

g30zAZLYUG
.pdfного потомка Z. Тогда достаточно позаботиться о том, чтобы вершина U ссылалась теперь на Z, а не на V, после чего командой
free(<adres V>);
очистить участок памяти, занятый вершиной V.
Сложность третьей ситуации в том, что с помощью одной ссылки (от предка удаляемой вершины) нельзя указать сразу два направления (к обоим потомкам удаляемой вершины). В этом случае удаляемый элемент за-
меняют либо на самый правый элемент его левого поддерева, либо на самый левый элемент его правого поддерева. Каждый из этих элементов имеет не более одного потомка, иначе он не был бы самым правым (самым левым), причём их перенос на место удаляемого элемента не нарушает структуру дерева поиска.
Рассмотрим процесс преобразования дерева поиска после удаления вершины с двумя потомками. Пусть удаляется вершина V, имеющая двух потомков. Тогда поиск замещающего элемента W (самого правого элемента левого поддерева вершины V) осуществляется следующим образом: спускаемся вдоль самой правой ветви левого поддерева вершины V до тех пор, пока не найдем вершину с нулевым правым указателем. Найденную вершину выбираем в качестве W. После этого заменяем вершину V на W, цепляя единственного потомка вершины W (если он есть) к предку этой вершины.
Пример. Пусть из дерева поиска необходимо удалить элемент 10 (рисунок 5.3, а). Удаляемый элемент заменяется самым правым элементом его левого поддерева, т.е. элементом 8. Потомок элемента 8 (элемент 6) цепляется к предку элемента 8 (элементу 5) (рис. 5.3, б).
Оценка сложности
В лучшем случае дерево поиска окажется полным. Высота H этого дерева определит максимальную сложность операций поиска, включения и удаления элементов, которая составит, таким образом,
Tmax(n) = O (log2(n)).
Однако в худшем случае, когда все поступающие из входного потока ключи идут в порядке убывания (или возрастания), дерево выродится в обычный линейный список и максимальная сложность операций поиска, включения и удаления элементов составит
Tmax(n) = O(n),
т.е. преимущества дерева поиска по сравнению с линейным списком будут утрачены.
На лекции в теме «АВЛ-деревья» подробно рассмотрены сбалансированные деревья поиска, рост которых специальным образом контроли-
71

руется. Но в рамках данной лабораторной работы они рассматриваться не будут. Программную реализацию АВЛ-деревьев см., например, в [2].
п. 1. Дихотомический поиск в отсортированном массиве записей
В этом пункте решим следующую задачу: в массиве, упорядоченном по первому полю, найдём студента с заданной фамилией и выведем на экран его оценку за экзамен.
1.1. Откройте проект lab_04, сохранённый в ходе выполнения лабораторной работы № 4.
1.2. В процедуре main закомментируйте вызовы процедуры
Sort_Shell_2 и процедуры Sort_Shell_3, оставив
вызов процедуры сортировки по первому полю Sort_Shell_1 и
печать массива, отсортированного по первому полю.
1.3. В цикл печати внесите следующее изменение: распечатывайте и номер «i» тоже, т.е. строку
cout << myArray[i].surname << "\t" << myArray[i].name << "\t" << myArray[i].ball << "\n";
замените строкой
cout << i << "\t" << myArray[i].surname << "\t" << myArray[i].name << "\t" << myArray[i].ball << "\n";
1.4. В области объявления глобальных переменных (выше текста процедур) добавьте объявление новой строковой переменной (назовём её surname1), имеющей ту же длину, что и поле surname нашей структуры данных:
char surname1[24];
По значению этой переменной и будет производиться поиск в массиве.
1.5. В любом подходящем для этой цели редакторе (например, в блокноте) создайте текстовый файл с именем кеу и поместите туда любую фамилию из списка. Например, Петрунько. Сохраните файл в той же папке, где расположены cpp-файлы Вашего проекта.
1.6. В процедуру main добавьте ввод переменной surname1:
f.open("key.txt"); f >> surname1; f.close();
cout << "Ищем запись с ключом: " << surname1 <<"\n";
72

1.7. Перед процедурой main вставьте рекурсивную процедуру Locate поиска записи по ключу surname1:
int Locate(int first, int last)
{
int number,med; number = -1;
// Работаем, если передано более 1 элемента и искомый элемент не найден if (first <= last && number == -1)
{
med = (first+last) / 2;
if (strcmp(surname1,myArray[med].surname)==0) // Значения совпали { number = med; // Искомый элемент найден
}
else
if (first!=last) // Если вершина не концевая
{
if (strcmp(surname1,myArray[med].surname)==-1)
{
number = Locate(first,med); |
// Продолжить поиск слева |
}
else
{
number = Locate(med+1,last); // Продолжить поиск справа
}
};
};
return(number);
}
На вход рекурсивной процедуры Locate поступают два целочисленных значения:
first – индекс первого передаваемого элемента массива; last – индекс последнего передаваемого элемента массива.
Процедура Locate возвращает целое число number – индекс искомого элемента массива. Если элемент с данным ключом в массиве не найден, то number = -1.
Для сравнения строковых переменных в процедуре используется функция strcmp.
1.8. В процедуре main после ввода переменной surname1 добавьте вызов процедуры Locate и печать возвращённого ею значения:
int num;
num = Locate(0,myArray.size()-1);
cout << "Номер искомой записи = " << num << "\n";
73
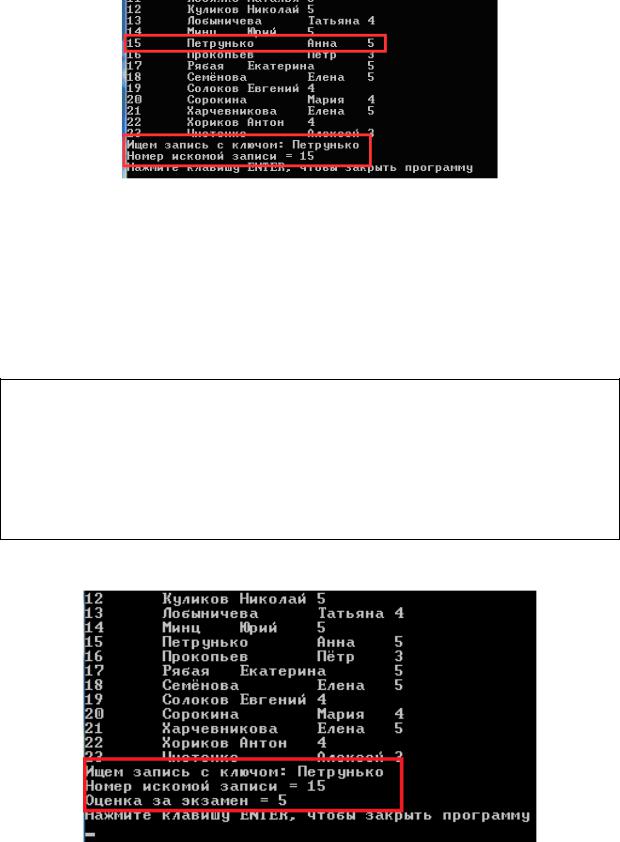
Запустите программу на выполнение, чтобы убедиться, что всё работает правильно.
Действительно, в отсортированном по первому полю массиве запись об Анне Петрунько имеет номер 15.
Поэкспериментируйте, задавая в текстовом файле с именем key другие фамилии. Убедитесь также, что если Вы зададите фамилию, которой нет в списке, то процедура поиска вернёт значение -1.
1.9. По известному индексу элемента мы получили доступ ко всем его полям, в том числе и к полю «ball». Так что для вывода оценки, которую получила на экзамене Анна Петрунько, достаточно одного оператора:
if (num != -1)
{
cout << "Оценка за экзамен = " << myArray[num].ball << "\n";
}
else
{
cout << "Студент с данной фамилией в списке отсутствует\n";
}
Запустите программу на выполнение, чтобы убедиться, что она работает правильно.
74
ЗАДАНИЕ № 1. Дихотомический поиск в отсортированном мас-
сиве
Вернитесь к проекту, в котором Вы выполняли задание лабораторной работы № 4. В отсортированном по первому полю массиве с помощью процедуры Locate (модифицированной под Ваш набор данных) организуйте поиск элемента с заданным значением первого поля (как и в рассмотренном выше примере, прочитайте значение переменной, по которой будет производиться поиск, из входного текстового файла).
Выведите на консоль номер записи и значение её третьего поля.
Работающую версию программы, а также программный код, предъявите преподавателю.
п. 2. Дерево поиска на примере задачи подсчёта количества вхождений каждого из элементов входной последовательности
В этом пункте будем решать следующую задачу. Пусть на вход поступает произвольная последовательность элементов. Требуется подсчитать количество вхождений каждого из элементов. Для простоты будем считать, что входная последовательность содержит натуральные числа.
Например, для последовательности вида:
128, 777, 1024, 777, 80808, 128, 1024, 1967, 777, 1967
программа должна вывести на печать такой результат:
128 – 2, 777 – 3, 1024 – 2, 80808 – 1, 1967 – 2.
Решим задачу с помощью дерева поиска. В каждой его вершине будем хранить запись с двумя целочисленными полями:
key – элемент входной последовательности; count – количество вхождений элемента key.
Просматриваем входную последовательность слева направо; прочитав очередное число, ищем его в дереве поиска. Если такого числа в дереве нет, то добавляем новую вершину, в поле key заносим вновь введённое число, а в поле count заносим 1. Если такое число найдено, то увеличиваем на единицу значение поля count.
После того как дерево построено, остаётся выполнить его обход и распечатать информацию, хранящуюся в каждой из вершин.
2.1.Создайте новый проект (см. пункты 1.1–1.7 лабораторной работы
№2). Имя проекта, например, lab_05.
2.2.После строки
using namespace std;
75

в области объявления глобальных типов и переменных вставьте объявление нового типа данных:
typedef struct SearchTree
{
int key; |
// Целочисленный ключ |
int count; |
// Счётчик количества элементов с ключом key |
struct SearchTree *lptr; // Указатель на левое поддерево struct SearchTree *rptr; // Указатель на правое поддерево
} NODE;
2.3. Сразу под объявлением нового типа NODE задайте объявление указателя на корень дерева:
NODE *proot;
2.4. Чтобы создать пустое, не содержащее ни одного элемента, дерево, надо обнулить указатель на его корень. Для этого в начало процедуры main добавьте оператор:
proot=NULL; |
// Создание пустого дерева |
|
|
2.5. Непосредственно перед процедурой main вставьте заготовки для процедур
поиска элемента с включением его в дерево,
удаления элемента из дерева,
печати дерева.
void SearchOrAdd(int y, NODE *&pv)
{
//Поиск с включением
}
void Delete(int y, NODE *&pv)
{
//Удаление элемента
}
void PrintInOrder(int tab, NODE *&pv)
{
// Печать дерева во внутреннем порядке
}
76

2.6. В процедуре main создайте пользовательское меню, аналогичное меню для списка с двумя связями:
int y;
int choice; label_1:
cout << "Введите цифру:" << "\n" <<
"Добавить элемент " << "\t" << "0" << "\n" << "Удалить элемент " << "\t" << "1" << "\n" <<
"Распечатать содержимое дерева" << "\t" << "2" << "\n" << "Закончить" << "\t" << "3" << "\n";
cin >> choice; cin.ignore(); switch (choice)
{
case 0: cout << "Введите добавляемое число\n"; cin >> y;
cin.ignore();
SearchOrAdd(y,proot);
PrintInOrder(0,proot);
break;
case 1: if (proot != NULL)
{
cout << "Введите удаляемое число\n"; cin >> y;
cin.ignore();
Delete(y,proot);
PrintInOrder(0,proot);
}
break;
case 2: if (proot != NULL)
{
PrintInOrder(0,proot);
}
break; case 3: break;
// default: break;
};
if (choice != 3) goto label_1;
2.7. Приступим к разработке рекурсивной процедуры SearchOrAdd (поиск с включением). Начиная с корня дерева, процедура ищет элемент с ключом «y». Здесь возможны следующие ситуации: двигаясь по дереву поиска,
77

в конце концов «упёрлись» в нулевой указатель. Это означает, что элемента с ключом «y» в дереве нет. Тогда выделяем место в памяти под новый элемент и заполняем его поля;
добрались до вершины V, у которой ключевой элемент больше либо равен «y». Значит, продолжаем поиск в левом поддереве вершины V;
добрались до вершины V, у которой ключевой элемент меньше либо равен «y». Следовательно, продолжаем поиск в правом поддереве вершины V;
добрались до вершины V, у которой ключевой элемент совпал с «y». Значит, наращиваем счётчик.
Окончательно, процедура SearchOrAdd выглядит так:
void SearchOrAdd(int y, NODE *&pv) // Поиск с включением
{
if (pv==NULL) // Элемента с ключом "y" в дереве не найдено
{
//Выделяем место в памяти под новую переменную типа NODE pv = new NODE;
//По адресу pv в поле ключа помещаем введённое число
pv->key = y;
// По адресу pv в поле счётчика помещаем единицу pv->count=1;
//По адресу pv в поля указателей помещаем нули, т.к.
//вновь добавленная вершина - концевая
pv->lptr=NULL; pv->rptr=NULL;
}
else
{
if(y<pv->key)
{// Продолжить поиск в левом поддереве
SearchOrAdd(y, pv->lptr);
}
else
if(y>pv->key)
{// Продолжить поиск в правом поддереве
SearchOrAdd(y, pv->rptr);
}
else
{// Нашли элемент с ключом "y"; наращиваем счётчик pv->count++;
};
};
}
78

2.8. Займёмся процедурой вывода дерева на экран. Чтобы не переводить устройство в графический режим, «положим дерево на бочок», т.е. развернём его на 90 градусов против часовой стрелки.
Например, дерево поиска, изображённое на рисунке 5.4, а, будем выводить на экран в виде, представленном на рисунке 5.4, б.
а |
б |
Рис. 5.4. Дерево поиска
Печать дерева можно организовать рекурсивно, используя обход во внутреннем порядке:
от текущей позиции tab сдвинуться вправо на 5 символов и напечатать ППД;
от текущей позиции tab напечатать корень;
от текущей позиции tab сдвинуться вправо на 5 символов и напечатать ЛПД.
При первоначальном вызове процедуры печати надо положить tab=0; тогда корневой элемент будет прижат к левому краю окна вывода.
Изложенные соображения и реализованы в приведённом ниже коде:
void PrintInOrder(int tab, NODE *&pv) |
// Печать во внутреннем порядке |
{ |
|
int i;
if (pv != NULL)
{
// Отступить слева tab+5 позиций и напечатать правое поддерево
PrintInOrder(tab+5,pv->rptr);
// Отступить слева tab позиций
for (i=1; i<=tab; i++) cout << " ";
// Напечатать ключ и счётчик (в скобках) текущей вершины cout << pv->key << " (" << pv->count << ")"; cout << "\n";
// Отступить слева tab+5 позиций и напечатать левое поддерево
PrintInOrder(tab+5,pv->lptr);
}
}
79
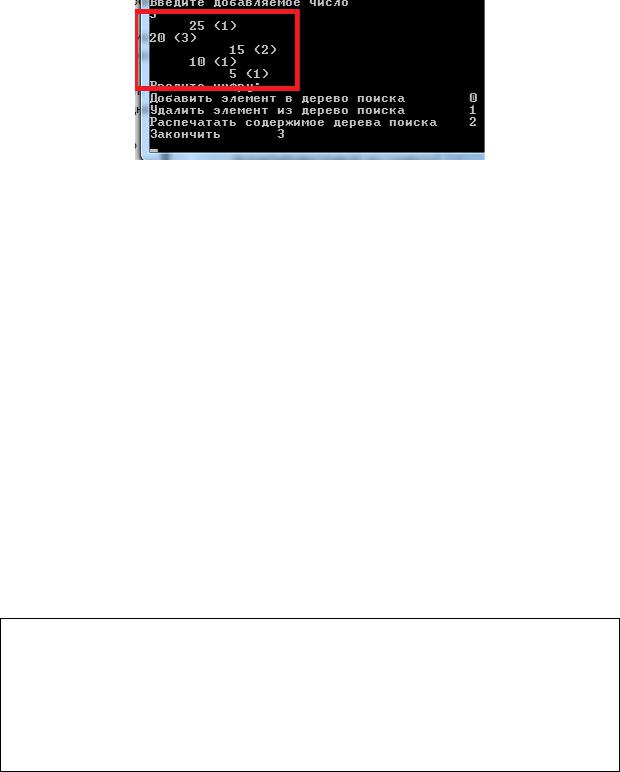
Запустите программу на выполнение. Используя пользовательское меню, последовательно добавьте следующие элементы:
20, 10, 15, 20, 20, 25, 15, 5.
Проследите за «ростом» дерева. В скобках указано количество вхождений каждого элемента. Если Вы всё сделали правильно, то должно получиться такое вот дерево:
2.9. Поставленная задача выполнена, но чтобы полностью усвоить приёмы работы с деревом поиска, Вам необходимо научиться удалять элементы. Займёмся процедурой Delete.
Двигаясь от корня вдоль пути поиска, ищем удаляемый элемент. Если элемент найден, то, в первую очередь, проверяем значение
счётчика count. Если это значение больше единицы, то просто уменьшаем его на единицу (количество вхождений элемента сократилось).
Впротивном случае элемент необходимо исключить из дерева поиска. Тогда перегружаем адрес удаляемого элемента в буфер buf (чтобы потом, как обычно, с помощью оператора free очистить место, занимаемое удаляемым элементом) и начинаем анализировать ситуацию. Здесь возможны три принципиально различные случая:
у удаляемой вершины нет левого поддерева или она концевая, т.е. у неё нет ни левого, ни правого поддерева;
у удаляемой вершины нет правого поддерева;
у удаляемой вершины присутствуют оба потомка.
Впервом случае на место удаляемой вершины помещаем её правого потомка. Во втором случае на место удаляемой вершины помещаем её левого потомка. В третьем случае вызываем процедуру Del, о которой пойдёт речь в следующем пункте.
void Delete(int y, NODE *&pv) // Удаление элемента
{
NODE *buf; if (pv!=NULL)
{
if(y<pv->key)
{
80