

nC1DMY1V3A
.pdfВ данном случае нисходящий характер вычисления значений атрибутов отражается в том, что каждое правило вычисления атрибутов нетерминалов показывает, как вычислять нетерминалы, входящие в правую часть.
Рис. 6.3. Атрибутное дерево вывода цепочки ТИПвещV1, V2, V3
Определение 6.4. Атрибуты, значения которых определяются нисходящим способом, когда задаются правила вычисления атрибутов правых частей по данным атрибутов левых и правых частей, называют наследуе-
мыми атрибутами.
Атрибутные транслирующие грамматики и перевод
Обобщим введенные выше понятия в следующем определении. Определение 6.5. Атрибутная транслирующая грамматика – это транс-
лирующая грамматика, к которой добавляются следующие определения:
1.Каждый входной символ, символ действия или нетерминальный символ имеет конечное множество атрибутов, и каждый атрибут имеет (возможно, бесконечное) множество допустимых значений.
2.Все атрибуты нетерминальных символов и символов действия делятся на наследуемые и синтезируемые.
3.Правила вычисления наследуемых атрибутов определяются следующим образом:
a.Каждому вхождению наследуемого атрибута в правую часть данной продукции сопоставляется правило вычисления значения этого атрибута как функции некоторых других атрибутов символов, входящих в правую или левую часть данной продукции.
b.Задается начальное значение каждого наследуемого атрибута начального символа.
4.Правила вычисления синтезируемых атрибутов определяется так:
a.Каждому вхождению синтезируемого нетерминального атрибута в левую часть данной продукции сопоставляется правило вычисления значения этого атрибута как функции некоторых других атрибутов символов, входящих в левую или правую часть данной продукции.
80

b.Каждому синтезируемому атрибуту символа действия сопоставляется правило вычисления значения этого атрибута как функции некоторых других атрибутов этого символа действия.
Пример использования определения: пусть есть правило
<X> b<Y><Z>.
Все символы правила имеют следующие атрибуты по пункту 1 определения:
<X> – три атрибута,
<Y> и <Z> – по два атрибута, b – один атрибут,
то есть правило записывается в следующем виде:
<X>p, q, r bs<Y>y, u<Z>v, w
По пункту 2 определяем атрибуты по классификации и применяем правила определения атрибутов:
a.если в левой части продукции синтезирующими являются только атрибуты q и r, то по пункту 4а – они определяются;
b.если в правой части наследуемыми атрибутами являются y и v, определяемые по 3а; тогда выше указанную продукцию можно дополнить, например, правилами:
q SIN(u + w) (r, v) s u
y p
Атрибутные транслирующие грамматики используются для определения атрибутных деревьев вывода, а затем атрибутных последовательностей актов и атрибутных переводов.
Деревья определяются следующими процедурами построения:
1.По соответствующей неатрибутной грамматике построить дерево вывода последовательности актов, состоящей из входных символов и символов действия без атрибутов.
2.Присвоить значения атрибутам входных символов, входящих в дерево вывода.
3.Присвоить начальные значения наследуемым атрибутам начального символа дерева вывода.
4.Вычислить значения атрибутов символов, входящих в дерево вывода, повторяя следующее действие до тех пор, пока оно станет невозможным: найти атрибут, которого еще нет в дереве, но аргументы правила его вычисления уже имеются, вычислить значение этого атрибута и добавить его к дереву.
5.Если выполнение шага 4 приведет к тому, что значения всех атрибутов всех символов дерева окажутся вычисленными, то будем называть полученное дерево завершенным. В противном случае – незавершенным.
81
Далее можно еще раз вернуться к дереву вывода выражения (c3+c8) (c2+c4), и описать процесс построения атрибутного дерева по шагам представленной процедуры (учитывая, что шаг 3 выполняется впустую, так как начальный символ не имеет атрибута).
(c2+c4), и описать процесс построения атрибутного дерева по шагам представленной процедуры (учитывая, что шаг 3 выполняется впустую, так как начальный символ не имеет атрибута).
Пусть даны атрибутная транслирующая грамматика и дерево вывода, полученное с помощью этой грамматики.
Определение 6.6. Последовательность атрибутов символов действия и атрибутов входных символов, полученная по этому дереву вывода, назы-
вается атрибутной последовательностью актов.
Определение 6.7. Атрибутная последовательность действий данной атрибутной последовательности актов называется переводом атрибутов входной цепочки.
Определение 6.8. Множество пар, состоящих из атрибутов входной цепочки и атрибутной последовательности действий, которое получается по данной атрибутной грамматике, называется атрибутным переводом,
определенным этой грамматикой.
Вопросы и задания для контроля к теме 6
1.Введите понятие символа действия.
2.Что представляет собой последовательности актов?
3.Дайте определение транслирующей грамматики.
4.Что понимается под переводом с математической точки зрения?
5.С какой целью строится атрибутная грамматика.
6.Какие типы атрибутов используются в обработке языков?
7.Сформулируйте правила определения синтезируемых атрибутов.
8.Сформулируйте правила определения наследуемых атрибутов.
9.Дайте определения атрибутного перевода.
82
Тема 7. Восходящие методы обработки языков
Рассмотрим использование восходящего подхода для обработки цепочки с помощью МП-автомата.
Принцип восходящих процессоров заключается в том, что они распознают нижние правила грамматики раньше верхних.
Введем понятия, на котором базируется восходящий анализ. Рассмотрим грамматику с начальным символом <S>:
1.<S> (<A><S>)
2.<S> (b)
3. |
<A> |
(<S>a <A>) |
4. |
<A> |
(a) |
Эта грамматика однозначна, так как каждая цепочка порожденная ею имеет одно дерево вывода и один правый вывод.
Рассмотри цепочку (((b)a(a))(b)).
Дерево вывода этой цепочки приведено на рис. 7.1.
Рис. 7.1. Дерево вывода цепочки (((b)a(a))(b))
Правый вывод:
<S>1 (<A><S>2) (<A>3(b)) ((<S>a<A>4)(b)) ((<S>2a(a))(b)) 
(((b)a(a))(b))
При восходящем анализе имеет место обращение правого вывода [3]. Для рассмотренного выше примера это обращение выглядит так:
(((b) a (a)) (b))
2
((<S> a (a)) (b))
4
((<S>a<A>) (b))
3
(<A> (b))
2
(<A><S>)
1
<S>
83

На каждом шаге вывода вхождение правой части некоторого правила заменятся нетерминалом из левой части этого правила. Каждая подчеркнутая подцепочка называется основой цепочки, в которой та встречается, а соответствующее правило основывающим правилом этой цепочки.
В общем случае:
Определение 7.1. Основа цепочки (состоящая из терминала и нетерминала) это вхождение правой части последнего правила, примененного в правом выводе этой цепочки.
Определение 7.2. Основывающее правило цепочки 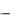 это последнее правило, примененное в правом выводе этой цепочки.
это последнее правило, примененное в правом выводе этой цепочки.
Если грамматика однозначна, то у цепочки может быть не более одного правого вывода, а значит, не более одной основы и основного правила.
Цепочка может и не иметь основы. Например, цепочка (a)) вообще не выводима и следовательно не имеет основы.
Цепочка ((а) <S>) имеет вывод <S>1 (<A>4<S>) ((a) <S>), но у нее нет правого вывода и, значит, нет основы.
Правый вывод можно интерпретировать как построение дерева вывода. Замена нетерминала правой частью одного из его правил соответствует добавлению символов правой части в качестве вершин дерева, «подвешенных» снизу к вершине, соответствующей заменяемому нетерминалу.
Аналогично обращение правого вывода можно понимать как подрезку дерева вывода, которая состоит в удалении листьев (вершин дерева, не имеющих потомков) дерева, составляющих правую часть правила.
При обращении правого вывода всегда подрезается самая левая из допускающих подрезку вершин.
Проиллюстрируем принцип работы МП-автомата при обработке цепочек «снизу вверх», на примере языка задаваемого грамматикой, описанной выше.
МП-автомат будет использовать пять операций для манипулирования магазином и входной цепочкой: ПЕРЕНОС, СВЕРТКА(1), СВЕРТКА(2), СВЕРТКА(3), СВЕРТКА(4).
ПЕРЕНОС переносит текущий входной символ на верх магазина и осуществляет сдвиг во входной цепочке (кроме ).
СВЕРТКА (p), для p = 1, 2, 3, 4 выбирается в тех случаях, когда верхние символы магазина совпадают с правой частью правила под номером (p). Эта операция выталкивает из магазина все символы правой части правила p, а затем вталкивает в магазин его левую часть.
Например, СВЕРТКА(1): ВЫТОЛКНУТЬ, ВЫТОЛКНУТЬ, ВЫТОЛКНУТЬ, ВЫТОЛКНУТЬ, ВТОЛКНУТЬ (<S>).
Операция СВЕРТКА (p) изменяет цепочку получаемую конкатенацией содержимого магазина и необработанной части входной цепочки, заменяя вхождение правой части правила под номером p на его левую часть.
84

Операция свертки не примитивная, следовательно, МП-автомат не примитивный.
Приведем последовательность конфигураций автомата для входной цепочки (((b) a (a))(b)):
№ шага |
Содержимое магазина |
Входная цепочка |
Операция |
1 |
|
(((b) a (a)) (b)) |
ПЕРЕНОС |
|
|
|
|
2 |
( |
((b) a (a)) (b)) |
ПЕРЕНОС |
3 |
(( |
(b) a (a)) (b)) |
ПЕРЕНОС |
4 |
((( |
b) a (a)) (b)) |
ПЕРЕНОС |
5 |
(((b |
) a (a)) (b)) |
ПЕРЕНОС |
6 |
(((b) |
a (a)) (b)) |
СВЕРТКА (2) |
7 |
((<S> |
a (a)) (b)) |
ПЕРЕНОС |
8 |
((<S> a |
(a)) (b)) |
ПЕРЕНОС |
9 |
((<S> a ( |
a)) (b)) |
ПЕРЕНОС |
10 |
((<S> a (a |
)) (b)) |
ПЕРЕНОС |
11 |
((<S> a (a) |
) (b)) |
СВЕРТКА (4) |
12 |
((<S> a <A> |
) (b)) |
ПЕРЕНОС |
13 |
((<S> a <A>) |
(b)) |
СВЕРТКА (3) |
14 |
(<A> |
(b)) |
ПЕРЕНОС |
15 |
(<A> ( |
b)) |
ПЕРЕНОС |
16 |
(<A> (b |
)) |
ПЕРЕНОС |
17 |
(<A> (b) |
) |
СВЕРТКА (2) |
18 |
(<A><S> |
) |
ПЕРЕНОС |
19 |
(<A><S>) |
|
СВЕРТКА (1) |
|
|
|
|
20 |
<S> |
|
ДОПУСТИТЬ |
|
|
|
Автомат допускает входную цепочку, так как он убедился, что входная цепочка выводима из <S>.
На каждом шаге процесса обработки старая, представленная в автомате цепочка или совпала с новой представленной цепочкой, или может быть выведена из исходных применением одного правила.
Построим управляющую таблицу МП-автомата:
|
( |
a |
B |
) |
|
<S> |
|
|
|
|
|
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ОПОЗНАНИЕ2 |
|
<A> |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ОПОЗНАНИЕ2 |
( |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ОПОЗНАНИЕ2 |
) |
ОПОЗНАНИЕ1 |
ОПОЗНАНИЕ1 |
ОПОЗНАНИЕ1 |
ОПОЗНАНИЕ1 |
ОПОЗНАНИЕ1 |
b |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ОПОЗНАНИЕ2 |
a |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ОПОЗНАНИЕ2 |
|
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ПЕРЕНОС |
ОПОЗНАНИЕ2 |
Начальное содержимое магазина: 
85

ОПОЗНАНИЕ1: если на верху магазина (<A><S>), то СВЕРТКА(1), иначе если наверху магазина (b), то СВЕРТКА(2), иначе если на верху магазина (<S> a <A>), то СВЕРТКА(3), иначе если на верху магазина (a), то СВЕРТКА(4), иначе ОТВЕРГНУТЬ.
ОПОЗНАНИЕ2: если на верху магазина <S>, то ДОПУСТИТЬ, иначе ОТВЕРГНУТЬ.
ПЕРЕНОС: ВТОЛКНУТЬ(текущий входной символ), СДВИГ, СВЕРТКА(1), СВЕРТКА(2), СВЕРТКА(3), СВЕРТКА(4) описаны
выше.
Работа автомата основана на том, что, если вся входная цепочка допустима, то цепочка, представленная магазином и необработанной частью входа, является промежуточной цепочкой в правом выводе входной цепочки.
Автомат переносит входные символы в магазин до тех пор, пока в его верхней части не окажется основа представленной им цепочки. Затем автомат выполняет операцию СВЕРТКА, соответствующую основывающему правилу. Эта операция заменяет основу левой частью основывающего правила.
Для характеристики этого метода распознавания используют термин «восходящий», потому что правила для потомков любого нетерминала в дереве распознаются раньше, чем правило для него самого.
Для реализации процедуры ОПОЗНАНИЯ существуют несколько методов. Рассмотрим некоторые из них.
Метод «Перенос-свертка»
Автомат, реализующей метод «Перенос-свертка», использует расширенный магазинный алфавит для кодирования дополнительной информации о магазине.
Закодированной информации достаточно, чтобы по верхнему символу магазина и текущему входному символу выяснить, находится ли основа в верхней части магазина, и, если да, то определить основывающее правило, не просматривая других символов магазина.
Опишем разработку МП-автомата, реализующего метод «переноссвертка», для приведенной выше грамматики:
1.<S> (<A><S>)
2.<S> (b)
3.<A> (<S> а <A>)
4.<A> (a)
Магазинный алфавит такого автомата состоит из 14 символов: каждый магазинный символ понимается одновременно как представление грамматического символа и кода цепочки:
86

Грамматический символ |
Магазинный символ |
Кодируемая цепочка |
|
|
|
|
|
a |
a1 |
(<S>a |
|
a2 |
(a |
||
|
|||
|
|
|
|
b |
b1 |
(b |
|
( |
(1 |
( |
|
|
)1 |
(<A><S>) |
|
|
|
|
|
) |
)2 |
(b) |
|
)3 |
(<S>a<A>) |
||
|
|||
|
)4 |
(a) |
|
|
|
|
|
|
<S>1 |
(<A><S> |
|
<S> |
<S>2 |
(<S> |
|
|
<S>3 |
<S> |
|
|
|
|
|
<A> |
<A>1 |
(<A> |
|
<A>2 |
(<S>a<A> |
||
|
|||
нет |
|
|
|
|
|
|
Каждый магазинный символ представляет грамматический символ, полученный из него отбрасыванием индекса.
Самым правым символом каждой кодируемой цепочки является грамматический символ, представленный магазинным символом.
Описываемый МП-автомат построен так, что магазинный символ вталкивается в магазин только тогда, когда кодируемая этим символом цепочка совместима с цепочкой, которую будет представлять магазин после вталкивания.
Говорят, что цепочка, кодируемая данным символом магазина, совместима с цепочкой, представляемой символами магазина, расположенными ниже данного символа и включая его самого, если выполнено одно из следующих условий:
1) кодируемая цепочка является суффиксом цепочки, представленной магазином;
2) кодируемая цепочка является конкатенацией и цепочки, представленной магазином.
Например, если магазин содержит (1 (1 <S>2 a1
автомат мог бы втолкнуть символ <A>2 , получив новое содержимое
(1 (1 <S>2 a1<A>2
Символ, который втолкнул автомат, совместим с новым содержимым магазина, так как четыре верхних символа магазина представляют цепочку, закодированную символом <А>2.
Символ <А>1 – не совместим.
Магазинный алфавит построен так, что для каждого магазинного символа, за исключением <S>3 и , кодируемая цепочка является префик-
87

сом правой части некоторого правила. И наоборот, каждый непустой префикс правой части кодируется магазинным символом.
Таким образом, управление МП-автоматом осуществляется при помощи 2-х таблиц: обычной управляющей таблицей и таблицей вталкивания.
Таблица вталкивания предназначена для определения того, какой из магазинных символов, представляющих данный грамматический символ, нужно втолкнуть.
Таблица вталкивания для рассмотренного выше примера:
|
a |
b |
( |
) |
<S> |
<A> |
a1 |
|
|
(1 |
|
|
<A>2 |
a2 |
|
|
(1 |
)4 |
|
|
b1 |
|
|
(1 |
)2 |
|
|
(1 |
a2 |
b1 |
(1 |
|
<S>2 |
<A>1 |
<S>1 |
|
|
(1 |
)1 |
|
|
<S>2 |
a1 |
|
(1 |
|
|
|
<S>3 |
|
|
(1 |
|
|
|
<A>1 |
|
|
(1 |
|
<S>1 |
|
<A>2 |
|
|
(1 |
)3 |
|
|
|
|
|
(1 |
|
<S>3 |
|
Каждый непустой элемент таблицы указывает символ, который нужно втолкнуть для данной комбинации символа магазина и символа грамматики.
Пустые элементы в таблице относятся к комбинациям, при которых автомат отвергает входную цепочку.
Таблица не содержит строк для магазинных символов )1 , )2 , )3 , )4, так как в данной схеме управления никогда не делается попыток втолкнуть символ, если на верху магазина – правая скобка.
В результате можно сформулировать следующий принцип работы МП-автомата: если конкатенация грамматического символа и префикса, закодированного магазинным символом, дает новый префикс, то вталкивается тот магазинный символ, который кодирует этот новый префикс.
Если же конкатенация не дает нового префикса, значит обнаружена недопустимая комбинация входных символов и автомат отвергает входную цепочку.
Метод «Перенос-опознание»
Будем рассматриватьоднозначные грамматики, не содержащие -правил. Рассмотрим сначала задачу определения элементов таблицы управления: какие из них должны содержать ПЕРЕНОС, какие – ОПОЗНАНИЕ, ка-
кие – ОТВЕРГНУТЬ.
88

Предположим, что имеется МП-автомат для данной грамматики с начальным символом <S>. На каждом шаге обработки этим автоматом некоторой входной цепочки справедливо в точности одно из следующих утверждений:
1. Входная цепочка допустима, и верхняя часть магазина представляет основу цепочки, представляемой магазином и еще не обработанными входными символами.
2. Входная цепочка допустима, содержимое магазина – <S>, и текущий входной символ – концевой маркер.
3.Входная цепочка допустима, текущий входной символ – не концевой маркер, и верхняя часть магазина не представляет основу представленной в автомате цепочки.
4.Входная цепочка недопустима.
Каждый раз, когда автомат достигает конфигурации, описываемой одним из первых двух утверждений, он должен выбрать процедуру опознания. Выбор осуществляется с помощью управляющей таблицы, исходя из верхнего символа магазина и текущего входного символа.
Каждый раз при достижении автоматом конфигурации, описываемой утверждением 3, он должен выбрать операцию ПЕРЕНОС. Утверждение 4 – ОТВЕРГНУТЬ.
Для того чтобы решить, какие элементы управляющей таблицы должны содержать ПЕРЕНОС, а какие – процедуры опознания, разработчик должен проанализировать грамматику и предвидеть, какие элементы таблицы могут встретиться в конфигурациях, описываемых утверждениями 1 или 2, и какие – в конфигурациях, соответствующих утверждению 3. Для некоторых грамматик такой анализ показывает, что некоторые элементы таблицы могут встретиться как в ситуации, описываемой утверждением 1 или 2, так и в ситуации, описываемой утверждением 3. В этом случае из приведенных выше аргументов следует, что табличный элемент должен содержать и ПЕРЕНОС, и процедуру опознания.
Как средство анализа грамматик можно использовать понятия множеств первых и следующих символов.
По данной контекстно-свободной грамматике с начальным символом <S> и по символу грамматики х определим два множества:
1. СЛЕД (х)
– множество входных символов (возможно, включающее ), которые могут непосредственно следовать за х в некоторой промежуточной цепочке, выводимой из <S> ,
2. ПЕРВ (х)
– множество тех символов грамматики, которые встречаются в начале промежуточных цепочек, выводимых из х.
За исключением тривиальных различий, эти определения совпадают с введенными ранее определениями множеств СЛЕД и ПЕРВ. Вычисления
89