

книги / Прикладной статистический анализ в горном деле (Многомерная математическая статистика)
..pdfковы, поскольку данные нормализованы. В табл. 4.8 приведены собственные значения для каждой дискриминантной функции и кумулятивная доля объясненной дисперсии, накопленной каждой функцией. Как видно, 100 % всей дискриминирующей мощности определяется этой функцией.
Таблица 4.8
Исходные и стандартизованные коэффициенты канонических переменных
В окне «Канонический анализ» выберите вкладку «Дополнительно», щёлкните на кнопку «Факторная структура» (см. рис. 4.13). В появившейся таблице (табл. 4.9, левая часть) представлены объединенные внутригрупповые корреляции переменных с соответствующими дискриминантными функциями. Их именуют структурными коэффициентами и используют для содержательной интерпретации функций, формируя её структуру. А коэффициенты дискриминантной функции обозначают вклад каждой переменной в функции.
Таблица 4.9
Факторная структура (слева) и средние канонических переменных (справа)
111

Если нажать кнопку «Средние канонических переменных», программа выведет таблицу со средними значениями коэффициентов для дискриминантных функций (табл. 4.9, правая часть). Перейдём на вкладку «Канонические значения» (в окне на рис. 4.13) и активируем кнопку «Канонические значения для каждого наблюдения». Программа выводит таблицу со значениями дискриминантных функций для каждого наблюдения
(табл. 4.10).
Таблица 4.10 Рассчитанные значения дискриминантных функций
Процедура дискриминации предполагает, что выделенные в результате проведения ДА группы наблюдений должны располагаться друг от друга как можно дальше. И, напротив, наблюдения, определяемые в ходе расчётов как объекты из одной группы, должны иметь близкие значения дискриминантных функций. Так, у скважин, встретивших ГДЯ, значения ДФ положительны (множество W), а у не встретивших (N) – отрицательны. Чтобы сохранить эти значения для дальнейшего анализа, надо нажать на кнопку «Cохранить канонические значения».
Вкладка «Канонические значения» позволяет построить и проанализировать гистограммы канонических значений, их графики рассеивания.
В приведенном примере мы получили разделение всех наблюдений по кодам. Газодинамическое явление или произошло, или не произошло. Вместе с тем многомерные методы статистических исследований являются вероятностными, и на рудниках
112

при прогнозе ГДЯ на новые участки хотелось бы знать их ожидаемую вероятность проявления. Для решения задачи в такой постановке введём в исходную таблицу новую числовую переменную kod_ch. Заполним её следующими вероятностями: если в скважине встречено ГДЯ, то поставим «1», в противном слу-
чае «0» (табл. 4.11).
После пересчёта можно получить вероятности проявления ГДЯ (табл. 4.12, правая часть).
Таблица 4.11
Дополнение переменной
Таблица 4.12
Метрика Махаланобиса (левая часть) и вероятности проявления ГДЯ (правая часть)
Значения метрик не изменились, вероятность появления ГДЯ (правая часть табл. 4.12) рассчитана для первого и второго множества (Gr1_0 с нулевыми значениями кодов и Gr2_1 с кодом, равным единице). Для отображения вероятности проявления выбросов достаточно одного столбца Gr2_1. Скопируем его в исходную таблицу и в геоинформационной системе в коорди-
113
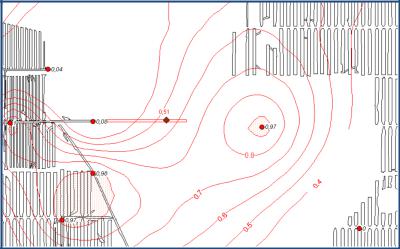
натах рудника выведем вероятности проявления ГДЯ. Из рис. 4.14 видно, что на проектном участке разработки пройдена подготовительная выработка и произведён отбор бороздовой пробы. На рис. 4.14 она показана ромбом. Произведены и лабораторные исследования пробы, определены значения основных компонентов.
Рис. 4.14. Изолинии вероятности появления газодинамических явлений (показаны вероятности от 0,4 до 1)
В ходе проведения ДА, когда вычислены все необходимые статистики по таблице исходных данных (говорят «после обучения») и доказана состоятельность дискриминации, появляется возможность прогнозировать уровень риска ГДЯ для новых данных или планируемых участков горных работ. Прогноз можно выполнить, дописывая в конец таблицы исходных данных новые наблюдения. Дополнения выполняются, например, при помощи контекстного меню (правая кнопка мыши) и команды «Добавить наблюдение». При вводе новых данных уровень риска ГДЯ неизвестен, поэтому значение кода не указываем. После ввода загружаем процедуру ДА, инициируем кнопку «Апостериорные вероятности». Получаем значения ожидаемой вероят-
114
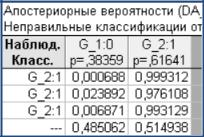
ности принадлежности пробы к той или иной группе уровня риска газодинамических проявлений. Результаты опробования заносим в исходную таблицу.
Проведём расчёты дискриминатного анализа, при этом исключаем новые данные для обучения ДФ (кнопка Select Cases). После выполнения дискриминантного анализа в строке «Классификация выбранных наблюдений» снимаем ограничения на использование строки 525 и выводим таблицу апостериорных вероятностей (табл. 4.13).
Таблица 4.13 Расчёты вероятностей для новых данных
В последней строке выведены расчёты для новой пробы. Вероятность появления ГДЯ в бороздовой пробе составляет величину, равную 0,51. Эта проба как раз лежит между изолиниями вероятностей 0,5 и 0,6. Её интерполированное значение вероятности (по изолинии на плане горных работ) составляет 0,54, что близко к расчётной величине. Таким образом, на горных участках, по мере увеличения вероятности проявлений ГДЯ, планом горных работ необходимо предусмотреть превентивные меры по снижению уровня выбросоопасности.
115

5.ФАКТОРНЫЙ АНАЛИЗ
5.1.Общие сведения
Вглаве, посвящённой каноническому анализу, мы рассматривали зависимости между двумя группами переменных.
Вотдельные группы мы объединяли близкие по смыслу переменные: геопространственные характеристики в одну и химический состав проб во вторую группу. Впоследствии каждая группа исходных переменных образовывала новую переменную, которая именуется канонической переменной. Канонические переменные, объединяющие исходные аргументы из каждой группы, несут обобщённую информацию о каждой группе [41].
Аналогичный подход используется и в дискриминантном анализе. Линейные дискриминантные функции также интегрируют всю информацию по исследуемым объектам. Но в этом методе ЛДФ служат для разделения объектов по наиболее отличающим признакам.
Воснове различных методов факторного анализа лежит следующее предположение: наблюдаемые и обрабатываемые переменные являются реальными, но они косвенно, через какието другие сущности, влияют на исследуемые явления или объек-
ты. На самом деле существуют внутренние (скрытые, не наблюдаемые непосредственно, их именуют латентными5) переменные. Количество латентных переменных невелико, но именно они и определяют наблюдаемые значения исходных данных. Латентные переменные именуют факторами.
Например, на защите выпускной квалификационной работы студент получает оценки от каждого члена комиссии – от специалистов по экономике, по горному профилю, по маркшей-
5 Латентность (от лат. latentis – «скрытый, невидимый») – свойство объектов находиться в скрытом состоянии, не проявляя себя явным образом.
116

дерскому обеспечению, по безопасности. Эти оценки есть отражение других, скрытых факторов, таких как усидчивость, мотивируемость, склонность к точным, естественным или иным видам деятельности. Такие понятия нельзя измерять и оценить непосредственно, но они связаны с усвоенными студентом зназнаниями, которые зафиксированы полученными оценками в процессе обучения.
Факторный анализ, как и ранее рассмотренные статистические методы, является частью многомерной статистики, и в процессе его проведения одновременно в анализе также используется несколько переменных. Между ними можно установить тесноту связей, вычислив матрицу корреляций. По величине коэффициентов корреляции переменные можно объединить в группы. Например, переменная X имеет высокую корреляцию (r = 0,71) c высотной отметкой кровли пласта Z (табл. 5.1). Тесно связаны и компоненты KCl и NaCl, корреляция которых достигает значения r = 0,48. С другими переменными у них слабая связь. Мы не ставим в пример корреляцию между отметками кровли и почвы пласта несмотря на то, что она слишком высокая, r = 0,99. Совместное использование сильно зависимых переменных приведёт к появлению мультиколлинеарности, избежать её поможет удаление одной из переменных.
Таблица 5.1
Матрица корреляций. Средние равны нулю, а дисперсия – единице
117
В рассмотренных примерах коррелированные переменные образуют некую новую группу – фактор. Как и в дискриминантном анализе, в факторном анализе (ФА) также применяется совокупность отдельных статистических методов. Основываясь на тесных связях анализируемых переменных и связях самих наблюдаемых объектов, факторный анализ позволяет выявить и обобщить скрытые механизмы изменения изучаемых объектов, исследуемых переменных и явлений.
Ранее указывалось, что в многомерном статистическом анализе используются нормированные переменные с нулевым средним и единичной дисперсией. Тогда сумма дисперсии в факторе будет равна количеству анализируемых переменных, по единице на каждую переменную. В процессе выполнения ФА сильно коррелируемые друг с другом переменные объединяются в один латентный фактор. По аналогии с регрессионным анализом составляется линейное уравнение, в котором фактор служит функцией, а сгруппированные в этом факторе переменные становятся аргументами. При этом происходит перераспределение дисперсии между переменными, служащими аргументами фактора. Если принять во внимание, что дисперсия каждой входной переменной составляет единицу, выстраивается довольно простая и наглядная структура влияния их на фактор. Внутри сгруппированных в фактор аргументов их взаимозависимость в составе фактора между собой будет выше, чем их коррелированность с переменными из состава других факторов. В ходе анализа горно-геологической ситуации на начальном этапе рассматривается влияние многих наблюдаемых переменных на изучаемые процессы горного производства, в этом случае особенно важно объединение нескольких исходных переменных в один фактор, несущий обобщённую информацию.
Каждая латентная переменная трактуется как некоторая причина взаимосвязи группы переменных. Состав наиболее влиятельных переменных этой группы позволяет объяснить назначение фактора. Например, анализируя геопространственные переменные и химический состав проб в факторном анализе, специалист получает значимые корреляции. Следовательно, он
118
может предположить, что существует некоторая интегрированная переменная – фактор геопространства, которая способна объяснить высокие корреляции признаков сходством полученных результатов.
5.2. Методы проведения факторного анализа
Основная идея факторного анализа заключается в выделении из всех исходных переменных небольшого количества факторов, причём каждый фактор рассматривается как функция от группы входных аргументов. Получается, что методы факторного анализа в практике горных инженеров, геологов и других исследователей используются для сжатия информации.
Следует отметить, коррелировать могут не только входные переменные Xj, но и сами объекты (наблюдения) ni. Поэтому поиск латентных факторов можно выполнять как по переменным, так и по объектам. Если некоторые объекты имеют значимые связи с достаточно большим числом входных переменных (m > 3), логично допустить и другое предположение: в анализируемых данных существуют компактные области точек (кластеры) в осях – «входные переменные – объекты наблюдений».
При этом новые оси обобщают уже не признаки Xj, а объекты ni, соответственно и латентные факторы Fr будут распознаны по составу наблюдаемых объектов:
Fr c1n1 c2n2 ... cnnn ,
где ci – вес объекта ni в факторе Fr.
В первом случае ФА используют R-методику факторного анализа. Она предусматривает вычисление коэффициентов корреляции между исходными переменными Хj. Во втором случае ФА применяется Q-технология, которая предусматривает расчёты корреляции между объектами (точнее, их состояниями, описываемыми векторами параметров).
Технология проведения ФА базируется на использовании редуцированной матрицы парных корреляций. Редуцированная
119
матрица – это матрица, на главной диагонали которой расположены не единицы, как в матрице корреляций, а их редуцированные, несколько уменьшенные величины. Уменьшение величины определяется тем, что в результате анализа будет объяснена не вся дисперсия изучаемых переменных, равная единице для нормированных данных, а ее некоторая часть, обычно значительная. Остаток (разница между единицей и объясняемой частью дисперсии) представляет необъясненную часть дисперсии, именуемую характерностью. Последняя возникает из-за специфичности наблюдаемых объектов или ошибок, допускаемых при регистрации явлений, процессов, т.е. ненадежности вводных данных.
В практике многомерного статистического анализа используется метод главных компонент (МГК). Он имеет схожий алгоритм и решает схожие с ФА аналитические задачи, но его не соотносят с ФА. Основное его отличие заключается в том, что обработке подлежит не редуцированная, а обычная матрица парных корреляций. Её главная диагональ заполнена единицами (а в матрице ковариаций – значениями дисперсии). В методе МГК пользователь ожидает объяснения всей дисперсии анализируемых признаков, остатки рассматриваются сами по себе, параметр, подобный статистике «характерность», в анализе отсутствует. Выявление наиболее влиятельных факторов и подбор факторной структуры исследуемого процесса наиболее целесообразно выполнять методом главных компонент. Его суть аналогична ФА – замена коррелированных переменных некоррелированными факторами. Ещё одна положительная черта этого метода – возможность ограничиться наиболее информативными главными компонентами и исключить остальные из анализа. Такой подход упрощает интерпретацию результатов. Считается, что он имеет математически обоснованную методологию проведения факторного анализа [12; 41; 78]. Вместе с тем его недостатком считают отсутствие выделения из общей дисперсии общей и уникальной составляющих [41].
При классификации методов ФА можно выделить следующие группы:
1. Метод главных компонент (Г. Хотеллинг).
120