

3.2. Исключение дублирования записей
Важным требованием к реляционным таблицам является отсутствие дублирования записей. При наличии дублирования результаты анализа данных могут быть противоречивы, не соответствовать действительности.
В электронных таблицах, текстовых файлах данные могут быть выделены цветом, шрифтом, заполнением. Таким образом, придается различный смысл разным группам данных, даже если эти данные совпадают. В базах данных это невозможно и поэтому дублирование записей недопустимо.
Рассмотрим фрагмент реальной электронной таблицы с повторяющимися записями, представленной на рис. 3.8.
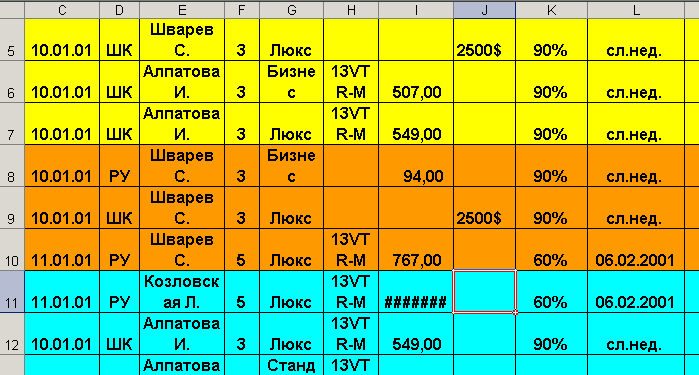
Рис. 3.3. фрагмент реальной электронной таблицы с повторяющимися записями
Здесь повторяются записи с номерами строк 7 и 12, а также записи с номерами строк 5 и 9. Цветом выделены регионы, поэтому пользователям электронных таблиц ясно, чем отличаются повторяющиеся записи. Интересно также отметить, что в последнем столбце дата введена явно некорректно, что еще раз подтверждает актуальность задачи, рассмотренной в предыдущем параграфе.
При использовании таблиц такого рода в БД необходимо сформировать таблицу регионов, таблицу записей, отражающих основные данные, удалить дублирование в основной таблице и организовать связи между таблицами. Перечисленные действия связаны с вопросами нормализации и организации связи между таблицами. Эти вопросы будут рассмотрены позже в соответствующих главах.
Выше рассмотрено дублирование записей, которое не обусловлено смысловыми ошибками, но дублирование может быть и другого рода, когда пользователь электронной таблицы ввел неоднократно одни и те же данные. Такая ситуация вполне возможна при наличии нескольких сотен записей в таблице.
В любом случае перед использованием таблиц в БД необходимо устранить в них дублирование записей.
После импорта исходной таблицы в БД таблица с повторяющимися записями в формате БД примет вид, приведенный на рис. 3.9.

Рис. 3.9. Таблица с повторяющимися записями в формате БД
Чтобы выявить повторяющиеся записи можно построить запрос на SQL, который имеет следующий вид.
SELECT First(Предложения.Поле1) AS [Поле1 поле], First(Предложения.Поле2) AS [Поле2 поле], First(Предложения.Поле3) AS [Поле3 поле], First(Предложения.Поле4) AS [Поле4 поле], First(Предложения.Поле5) AS [Поле5 поле], First(Предложения.Поле6) AS [Поле6 поле], First(Предложения.Поле7) AS [Поле7 поле], First(Предложения.Поле8) AS [Поле8 поле], First(Предложения.Поле9) AS [Поле9 поле], First(Предложения.Поле10) AS [Поле10 поле], Count(Предложения.Поле1) AS Повторы
FROM Предложения
GROUP BY Предложения.Поле1, Предложения.Поле2, Предложения.Поле3, Предложения.Поле4, Предложения.Поле5, Предложения.Поле6, Предложения.Поле7, Предложения.Поле8, Предложения.Поле9, Предложения.Поле10
HAVING (((Count(Предложения.Поле1))>1) AND ((Count(Предложения.Поле10))>1));
Несмотря на то, что запрос занимает немало строк, он несложен по сути – из таблицы “Предложения” выбираются первые значения всех полей ( First(Предложения.Поле1) ) и этим значениям присваивается имя ( AS [Поле1 поле] ) . Выводимые данные группируются по этим значения ( конструкция GROUP BY). С помощью конструкции HAVING выводятся только те строки, в которых имеются повторения (((Count(Предложения.Поле1))>1) AND ((Count(Предложения.Поле10))>1))
Результат выполнения запроса на выборку повторяющихся записей представлен на рис. 3.10. В отдельном столбце ”Повторы” выводятся количества повторений соответствующих записей в таблице.

Рис. 3.10. Результат выполнения запроса на выборку повторяющихся записей
Следует отметить, что в некоторых СУБД, например в Microsoft Access, запрос такого рода строится просто - с помощью специального мастера ”Повторяющиеся записи”.
Как видно из рисунка 3.10, таких записей в таблице оказалось две. При небольшом количестве повторяющихся записей, как в данном случае, проще всего их удалить вручную. Для значительного числа повторяющихся записей оправданно использование специально ориентированных средств.
Предлагается алгоритм исключения повторяющихся записей на основе использования списка повторяющихся записей. Он выглядит следующим образом.
FOR i = 1 TO k
S = SP i
C = C(SP i) - 1
FOR j = 1 TO n
IF (SNj = S) AND (C > 0) THEN
DELETE (SNj)
C = C - 1
END IF
NEXT j
NEXT i
Здесь k – число повторяющихся записей;
n – число записей в исходной таблице;
SPi – i-я, текущая запись в таблице повторяющихся записей;
C(SP i) – количество повторений i-й записи;
SNj - j-я, текущая строка в исходной таблице;
DELETE (SNj) – оператор удаления j-ой записи в исходной таблице;
В соответствии с алгоритмом удаляются не все повторяющиеся записи, а только лишние, поэтому и задействован оператор C = C(SP i) - 1.
Как видно из алгоритма, большинство его команд соответствуют командам языка программирования Basic. Вероятно, что алгоритм будет реализовываться в рамках СУБД Microsoft Access, а в нем в качестве алгоритмического языка программирования используется Visual Basic.
Следует отметить, что, несмотря на кажущуюся простоту алгоритма, его реализация нетривиальна. В частности еще предстоит решить, каким программным путем осуществлять последовательную выборку записей обеих таблиц, их сравнение и удаление.
Вычислительную сложность алгоритма можно существенно понизить и преобразовать его к следующему виду.
FOR i = 1 TO k
S = SP i
C = C(SP i) - 1
FOR j = 1 TO n
IF (SNj = S) AND (C > 0) THEN
DELETE (SNj)
C = C - 1
END IF
IF C = 0 THEN
EXIT FOR
END IF
NEXT j
NEXT i
Добавление конструкции “IF C = 0 THEN EXIT FOR” позволяет после исключения повторяющихся строк не сканировать вхолостую оставшиеся строки исходной таблицы, а завершить внутренний цикл.
Если допускается переименование таблицы с повторяющимися записями, то практически во всех СУБД можно построить запрос, который формирует на основе исходной таблицы новую таблицу, но без повторяющихся записей. Запрос для таблицы, представленной на рис. 3.9, имеет вид.
SELECT DISTINCT Таблица1.* INTO Таблица2
FROM Таблица1;
Здесь все поля Таблицы1 (Таблица1.*) добавляются к Таблица2 (INTO Таблица2) из Таблицы1 (FROM Таблица1). При этом посредством конструкции ”DISTINCT” в Таблицу2 добавляются только уникальные значения.
После выполнения запроса Таблица2 примет вид рис 3.11.

Рис.3.6. Таблица без повторяющихся записей
Если не допускается переименование таблицы с повторяющимися записями, то рассмотренный запрос на создание новой таблицы тоже можно использовать, но с обязательным выполнением дополнительных мероприятий. Эти мероприятия заключаются в удалении исходной таблицы и переименовании полученной таблицы.
Подобные средства, конечно, предпочтительно использовать, если данные представлены в формате какой-либо СУБД,