

1.3. Понятие системы управления базами данных
Функционирование БД обеспечивается совокупностью языковых и программных средств, называемых системой управления базами данных (СУБД).
Система управления базами данных – совокупность языковых и программных средств, предназначенных для создания, ведения и использования базы данных многими пользователями [12].
Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры. Файлы, снабженные описанием хранимых в них данных и находящиеся под управлением СУБД, называются в свою очередь базами данных.
Создание и применение СУБД призвано к максимальному удовлетворению требований, предъявляемых к эффективным базам данных. Это приводит к необходимости решения вопроса централизованного управления данными.
Концепция централизованного управления данными имеет ряд неоспоримых преимуществ по сравнению с файловыми системами (см. прил.1):
1. Минимальная избыточность хранимых данных.
2. Непротиворечивость хранимых данных.
3. Многоаспектное использование данных.
4. Комплексная оптимизация.
5. Возможность стандартизации представления и обмена данными.
6. Возможность обеспечения санкционированного доступа к данным.
Но, предоставляя весомые преимущества, централизованное управление данными предъявляет к СУБД требование независимости данных от использующих их прикладных программ.
Современные СУБД реализуют централизованное управление данными и, кроме того, обеспечивают:
а) определение данных, подлежащих хранению в БД (определение логических свойств данных, соответствующих представлениям пользователя и называемых структурами данных в БД, а также физическая организация хранения данных, называемая структурами хранения БД);
б) первоначальную загрузку данных в БД – так называемое создание БД;
в) обновление данных;
г) доступ к данным по различным запросам пользователя, отбор и извлечение некоторой части БД, редактирование извлеченных данных и выдачу их пользователю. Перечисленные действия принято называть процессом получения справок из БД.
Специальные средства СУБД обеспечивают секретность данных, т.е. защиту данных от неправомочного воздействия, и целостность данных – защиту от непредсказуемого взаимодействия конкурирующих процессов, приводящих к случайному или преднамеренному разрушению данных, а также от отказов оборудования.
1.3.1. Обобщенная архитектура субд
Основной интерес применения СУБД заключается в том, чтобы предложить пользователям (или прикладным процессам) абстрактное представление данных, скрыв особенности хранения и управления ими.
Обобщенная структура связей программ и данных при использований СУБД представлена на рис. 1.1 [5].

Рис. 1.1. Связь программ и данных при использовании СУБД
СУБД должна предоставлять доступ к данным посредством прикладных программ любым пользователям, включая и тех, которые практически не имеют представления о:
1) физическом размещении в памяти данных и их описаний;
2) механизмах поиска запрашиваемых данных;
3) проблемах, возникающих при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
4) способах обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа;
5) поддержании баз данных в актуальном состоянии и множестве других функций СУБД [5, 8, 17].
При выполнении основных из этих функций СУБД должна использовать различные описания данных. Очевидно, что в таких описаниях обязательно должны быть учтены:
сущности интересующей предметной области;
атрибуты, характеризующие неотъемлемые свойства каждой сущности;
связи, ассоциирующие выделенные сущности.
С самых общих позиций, в архитектуре современных СУБД выделяют три уровня абстракции, т.е. три уровня описания элементов хранимых данных. Эти уровни составляют трехуровневую архитектуру, представленную на рис. 1.2, которая охватывает внешний, концептуальный и внутренний уровни [7].
Представленный подход к описанию данных предложен комитетом ANSI/SPARC (Комитет Планирования Стандартов и Норм Национального Института Стандартизации США) и имеет целью отделение пользовательского представления о базе данных от ее физической организации. Такое отделение обеспечивает независимость хранимых данных и применяется по следующим причинам.
Каждый пользователь должен иметь возможность обращаться к данным, используя свое представление о них, изменять свое представление о данных без влияния на представления других пользователей.
Пользователи не должны иметь дело с деталями физической организации данных, т.е. не должны зависеть от особенностей физического хранения данных.
Администратор базы данных (АБД) должен иметь возможность изменять структуру хранения данных в базе так, чтобы эти изменения оставались «прозрачными» для остальных пользователей.
Структура базы данных не должна зависеть от физических аспектов хранения, например, при переключении на новое устройство внешней памяти.
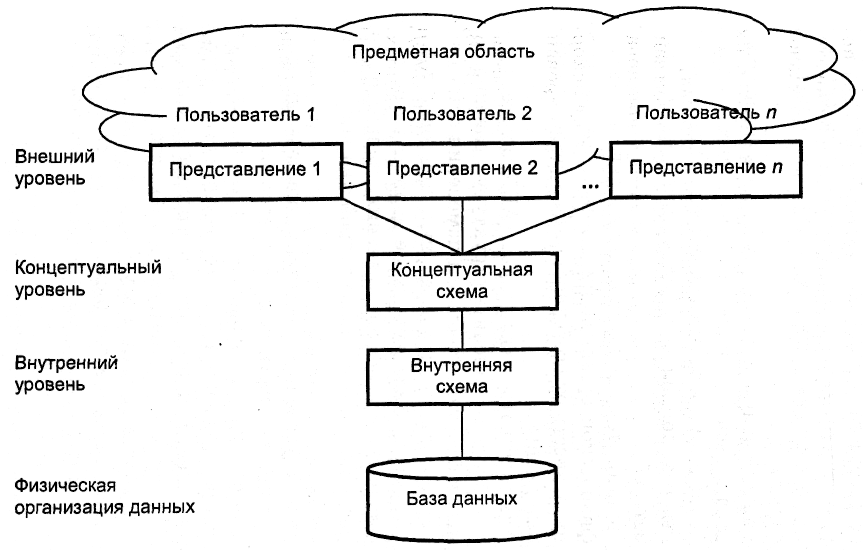
Рис. 1.2. Трехуровневая архитектура ANSI/SPARC
Внешний уровень – представление базы данных с точки зрения конкретных пользователей.
Указанный уровень может включать несколько различных представлений БД со стороны различных групп пользователей. При этом каждый пользователь имеет дело с представлением предметной области, выраженным в наиболее понятной и удобной для него форме. Такое представление содержит только те сущности, атрибуты и связи, которые интересны ему при решении профессиональных задач.
Различные представления на внешнем уровне могут пересекаться, т.е. использовать общие описания абстракций предметной области.
На внешнем уровне создается инфологическая модель БД (внешняя схема), полностью независимая от платформы (т.е. вычислительной системы, на которой будет использоваться). Инфологическая модель является человеко-ориентированной: средой ее хранения может быть память человека, а не ЭВМ. Инфологическая модель не изменяется до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Концептуальный уровень – обобщающее представление базы данных, описывающее то, какие данные хранятся в БД, а также связи, существующие между ними.
Концептуальный уровень является промежуточным в трехуровневой архитектуре. Содержит логическую структуру всей базы данных. Фактически, это полное представление требований к данным со стороны организации, которое не зависит от соображений относительно способа их хранения. На концептуальном уровне необходимо выделить:
1) сущности, их атрибуты и связи;
2) ограничения, накладываемые на данные;
3) семантическую информацию о данных;
4) информацию о мерах обеспечения безопасности.
Концептуальный уровень поддерживает каждое внешнее представление. Поэтому на этом уровне содержатся любые доступные пользователю данные, за исключением сведений о методах хранения этих данных.
На концептуальном уровне создается даталогическая модель (концептуальная схема БД), представляющая собой описание инфологической модели (внешней схемы) на языке определения данных конкретной СУБД. Эта модель является компьютеро-ориентированной (зависит от применяемой на компьютере СУБД).
Внутренний уровень – физическое представление базы данных, описывающее методы их хранения в вычислительной системе.
Данный уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Содержит описания структур данных и отдельных файлов, используемых для хранения данных в запоминающих устройствах.
На внутреннем уровне осуществляется взаимодействие СУБД с методами доступа операционной системы с целью эффективного размещения данных на носителях, создания индексов и т.д. На этом уровне используется следующая информация:
карта распределения дискового пространства для хранения данных и индексов;
описание подробностей сохранения записей (с указанием реальных размеров сохраняемых элементов данных);
сведения о размещении записей;
сведения о возможном сжатии данных и выбранных методах их шифрования.
Реализация перечисленной информации производится на физическом уровне вычислительной системы, который контролируется операционной системой. В настоящее время функции СУБД и операционной системы на физическом уровне строго не разграничиваются. В одних СУБД используются все предусмотренные в данной операционной системе методы доступа, в других применяются только основные и реализована собственная файловая система.
На внутреннем уровне создается физическая модель БД (внутренняя схема), которая также является компьютеро-ориентированной (зависит от СУБД и операционной системы). С ее помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным по именам, не заботясь об их физическом расположении. По этой модели СУБД отыскивает необходимые данные на внешних запоминающих устройствах.
Соответствующие трехуровневой архитектуре ANSI/ SPARC три уровня моделей данных для описания предметной области и реализации базы данных представлены на рис. 1.3 [5].
Для реализации рекомендаций ANSI/SPARC и выполнения сервисных функций, СУБД строится по модульному принципу и является сложным программным продуктом. Конкретный состав модулей и их взаимосвязей в реальных СУБД сильно различается, но можно выделить ряд их обобщенных компонентов.
Основные программные компоненты СУБД представлены на рис. 1.4 [7].
Процессор запросов. Это основной компонент СУБД, который преобразует запросы в последовательность низкоуровневых инструкций для контроллера базы данных.
Контроллер базы данных. Этот компонент взаимодействует с запущенными пользователями прикладными программами и запросами. Контроллер базы данных принимает запросы и проверяет внешние и концептуальные схемы для определения тех концептуальных записей, которые необходимы для удовлетворения требований запроса. Затем контроллер базы данных вызывает контроллер файлов для выполнения поступившего запроса. Компоненты контроллера базы данных показаны на рис.1.5 [7].