

Лабораторная работа №2
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №2
по дисциплине
«Управление данными»
Москва 2023
Оглавление
Цель работы 2
Ход лабораторной работы 3
Вывод 12
Цель работы
Ознакомиться с методами понижения размерности данных из библиотеки Scikit Learn
Ход лабораторной работы
Создать Python скрипт. Загрузить датасет в датафрейм, и разделить данные на описательные признаки и признак отображающий класс.
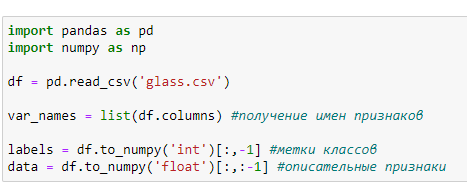
Рисунок 1 - Код
Провести нормировку данных к интервалу [0 1]
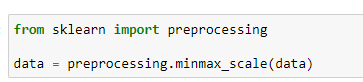
Рисунок 2 - Код
Построить диаграммы рассеяния для пар признаков. Самостоятельно определите соответствие цвета на диаграмме и класса в датасете.
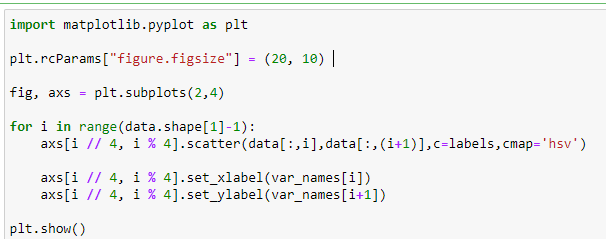
Рисунок 3 - Код
Построенные диаграммы представлены на рисунках 4 – 5
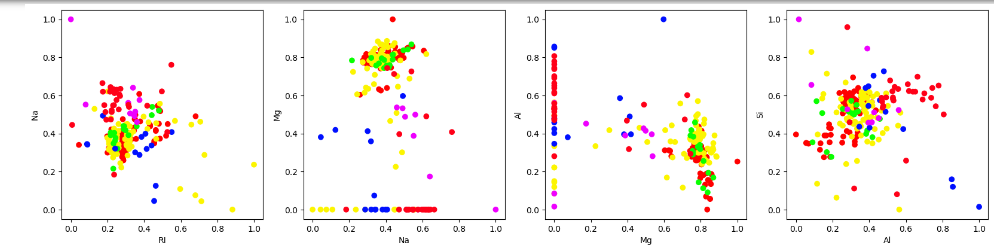
Рисунок 4 – построенные диаграммы
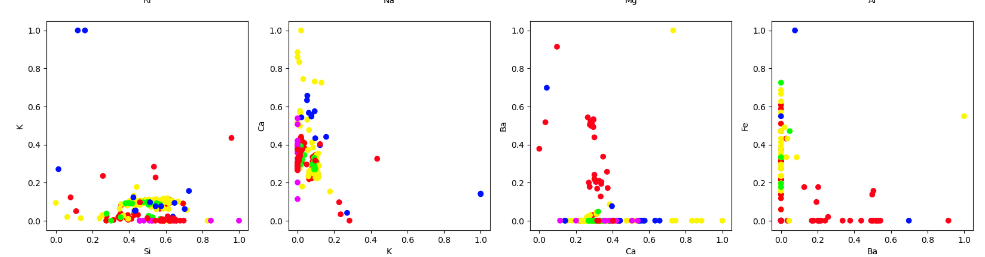
Рисунок 5 – построенные диаграммы
Чтобы определить цвет на диаграмме и класс в датасете, следует с помощью функции scatter пострить scatter-plot с использованием метки классов по label-ам:
Рисунок 6 - Метки классов по label-ам
Воспользуемся методом главных компонентов (PCA). Проведем понижение размерности пространства до размерности 2.
Рисунок 7 - Код
Далее выведем значение объясненной дисперсии в процентах и собственные числа соответствующие компонентам

Рисунок 8 – Полученный результат
Теперь необходимо построить диаграмму рассеяния после метода главных компонент.
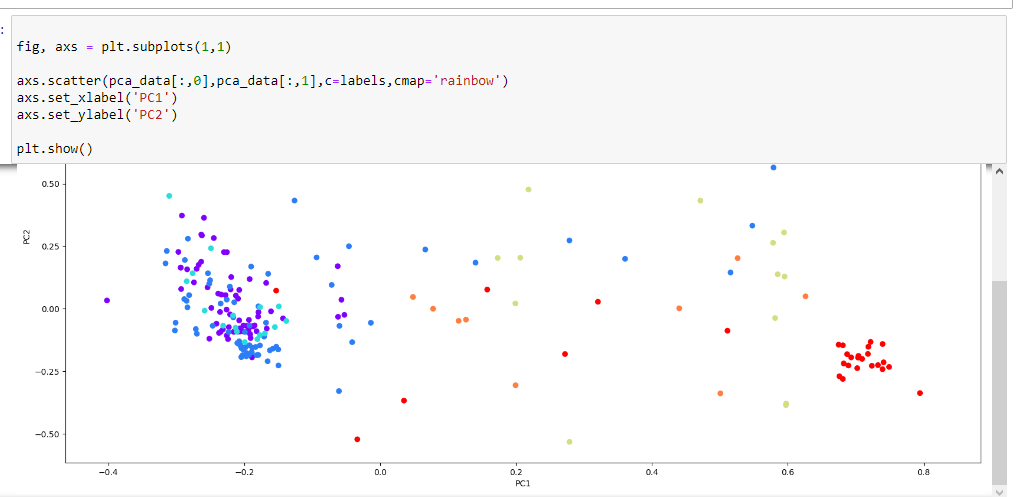
Рисунок 9 – Полученный результат
Просмотрев полученные результаты можно сделать следующий вывод:
Была обнаружена скученность данных в виде красных точек (тип 7 - headlamps) в правой части графика. Компоненты, до которых понизили пространство - PC1 и PC2. Это означает, что для красных точек (headlamps) более важной составляющей является PC1, чем PC2. Для типов же 1, 2, 3 PC1 не является важным компонентом.
Теперь же потребуется изменить количество компонент, определим количество при котором компоненты объясняют не менее 85% дисперсии данных. Для этого понадобилось 4 компоненты.
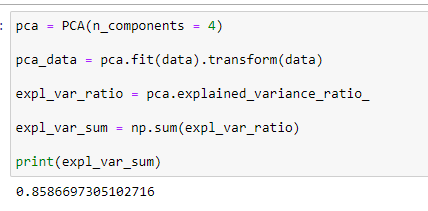
Рисунок 10 – Полученный результат
Воспользуемся методом inverse_transform восстановим данные, сравним с исходными. Рассмотрев их можно сказать, что эти данные похожи на изначальные, но не полностью. Причиной этого является то, что при инверсии не учитывались компоненты, которые ответственны за 15% процентов дисперсии и именно поэтому появляется эта разница.
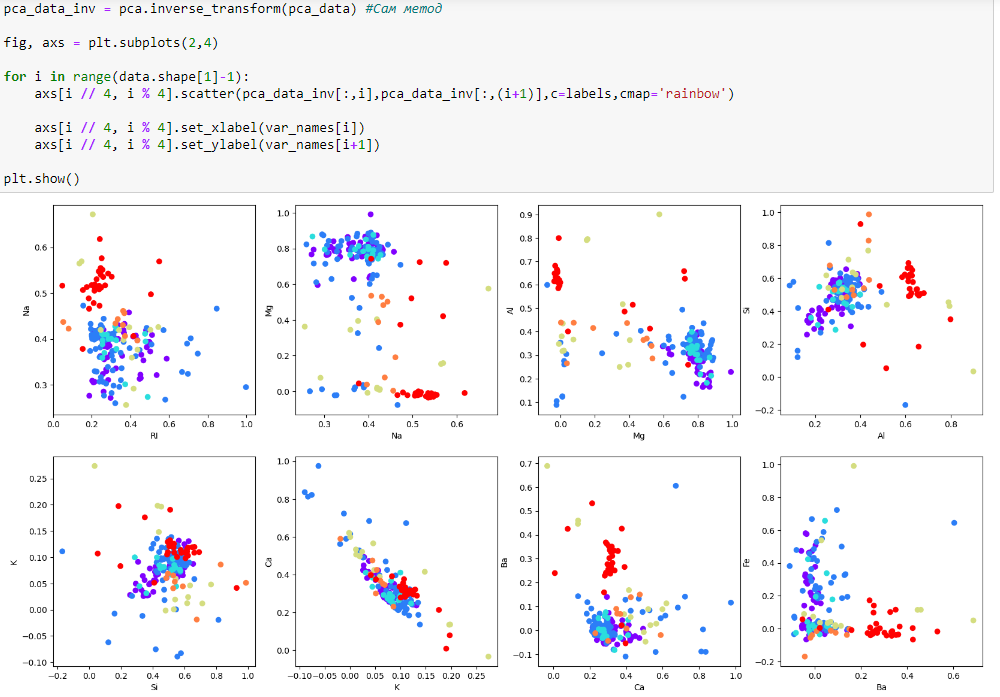
Рисунок 11 – Полученный результат
Теперь же исследуем метод главных компонентов при различных параметрах svd_solver. Следует сказать, что разница не была найдена по полученным результатам. Есть возможность, что сама разница заключается в скорости вычислений, так как как параметр svd_solver отвечает за метод SVD (Single Value Decomposition).

Рисунок 12 – Код

Рисунок 13 – Полученный результат
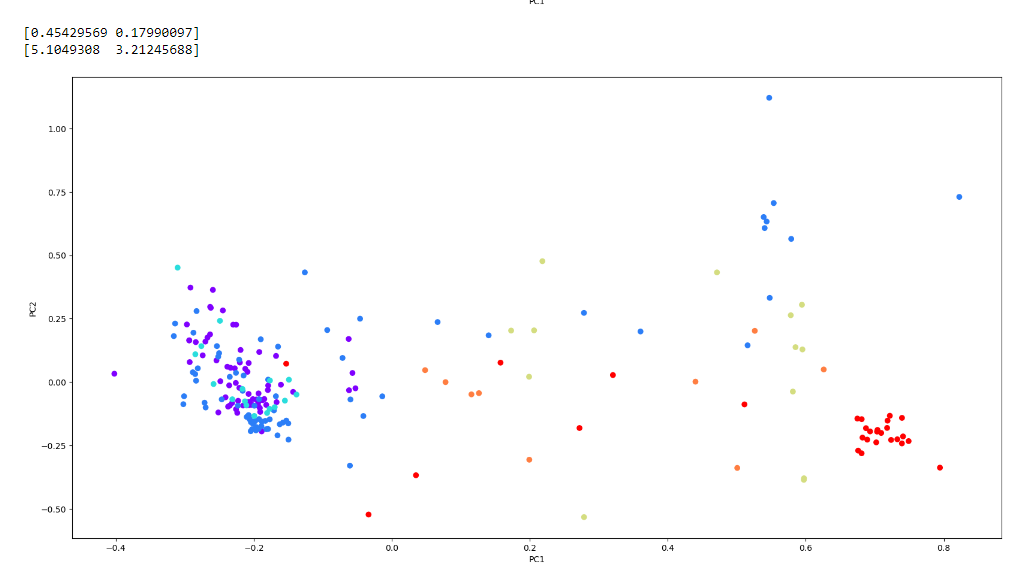
Рисунок 14 – Полученный результат
Рисунок 15 – Полученный результат
Аналогичным образом с PCA исследуем KernelPCA для различных параметров kernel и различных параметрах для ядра. Kernel PCA позволяет делать нелинейные преобразования над данными в отличие от PCA.
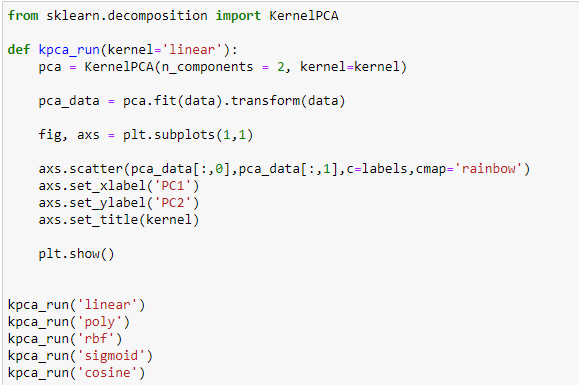 Рисунок 16 – Код
Рисунок 16 – Код
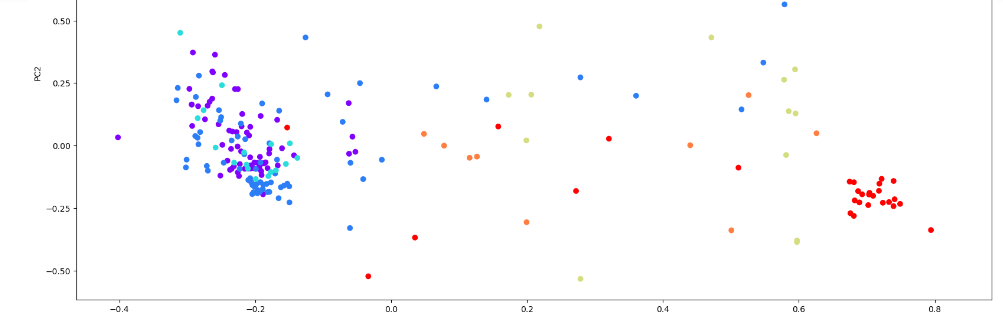
Рисунок 17 – Полученный результат

Рисунок 18 – Полученный результат

Рисунок 19 – Полученный результат
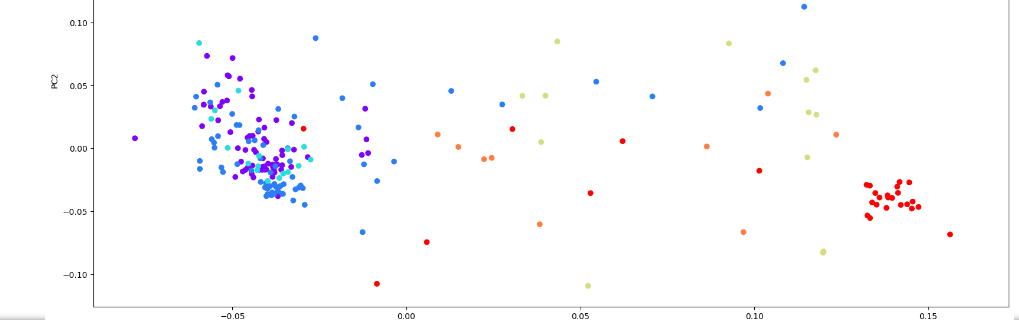
Рисунок 20 – Полученный результат
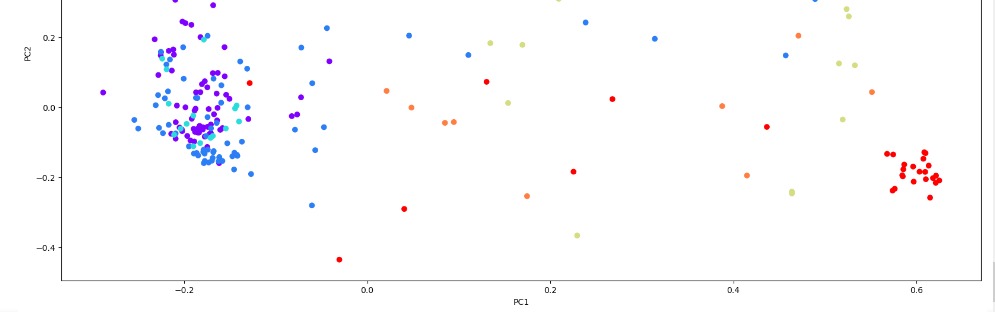
Рисунок 21 – Полученный результат
Понизим размерность используя факторный анализ FactorAnalysis.
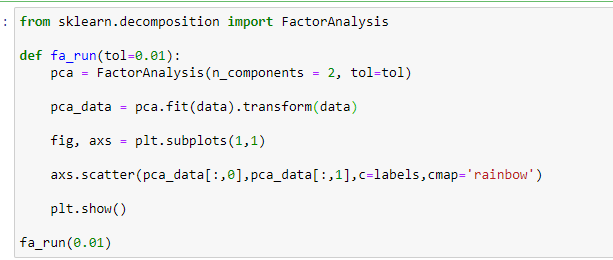
Рисунок 22 – Код
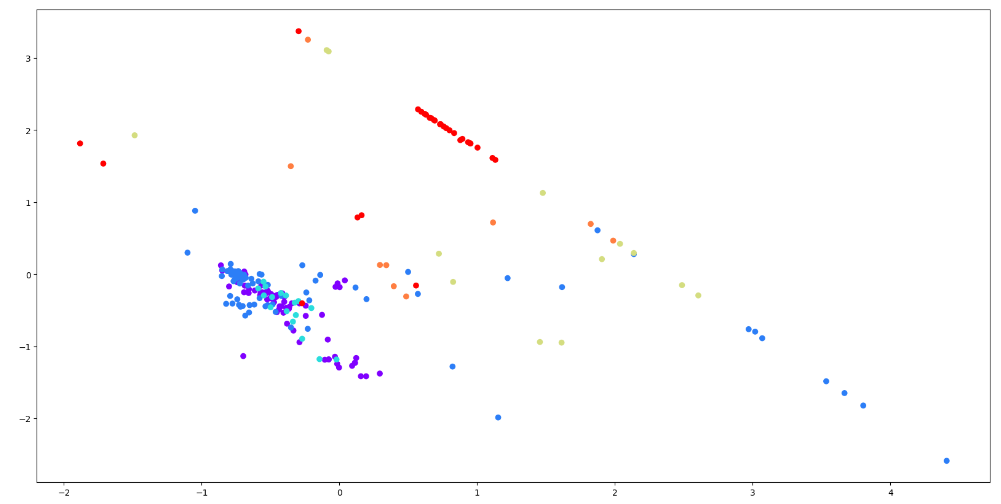
Рисунок 23 – Код
Вывод
Ознакомился с методами понижения размерности данных из библиотеки Scikit Learn