

Лабораторная работа №5
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №5
по дисциплине
«Управление данными»
Москва 2023
Оглавление
Цель работы 2
Ход лабораторной работы 2
Вывод 18
Цель работы
Ознакомиться с методами кластеризации модуля Sklearn
Ход лабораторной работы
Создадим Python скрипт и загрузим данные в датафрейм.

Рисунок 1 – Загрузка датафрейма
Проведем кластеризацию методов k-средних

Рисунок 2 – Кластеризация
Получим центры кластеров и определим какие наблюдения в какой кластер попали
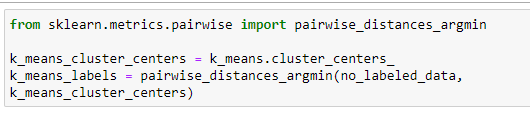
Рисунок 2 – Центры кластеров
Построим результаты классификации для признаков попарно (1 и 2, 2 и 3, 3 и 4)

Рисунок 3 – Код

Рисунок 4 – Полученный результат
Опишием полученные результаты и то, по каким из признаков произошло наилучшее разделение, а также как именно влияет значение параметра n_init
Самое лучшее разделение было осуществленно по 1 и 2 признаку, так как для других признаков, как видно из графиков, количество кластеров следовало было взять 2, а не 3. Это субъективная оценка, для оценки лучше использовать более объективный метод, а именно - подсчет ошибки в зависимости от объема кластера.
n_init - это количество раз, когда изначальные позиции центроидов будут инициализированы с разными сидами. Чем больше, те результат более точный, то есть не зависим от случайности. Особенно это важно, если в качестве метода инициализации был выбран random, а не kmeans++.
Уменьшим размерность данных до 2 используя метод главных компонент и нарисуем карту для всей области значений, на которой каждый кластер занимает определенную область со своим цветом

Рисунок 5 – Код
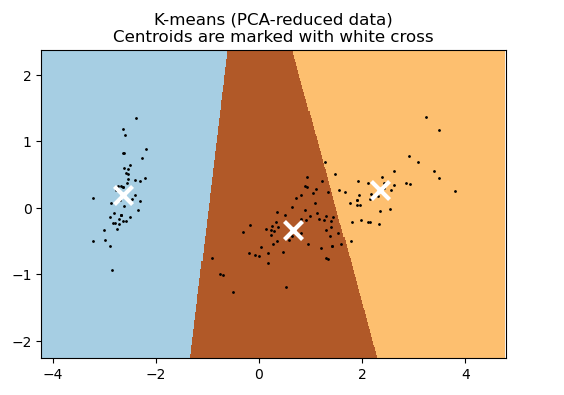
Рисунок 6 – Полученный результат
Исследуем работу алгоритма k-средних при различных параметрах init. Сначала надо выполнить несколько раз с параметров 'random', затем для вручную выбранных точек

Рисунок 7 – Код
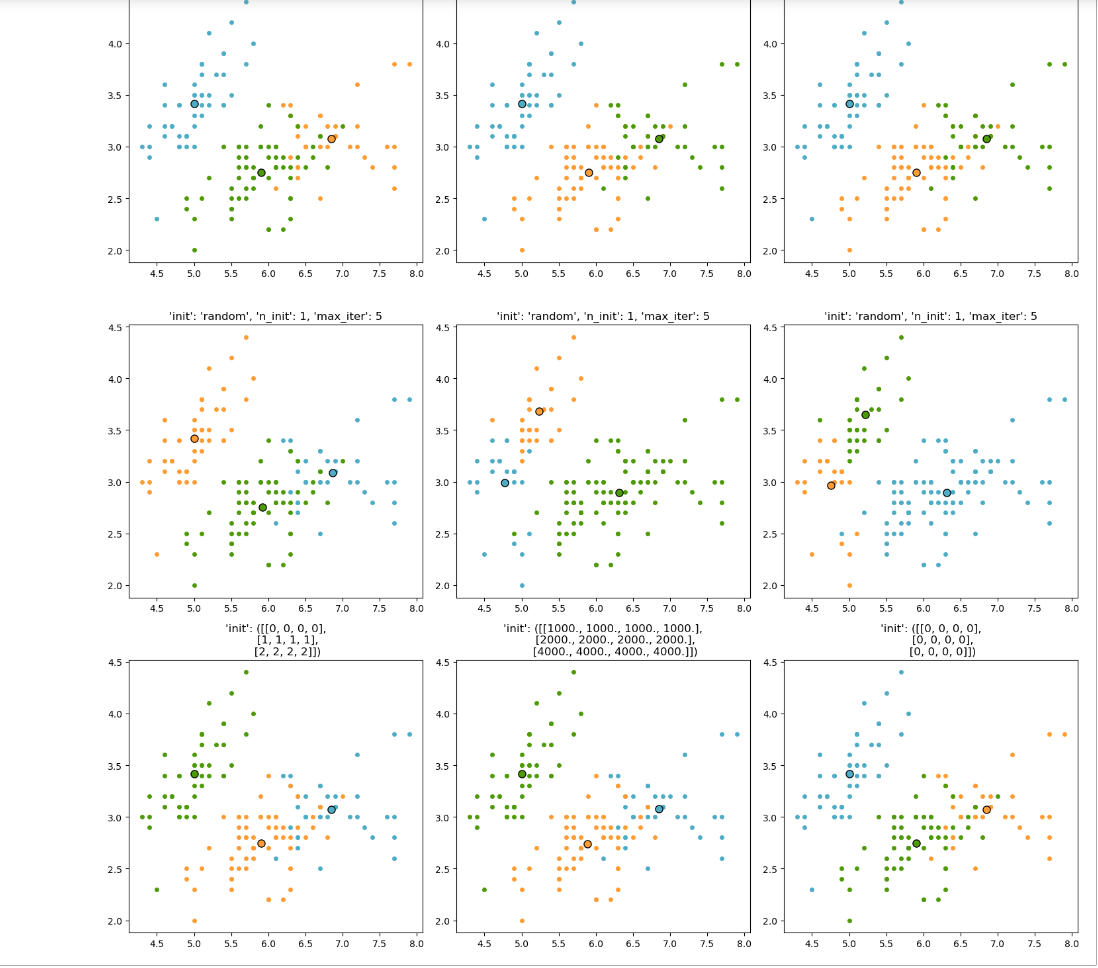
Рисунок 8 – Полученный результат
Определим наилучшее количество методом локтя

Рисунок 9 – Код

Рисунок 10 – Полученный результат
Проведем кластеризацию используя пакетную кластеризацию k-средних. В чем отличие от обычного метода k-средних. Построим диаграмму рассеяния, на которой будут выделено точки, которые для разных методов попали в разные кластеры
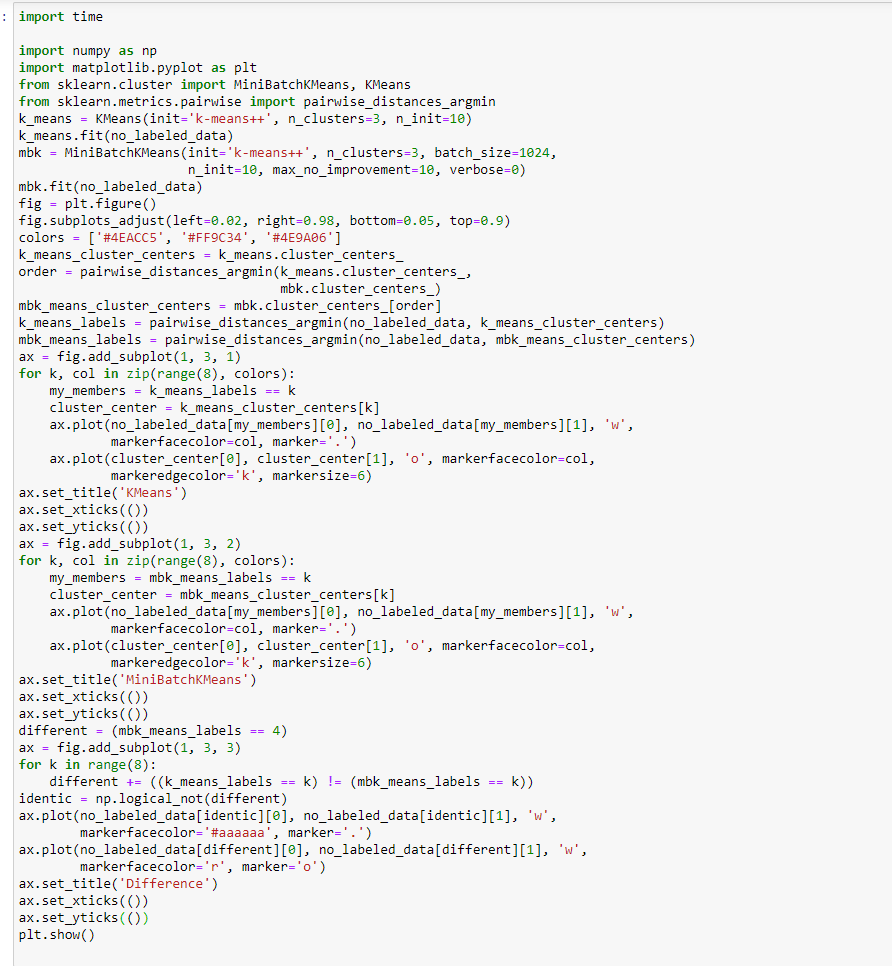
Рисунок 11 – Код

Рисунок 12 – Полученный результат
Отличие пакетной от обычной кластеризации заключается в том, что первая быстрее, так как при расчетах опирует случайной группой (batch) значений, а не каждой отдельно взятой точкой.
Проведем иерархическую кластеризацию на тех же данных

Рисунок 13 – Код
Отобразим результаты кластеризации
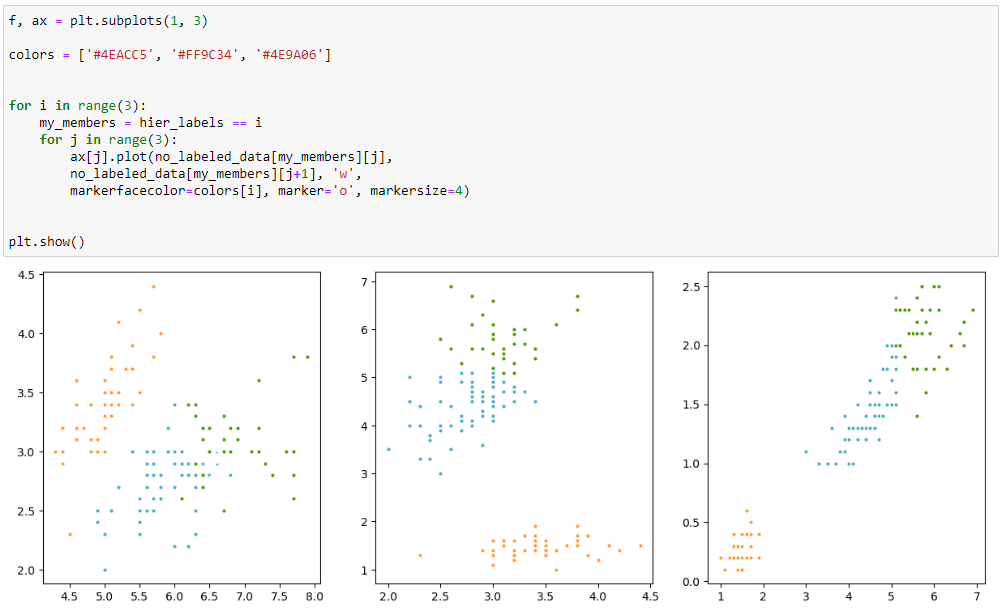
Рисунок 14 – Полученный результат
Проведем исследование для различного размера кластеров (от 2 до 5). Приведем полученные результаты
Рисунок 15 – Код
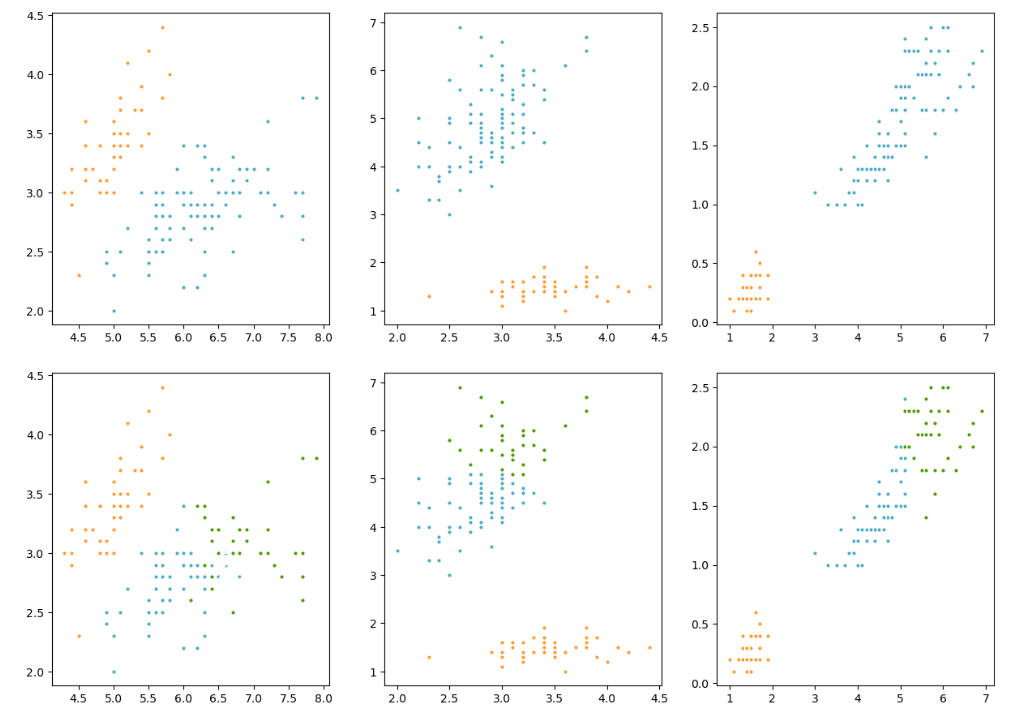
Рисунок 16 – Полученный результат
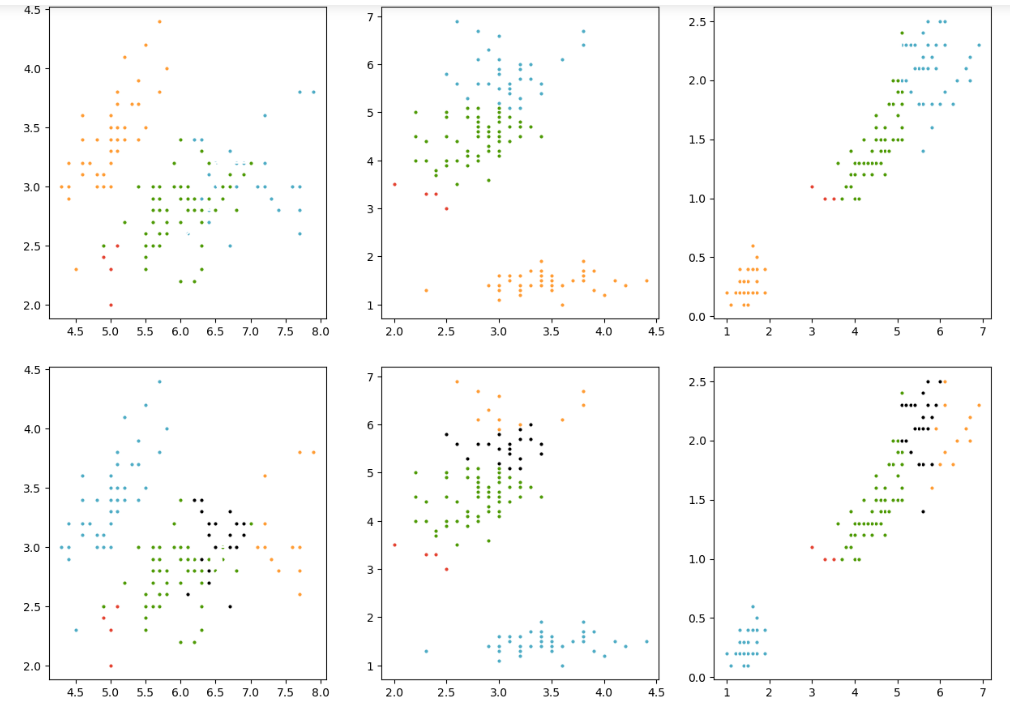
Рисунок 17 – Полученный результат
Нарисуем дендограмму до уровня 6

Рисунок 18 – Код
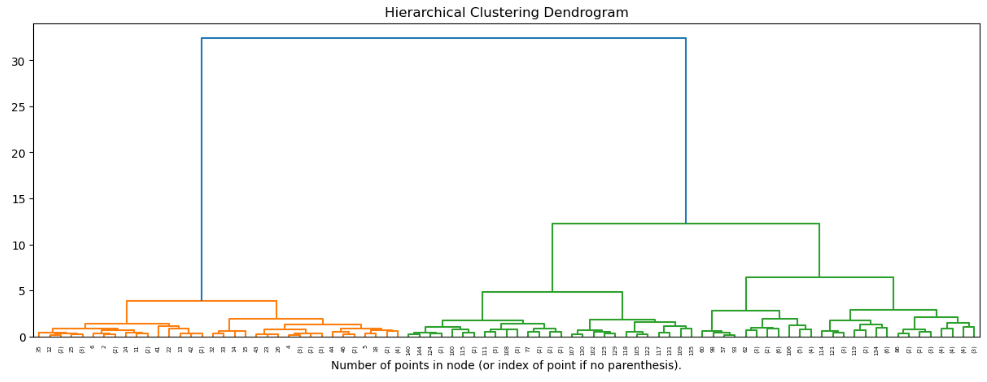
Рисунок 19 – Полученный результат
Сгенерируем случайные данные в виде двух колец

Рисунок 20 – Код
Проведем иерархическую кластеризацию

Рисунок 21 – Код

Рисунок 22 – Код

Рисунок 23 – Полученный результат
Исследуем кластеризацию при всех параметрах linkage. Отобразите и обоснуйте полученные результаты. Для каких случаев, какой тип связи работает лучше всего.

Рисунок 24 – Код
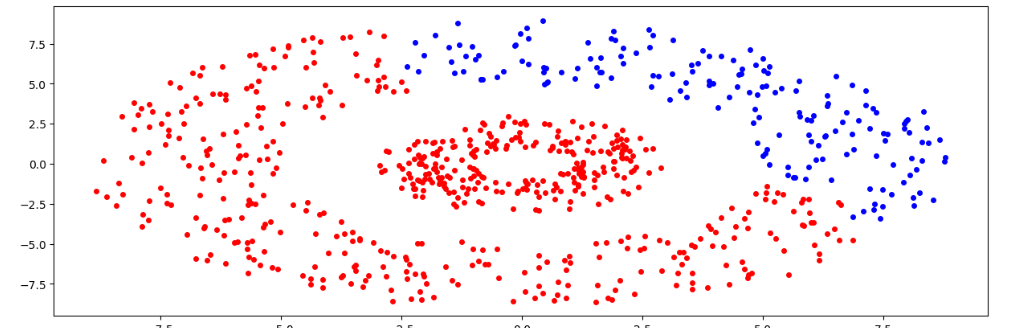
Рисунок 25 – Полученный результат
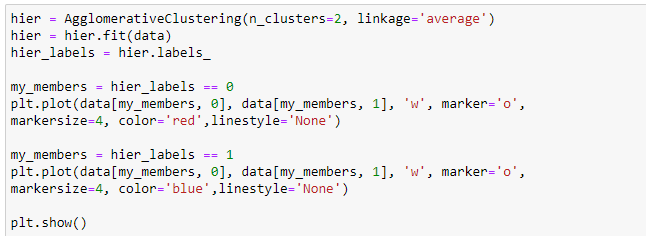
Рисунок 26 – Код
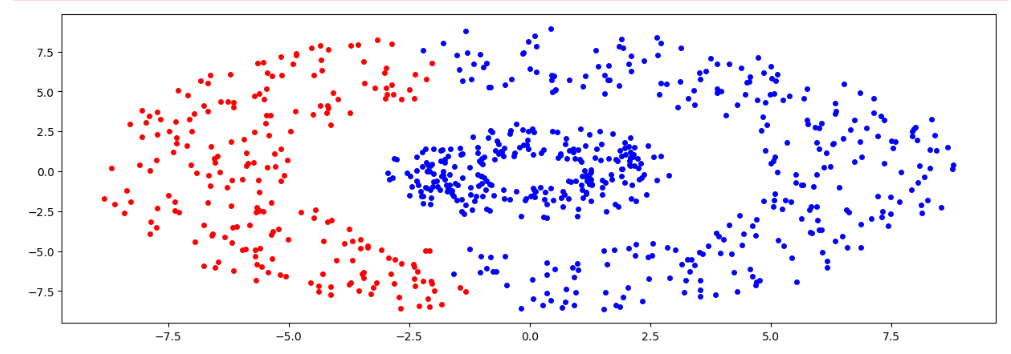
Рисунок 27 – Полученный результат

Рисунок 28 – Код
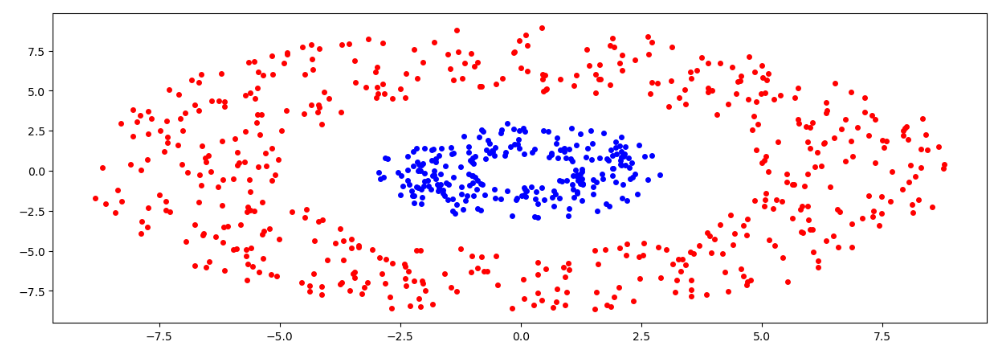
Рисунок 29 – Полученный результат
Можно сделать следующие выводы: для двух колец больше подошел метод линковки 'single'.
ward минимизирует дисперсию двух сливаемых кластеров
average использует среднее расстояний каждого наблюдения в двух кластерах
complete испольует максимум расстояний между всеми наблюдениями в двух кластерах
single испольует минимум расстояний между всеми наблюдениями в двух кластерах
Single хорошо подходит для кластеров не шарообразной формы, а также для больших датасетов (так как работает быстро). Ward лучше использовать для кластеров более-менее одинаковых размеров.
Вывод
Ознакомился с методами кластеризации модуля Sklearn