

2023ВКР750301ИСАКОВ
.pdf2.3.4 Разведка данных
Для решения задач анализа и разработки моделей машинного обучения используется квадратная матрица, получившая название – кадр данных. В
зависимости от происхождения и способа регистрации данных, можно выделить две имманентные логические категории дефектов: внешние по отношению к пациенту и искажения, связанные с его поведением и биологией.
Внешние факторы объединяют под собой неисправности, природа происхождения которых связана с физическими явлениями и биохимическими процессами, лежащими в основе работы применяемых технических средств.
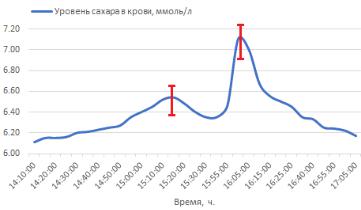
Так, в ходе исследования непрерывно регистрируются сигналы уровня сахара в крови малоинвазивным подкожным монитором Medtronic, ключевой частью которого является высокочувствительный платиновый сенсор. Как и в случае с другими биохимическими анализаторами, сенсор сталкивается с агрессивной биологической средой и со временем выходит из строя. Перед установкой монитора следует провести поверку и калибровку его характеристик. Не стоит забывать и то, что малоинвазивное устройство измеряет уровень глюкозы с ощутимой задержкой порядка 20 минут, в связи с тем, что глюкозе требуется время, чтобы накопиться в интерстициальной жидкости в достаточном для регистрации количестве (см. рисунок 12).
Рисунок 12 – Моделирование наложения кривых УСК с малоинвазивного монитора и персонального глюкометра
Помимо измерений, полученных с монитора, пациенты вручную вносят показатели мгновенного уровня сахара в периферической системе
51
кровообращения непосредственно до и спустя час после приема пищи. Для этих целей каждому участнику был выдан персональный глюкометр
AccuChek. Из-за различий в скорости накопления глюкозы в разных тканях,
прежде чем строить кривые наложения показателей сахара Medtronic и AccuChek, необходимо провести синхронизацию сигналов во времени. Более того, точность измерений глюкометра AccuChek может сильно пострадать при несоблюдении условий и методики взятия образца крови. Поверхность кожи,
контактирующая с биохимическим анализатором, должна быть предварительно очищена.
Последней технической проблемой является секвенирование рибосомальной РНК кишечной микробиоты 16SrRNA. Для этого используется библиотека кДНК (комплементарной ДНК). Каждая кДНК представляет собой фрагмент, фланкированный по обоим краям специальными адаптерами,
использующимися в процессе амплификации и секвенирования.
Амплификация концентраций выделенных фрагментов нуклеиновой кислоты происходит в ходе полимеразной цепной реакции (ПЦР). Метод позволяет достичь колоссального увеличения числа копий целевого участка. При этом его главное преимущество является и главным недостатком – разгерметизация контейнера, нарушение температурного режима или технологии ведет к увеличению числа прочтений мусорных копий в миллионы раз за несколько часов. Лучшая практика управления рисками предполагает использование ПЦР-анализаторов с максимально возможным количеством лунок на планшете, чтобы сократить количество прогонов на когорту анализов.
Внутренние по отношению к пациенту факторы описывают его поведенческие особенности, такие как ответственность, точность и пунктуальность. Так как исследование собирает большую часть показателей приема пищи и образа жизни через электронные дневники самонаблюдения и опросы, качество данных напрямую зависит от того насколько хорошо удалось до нести до участников их задачи и цели исследования. Как показывает практика работы с беременными, лучше всего просить их приходить на очный
52
прием к врачу с выданным глюкометром. Так специалист получит возможность сверить электронный дневник с фактической историей записей глюкометра.
Одна из наиболее часто встречающихся ошибок, которые можно устранить на очном приеме, состоит в том, что пациенты указывают любые измерения сахара до приема пищи как таковые полученные «натощак». В
действительности же, «натощак» считаются только те измерения, которые удалось зафиксировать утром, в промежутке от 8:00 до 9:00, после продолжительного ночного голодания.
Следующей категорией являются грубые фактические ошибки. К ним относятся:
•Пропуски или искажения времени измерения УСК. Оценивается как разница между временем, указанным в электронном дневнике, и временем фактического забора материала для анализа, сохраненном в памяти глюкометра. Допустимая разница не должна превышать 15 минут.
•Внесение данных приема пищи постфактум. Оценивается как разница между указанным и фактическим зафиксированным приложением временем внесения записи. Допустимая разница не должна превышать 45 минут.
•Невозможные величины, пропуски и занижение данных об основных приемах пищи. Достоверным свидетельством занижения можно считать среднесуточную энергетическую ценность менее 1000 ккал.
•Пропуски перекусов. Ошибка фиксируется по наличию необъясненного роста значений на кривой ППГО, зафиксированным монитором уровня глюкозы в плазме крови. Свидетельствовать о занижении предоставляемых данных может относительная представленность перекусов относительно основных приемов пищи (менее 10%).
•Недопустимые округления, как значений УСК, так и параметров приема пищи, например 250 гр. вместо 245.89 гр.
Кроме очевидных ошибок, встречаются и такие, зафиксировать которые можно только путем визуального анализа кривой ППГО. Для этих целей врачу
53
предлагается построить временные ряды и графики наложения кривых уровня глюкозы программными средствами Excel.
Наибольшую проблему для целей прогнозирования представляют отложенные приемы пищи. На графике они отображаются как двойной пик на кривой ППГО (см. рисунок 13). Такие кривые сахара получаются в результате наложения нескольких близкорасположенных во времени перекуса.
Например, сначала пациент съел здоровый обед (умеренная гликемическая нагрузка), а затем, с некоторой задержкой во времени, решил выпить латте со сладкой булочкой (высокая гликемическая нагрузка).
Рисунок 13 – Моделирование череды эксцессов на кривой ППГО
Если пациент измерил УСК в крови до основного приема пищи в 14:10,
но проигнорировал дополнительное измерение перед перекусом в 15:30,
предположив, что оба приема пищи укладываются в рамки обеденного времени – запись придется удалить. Отложенный прием пищи,
сформировавший череду эксцессов, затрудняет процесс оценки как абсолютных значений сахара, так и площади под кривой ППГО через шестьдесят или сто двадцать минут, т.к. последняя информация,
характеризующая углеводный обмен, была получена более часа назад.
Все дневники классифицируются по качеству от 0 до 2, где 0 – нет ошибок, 1 – присутствуют техногенные ошибки, 2 – присутствуют ошибки,
допущенные пациентом. Дневники категории 1 и 2 проходят частичную фильтрацию программными скриптами и экспертами, чтобы быть допущенными до следующего этапа исследования.
54
2.3.5 Предобработка данных
Учитывая особенности, выявленные в ходе разведки данных, составим алгоритм действий по работе с отфильтрованными дневниками наилучшего качества.
Во-первых, в данных присутствует значительное количество пропущенных значений (N/A – Not Assessed). В ряде случаев N/A можно с легкостью заменить на ноль. Так, в базе продуктов питания номинально присутствует порядка полусотни микронутриентов и макронутриентов, в то время как непосредственно в блюде большинство из них отсутствует.
Совершенно иначе дело обстоит с взаимосвязанными нутриентами, такими как общее число углеводов и моносахаридов или дисахаридов. В таком случае импутация пропущенного значения на ноль ведет к грубой ошибке.
Прежде чем произвести импутцию пропущенных значений признака,
необходимо убедиться в том, что столбец содержит не больше четверти N/A
от общего числа записей, в противном случае, грубая интерполяция значительно снизит точность прогнозирования. Аналогичный шаг можно предпринять и в отношении строк. Порог отсеивания пропущенных значений указан приблизительно и в действительности должен определяться относительной прогностической ценностью признака и общим числом строк.
Существует множество разных по своей сложности и эффективности алгоритмов импутации пропущенных значений. Самые простые из них берут порядковые значения (следующее/предыдущее) или статистические метрики
(усеченное среднее, мода, медиана) и вставляют их величины на место N/A.
Алгоритм слишком примитивен для работы с непрерывными величинами,
такими как число углеводов или пищевых волокон, но отлично подходит для импутации дискретных значений, например, возраст, срок беременности или число абортов. В основном данные были потеряны в результате неосторожной смены правил хранения. Визуальный анализ позволяет предположить, что в ходе перекрестного преобразования сырых данных к итоговому виду обучающей матрицы, пациенты выбирались упорядоченными когортами по
55
сроку их беременности на момент вступления в исследовательскую программу. Таким образом N/A значение срока беременности можно заменить ближайшим к нему следующим не пропущенным значением. Информацию о возрасте или числе абортов с большей статистической достоверностью удастся получить заменой N/A на робастные оценки усеченного среднего или медианы ранжированного ряда.
Для импутации пропущенных значений непрерывных переменных следует использовать методы, основанные на применение простых, т.е.
вычислительно недорогих, моделей машинного обучения. Среди наиболее популярных можно выделить:
•Метод ближайших соседей k-NN (k-Nearest Neighbors) или Hot Deck;
•Стохастическая регрессия;
•Метод опорных векторов;
•Многовариантное вменение признаков (MI – Multivariance Imputation).
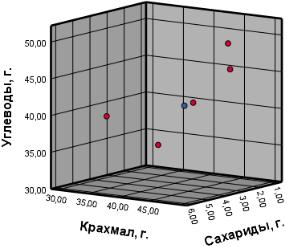
Так как каждому продукту в базе данных присвоена уникальная профилирующая категория, объединяющая когорту по принципу схожести состава и способа приготовления, можно предположить, что наилучших результатов удастся добиться методом k-NN. Так, при импутации неизвестного числа сахаридов в ржаном хлебе можно выделить известную подкатегорию злаковых продуктов и провести импутацию по трем ближайшим соседям в пространстве связанных признаков (см. рисунок 14).
Рисунок 14 – Трехмерная диаграмма рассеяния углеводов среди злаковых
56
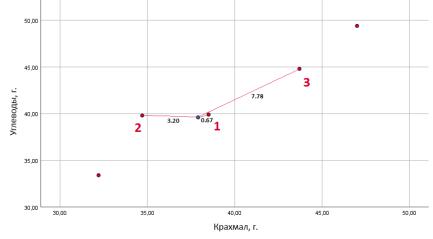
Перейдем в двумерную область для определения неизвестного количества сахаридов в исследуемом образце, представлен на скатерограмме рассеяния синей точкой (см. рисунок 15).
Рисунок 15 – Скатерограмма рассеяния углеводов относительно крахмала
Для решения задачи о поиске ближайших соседей воспользуемся Евклидовой метрикой расстояния ( , ), см. формулу (2.1).
|
( , ) = √ |
∑ |
( |
− )2 |
, |
(2.1) |
|
|
|
|
=1 |
|
|
|
|
где = ( , … , ) |
и = ( , … , ) |
– |
точки в многомерном |
||||
1 |
|
|
|
1 |
|
|
|
пространстве признаков.
Используя формулу 2.1, найдем = 3 ближайших к исследуемому
образцу соседей: 1 = 0,67; 2 = 3,20; 3 = 7,78.
Зная величину общего содержания моно и дисахаридов у ближайших
соседей ( 1 = 1,40; 2 = 5,10; 3 = 1,10), воспользуемся формулой (2.2) для вычисления средневзвешенного числа сахаридов ср.вз. в исследуемом образце.
|
|
∑=1 |
1 |
|
|
|
|
|
, |
(2.2) |
|||
|
ср.вз. = |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||
где |
– общее содержание моно и дисахаридов у -ого соседа; |
|
||||
– Евклидово расстояние до -ого соседа;
– число соседей.
57
Полученное средневзвешенное содержание сахаридов в ржаном хлебе составило 1,27 г., при реальном значении 1,70 г. Отметим, что непосредственно в данном примере, точность и производительность метода
Hot Deck была бы несколько выше (1,40 г. против 1,27 г.). Тем не менее метод крайне неустойчив к выбросам и в среднем показывает худшие результаты.
Следующая задача логично вытекает из предыдущей. В отличие от разных фракций углеводов, большинство прочих нутриентов имеют разные размерности: граммы, миллиграммы, микрограммы и т.д. Для большинства методов машинного обучения, основанных на анализе расстояний, например k-NN или SVR, совершенно необходимо стандартизировать систему измерений и провести масштабирование входных признаков. Есть несколько основных способов масштабирования:
•Нормализация (минимакс);
•Стандартизация (z-оценка);
•Десятичное масштабирование;
•Логарифмирование.
На практике нормализация и стандартизация имеют схожие области применения, но в задачах поиска оптимального вектора или минимума расстояний нелинейные методы масштабирования по z-оценкам применяется чаще, см. формулу (2.3).
′ = |
|
− ̅ |
|
|
|
|
, |
(2.3) |
|
|
|
|||
|
|
|
|
|
|
|
|
||
где и ′ – исходное и преобразованное значения признака;
̅ – выборочное среднее значение признака;
– среднеквадратическое отклонение от выборочного среднего.
Логарифмирование и десятичное масштабирование могут быть
использованы для преобразования многомиллионных чисел прочтений бактериальных признаков микробиоты кишечника в результате ПЦР реакции.
58
2.3.6 Регрессия опорных векторов
Алгоритм регрессии опорных векторов (SVR – Support Vector Regression) является адаптированным вариантом реализации одноименного алгоритма классификации с учителем (SVM – Support Vector Machine).
Оставаясь крайне гибким и универсальным в целом спектре решений задач машинного обучения (регрессия, классификация, кластеризация), метод сохраняет высокую надежность. В большинстве случаев его применяют в тех же целях, что и линейную регрессию, впрочем, SVR позволяет выявлять нелинейные взаимосвязи в многомерном пространстве признаков за счет использования разных функций ядра:
•Линейное ядро;
•Полиномиальное ядро;
•Радиальное (RBF – Radial Basis Function) или Гауссово ядро.
Гибкость подхода заключается в том, что на самом деле функция ядра может быть любой. Задача ядра, некоторым образом, спроецировать известные наблюдения в другое, обычно более высокое, измерение. Выше представлены лишь самые популярные из возможных вариантов.
Прежде чем адаптировать SVM для решения актуальных задач регрессии, постараемся разобраться в общих теоретических основах работы алгоритма для решения базовых задач о классификации нового наблюдения в n-мерном пространстве признаков.
Для простоты вычислений предположим, что мы имеем набор точек,
принадлежащих двум разным классам («синие» и «зеленые»). Необходимо,
некоторым образом, разделить эти классы так, чтобы сохранить возможность присвоения новому наблюдению метки одного из указанных подмножеств.
SVM предлагает найти некоторую гиперплоскость, кривую или линию в нашем случае, которая бы разделяла эти два класса. Разделяющая гиперплоскость должна пролегать таким образом, чтобы максимизировать расстояние между крайними точками двух подмножеств или, иначе говоря,
опорными векторами (см. рисунок 16) [55].
59
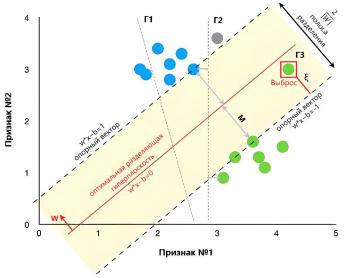
Рисунок 16 – Оптимальная разделяющая гиперплоскость для тренировочного набора данных
Нотации Г1, Г2 и Г3 обозначают гиперплоскости и их порядковые номера. В приведенном примере оптимальное разделение достигается только линией Г3, т.к. Г1 в принципе не дает корректного разделения, а Г2 имеет сравнительно небольшую величину полосы разделения. Так, если бы мы выбрали в качестве оптимальной разделяющей плоскости Г2, серая метка на графике была бы классифицирована как «зеленый» класс, в то время как она очевидно принадлежит к «синему» классу.
Классификация происходит на основании вычисления отступа
наблюдений от разделяющей классы границы, см. формулу (2.4) [56].
= ( − ) , |
(2.4) |
где – метка класса, может принимать значения −1 и 1;
– объект наблюдения;
и – искомые гиперпараметры модели, характеризующие положение разделяющей гиперплоскости, при этом = (1 … ) и = −0.
В случае если ≥ 1, исследуемый объект находится на удалении или непосредственно на границе получившейся разделяющей полосы и классифицируется правильно. Все отрицательные значения соответствуют ошибкам в работе алгоритма классификации.
60