

Компьютерные сети (3 курс 2 семестр) Черняхівський Ю.В. / ЛР9 ДОСЛІДЖЕННЯ РОБОТИ СЛУЖБИ WWW / ЛР_9_ДОСЛІДЖЕННЯ РОБОТИ СЛУЖБИ WWW_2017
.pdfМіністерство освіти і науки України
Київський коледж комп’ютерних технологій та економіки Національного авіаційного університету
ЗАТВЕРДЖУЮ заступник директора з навчально-виробничої роботи
________ А. П.Єрмоленко «___»____20__ р.
КОМП’ЮТЕРНІ МЕРЕЖІ
ІНСТРУКЦІЯ
до проведення лабораторної роботи № 9
Тема: «Дослідження роботи служби WWW»
Напрям підготовки «6.050102 Комп’ютерна інженерія»
Спеціальність шифр «5.05010201»
Освітньо-кваліфікаційний рівень – молодший спеціаліст
РОЗГЛЯНУТО ТАСХВАЛЕНО на засіданні випускової комісії спеціальності «ОКСМ»
___.____.2016 р.
Протокол № 1 голова ВК
___________І.В. Чорновол
РОЗРОБИВ ВИКЛАДАЧ
______ Ю.В. Черняхівський __.___.2016 р.
Київ 2016
Лабораторна робота № 9
Тема: Дослідження роботи служби WWW
Мета: Дослідити різноманітні види пошуку та пошукових систем, які використовуються в Internet; роботу служби WWW, основні протоколи, їх синтаксис та дію.
Кількість аудиторних годин: 2 години
Завдання:
-одержати відомості про типи пошуку в Internet та методику їх організації, про види пошукових систем та принципи їх роботи;
-провести пошук інформації, використовуючи різні види пошукових систем та різні типи пошуку;
-описати принцип роботи служби WWW та роботу протоколу HTTP.
Література:
1.В.Г. Олифер, Н.А. Олифер. Компьютерные сети. Принципы, технологии, протоколы: Учебник для вузов. 5-е изд. – СПб.: Питер, 2016. – 992 с.: ил.
2.Компьютерные сети. 5-е изд. / Э. Таненбаум, Д. Уэзеролл – СПб.: Питер, 2012. – 960 с.: ил.
3.Компьютерные сети: Нисходящий подход / Джеймс Куроуз, Кит Росс. – 6-е изд. – Москва: Издательство «Э», 2016. – 916 с.
4.Современные компьютерные сети. 2-е изд. / В. Столлингс. – СПб.:Питер, 2003. – 783 с.
5.Жуков І.А., Дрововозов В.І., Масловський Б.Г. Експлуатація комп’ютерних систем та мереж: Навч. посібник.- К.: НАУ-Друк, 2007. - 368с.
5.Черняхівський Ю.В. Конспект лекцій з предмету «Комп’ютерні мережі»
Характеристика робочого місця:
Робоче місце на базi ПК з встановленою ОС WINDOWS XP, інстальованим та налаштованим мережним адаптером Fast Ethernet та його драйвером, інстальованими та налаштованими протоколами ТСР/ІР, підключенням до корпоративної мережі коледжу, навчальний мережний сервер на базі ПК з операційною системою FreeBSD та інстальованим і налаштованим WEB-сервером.
Вимоги до охорони праці при виконанні лабораторної роботи:
1.Виконувати вимоги інструкції з охорони праці при виконанні лабораторно-практичних робіт в лабораторії
2.Не вмикати та вимикати ПЕОМ самостійно без потреби
3.Не залишати ПЕОМ у ввімкненому стані без нагляду
4.Не затуляти вентиляційні отвори монітора та системного блока
5.Не класти на клавіатуру різні речі – зошити, ручки тощо
6.Виконувати роботу у відповідності з інструкцією
Теоретичні відомості
Теоретичні питання з даної теми описані в методичній розробці «Організація пошуку в Internet».
Інформація може розміщуватися на веб-серверах, на ftp-серверах, в блогах, в новинах, в книгах, в словниках, в товарах, на географічних картах, в довідниках адрес організацій, серед афіш театрів і музеїв, в телепрограмах, в каталогах, в Вікіпедії, в архівах Інтернету, у пірингових мережах, в базах даних,
у веб-закладках або в рейтингових системах: |
|
||
|
джерела інформації; |
|
пошук телепрограми; |
|
пошук по блогам; |
|
пошук в каталогах; |
|
пошук в новинах; |
|
пошук в Вікіпедії; |
|
новини Google; |
|
пошук в архівах Інтернету; |
|
яндекс.Новини; |
|
пошук через пірингові системи; |
|
пошук книг та в книгах; |
|
пошук в базах даних; |
|
пошук в словниках; |
|
пошук в інтернет-версіях |
|
пошук в картинках; |
правових систем; |
|
|
пошук в товарах; |
|
первіс закладинок; |
|
пошук по карте; |
|
пошук через рейтингові |
|
пошук адрес; |
системи; |
|
|
пошук афіши; |
|
пошук звуків в FindSounds.com |
|
пошук по об’явам; |
|
інший пошук |
|
пошук інформації про погоду; |
|
|
Пошук може здійснюватися в пошукових індексах, через розміщення власної публікації з певної теми, через експертів тощо:
|
карти пошуку інформації; |
|
пошук за допомогою |
|
пошукові індекси; |
експертів; |
|
|
мова запитів в пошукових |
|
пошук на сайтах правових |
індексах; |
систем. |
||
|
особиста публікація як |
|
|
джерело інформації; |
|
|
|
|
Пошукові системи: |
|
|
|
Google; |
|
ru.msn.com; |
|
Yahoo!; |
|
Nigma.ru ; |
|
Апорт; |
|
AltaVista; |
|
Rambler; |
|
Quintura; |
|
Яндекс; |
|
Microsoft Live Search. |
@MAIL.RU;
|
Спеціалізовані пошукові системи: |
|
|
|
Bing |
|
KM.RU |
|
Ask.com |
|
informationrecuperation.blogspot |
|
GigaBits.com |
.com |
|
|
Taggalaxy.de |
|
та інші. |
FindSounds.com
ОПИС МОВИ ЗАПИТІВ
Як трактуються слова
Незалежно від того, в якій формі вжито слово в запиті, пошук враховує всі його форми за правилами певної мови (мови, яка використовується при запиті).
Наприклад, якщо задано запит "йти", то в результаті пошуку будуть знайдені посилання на документи, що містять слова 'йти', 'йде', 'йшов', 'йшла' тощо. На запит 'вікно' буде видана інформація, що містить і слово 'вікон', а на запит 'відкликали' - документи, що містять слово 'відкликались'.
Якщо набрати в запиті слово з великої літери, будуть знайдені тільки слова з великої літери (якщо це слово не перше в запиті), в іншому випадку будуть знайдені як слова з великою, так і з маленької літери.
Наприклад, запит 'лебідь' знайде і птицю, і генерала. Запит 'Лебідь' - генерала і ті випадки згадки птиці, коли вона написана з великої літери.
За замовчуванням пошук враховує всі форми заданого слова згідно з правилами російської мови. Однак існує можливість пошуку за точною словоформою, для цього перед словоформою треба поставити знак оклику '!'.
Так за запитом '! Лужкову' будуть знайдені всі документи, що містять словоформу 'Лужкову', а на запит 'Лужков ~ ~! Лужкову' - документи, в яких згадується Лужков, крім тих, які були знайдені за першим запитом.
Природно-мовний пошук
Знаки "+" і "-". Якщо необхідно, щоб слова із запиту обов'язково були знайдені, поставте перед кожним з них "+". Якщо треба виключити будь-які слова з результату пошуку, поставте перед кожним з них "-".
Наприклад, запит 'приватні оголошення продаж велосипеда', видасть багато посилань на сайти з різноманітними приватними оголошеннями. А запит з "+" 'приватні оголошення продаж + велосипеда' покаже оголошення про продаж саме велосипедів. Якщо потрібний опис Парижа, а не пропозиції численних турагентств, має сенс задати такий запит 'путівник по Парижу –агентство -тур'
Зверніть увагу на знак "-". Це саме мінус, а не тире і не дефіс. Знак "-" треба писати через пробіл від попереднього і разом з наступним словом, ось так: 'рак -гороскоп'. Якщо написати 'рак-гороскоп' або 'рак - гороскоп', то знак "-" буде проігноровано.
Основні оператори
Кілька набраних у запиті слів, розділених пробілами, означають, що всі вони повинні входити в одну пропозицію документа, який шукається. Той же самий ефект справить вживання символу '&'.
Наприклад, при запиті 'лікувальна фізкультура' або 'лікувальна фізкультура &'), результатом пошуку буде список документів, в яких в одному реченні містяться і слово 'лікувальна', і слово 'фізкультура'. (Еквівалентно запросу '+ лікувальна фізкультура +')
Між словами можна поставити знак '|', щоб знайти документи, що містять будь-яке з цих слів. (Зручно при пошуку синонімів).
Запит виду 'фото | фотографія | фотознімок | фото | фотозображення' задає пошук документів, що містять хоча б одне з перерахованих слів.
Ще один знак, тильда '~', дозволить знайти документи з пропозицією, що містить перше слово, але не містить друге.
За запитом 'банки ~ закон' будуть знайдені всі документи, що містять слово 'банки', поруч з яким (в межах речення) немає слова 'закон'.
Щоб піднятися на сходинку вище, від рівня пропозиції до рівня документа, треба відповідний знак застосувати двічі. Одинарний оператор (&, ~) шукає в межах абзацу, подвійний (& &, ~ ~) - в межах документа.
Наприклад, за запитом 'рецепти & & (плавлений сир)' будуть знайдені документи, в яких є і слово 'рецепти' і словосполучення '(плавлений сир)' (причому '(плавлений сир)' повинен бути в одному реченні. А запит 'керівництво Visual C ~ ~ ціна 'видасть всі документи зі словами' керівництво Visual C ', але без слова' ціна '
Пошук з відстанню
Часто в запитах шукають стійкі словосполучення. Якщо поставити їх в лапки, то будуть знайдені ті документи, в яких ці слова йдуть строго поспіль. Наприклад, за запитом "червона шапочка" будуть знайдені документи з
цією фразою. (При цьому контекст "а шапочка у неї була червона" знайдено не буде.)
Як Яndex адресує слова? Якщо всі слова в тексті перенумерувати по порядку їх слідування, то відстань між словами a і b - це різниця між номерами слів a і b. Таким чином, відстань між сусідніми словами дорівнює 1 (а не 0), а відстань між сусідніми словами, що стоять "не в тому порядку", дорівнює -1 (мінус 1). Те ж саме відноситься і до пропозицій.
Якщо між двома словами поставлений знак "/", за яким відразу надруковано число, значить, потрібно, щоб відстань між ними не перевищував цього числа слів.
Наприклад, задання запиту 'постачальники / 2 кава', вимагає знайти документи, в яких містяться і слово 'постачальники', і слово 'кава', причому відстань між ними повинна бути не більше двох слів і вони повинні перебувати в одному реченні. (Знайдуться "постачальники колумбійського кави", "постачальники кави з Колумбії" і т.д.)
Якщо порядок слів і відстань точно відомі, можна скористатися пунктуацією '/ + n'. Так, наприклад, задається пошук слів, що стоять підряд.
Запит 'синя / +1 борода' означає, що слово 'борода' має йти безпосередньо за словом 'синя'. (До того ж результату приведе запит "синя борода")
У загальному вигляді обмеження по відстані задається за допомогою пунктуації виду '/ (nm)', де 'n' мінімальне, а 'm' максимально допустима відстань. Звідси випливає, що запис '/ n' еквівалентний запису '/ (-n + n)', а запис '/ + n' еквівалентний запису '/ (+ n + n)'.
Запит 'музичне / (-2 4) освіта' означає, що 'музичне' повинно знаходитися від 'освіта' в інтервалі відстаней від 2 слів зліва до 4 слів справа.
ПрактичноНаприклад,всірезультатомзнаки можнапошукукомбінуватиза запитомобмеженням'вакансії ~ /відстані+1 студентів'. будуть документи, що містять слово 'вакансії », причому в цих документах слово 'студентів' знаходиться не безпосередньо за словом 'вакансії'.
Коли знаки обмеження по відстані стоять після подвійних операторів, то вжиті там числа - це відстань не в словах, а в пропозиціях. Відстань в абзацах визначається аналогічно відстані в словах.
Запит 'банк & & / 1 податки "означає, що слово 'податки' повинно знаходитися в тому ж самому, або в сусідньому зі словом 'банк' реченні.
Дужки
Замість одного слова у запиті можна підставити цілий вираз. Для цього його треба взяти в дужки.
Наприклад, запит '(історія, технологія, виготовлення) / +1 (сиру, сиру)' задає пошук документів, які містять будь-яку з фраз 'історія сиру', 'технологія сиру', 'виготовлення сиру', 'історія сиру'.
Пошук в зонах
Можна шукати інформацію в "зонах" - заголовках (ім'я "зони": Title), посиланнях (ім'я "зони": Anchor) та адресу (ім'я "зони": Address). Синтаксис: $ імя_зони (пошуковий вираз).
Запит '$ title CompTek' шукає в заголовках документів слово 'CompTek'. Запит '$ anchor (CompTek | Dialogic)' знаходить документи, в посиланнях, всередині яких є одне з слів 'CompTek' або 'Dialogic'.
Пошук в певних елементах
Можна обмежити пошук інформації списком серверів або навпаки виключити сервера з пошуку (url). Можна також шукати документи, які містять посилання на певні URL (link), і файли картинок (image). Якщо треба працювати не з конкретним URL (image), а з усіма, що починаються з даної послідовності символів, використовуйте "*". Синтаксис: # імя_елемента = "ім'я_файлу (URL)".
За запитом 'CompTek ~ ~ # url = "www.comptek.ru *"' будуть шукатися згадки компанії 'CompTek' скрізь, крім її власного сервера (www.comptek.ru). А запит '# link = "www.comptek.ru *"' покаже всі документи, які послалися на сервер компаніі. Запит '# image = "tort *"' дасть посилання на документи із зображеннями тортів (хоча, можливо, знайдеться і портрет черепахи Тортілли).
Можна також шукати за ключовими словами (keywords), анотаціями (abstract) і підписам під зображеннями (hint). Синтаксис: # імя_елемента = (пошуковий вираз).
Запросу '# keywords = (пошукова система) | # abstract = (пошукова система)' будуть шукатися всі сторінки, в meta-тегах яких є ці слова. За запитом '# hint = (кіно)' будуть знайдені документи, що містять зображення з таким підписом .
Ранжування результату пошуку
При пошуку для кожного знайденого документа Яндекс обчислює величину релевантності (відповідності) змісту цього документа пошуковому запиту. Список знайдених документів перед видачею користувачеві сортується за цією величиною в порядку зменшення. Релевантність документа залежить від ряду факторів, у тому числі від частотних характеристик слів, які треба знайти, ваги слова або виразу, близькості пошукових слів у тексті документа один до одного тощо.
Користувач може вплинути на порядок сортування, використовуючи оператори ваги й уточнення запиту.
Завдання ваги слова або виразу застосовується для того, щоб збільшити релевантність документів, які містять "зважений" вираз. Синтаксис: слово: число або (пошуковий_вираз): число
За запитом 'пошукові механізми: 5' будуть знайдені ті ж документи, що і за запитом 'пошукові механізми'. Різниця полягає в тому, що зверху знайденого списку виявляться документи, де найчастіше зустрічається саме слово 'механізми'. Запит 'пошукові (механізми | машини | апарати): 5' рівнозначний запиту 'пошукові (механізми: 5 | машини: 5 | апарати: 5 ) '.
Завдання уточнюючого слова або виразу застосовується для того, щоб збільшити релеватність документів, які містять уточнюючий вираз. Синтаксис: <- слово або <- (уточнюючий_вираз).
За запитом 'комп'ютер <- телефон' будуть знайдені всі документи, що містять слово 'комп'ютер', при цьому першими будуть видані документи, що містять слово 'телефон'. Якщо ні в одному документі зі словом 'комп'ютер' немає слова 'телефон', результат запиту буде еквівалентний запиту 'комп'ютер'.
Служба WWW
Служба WWW (World Wide Web) - призначена для обміну гіпертекстової інформацією.
Проект був запропонований в 1989 році. У 1993 з'явився перший браузер. WWW побудована за схемою "клієнт-сервер".
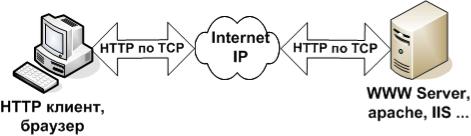
Браузер (Internet Explorer, Opera ...) є мультипротокольним клієнтом і інтерпретатором HTML. І як типовий інтерпретатор, клієнт у залежності від команд (тегів) виконує різні функції. До кола цих функцій входить не тільки розміщення тексту на екрані, але обмін інформацією з сервером у міру аналізу отриманого HTML-тексту, що найбільш наочно відбувається при відображенні убудованих у текст графічних образів.
Сервер HTTP (Apeche, IIS ...) обробляє запити клієнта на отримання файла (в найпростішому випадку).
Рисунок 1 - Взаємодія клієнта і сервера по протоколу HTTP. Спочатку служба WWW базувалася на трьох стандартах:
OHTML (HyperText Markup Lan-guage) - мова гіпертекстової розмітки документів;
OURL (Universal Resource Locator) - універсальний спосіб адресації ресурсів у мережі;
OHTTP (HyperText Transfer Protocol) - протокол обміну гіпертекстової інформацією.
Пізніше додали:
O CGI (Common Gateway Interface) - універсальний інтерфейс шлюзів. Створений для взаємодії HTTP - сервера з іншими програмами, встановленими на сервері (наприклад, СУБД).
Основу служби складає мережа WWW-серверів, на яких розміщені гіпертекстові документи, об'єднані перехресними посиланнями. WWWбраузер (WWW-клієнт) послідовно зчитує документи з різних серверів. При цьому частини одного документа можуть зберігатися на різних серверах. WWW-браузер самостійно аналізує гіпертекстовий документ і формує запити на отримання необхідного фрагмента з необхідного сервера. Таким чином, з'являється можливість організовувати величезні сховища структурованої інформації, пошук і оновлення якої здійснюється з мінімальними витратами, крім цього відсутня необхідність в дублюванні документів. Саме з початком використання служби WWW значно спростився пошук і використання інформації.
Основним форматом для подання гіпертекстових документів є HTML. Опис цього формату наведено нижче.
Для обміну інформацією між WWW-серверами і клієнтами використовується протокол HTTP.
Протокол HTTP
Перший документ (але не стандарт) - RFC1945 (Hypertext Transfer Protocol - HTTP/1.0 T. Berners-Lee, R. Fielding, H. Frystyk May 1996)
Остання версія - RFC2616 (Hypertext Transfer Protocol - HTTP/1.1 R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee June 1999)
Hypertext Transfer Protocol - протокол передачі гіпертексту, протокол високого рівня (а саме, рівня додатків). Використовується службою WWW для передачі Web-сторінок.
Протокол HTTP визначає запит-відповідь спосіб взаємодії між програмоюклієнтом і програмою-сервером в рамках технології World Wide Web. Нижче наведено приклади запиту клієнта і відповіді сервера:
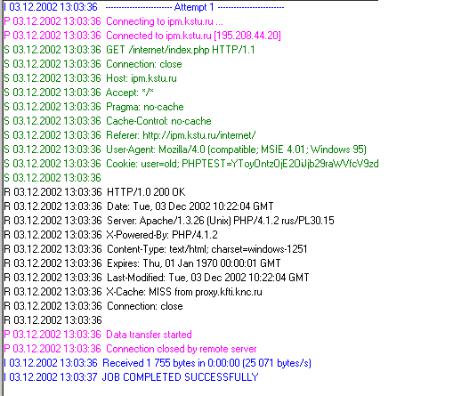
Рисунок 2 - Лістинг запиту і відповіді HTTP
Встановлення з’єднання
Connecting to ipm.kstu.ru ...
Connected to ipm.kstu.ru [195.208.44.20]
Запит клієнта
GET /internet/index.php HTTP/1.1 - (запит файлу та вказівка протоколу HTTP/1.1)
Connection: close - (закрити з’єднання після відправки файлу) Host: ipm.kstu.ru - (вказівка адреси серверу)
Accept: */* - (перевага типів даних) Cache-Control: no-cache - (не кешувати)
Referer: http://ipm.kstu.ru/internet/ - (звідки прийшов клієнт) User-Agent: Mozilla/4.0 (compatible; MSIE 4.01; Windows 95) - (назва
програми клієнта)
Відповідь сервера
HTTP/1.0 200 OK - (який протокол використовується, 200 - означає, що файл знайдено)
Date: Wed, 23 Oct 2002 08:32:31 GMT - (дата та час відповіді)
Server: Apache/1.3.26 (Unix) PHP/4.1.2 rus/PL30.15 - (назва, версія і модули http-сервера)
X-Powered-By: PHP/4.1.2 - (чим створена сторінка) Connection: close - (закрити з’єднання після одержання файлу)
Content-Type: text/html; charset=windows-1251 - (тип даних html, кодування windows-1251)
Далі йде вміст файлу (тіло запиту).
Робота по протоколу HTTP відбувається наступним чином: програма-клієнт встановлює TCP-з'єднання з сервером (стандартний номер порту-80) і видає йому HTTP-запит. Сервер обробляє цей запит і видає HTTP-відповідь клієнту.
HTTP-запит складається з заголовка запиту і тіла запиту, розділених символом нового рядка. Тіло запиту може бути відсутнім.
Тема запиту складається з головної (першої) рядка запиту і наступних рядків, уточнюючих запит у головній рядку. Наступні рядки також можуть бути відсутні.
Запит у головній рядку складається з трьох частин, розділених пробілами: 1) Метод (інакше кажучи, команда HTTP):
GET - метод GET служить для одержання будь-якої інформації, відповідно URI-запиту.
HEAD - запит заголовка документа. Відрізняється від GET тим, що видається тільки заголовок запиту з інформацією про документ. Сам документ не видається.
POST - цей метод застосовується для передачі даних CGI-скриптів. Самі дані випливають у наступних рядках запиту у вигляді параметрів.
PUT - помістити документ на сервері. Запит з цим методом має тіло, в якому передається сам документ.
DELETE - використовується для видалення ресурсів, ідентифікованих за допомогою URI-запиту
2)Ресурс - це шлях до певного файлу на сервері (називається URI), який клієнт хоче отримати (або розмістити - для методу PUT). Якщо ресурс - просто якийсь файл для зчитування, сервер повинен за цим запитом видати його в тілі відповіді. Якщо ж це шлях до якого-небудь CGI-скрипту, то сервер запускає скрипт і повертає результат його виконання. До речі, завдяки такій уніфікації ресурсів для клієнта практично байдуже, що він являє собою на сервері.
3)Версія протоколу - версия протокола HTTP, з якою працює клієнтська програма.
Рядки після головної рядка запиту мають наступний формат:
Параметр: значення.
Таким чином, задаються параметри запиту. Це є необов'язковим, всі рядки після головної рядка запиту можуть бути відсутні; в цьому випадку сервер приймає їх значення за замовчуванням або за результатами попереднього запиту (при роботі в режимі Keep-Alive).
Деякі параметри HTTP-запиту:
Connection (з’єднання) - може приймати значення Keep-Alive і close. KeepAlive («залишити в живих») означає, що після видачі даного документа з'єднання з сервером не розривається, і можна видавати ще запити. Більшість браузерів працюють саме в режимі Keep-Alive, так як він дозволяє за одне з'єднання з сервером "завантажити" html-сторінку і малюнки до неї. Будучи одного разу встановленим, режим Keep-Alive зберігається до першої помилки або до явного вказівки в черговому запиті Connection: close.
close («закрити») - з'єднання закривається після відповіді на цей запит. User-Agent - значенням є "кодове позначення" браузера, наприклад:
Mozilla/4.0 (compatible; MSIE 5.0; Windows 95; DigExt)
Accept - список підтримуваних типів вмісту браузера в порядку їх переваги даним браузером, наприклад: