

Представление служебной информации для последующего хранения или передачи.
Ответ:
Для вычисления объема занимаемого служебной информацией при кодировании черно-белых изображений алгоритмом Хаффмана с использованием длин серий будем исходить из следующих соображений.
Кодирование изображения представленного совокупностью блоков размера w * h осуществляется сопоставлением каждому типу блока кодовой комбинации кода Хаффмана. Код Хаффмана построен для распределения вероятностей типов блоков встречающихся в кодируемом изображении. На рисунке 4 схематично показана структура файла для хранения изображения сжатого этим методом:

Рисунок 4 – Структура заголовка файла HFI
В
верхней части рисунка указаны номера
байтов начиная с 0. Для каждого байта
номер поставлен в его начале и в конце.
Первые 3 байта используются для кодирования
формата файла (каждый байт содержит
символ в ASCII
коде), в данном случае это символы
hfi.
Следующие два поля содержат ширину и
высоту кодируемого изображения, каждое
поле занимает два байта, т.о. максимальная
высота\ширина равняется
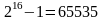 пикселей. Затем два поля по одному байту
для ширины и высоты блока (т.е. максимальное
значение этих полей 255). Для декодирования
изображения необходимо знать соответствие
типа блока и кода Хаффмана, для этого
предназначены поля список
блоков
и список
счетчиков длин.
Т.к. указанные поля имеют переменную
величину, то необходимо сохранять размер
для каждого из них – поля размер
списка блоков
и размер
списка счетчиков длин
соответственно. Кроме того, размер
блоков в списке может быть не кратен
восьми, поэтому может присутствовать
дополнительное поле в конце списка
блоков для выравнивания на границу
байта. Максимальный размер этого поля
семь бит. Полезная нагрузка также
выравнивается на границу байта.
пикселей. Затем два поля по одному байту
для ширины и высоты блока (т.е. максимальное
значение этих полей 255). Для декодирования
изображения необходимо знать соответствие
типа блока и кода Хаффмана, для этого
предназначены поля список
блоков
и список
счетчиков длин.
Т.к. указанные поля имеют переменную
величину, то необходимо сохранять размер
для каждого из них – поля размер
списка блоков
и размер
списка счетчиков длин
соответственно. Кроме того, размер
блоков в списке может быть не кратен
восьми, поэтому может присутствовать
дополнительное поле в конце списка
блоков для выравнивания на границу
байта. Максимальный размер этого поля
семь бит. Полезная нагрузка также
выравнивается на границу байта.
Отличия векторных цифровых изображений от растровых цифровых изображений.
Ответ:
Все цифровые изображения можно разбить на два больших класса: векторные цифровые изображения и растровые цифровые изображения.
Для векторного представления изображения характерно разбиение графического образа, содержащегося в этом изображении, на графические примитивы (линии, окружности, эллипсы, многоугольники и т.д.). Графические примитивы задаются координатой некоторой точки, принадлежащей этому примитиву и характеризующей его положение на плоскости изображения, и параметрами графического примитива, характеризующими его форму, размер и ориентацию (например, для квадрата это может быть координата любого угла, размер стороны и угол поворота). По этой причине, при сильном увеличении изображения при просмотре, векторные изображения остаются предельно четкими.
Для растровых цифровых изображений последнее утверждение не справедливо. Если у векторных изображений задаются параметры для каждого графического примитива, то у растровых изображений задаются параметры для каждой точки на плоскости изображения. Такая точка называется единичный элемент изображения или пиксель (от английского picture element). На первый взгляд, кажется, что задать каждую точку на изображении это гораздо более сложная задача, чем задание графических примитивов, но это совсем не так. Во-первых, графические примитивы отличаются большим разнообразием видов и различным количеством параметров для каждого вида, что вызывает определенные трудности для их описания некоторым двоичным кодом (т.е. для представления в цифровой форме). Во-вторых, разбить изображение на совокупность графических примитивов – далеко не тривиальная задача, поэтому область применения векторной графики сильно ограничена, в основном это искусственно созданные изображения (например, деловая графика). Изображения реального мира (фотографии и др.) являются растровыми. Конечно, можно нарисовать лицо человека в виде эллипса с глазами – кругами внутри и ртом – линией, но это будет очень грубое приближение. Растровое изображение дает настолько точное приближение, что человек может не заметить разницы, если не будет специально искать её.
Понятие глубины цветопередачи цифрового изображения.
Ответ:
Растровые изображения получаются в результате процесса АЦП (аналого-цифровое преобразование). Сначала оригинал сканируется или фотографируется, количество светочувствительных датчиков в устройстве определяет разрешающую способность системы (измеряется в dpi, dot-per-inch или в точках на дюйм), на этом этапе происходит дискретизация образа оригинала. Затем происходит квантование каждой точки-отсчета; количество уровней квантования зависит от характеристик и назначения системы; остановимся на 3 основных вариантах: 2 уровня, 256 уровней и 16777216 уровней. Так как каждая точка изображения может принимать значение одного из возможных уровней квантования, то для возможности отличать один уровень от другого, соответственно, будем иметь 1 бит, 8 бит или 24 двоичных разряда (бита) на точку. Эта величина называется глубиной цветопередачи изображения и, в зависимости от её значения, будем различать черно-белые, полутоновые и цветные растровые изображения соответственно.
Каким образом можно улучшить коэффициенты сжатия для, предлагаемого в настоящей лабораторной работе, алгоритма сжатия и способа хранения сжатой информации, если допустить сжатие с потерями и если не допускать сжатие с потерями?
Ответ: Один из способов улучшить коэффициент сжатия это использовать сжатие с потерями - это методы сжатия данных, при которых часть данных отбрасывается и не подлежит восстановлению (используется для видео, звука, изображений) Ксж до 99% , сжатие без потерь хуже - это методы сжатия данных, при которых данные восстанавливаются после их распаковки полностью без внесения изменений (используется для текстов, программ) Ксж до 50%
Методы архивации:
Без сжатия (просто помещает файлы в архив без их упаковки).
Скоростной (сжимает плохо, но очень быстро).
Быстрый.
Обычный (используется для создания резервных копий данных).
Хороший.
Максимальный (обеспечивает наиболее высокую степень сжатия, но с наименьшей скоростью, используется для передачи по компьютерным сетям или для долговременного хранения).