

8. Декодирование LZW
.docxМИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра информационных систем
отчЁт
по практической работе №8
по дисциплине «Теория информации, данные, знания»
Тема: Декодирование LZW.
Студент гр. 93— |
|
— |
Преподаватель |
|
Писарев И. А. |
Санкт-Петербург
2020
Цель работы
Сформулировать ответы на вопросы с указанием источников информации.
Вопросы по теме:
В каких популярных программах реализован метод LZW?
Гарантирует ли метод LZW отсутствие потерь или искажений данных?
Опишите метод декодирования Лемпеля—Зива—Велча (LZW).
Решить задачи:
Декодируйте сообщение «99 256 257 258» методом LZW. Приведите описание последовательности выполненных действий декодирования с комментариями выполняемых шагов алгоритма.
Декодируйте сообщение «65 68 256 257 68 260» методом LZW. Приведите описание последовательности выполненных действий.
Выполнение работы
Вопрос 1.
В настоящее время используется в файлах формата TIFF, PDF, GIF, PostScript и других, а также отчасти во многих популярных программах сжатия данных (ZIP, ARJ, LHA). (2, С. 70)
Вопрос 2.
Данный тип компрессии не вносит искажений в исходный графический файл, и подходит для сжатия растровых данных любого типа. (2, С. 69)
Вопрос 3.
Декодер начинает с заполнения словаря первыми символами алфавита (их, обычно, 256). Затем он читает входной файл, который состоит из указателей в словаре, использует каждый указатель для того, чтобы восстановить несжатые символы из словаря и записать их в выходной файл. Кроме того, он строит словарь тем же методом, что и кодер.
На первом шаге
декодирования, декодер вводит первый
указатель и использует его для
восстановления словарного элемента
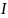 .
Это строка символов, и она записывается
декодером в выходной файл. Далее следует
записать в словарь строку
.
Это строка символов, и она записывается
декодером в выходной файл. Далее следует
записать в словарь строку
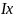 ,
однако символ
,
однако символ
 ещё неизвестен; это будет первый символ
следующей строки, извлечённой из словаря.
ещё неизвестен; это будет первый символ
следующей строки, извлечённой из словаря.
На каждом шаге
декодирования после первого декодер
вводит следующий указатель, извлекает
следующую строку
 из словаря, записывает её в выходной
файл, извлекает её первый символ
и заносит строку
в словарь на свободную позицию
(предварительно проверив, что строки
нет в словаре). Затем декодер перемещает
в
.
Теперь он готов к следующему шагу
декодирования. (1, С. 102)
из словаря, записывает её в выходной
файл, извлекает её первый символ
и заносит строку
в словарь на свободную позицию
(предварительно проверив, что строки
нет в словаре). Затем декодер перемещает
в
.
Теперь он готов к следующему шагу
декодирования. (1, С. 102)
Задача 1.
Вход |
Запись в словарь |
Выход |
|
Полная |
Частичная |
||
99 (c) |
|
256: c� |
c |
256 (c�) |
256: cc |
257: cc� |
cc |
257 (cc�) |
257: ccc |
258: ccc� |
ccc |
258 (ccc�) |
258: cccc |
259: cccc� |
cccc |
Выходное сообщение: cccccccccc.
Задача 2.
Вход |
Запись в словарь |
Выход |
|
Полная |
Частичная |
||
65 (A) |
|
256: A� |
A |
68 (D) |
256: AD |
257: D� |
D |
256 (AD) |
257: DA |
258: AD� |
AD |
257 (DA) |
258: ADD |
259: DA� |
DA |
68 (D) |
259: DAD |
260: D� |
D |
260 (D�) |
260: DD |
261: DD� |
DD |
Выходное сообщение: ADADDADDD.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
Сэломон Д. Сжатие данных, изображений и звука. М.: Техносфера. 2004. 368 с.
Гошин Е.В. Теория информации и кодирования. Самара: Самарский университет. 2018. 124 с.