

9.9. Кластерный анализ
Пример 9.11.Рассмотрим выполнение кластерного анализа в системеSTATISTICAна классическом примере классификации автомобилей. Задача состоит в том, чтобы разбить автомобили известных марок на несколько однородных групп (например, три). Для решения этой задачи воспользуемся методомК средних.
Решение
1) В переключателе модулейSTATISTICAвыберите пунктКластерный анализ(ClasterAnalysis) и нажмите кнопкуПерейти (SwitchTo). На экране появится стартовая панель модуля (рис.9.82).

Рис. 9.82. Стартовая панель модуля Кластерный анализ
Нажав кнопку Данные(OpenData), откройте файлcars.sta, который находится в каталоге примеров (Examples) системыSTATISTICA(рис. 9.83).

Рис. 9.83. Таблица исходных данных
По строкам в файле данных записаны марки 22 машин – это наблюдения (case). По столбцам записаны характеристики машин, переменные (Variable):
PRICE– цена;
ACCELE– интенсивность разгона;
BRAKIN– эффективность торможения;
HANDLI– ресурс мотора;
MILAGE– расход горючего (миль/галлон).
Значения переменных в этом файле стандартизированы по формуле (8.9).
2) В списке методов стартовой панели модуля Кластерный анализвыберите методК средних(Kmeansclustering) и нажмите кнопкуOK. На экране появится диалоговое окно (рис.9.84).

Рис. 9.84. Окно задания параметров кластерного анализа
Выберите ВСЕ (All) переменные для анализа. Так как мы будем разбивать машины на группы, то в полеКластер(Claster) выберитеНаблюдения (строки) (Cases). Остальные опции установите, как показано на рис. 9.83. Нажав кнопкуOK,запустите вычислительную процедуру. В верхней части окнаРезультаты метода К средних(рис.9.85) отображается информация, не требующая комментариев.

Рис. 9.85. Окно результатов кластерного анализа методом К средних
Клавиши в нижней части окна позволяют провести детальный анализ результатов кластеризации. Чтобы посмотреть, как распределились машины по классам, нажмите клавишу Элементы кластеров и расстояния (Membersofeachcluster&distances). На экране появятся 3 таблицы с названиями машин, отнесенных к определенным кластерам (рис. 9.86 – 9.88).


Рис. 9.86. Список машин, включенных в кластер 1

Рис. 9.87. Список машин, включенных в кластер 2

Рис. 9.88. Список машин, включенных в кластер 3
В строках таблиц указано расстояние от каждого объекта (машины) до центра того кластера, в который он включен.
3) Чтобы посмотреть расстояния между центрами классов в диалоговом окне Результаты метода К средних, нажмите клавишуСредние классов и евклидовы расстояния (Clustermeans&Euclideandistances). Из таблицы (рис. 9.89) видно, что, например, расстояние между первым и вторым кластером равно 0,968956. Над диагональю в таблице даны квадраты расстояний.

Рис. 9.89. Евклидовы расстояния между кластерами
С помощью клавиши График средних (Graphofmeans) можно построить графики средних значений характеристик машин для каждого кластера (рис.9.90).
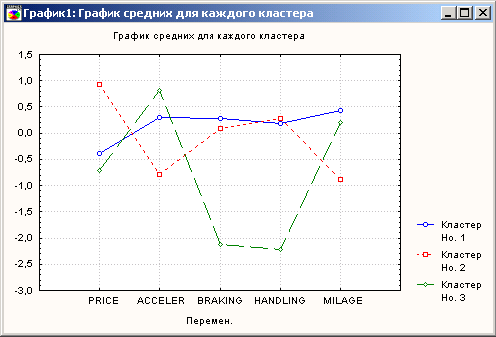
Рис. 9.90. Графики средних значений характеристик машин для каждого кластера
Как видно из графиков, в первый класс включены машины со средними (сбалансированными) характеристиками, во второй – дорогие машины, в третий – высокоскоростные. Таким образом, разбиение машин на классы можно считать выполненным.
Задания для самостоятельной работы
Вернитесь в диалоговое окно Кластеризация методом К-средних (рис. 9.84) и сократите количество переменных до трех:PRICE,ACCELE,MILAGE. Повторите кластерный анализ и сопоставьте результаты с предыдущими.
Вернитесь в стартовую панель факторного анализа Методы кластеризациии выберите режимОбъединение (древовидная кластеризация) (Joing(Treeclustering)). Пользуясь техническим руководством системыSTATISTICA, постройте дендрограмму, аналогичную приведенной на рис.9.91. Проанализируйте полученные результаты.

Рис. 9.91. График древовидной кластеризации (дендрограмма)