

Кодирование в телекоммуникационных системах.-2
.pdf81
необходимы дополнительные затраты на сохранение целостности индексов в нем, в целом это дает очень существенный выигрыш потому, что отсутствует постоянное сдвигание большого блока памяти. Если размер кольцевого буфера равен степени двойки, то стандартная для кольцевого буфера операция “смещение по модулю размер”, может быть заменена побитовой логической операцией, что еще больше повышает эффективность.
Помимо проблем с быстродействием, у алгоритма LZ77 возникают проблемы с самим сжатием. Они появляются, когда кодер не может найти совпадающую подстроку в словаре и выдает стандартный 3-компонентный код, пытаясь закодировать один символ. Если словарь имеет длину 4К, а буфер — 16 байтов, то код <0, 0, символ> будет занимать 3 байта.
Кодирование одного байта в три имеет мало общего со сжатием и существенно понижает производительность алгоритма.
Упрощенный алгоритм LZ77
пока (буфер_предпросмотра не пуст) найти наиболее длинное соответствие
(позиция_начала, длина) в буфере_предыстории и в буфере_предпросмотра; если
(длина>минимальной_длины), то вывести в кодированные данные пару (позиция_начала,
длина); иначе вывести в кодированные данные первый символ буфера_предпросмотра;
изменить указатель на начало буфера_предпросмотра и продолжить.
Алгоритм LZ78
Этот алгоритм генерирует на основе входных данных словарь фрагментов, внося туда фрагменты данных (последовательности байт) по определенным правилам и присваивает фрагментам коды (номера). При сжатии данных (поступлении на вход программы очередной порции) программа на основе LZ78 пытается найти в словаре фрагмент максимальной длины, совпадающий с данными, заменяет найденную в словаре порцию данных кодом
фрагмента и дополняет словарь новым фрагментом. При заполнении всего словаря
(размер словаря ограничен по определению) программа очищает словарь и начинает процесс заполнения словаря снова. Реализации этого метода различаются конструкцией словаря,
алгоритмами его заполнения и очистки при переполнении.
Обычно, при инициализации словарь заполняется исходными (элементарными)
фрагментами всеми возможными значениями байта от 0 до 255.
Это гарантирует, что при поступлении на вход очередной порции данных будет найден в словаре хотя бы однобайтовый фрагмент.
Алгоритм LZ78 резервирует специальный код, назовем его «Reset», который вставляется в упакованные данные, отмечая момент сброса словаря. Значение кода Reset обычно принимают равным 256.
82
Таким образом при начале кодирования минимальная длина кода составляет 9 бит.
Максимальная длина кода зависит от объема словаря – количества различных фрагментов,
которые туда можно поместить. Если объем словаря измерять в байтах (символах), то очевидно, что максимальное количество фрагментов равно числу символов, а,
следовательно, максимальная длина кода равна log2 (объем словаря в байтах).
Проведение эксперимента и обработка результатов
Кодирование фразы алгоритмом LZ77 со следующими размерами СЛОВАРЬ/БУФЕР Таблица 2.3. Варианты расчетных заданий
ФРАЗА |
|
СЛОВАРЬ/БУФЕР |
|
||
|
|
|
|
|
|
«IDI TYDA, |
|
|
|
|
|
NE ZNAU |
8/5 |
12/5 |
12/8 |
16/8 |
|
KUDA» |
|||||
|
|
|
|
||
|
|
|
|
|
|
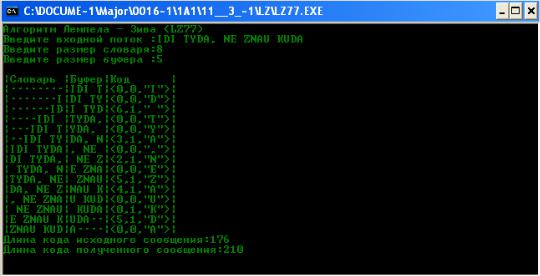
Используем ввод фразы с клавиатуры в программе LZ77.EXE для разных размеров словаря/буфера:
Рис. 2.9. Ввод фразы с клавиатуры для размеров 8/5
83
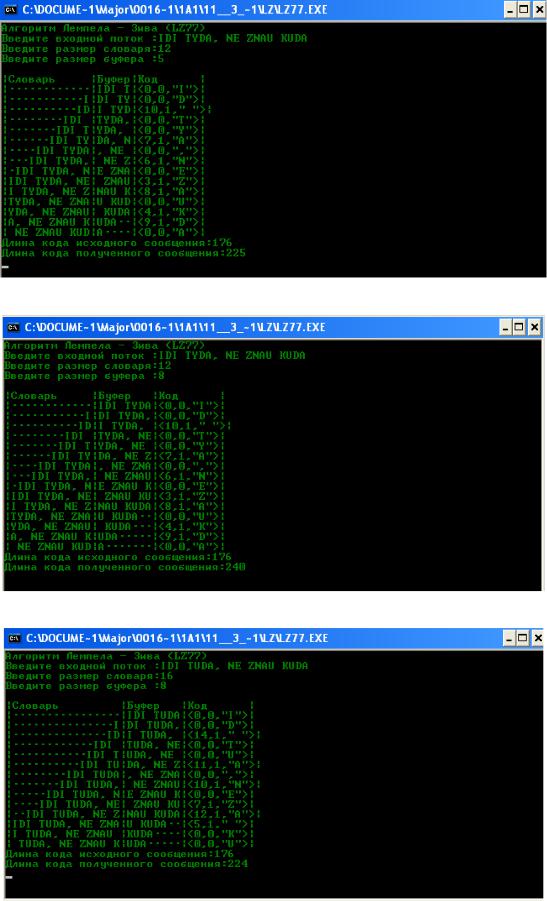
Рис. 2.10. Ввод фразы с клавиатуры для размеров 12/5
Рис. 2.11. Ввод фразы с клавиатуры для размеров 12/8
Рис. 2.12. Ввод фразы с клавиатуры для размеров 16/8
84
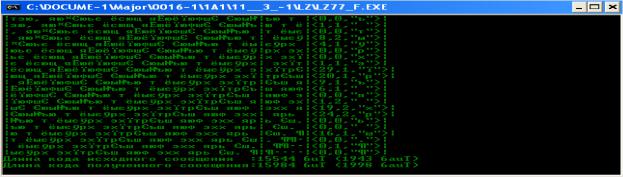
Используем ввод текста из файла для разных размеров словаря/буфера:
Текст: «Полуадаптированное моделирование pешает эту проблему, используя для каждо-
го текста свою модель, котоpая строится еще до самого сжатия на основании результатов предварительного просмотра текста (или его образца). Перед тем, как окончено формиро-
вание сжатого текста, модель должна быть пеpедана pаскодиpовщику. Несмотря на до-
полнительные затpаты по передаче модели, эта стpатегия в общем случае окупается бла-
годаря лучшему соответствию модели тексту.
Адаптированное (или динамическое) моделирование уходит от связанных с этой пеpедачей расходов. Первоначально и кодировщик, и раскодировщик присваивают себе некоторую пустую модель, как если бы символы все были равновероятными. Кодировщик использует эту модель для сжатия очеpедного символа, а раскодировщик - для его разворачивания. Затем они оба изменяют свои модели одинаковым образом (например,
наращивая вероятность рассматриваемого символа). Следующий символ кодируется и достается на основании новой модели, а затем снова изменяет модель. Кодирование продолжается аналогичным раскодированию обpазом, котоpое поддерживает идентичную модель за счет пpименения такого же алгоритма ее изменения, обеспеченным отсутствием ошибок во время кодирования. Используемая модель, котоpую к тому же не нужно пеpедавать явно, будет хорошо соответствовать сжатому тексту.
Адаптированные модели представляют собой элегантную и эффективную технику, и
обеспечивают сжатие по крайней мере не худшее производимого неадаптированными схемами. Оно может быть значительно лучше, чем у плохо соответствующих текстам статичных моделей. Адаптированные модели, в отличии от полуадаптиpованных, не производят их предварительного просмотра, являясь поэтому более привлекательными и лучшесжимающими. Т.о. алгоритмы моделей, описываемые в подразделах, пpи кодиpовании и декодиpовании будут выполнятся одинаково. Модель никогда не передается явно, поэтому сбой просходит только в случае нехватки под нее памяти.»
Рис. 2.13. Ввод текста из файла для размеров 32/5
85
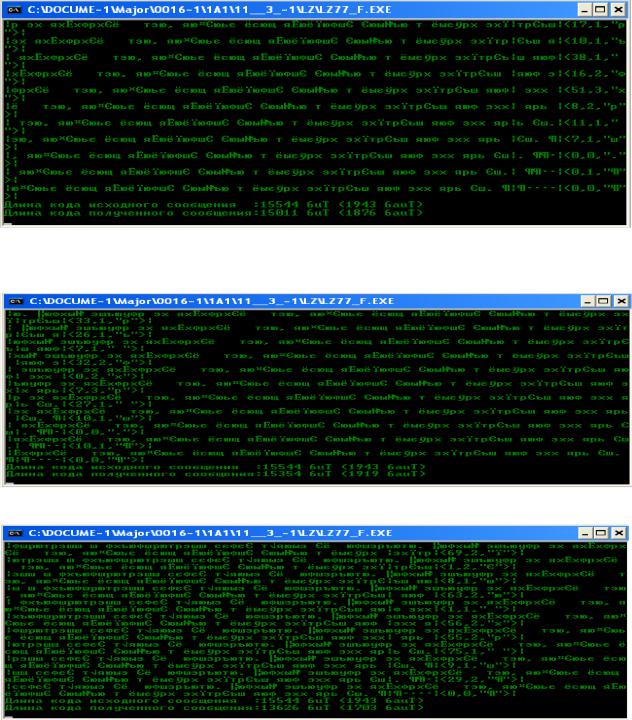
Рис. 2.14. Ввод текста из файла для размеров 64/5
Рис. 2.15. Ввод текста из файла для размеров 80/5
Рис. 2.16. Ввод текста из файла для размеров 128/5
Таблица 2.4. Результаты измерений
Dсловарь |
32 |
64 |
80 |
128 |
|
|
|
|
|
Lвх/Lвых |
0,972 |
1,036 |
1,012 |
1,141 |
|
|
|
|
|
86
140 |
|
|
|
120 |
|
|
|
100 |
|
|
|
80 |
|
|
|
60 |
|
|
|
40 |
|
|
|
20 |
|
|
|
0 |
|
|
|
0,972 |
1,036 |
1,012 |
1,141 |
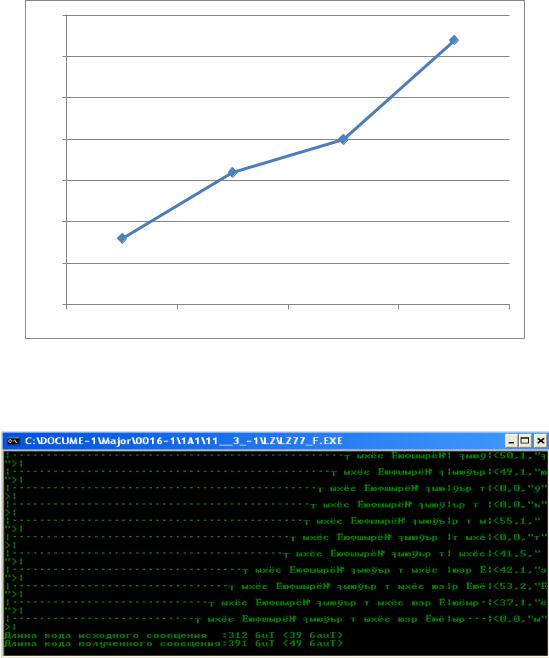
Рис. 2.17. График зависимости коэффициента сжатия от размера словаря |
|||
Кодирование для разной длины текста и одинакового размера словаря 64/5: |
|||
Рис. 2.18. Ввод текста длиной 39 байт
87
Рис. 2.19. Ввод текста длиной 452 байта
Рис. 2.20. Ввод текста длиной 1488 байт
Рис. 2.21. Ввод текста длиной 4292 байта
88
Таблица 2.5. Результаты измерений
Lвх |
39 |
452 |
1488 |
4292 |
|
|
|
|
|
Lвх/Lвых |
0,795 |
0,993 |
1,037 |
1,028 |
|
|
|
|
|
5000 |
|
|
|
4500 |
|
|
|
4000 |
|
|
|
3500 |
|
|
|
3000 |
|
|
|
2500 |
|
|
|
2000 |
|
|
|
1500 |
|
|
|
1000 |
|
|
|
500 |
|
|
|
0 |
|
|
|
39 |
452 |
1488 |
4292 |
Рис. 2.22. График зависимости коэффициента сжатия от размера словаря При кодировании коротких текстов коэффициент сжатия оказывается меньше 1, т.е.
избыточность не удаляется, а вводится еще больше. При увеличении размера словаря коэффициент сжатия увеличивается. Большой размер буфера также ухудшает коэффициент сжатия. Если размер словаря кратен степеням двойки, то сжатие лучше. Однако, при большом размере словаря снижается скорость кодирования. При увеличении размера текста коэффициент сжатия увеличивается.
2.4. Фрактальные методы кодирования изображений
Современные компьютеры весьма интенсивно применяют графику. Операционные системы с интерфейсом оконного типа используют картинки, например, для отображения директорий или папок. Некоторые совершаемые системой действия, например загрузку и пересылку файлов, также отображаются графически. Многие программы и приложения предлагают пользователю графический интерфейс (GUI), который значительно упрощает работу пользователя и позволяет легко интерпретировать полученные результаты.
Компьютерная графика используется во многих областях повседневной деятельности при переводе сложных массивов данных в графическое представление.
89
Фрактал (лат. fractus — дроблёный, сломанный, разбитый) — геометрическая фигура,
обладающая свойством самоподобия, то есть составленная из нескольких частей, каждая из которых подобна всей фигуре целиком. В математике под фракталами понимают множества точек в евклидовом пространстве, имеющие дробную метрическую размерность (в смысле Минковского или Хаусдорфа), либо метрическую размерность, отличную от топологической
[14]. Слово «фрактал» может употребляться не только как математический термин.
Фракталом в прессе и научно-популярной литературе могут называть фигуры, обладающие какими-либо из перечисленных ниже свойств: Обладает нетривиальной структурой на всех масштабах. В этом отличие от регулярных фигур (таких, как окружность, эллипс, график гладкой функции): если мы рассмотрим небольшой фрагмент регулярной фигуры в очень крупном масштабе, он будет похож на фрагмент прямой. Для фрактала увеличение масштаба не ведёт к упрощению структуры, на всех шкалах мы увидим одинаково сложную картину.
Является самоподобной или приближённо самоподобной. Обладает дробной метрической размерностью или метрической размерностью, превосходящей топологическую. Многие объекты в природе обладают фрактальными свойствами, например,
побережья, облака, кроны деревьев, снежинки, кровеносная система и система альвеол человека или животных.
Фракталы, особенно на плоскости, популярны благодаря сочетанию красоты с простотой построения при помощи компьютера. Первые примеры самоподобных множеств с необычными свойствами появились в XIX веке (например, множество Кантора). Термин
«фрактал» был введён Бенуа Мандельбротом в 1975 году и получил широкую популярность с выходом в 1977 году его книги «Фрактальная геометрия природы».
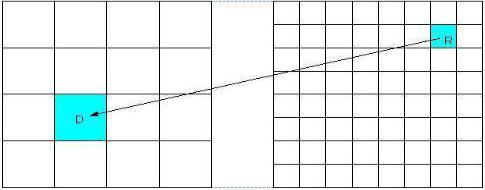
При фрактальном сжатии изображения для области меньшего размера подыскивается похожая на нее область большего размера того же изображения (рисунок 2.23).
Рис. 2.23. Доменный и ранговый блоки
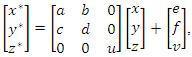
90
Область большого размера называется доменным блоком, а меньшего – ранговым блоком.Перевод доменного блока в ранговый осуществляется посредствомаффинных преобразований, которые в случае изображения в оттенках серого цвета можно представить следующей системой уравнений (2.9):
|
|
|
|
|
|
|
|
|
(2.9) |
|
|
где x, |
y, z – |
соответственно |
координаты |
и |
яркость |
пикселя |
доменного |
блока; |
|
x*, |
y*, |
z* – |
соответственно |
координаты |
и |
яркость |
пикселя |
рангового |
блока; |
|
a, |
b, c, |
d, |
e, |
f – коэффициенты преобразований |
координат на плоскости; |
|||||
u – |
|
|
|
коэффициент |
|
сжатия |
яркости; |
|||
v– сдвиг по яркости.
Врассматриваемых алгоритмах фрактального сжатия и восстановления изображения введенные упрощения позволяют заменить матричные преобразования операциями изменения ориентации доменного блока и операциями расчета яркости пикселей. Изменения ориентации доменного блока осуществляется за счет его поворота на угол кратный 90° и
зеркального отражения и поворота зеркального отражения.
Из всех возможных доменных блоков выбирается блок, ближайший (в выбранной метрике) к рассматриваемому ранговому блоку.
Когда доменный блок найден, то запоминаются его номер и параметры преобразования в текущий ранговый блок, из которых и состоит решение задачи фрактального сжатия.
Ниже, на рисунке 2.32. ,представлен алгоритм фрактального сжатия.