

Кластерный анализ
.docПрактическое занятие 3. Реализация методов кластеризации в среде Rapid Miner. Алгоритм k-means.
Кластерный анализ — задача разбиения выборки объектов на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались.
Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке.
Задача кластер анализа состоит в выяснении по эмпирическим данным, насколько элементы «группируются» или распадаются на изолированные «кластеры» (от cluster (англ.) — гроздь, скопление). Иными словами, задача — выявление естественного разбиения на классы, свободного от субъективизма исследователя, а цель — выделение групп однородных объектов, сходных между собой, при резком отличии этих групп друг от друга.
Цели кластеризации
-
Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
-
Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
-
Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
Формальная постановка задачи кластеризации
Пусть ![]() —
множество объектов,
—
множество объектов, ![]() —
множество номеров (имён, меток) кластеров.
Задана функция расстояния между
объектами
—
множество номеров (имён, меток) кластеров.
Задана функция расстояния между
объектами ![]() .
Имеется конечная обучающая выборка
объектов
.
Имеется конечная обучающая выборка
объектов ![]() .
.
Требуется
разбить выборку на непересекающиеся
подмножества, называемые кластерами,
так, чтобы каждый кластер состоял
из объектов, близких по метрике ![]() ,
а объекты разных кластеров существенно
отличались. При этом каждому
объекту
,
а объекты разных кластеров существенно
отличались. При этом каждому
объекту ![]() приписывается
номер кластера
приписывается
номер кластера ![]() .
.
Алгоритм
кластеризации —
это функция ![]() ,
которая любому объекту
,
которая любому объекту ![]() ставит
в соответствие номер кластера
ставит
в соответствие номер кластера ![]() .
Множество
.
Множество ![]() в некоторых
случаях известно заранее, однако чаще
ставится задача определить оптимальное
число кластеров, с точки зрения того
или иного критерия качества кластеризации.
в некоторых
случаях известно заранее, однако чаще
ставится задача определить оптимальное
число кластеров, с точки зрения того
или иного критерия качества кластеризации.
Кластеризация
(обучение
без учителя) отличается от классификации
(обучения
с учителем) тем, что метки исходных
объектов ![]() изначально
не заданы, и даже может быть
неизвестно само множество
изначально
не заданы, и даже может быть
неизвестно само множество ![]() .
.
Описание данных.
Исходными данными служат результаты исследования морфо-функционального состава слюны пациентов различных возрастных категорий. В исследовании участвовали 4 группы пациентов, которые были разбиты по следующим признакам:
- без патологии (группа контроля)
- обладающие патологией печени (цирроз)- 6 пациентов( 20-26).
- с заболеваниями желудочно-кишечного тракта
-пациенты, с диагностированной алкогольной зависимостью
В обследование каждого участника исследования входило изучение белкового состава слюны, анализ маркеров воспалительного процесса, а также установка индексов общего соматического состояния здоровья (индекс гигиены, индекс PMA).
Постановка задачи. Установить прогностическую значимость маркеров и параметров обследования - по имеющимся результатам обследования пациентов сформировать кластеры и установить распределение пациентов по классам, в зависимости от данных обследования (характеристик).
Алгоритм k-means
Для кластеризации данных будем использовать алгоритм k-means - наиболее популярный метод кластеризации. Был изобретён в 1950-х годах математиком Гуго Штейнгаузом и почти одновременно Стюартом Ллойдом.
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
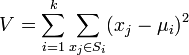
где ![]() — число кластеров,
— число кластеров, ![]() — полученные кластеры,
— полученные кластеры, ![]() и
и ![]() —
центры масс векторов
—
центры масс векторов ![]() .
.
Алгоритм разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множество конечно, а на каждом шаге суммарное квадратичное уклонение V уменьшается, поэтому зацикливание невозможно (рисунок 1).

Рисунок 1. Алгоритм k-means.
Порядок выполнения работы:
Начало работы
-
Запустите программу RapidMiner.
-
Загрузите данные обследования пациентов. Для этого импортируйте данные с листа Excel (рисунок 2).

Рисунок 2
2.1. Выберите путь к файлу: Z:\Весна20122013\Задания\DataMining\Practic_3\Stomat.xls
2.2. Выберите лист с данными (лист 1), нажмите next.
2.3. В появившемся окне с данными: первая строка – названия столбцов (задайте категорию name, как на рисунке 3), нажмите next.
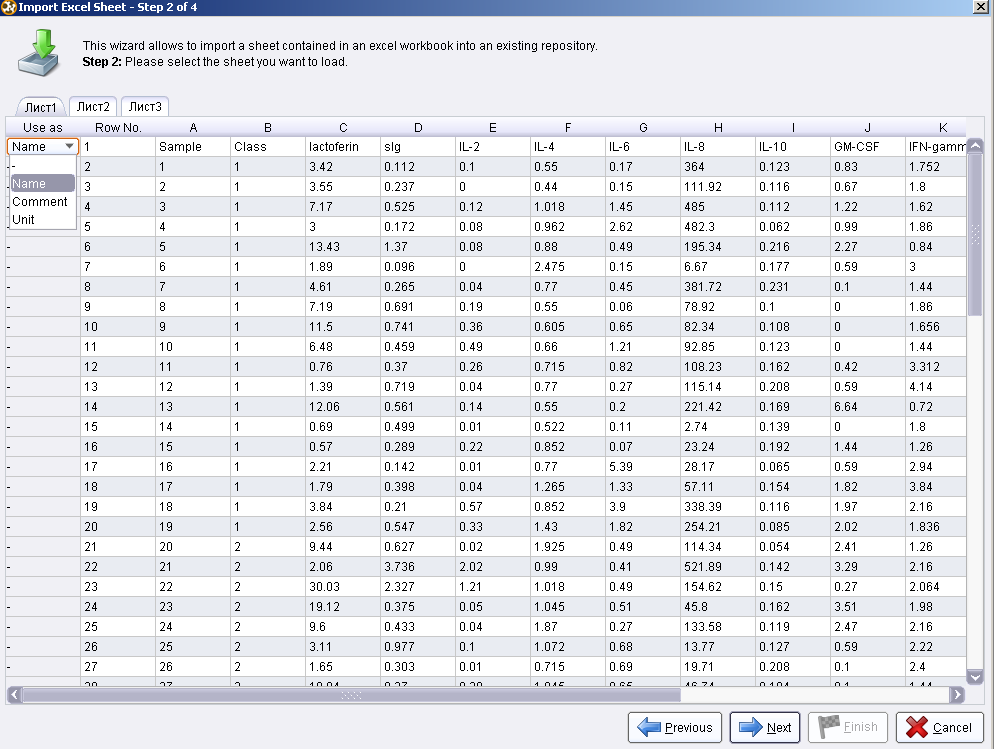
Рисунок 3
-
Установите типы данных
-
для порядкового номера вид данных id
-
остальные данные являются атрибутами
-
для качественных данных уставите тип данных nominal
-
для целых значений – integer
-
для значений с плавающей точкой – real
Установить типы данных можно также с помощью кнопки

(В этом случае система сама установит рекомендуемые типы данных).
Внимание! Первый столбец с порядковым номером пациента (Sample) должен иметь тип id – это позволит идентифицировать в системе каждого пациента (рисунок 4)..

Рисунок 4.
После установки типов данных, нажмите кнопку Next.
-
Сохраните данные в Вашем репозитарии в папке Data под именем Practice_3.
Изучение данных.
-
Изучите полученные данные: запустите оператор Retrieve, в окне

Выберите загруженный набор данных Practice_3. Соедините выход оператора с ires, запустите процесс.
-
Перейдите на вкладку Example Set(Retrieve) – рисунок 5.
-

Рисунок 5.
-
Для каждой переменной выпишите среднее значение, стандартное отклонение, максимальное и минимальное значения (Range).
Внимание! Вы можете воспользоваться мастером экспорта данных, для этого: на этой же вкладке нажмите значок экспорта, выберите соответствующую команду (рисунок 6).

Рисунок 6.1.
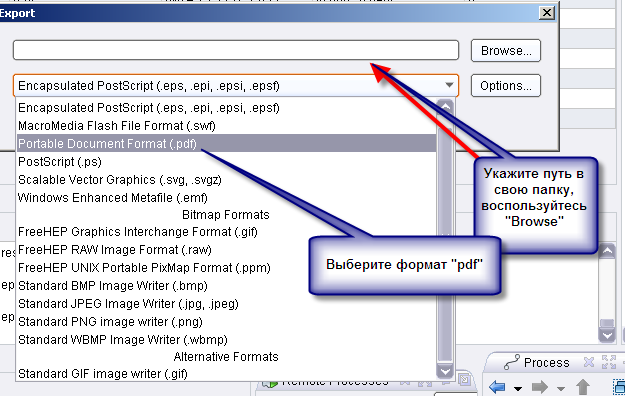
Рисунок 6.2.
-
Вернитесь в окно моделирования, нажмите
 .
.
Кластерный анализ
-
Создайте новый процесс, выберите оператор Retrieve, загрузите набор данных Practice_3
-
Для того, чтобы убедиться, что разделение данных на кластеры не зависит от размаха переменных, воспользуемся инструментом нормализации. Выберите в списке операторов соответствующий оператор Normalize (рисунок 7) и подключите его к оператору Retrieve.

Рисунок 7.1

Рисунок 7.2.
-
Выберите оператор Сlustering k-mean (рисунок 8).Установите kравное 4.
-
Выберите оператор ClusterDistancePerformance, (рисуное 8)
i

Рисунок 8.
12. Соедините операторы, обратите внимание, что оператор Clustering имеет два выходных порта «Clu», верхний порт «Сlu» оператора Clustering нужно соединить с портом «Сlu» оператора Performance, а нижний порт «Сlu» оператора Clustering нужно соединить спортом «exa» оператора Performance, у вас получится перекрестное соединение (рисунок 9).

Рисунок 9.
13. Соедините все выходные порты оператора Performance c портами «res» основного окна, если все правильно сделано, то у вас получится следующая цепочка операторов(рисунок 10)

Рисунок 10.
14. Запустите процесс. Сохраните результаты.
15. Изучите полученные данные

Просмотрите вкладки в окне с результатами и ответьте на вопросы:
-
Какие объекты попали в кластер?
-
Укажите расстояние между классами и расстояние внутри каждого класса?
-
Скопируйте таблицу с результатами с помошью мастера экспорта, насколько точно сработал алгоритм?
-
Сформулируйте выводы и составьте отчет.