

Лабораторная работа №8
.docxМинистерство цифрового развития, связи и массовых коммуникаций
Российской Федерации Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное
учреждение высшего образования
Московский технический университет связи и информатики
Кафедра «Математическая кибернетика и информационные технологии»
Лабораторная работа №8
по дисциплине
«Управление данными»
Москва 2023
Оглавление
Цель работы 2
Ход лабораторной работы 3
Вывод 23
Цель работы
Ознакомиться с методами классификации модуля Sklearn
Ход лабораторной работы
Создадим Python скрипт и загрузим данные в датафрейм. Загрузим данные в датафрейм
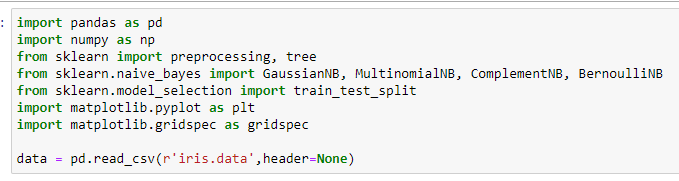
Рисунок 1 – Загрузка данных в датафрейм
Выделим данные и их метки

Рисунок 2 – Код
Преобразуем тексты меток к числам

Рисунок 3 – Код
Разобьём выборку на обучающую и тестовую

Рисунок 4 – Код
Проведем классификацию наблюдений используя LDA
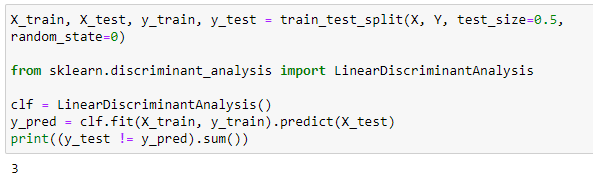
Рисунок 5 – Полученный результат
Используя функцию score() выведем точность классификации
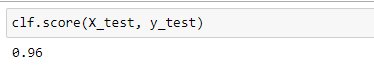
Рисунок 6 – Полученный результат
Построим график зависимости неправильно классифицированных наблюдений и точности классификации от размера тестовой выборки. Размер тестовой выборки изменяем от 0.05 до 0.95 с шагом 0.05.

Рисунок 7 – Полученный результат
Опишем для чего нужна функция transform. Применим ее, и визуализируем результаты.

Рисунок 8 – Полученный результат
Исследуем работу классификатор при различных параметрах solver, shrinkage.

Рисунок 9 – Полученный результат

Рисунок 10 – Полученный результат
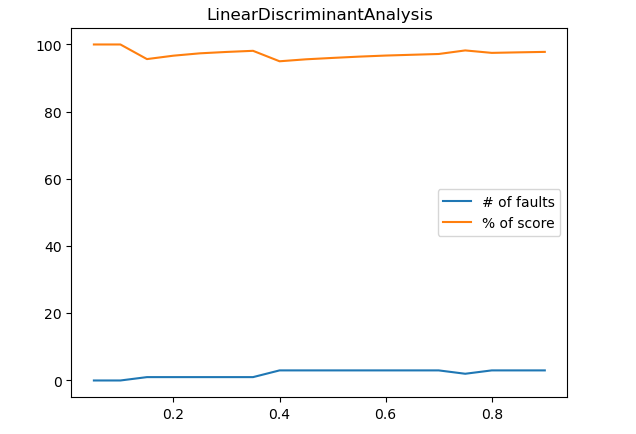
Рисунок 11 – Полученный результат


Рисунок 12 – Полученный результат

Рисунок 13 – Полученный результат
Задаем априорную вероятность классу с номером 1 равную 0.7, остальным классам зададим равные априорные вероятности
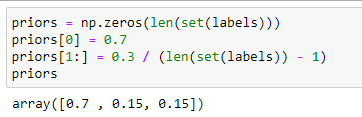
Рисунок 14 – Полученный результат

Рисунок 15 – Полученный результат
Классификацию при SVM на тех же данных
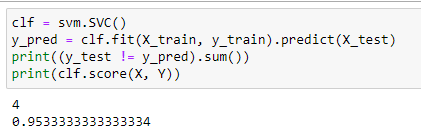
Рисунок 16 – Полученный результат
Используя функцию score() выведем точность классификации

Рисунок 17 – Полученный результат
Выведем следующую информацию

Рисунок 18 – Полученный результат
Построим график зависимости неправильно классифицированных наблюдений и точности классификации от размера тестовой выборки. Размер тестовой выборки изменяем от 0.05 до 0.95 с шагом 0.05. Параметр random_state сделаем равным номеру своей зачетной книжки. Обоснуем полученные результаты.

Рисунок 19 – Полученный результат
Исследуем работу метода опорных векторов при различных значениях kernel, degree,max_iter

Рисунок 20 – Полученный результат
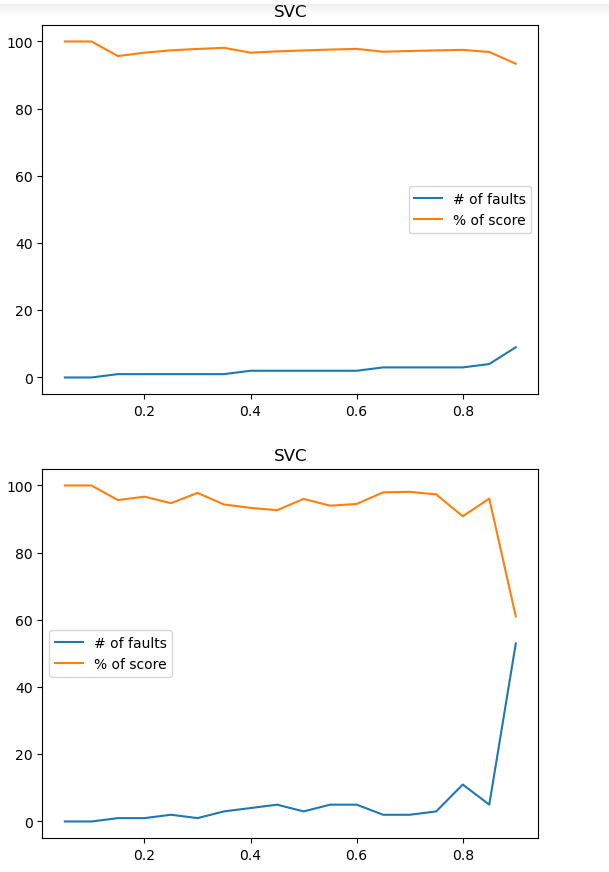
Рисунок 21 – Полученный результат

Рисунок 22 – Полученный результат

Рисунок 23 – Полученный результат

Рисунок 24 – Полученный результат
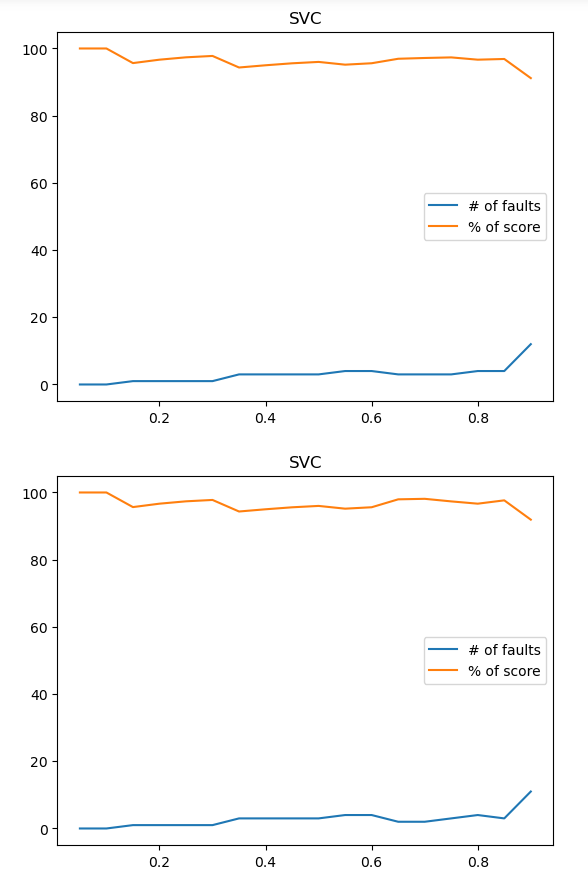
Рисунок 25 – Полученный результат
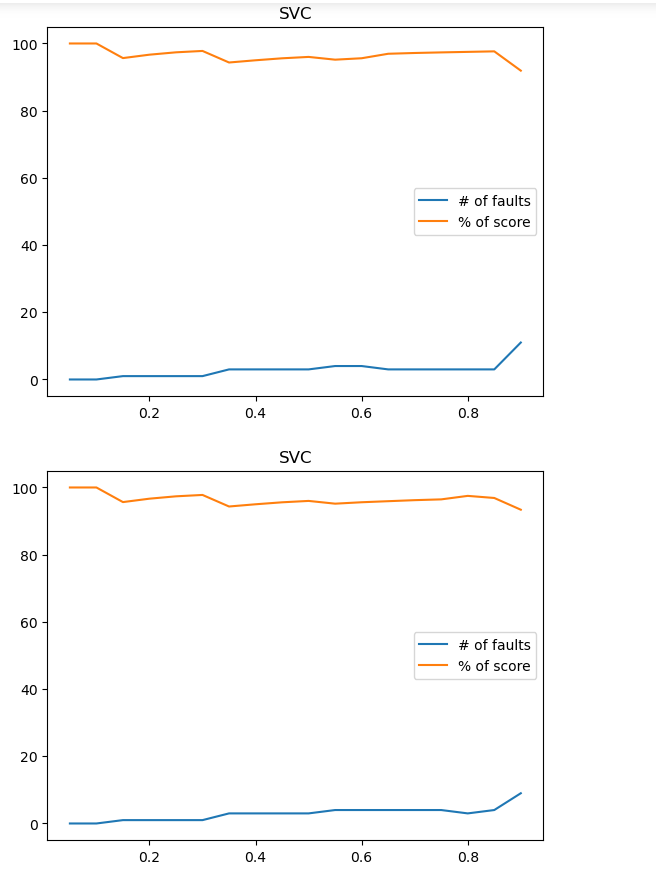
Рисунок 26 – Полученный результат

Рисунок 27 – Полученный результат
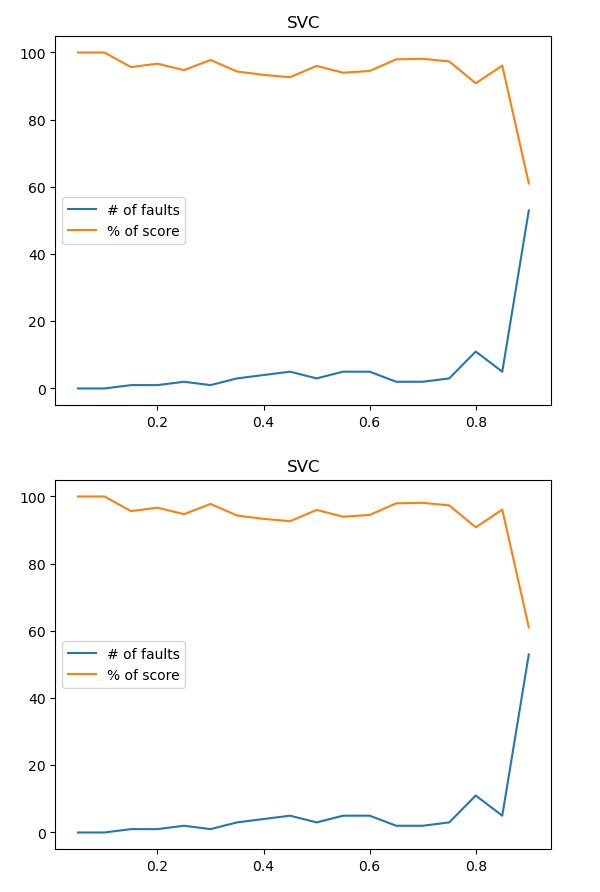
Рисунок 28 – Полученный результат
Проведем исследование для методов NuSVC и LinearSVC. В чем их отличие от SVC

Рисунок 29 – Полученный результат

Рисунок 30 – Полученный результат
Вывод
Ознакомился с методами классификации модуля Sklearn