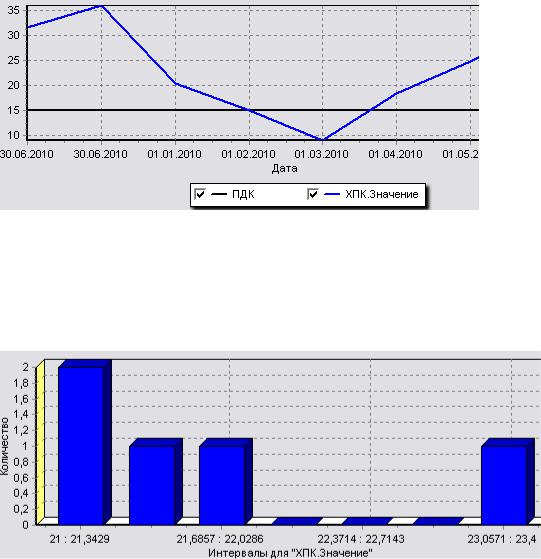
1.Постройте отчет–диаграмму «Динамика показателя содержания ХПК (хи-
мическое потребление кислорода) в реке Ока», используя все имеющиеся данные.
Рис. 27. Временной ряд загрязнителя ХПК
2.Постройте отчет–гистограмму распределения показателя «ХПК» в реке Бе-
ленькая за последние 5 месяцев от имеющихся данных. Назовите отчет «Ги-
стограмма показателя ХПК»
Рис. 28. Гистограмма показателя ХПК
3.Постройте куб (и кросс-диаграмму) по двум измерениям Створ и Название загрязнителя, в ячейках которого указаны средние значения показателей,
имеющихся в ХД ВОДА. Определите, у какого загрязнителя наибольшее среднее значение. Назовите отчет «Средние значения загрязнителей»
63
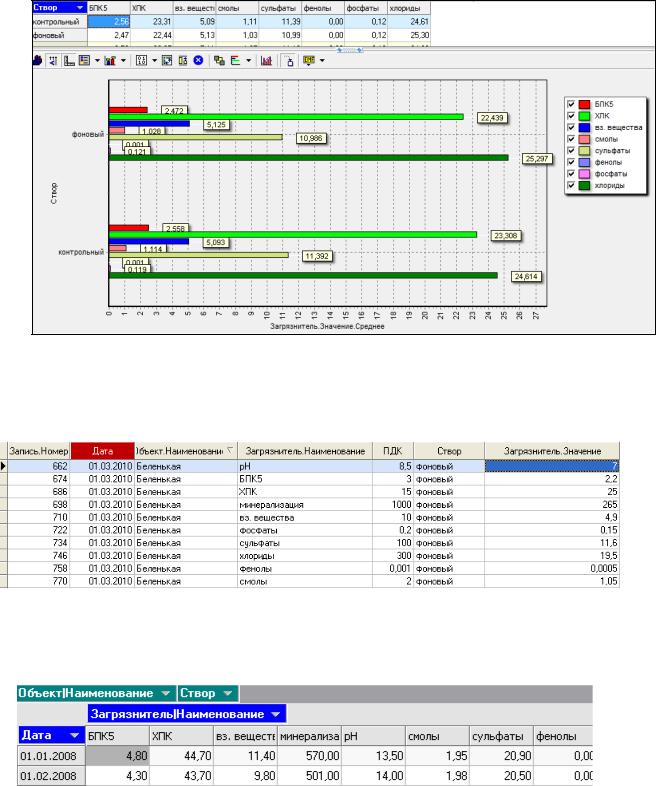
Рис. 29. Отчет «Средние значения загрязнителей»
4.Из ХД ВОДА выгружена информация по экологическим показателям объек-
тов Нижегородской области (фрагмент данных в таблице).
Используя визуализатор OLAP-куб, требуется получить отчет в виде приведенной ниже таблицы (указан фрагмент).
Таблица
Дополнительно: требуется сделать преобразование (трансформацию) дан-
ных так, чтобы на выходе была указанная таблица. Какие обработчики нуж-
но использовать в сценарии для решения этой задачи?
64
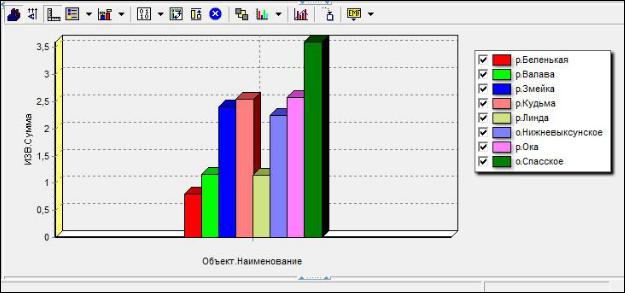
5.Построить отчет-диаграмму «Индекс загрязнения воды (ИЗВ)» для всех рас-
сматриваемых водных объектов и сделать вывод, какой объект является са-
мым загрязненным.
Рис. 30. Отчет «ИЗВ»
Указание: Для составления данного отчета должна быть произведена фильтрация по каждому водному объекту и шести загрязнителям, относящимся к конкретному водному объекту. С помощью внешнего левого соединения для каждого водного объекта нужно составить таблицу, содержащую информацию о загрязнителях, их значениях и ПДК (предельно допустимая концентрация). Далее с помощью калькулятора в таблицу добавить поле «Отношение», которое вычисляется путем деления столбца «Значение загрязнителя» на столбец «ПДК». После вычисления данного столбца произвести группировку по измерениям
«Наименование объекта» и «Дата», а в качестве агрегации факта «Отношение» выбрать. Затем с помощью калькулятора в полученную таблицу добавить поле
«ИЗВ», которое вычисляется по формуле (2), и вывести диаграмму на панель отчетов.
|
n |
|
/ |
ПДК |
i |
ИЗВ |
i 1Ci |
|
|
||
|
N |
|
|
||
|
|
|
|
||
Сi - концентрация компонента;
N – число показателей, используемых для расчета индекса;
ПДКi – установленная величина для соответствующего типа водного объекта.
65

6. Написать сценарий и получить отчет «Отношение к ПДК» (рис. 31).
Отчет представляет собой сводную таблицу, в которой представлено отно-
шение каждого загрязнителя к уровню его ПДК. Данные значения являются относи-
тельными, то есть не имеют единиц измерения, поэтому их можно использовать для корреляционного анализа.
Рис. 31. Отчет «Отношение к ПДК» (фрагмент)
Задание 2. Требуется разработать систему аналитической отчетности в Deductor на основе созданного ранее хранилища данных Регион. Все требуемые отчеты должны быть вынесены на Панель отчетов (рис. 32). При помощи операций транс-
понирование измерений, фильтрация и агрегирование фактов, сформировать отчеты и ответить на вопросы в заданиях.
Используемые обозначения основных социально-экономических показателей:
Показатель промышленность – объем произведенной продукции (работ,
услуг) в действующих ценах соответствующих лет по крупным и средним предприятиям, млн.руб.;
Показатель с/х – продукция сельского хозяйства в хозяйствах всех категорий
(в фактически действовавших ценах), тыс.руб.;
Показатель инвестиции – инвестиции в основной капитал крупных и средних предприятий, тыс.руб.;
Показатель зарплата – среднемесячная заработная плата работающих на крупных и средних предприятиях, руб.;
Показатель безработица – уровень официально зарегистрированной безработицы (в % от экономически активного населения);
Показатель доход – доходы бюджета, млн.руб.;
Показатель расход – расходы бюджета, млн.руб.
66

Рис. 32. Отчеты по данным ХД Регион
1. Сформировать многомерные отчеты и соответствующие им кросс-
диаграммы для показателя промышленность, в которых будут указаны 5
лучших районов по объем произведенной продукции, 5 худших и районы,
дающие 50% от общего объема произведенной продукции в Нижегород-
ском регионе.
Последовательность выполнения задания
1)Подключить ХД Регион, извлечь имеющуюся там информацию и от-
корректировать названия полей, используя обработчик Настройка набора данных.
2)Запустить мастер визуализации и указать способ отображения дан-
ных в виде куба.
3)Произвести настройку назначений полей куба: измерения – дата
(размещаем в строки), код_региона-название (размещаем в колонки),
код региона – информационный, остальные поля – факты (с агрегаци-
ей – сумма).
67
4)В полученной кросс-таблице осуществить фильтрацию, выбрав факт промышленность, измерение код_региона-название и
а) условие «Первые N», значение «5»;
б) условие «Последние N», значение «5»;
в) условие «Доля от общего», значение «50».
2.Сформировать многомерные отчеты и соответствующие им кросс-
диаграммы для показателя с/х, в которых будут указаны 5 лучших районов по уровню с/х, 5 худших.
3.Определить первые 5 районов по инвестициям и 5 последних.
4.Определить районы с самым высоким и самым низким уровнем безработицы.
5.Определить районы с самым высоким и самым низким уровнем зарплаты.
6.Определить 5 самых доходных районов, 5 районов с самым низким уровнем доходов и районы, дающие 80% дохода бюджета всего Нижегородского региона.
7.Определить районы с наибольшим и наименьшим расходом бюджета.
Задание для раздела 3.
Пример построения классифицирующего дерева решений для оценки не-
движимости в аналитической платформе Deductor Studio Academic.
Рассмотрим построение модели классификации, относящей объекты недвижимости на основе их признаков к одному из трех классов «дорогие, средние, дешевые квартиры».
Таблица. Входные атрибуты, влияющие на оценку жилья.
№ |
Наименование |
Описание |
Тип значений |
|
|||
|
|
|
|
1 |
2 |
3 |
4 |
|
|||
|
|
|
|
1 |
№ п/п |
номер по порядку |
целый |
|
|||
|
|
|
|
2 |
Адрес |
название улицы |
строковый |
|
|||
|
|
|
|
3 |
Общая площадь |
общая площадь квартиры, кв. м |
вещественный |
|
|||
|
|
|
|
|
|
68 |
|
4 |
Кухня |
площадь кухни, кв. м |
|
вещественный |
|
|
|
||||
|
|
|
|
|
|
5 |
Жилая площадь |
жилая площадь, кв. м |
|
вещественный |
|
|
|
||||
|
|
|
|
|
|
6 |
Остальная |
остальная площадь, кв. м |
|
вещественный |
|
площадь |
|
||||
|
|
||||
|
|
|
|
|
|
|
|
материал стен дома: |
|
|
|
|
|
|
кирпич – 4 |
|
|
7 |
Стены |
|
монолитный – 3 |
|
целый |
|
|
|
|||
|
|
|
|
||
|
|
|
панельный- 2 |
|
|
|
|
шлакоблочный – 1 |
|
|
|
|
|
|
|
|
|
|
|
этаж дома: |
|
|
|
8 |
Этаж |
первый/последний - 0 |
|
целый |
|
|
|
|
|||
|
|
|
|
||
|
|
|
остальные - 1 |
|
|
|
|
|
|
|
|
|
|
наличие балкона: |
|
|
|
|
|
|
лоджия - 2 |
|
|
9 |
Балкон |
|
простой - 1 |
|
целый |
|
|
||||
|
|
|
нет – 0 |
|
|
|
|
|
|
|
|
|
|
|
|
окончание таблицы 7 |
|
1 |
2 |
|
3 |
|
4 |
|
|
|
|||
|
|
|
|
|
|
|
|
наличие санузла: |
|
|
|
10 |
Санузел |
|
раздельный - 1 |
|
целый |
|
|
|
|||
|
|
|
|
||
|
|
|
совмещенный – 0 |
|
|
|
|
|
|
|
|
|
|
наличие телефона: |
|
|
|
11 |
Телефон |
|
есть -1 |
|
целый |
|
|
|
|||
|
|
|
|
||
|
|
|
нет – 0 |
|
|
|
|
|
|
|
|
|
|
Оценка состояния помещения: |
|
|
|
|
|
|
нежилое - 0 |
|
|
|
|
|
без отделки - 1 |
|
|
12 |
Состояние |
|
удовлетворительное -2 |
|
целый |
|
|
||||
|
|
|
хорошее- 3 |
|
|
|
|
|
отличное – 4 |
|
|
|
|
|
|
|
|
|
|
|
69 |
|
|
Шаг 1. Загрузка данных и проверка их качества определяется с помощью ви-
зуализаторов Статистика и различных диаграмм.
Шаг 2. Очистка данных, используя следующие обработчики:
Парциальная обработка – восстановление, редактирование,
сглаживание данных;
Факторный анализ – понижение размерности входных
факторов;
Корреляционный анализ – устранение незначащих факторов;
Дубликаты и противоречия – выявление дубликатов и противоречий;
Фильтрация – фильтрация строк таблицы по условию.
Шаг 3. Трансформация данных (так как обработчик Дерево решений работает только с дискретными значениями): преобразование выходного поля «цена 1 кв. м»
из непрерывного в дискретный тип, используя обработчик Квантование.
Квантование – это процесс, в результате которого происходит распределение значений непрерывных данных по конечному числу интервалов заданной длины.
Для разбиения нужно настроить следующие параметры квантования:
Способ – выбираем из списка способ квантования по квантилям, чтобы в каждый из квантильных интервалов попадало одинаковое количество квартир.
Интервал – указываем количество интервалов, на которое будет разбит диапазон исходных данных. Разбиваем на три интервала, так как в необходимо все объекты недвижимости разбить на 3 класса.
Значение – указываем 3 интервала, например: от 51111,11 до 60000 рублей;
от 60000 до 62857,15 рублей; от 62857,15 до75000 рублей.
Шаг 4. Применяя обработчик «Замена значений», по таблице подстановок присваиваем интервалам, полученным на предыдущем шаге метки <Дешевая квартира>, <Средняя квартира>, <Дорогая квартира>.
Шаг 5. Строим модель классификации объектов недвижимости, используя об-
работчик Дерево решений:
70