

new_daterange = pd.date_range(start, stop, freq='300S') new_daterange = new_daterange.strftime('%Y-%m-%d %H:%M')
# Произведем операцию реиндексирования и интерполирования
df_file = df_file.set_index('time').reindex(new_daterange).interpolate().reset_index()
# Объединим обработанные дата фреймы в один df = pd.concat([df, df_file], axis=0)
df = df.set_index(['index']) df = df.sort_index()
Графическое представление обработанного дата фрейма (библ. pyplot)
Plotly - библиотека для визуализации данных, состоящая из нескольких частей:
Front-End на JS
Back-End на Python (за основу взята библиотека Seaborn)
Back-End на R
Документация - https://plotly.com/graphing-libraries/
Модуль plotly.express (обычно импортируемый как px) содержит функции, которые могут создавать целые графики сразу, и называется Plotly Express или PX. Plotly Express является встроенной частью библиотеки графиков и является рекомендуемой отправной точкой для создания наиболее распространенных графиков. Каждая функция Plotly Express использует графические объекты внутри и возвращает экземпляр plotly.graph_objects.Figure. Модуль plotly.graph_objects (обычно импортируемый как go) содержит автоматически сгенерированную иерархию классов Python, которые представляют неконечные узлы в этой схеме рисунка. Термин «объекты графа (graph objects)» относится к экземплярам этих классов.
Данная библиотека позволяет выполнять интерактивный анализ построенных графиков.
#импорт очновных модулей библиотеки plotly import plotly.graph_objects as go
import plotly.express as px
#Метод .line() создает линейный график (соединенный по точкам) fig = px.line(df, x=df.index, y=df['muf'], title='MUF')
#Выведем не весь временной ход, только часть, где присутствует
#не весь день
fig.update_xaxes(range=['2021-02-02', '2021-02-09']) fig.show()
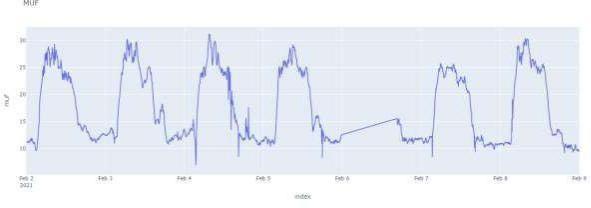
Рисунок 1. Графическое представление интерполированного временного хода значений максимальной применимой частоты.
32

Анализ графика и удаление значений за неполный день
Проводя анализ интерполированных временных рядов (график рис.1) может возникунать необходимость удалить значения за не полный день, как, например, за 2021- 02-05. Программный код ниже позволяет по определенным инедксам формата даты удалить из дата фрейма не восстановленные значения временного хода.
# Удаляем диапазон значений за 06.02.2021
df = df.drop(df.loc['2021-02-06 16:40':'2021-02-06 23:55'].index)
# Построми графки скорреткированного хода
fig = px.line(df, x=df.index, y=df['muf'], title='MUF') fig.update_xaxes(range=['2021-02-02', '2021-02-09']) fig.show()
Рисунок 2. Графическое представление интерполированного временного хода значений максимальной применимой частоты без остаточной составляющей.
Обработка аномалий временного хода и апроксимация Детектирование аномалий
Обработку аномалий выполним при помощи метода машинного обучения IsolationForest. Изолирующий лес — это алгоритм обнаружения аномалий. Он обнаруживает аномалии, используя изоляцию (насколько далеко точка данных находится от остальных данных), а не моделируя нормальные точки см. За данную процедуру отвечает библиотека sklearn.ensemble. Кроме того, для работы данного алгоритма машинного обучения требуется предварительная обработка используемого набора данных, за что отвечает метод StandartScaler библиотеки sklearn.preprocessing. Предварительния обработка бывает необходима в следующих случаях:
Когда наши данные состоят из атрибутов с разным масштабом, многие алгоритмы машинного обучения могут извлечь выгоду из масштабирования атрибутов, чтобы все они имели одинаковый масштаб.
Это важно для алгоритмов оптимизации, используемых в ядре алгоритмов машинного обучения, таких как градиентный спуск.
Это также важно для алгоритмов, которые взвешивают входные данные, такие как регрессия и нейронные сети, и алгоритмов, которые используют меры расстояния, например, K-ближайшие соседи.
Кроме того, есть возможность масштабировать исходные данные с помощью scikitlearn, используя класс MinMaxScaler.
#Испорт библиотек и иниициализация предобработчика scaler
from sklearn.ensemble import IsolationForest from sklearn.preprocessing import StandardScaler scaler = StandardScaler()
# Создадим функцию выполняющую операции детектирования аномалий
33
def IsolationForestOutfitDetectionRes(df, col_name):
#Удалим пустые ячейки входного датафрейма
#т.к. метод IsolationForest не работает с NaN значениями df = df.dropna()
#outliers_fraction определяет чувствительность алгоритма
#к аномальным значениям
outliers_fraction = float(.015) #Изменять в пределах до 0,01 до 0,05
#Применяем предобработчик и формируем новый датафрейм np_scaled = scaler.fit_transform(df[col_name].values.reshape(-1, 1)) data = pd.DataFrame(np_scaled)
#Передаем в алгоритм IsolationForest пемеренную чувствительности model = IsolationForest(contamination=outliers_fraction)
#Обучаем модель
model.fit(data)
#Создаем во входном дата фрейме новую колонку в которой
#буду записаны прогнозные метки тех значений МПЧ, которые
#алгоритм посчитал выбросами
df['Anomaly'] = model.predict(data)
# Вынесем в отдельный дата фрейм только выбросы (аномалии) anomaly = df.loc[df['Anomaly'] == -1, [col_name]] #anomaly
return anomaly, df
Интерполяция
Функция интерполяции в данном случае используется для апроксимации аномальных значений. На вход функции AnomalyInterpolationи() передается датафрейм с аномалиями и исходный. Далее данные аномальные значения удаляются из исходного датафрейма, а образованные пропуски интерполируются встроенным методом pandas interpolate(). Для интерполяции гармонических временных рядов подойдет полином второй степени.
def AnomalyInterpolation(anomaly_df, df, col_name):
#Конвертируем интерполируемую колонку в числовой формат df[col_name] = pd.to_numeric(df[col_name], errors='coerce')
#Конвертируем индексы в формат DatetimeIndex
df.index = pd.DatetimeIndex(df.index)
#Присваеваем индексы аномальных значений ряда indexes = anomaly_df[col_name].index
#Находим с сиходном датафрейме значения, по "аномальному" индексу
#и заменяем их на NaN для дальнейшей интерполяции df.loc[indexes.values, col_name] = np.NaN
#Сохраняем только целевую колонку
df = df[col_name]
df2 = pd.DataFrame()
#Методов interpolate выполняем интерполяцию
#полиномом второй степени
df2[col_name] = df.interpolate(method='polynomial', order=2)
return df2
Визуализация аномалий
Для визуализации аномальных значений ряда создадим функцию, которая принимает на вход метки выбросов и обрабатываемый датафрейм.
def PlotAnomaly(a, df):
#Инициализируем график - объект fig = go.Figure()
#Добавим ряд временного хода МПЧ
34
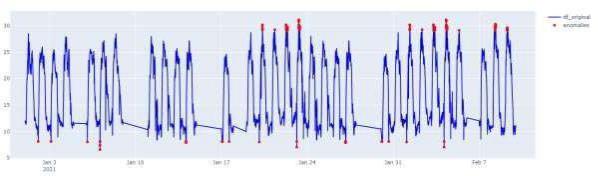
fig.add_trace(go.Scatter( x=df.index, y=df['muf'], hoverinfo="text", marker=dict(
color="blue"
), showlegend=True, name = 'df_original'
))
# Добавим ряд аномалий, которые будут отображены точками (параметр mode='markers')
fig.add_trace(go.Scatter( x=a.index, y=a['muf'], hoverinfo="text", marker=dict(
color="red"
), mode='markers', showlegend=True, name = 'anomalies'
))
fig.show()
Применим функцию детектирования аномалий без интерполяции, только для аизуализации продетектированных выбросов
col_name = 'muf'
#Сделаем копию исходного датафрейма для дальнейшего
#графического сравнения
original_df = df.copy()
# Применим функцию поиска аномалий
anomaly_df, df1 = IsolationForestOutfitDetectionRes(df, col_name)
# Построим графки
PlotAnomaly(anomaly_df, df)
Рисунок 3. Временной ход МПЧ с выделенными выбросами, которые были обнаружены средствами алгоритма МО.
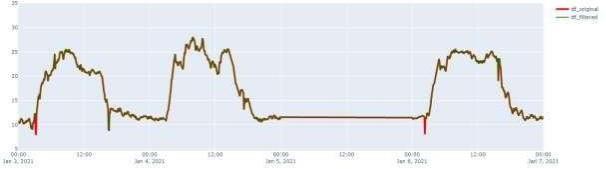
Далее проведем апроксимацию аномалий функцией AnomalyInterpolation() и построим график для сравнения результатов апроксимации и оригинального ряда (рис. 4)
35
df_filtered = AnomalyInterpolation(anomaly_df, df1, col_name)
fig = go.Figure()
fig.add_trace(go.Scatter( x=original_df.index, y=original_df['muf'], line=dict(color='red', width=4), hoverinfo="text", marker=dict(
color="blue"
), showlegend=True, name = 'df_original'
))
fig.add_trace(go.Scatter( x=df_filtered.index, y=df_filtered['muf'], hoverinfo="text", marker=dict(
color="green"
), showlegend=True, name = 'df_filtered'
))
fig.update_xaxes(range=['2021-01-03', '2021-01-07'])
fig.show()
Рисунок 4. Сравнение оригинального временного хода МПЧ и с корректировкой аномалий.
Выделим, напрмер, диапазон с 3 по 7 января, заметна корректировка ряда в начале дня 03.01 и 06.01. Операцию обоработкт аномалий можно запускать повторно, для более глубокой очистки, выполним еще цикл.
anomaly_df, df_filtered = IsolationForestOutfitDetectionRes(df_filtered, col_name) PlotAnomaly(anomaly_df, df_filtered)
36