

6.Провели оценку ошибку классификации. Подсчитали метрики:
•"Accuracy" (Доля правильных ответов)
Метрика показывает процент значений, которые модель угадала правильно при проверке на тестовых данных. Оценили предсказания для моделей К-ближайших соседей,
Логической регрессии и Случайный лес в соответствии с рисунком 16.
Рисунок 16 – Оценка метрики Accuracy
Самый лучший результат у модели Случайный лес точность предсказаний 92%,
Логическая регрессия показала схожий, но немного хуже результат, а К-ближайших отстает в среднем на 6% от остальных.
•"Balanced accuracy" (Сбалансированная точность)
Показывает среднюю точность для классов используется для оценки несбалансированных классов.
Особенно подходит нам, потому что у нас заметно больше отрицательных значений чем отрицательных в целевом признаке. Оценили предсказания для моделей К-ближайших соседей, Логической регрессии и Случайный лес в соответствии с рисунком 17.
Рисунок 17 – Оценка метрики Balanced accuracy
Самый лучший результат у модели Случайный лес точность предсказаний 88%,
Логическая регрессия показала схожий, но немного хуже результат, а К-ближайших отстает в среднем на 8% от остальных.
11
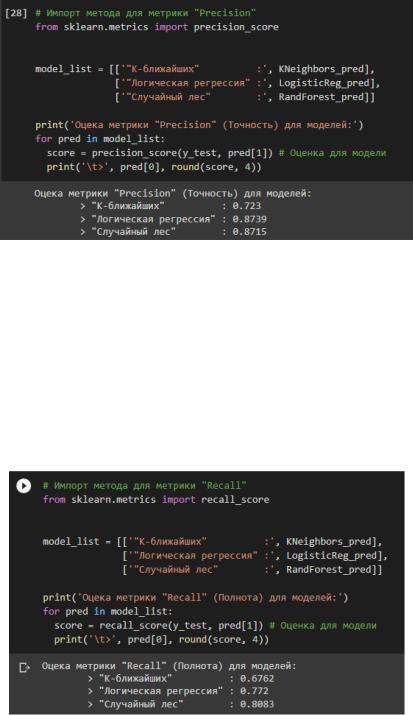
•"Precision" (Точность)
Метрика показывает какая доля прогнозов относительно "1" класса верна. То есть смотрим долю правильных ответов только среди целевого класса. Оценили предсказания для моделей К-ближайших соседей, Логической регрессии и Случайный лес в соответствии с рисунком 18.
Рисунок 18 – Оценка метрики Precision
Самый лучший результат у модели Случайный лес точность предсказаний 87%,
Логическая регрессия показала схожий, но немного хуже результат, а К-ближайших отстает в среднем на 8% от остальных.
•"Recall" (Полнота)
Показывает, сколько реальных объектов "1" класса вы смогла обнаружить модель.
Оценили предсказания для моделей К-ближайших соседей, Логической регрессии и Случайный лес в соответствии с рисунком 19.
Рисунок 19 – Оценка метрики Recall
Модель случайный лес очередной раз показывает лучший результат порядка 80%,
логическая регрессия немного отстает от лучшего, а К-ближайших отстает от остальных в среднем на 10%.
12
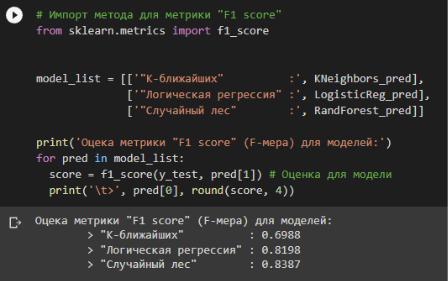
•'F1 score' (F-мера, Сбалансированная Точность/Полнота)
Данная метрика позволяет получить общую оценку для метрик Точности и Полноты,
которая учитывает обе метрики при подсчетах. Оценили предсказания для моделей К-
ближайших соседей, Логической регрессии и Случайный лес в соответствии с рисунком 20.
Рисунок 20 – Оценка метрики F1 score
Полученный результат достаточно был достаточно предсказуем по результатам посчитанных ранее метрик. Случайный лес получил высшую оценку 83%, логическая регрессия всего на 1,5% отстает, а К-ближних снова с худшим результатом в примерно 70%.
13
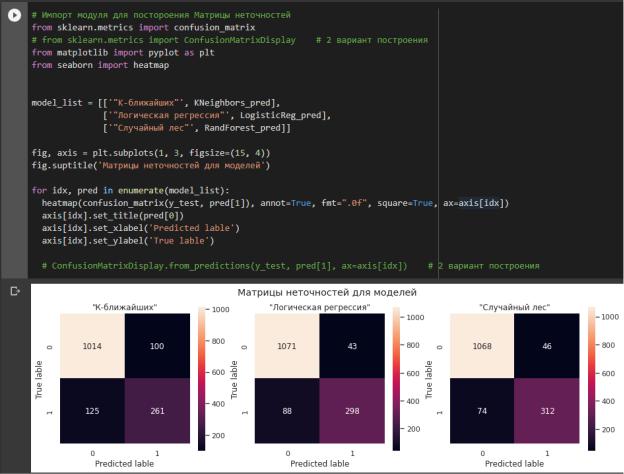
7.Построили матрицу неточностей с помощью confusion_matrix для моделей К-
ближайших соседей, Логической регрессии и Случайный лес в соответствии с рисунком 21.
Данная матрица дает количественную оценку предсказаний данных моделью,
показывая сколько положительных и отрицательных значений угадано верно и ошибочно.
Рисунок 21 – Построение матриц неточностей На основании данной матрицы производятся расчеты всех ранее полученных
метрик, а на основании группы таких матриц, полученных при разных пороговых значениях, строится ROC-кривая.
14

8.Построили график ROC-кривой для моделей К-ближайших соседей,
Логической регрессии и Случайный лес в соответствии с рисунком 22.
График ROC-кривой позволяет оценить при каком пороговом значении модель будет давать лучший результат при классификации данных.
Метрика AUC — это площадь под кривой ROC.
Общее правило гласит - чтобы определить оптимальную точку на кривой ROC
нужно максимизировать разницу (True Positive Rate (TPR) - False Positive Rate (FPR)),
которая на графике представлена вертикальным расстоянием между полученной ROC-
кривой и диагональной линией из точки (0, 0) в (1, 1).
Рисунок 22 – Построение ROC-кривых
Оценка AUC показывает неплохие результаты для всех моделей, но самый лучший
умоделей Логической регрессии и Случайного леса.
9.Ссылка на Google диск с Jupyter-ноутбук
URL: https://colab.research.google.com/drive/1Lj08P2PLZg4YNv1DcEmMJm7jJXy99atT?usp=sharin g
15
Вывод
В ходе данной лабораторной работы мы подготовили датасет, провели на этих данных обучение различных моделей для задачи классификации и провели оценку качества.
Подготовили датасет с информацией о клиентах фитнес-клуба, исправив ошибки с названиями, в остальном данные были валидны.
Затем, чтобы можно было провести обучение моделей классификации,
стандартизировали данные, чтобы установить подходящие размерности параметров.
Обучили три различные модели с применением методов K-ближайших соседей,
Логической регрессии и Случайного леса.
Для нашей задачи лучше всего себя показала модель классификатора на основе метода Случайного леса, во всех метриках результаты превышали 0,8 и доходили в плоть до 0,97 – это очень хороший результат говорящий о том, что ошибки есть но они минимальны, поэтому точность предсказаний будет весьма хорошая.
Модель Логической регрессии показала немного худшие на схожие с моделью случайного леса оценки метрик.
Модель К-ближайших соседей не подходит для нашей задачи так как значительно уступает остальным по качеству получаемых прогнозов.
16