

5 / ИИиМО_ЛР5_decisiontree
.pdfпримеров было распознано неверно, к какие именно примеры были отнесены к какому классу ошибочно. На этот вопрос дает ответ визуализатор «Таблица сопряженности». Очень важно знать, каким образом каждый фактор влияет на классификацию. Такую информацию предоставляет визуализатор «Значимость атрибутов».
Рисунок 13 – Настройка алгоритма «Дерево решений»
(способы отображения)
Проанализируем данные на полученных визуализаторах. Для начала посмотрим на таблицу сопряженности.
Рисунок 14 – Таблица сопряженности По диагонали таблицы расположены примеры, которые были

правильно распознаны, в остальных ячейках те, которые были отнесены к другому классу. В данном случае дерево правильно классифицировало практически все примеры. Перейдем к основному визуализатору для данного алгоритма – «Дерево решений» Самым значимым фактором оказался параметр «LKG (длина углубления зерна)», т. е. если параметр
«LKG (длина углубления зерна)» меньше 4,7, то зерно относится к кластеру
0.
Рисунок 15 – Дерево решений
Данный визуализатор предоставляет возможность просмотра примеров, которые попали в тот или иной узел, а также информацию об узле. Более удобно посмотреть значимость факторов или атрибутов в визуализаторе «Значимость атрибутов».

Рисунок 16 – Значимость атрибутов
С помощью данного визуализатора можно определить, насколько сильно выходное поле зависит от каждого из входных факторов. Чем больше значимость атрибута, тем больший вклад он вносит при классификации. В данном случае самый большой вклад вносит параметр
«LKG», как и было сказано выше. На визуализаторе «Правила» представлен список всех правил, согласно которым зерно можно отнести к тому или иному сорту пшеницы. Правила можно сортировать по поддержке,
достоверности, фильтровать по выходному классу (к примеру, показать только те правила, согласно
которым зерно относится к определенному классу).
Данные представлены в виде таблицы. Полями этой таблицы являются:
▪номер правила,
▪условие, которое однозначно определяет принадлежность к партии,
▪решение – то, к какому сорту относится зерно с параметрами,
соответствующих этому условию,
▪поддержка – количество и процент примеров из исходной выборки,
которые отвечают этому условию,
▪достоверность – процентное отношение количества верно распознанных примеров, отвечающих данному условию к общему количеству примеров, отвечающих данному условию (сумма верно и ошибочно распознанных примеров).
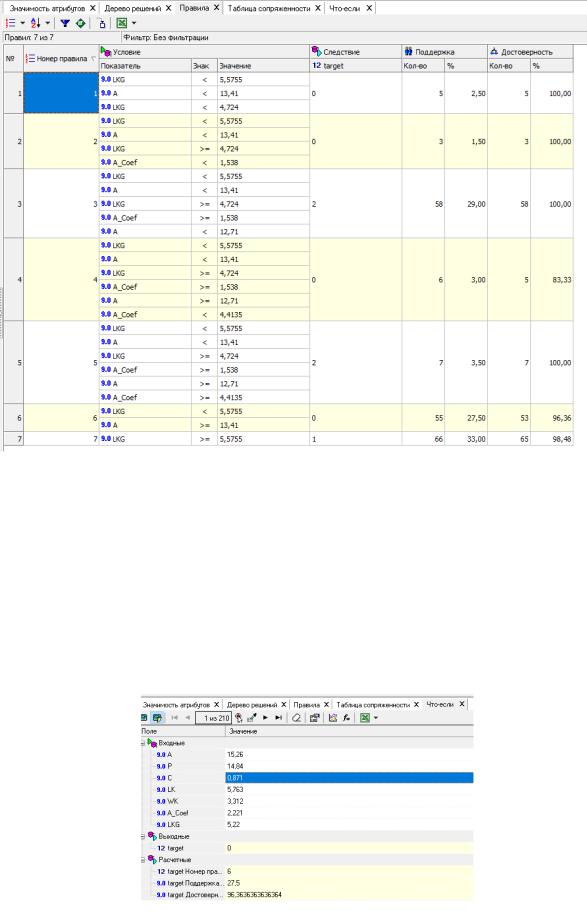
Рисунок 17 – Правила Исходя из данных этой таблицы, аналитик может сказать, что именно
влияет на то, что зерно относится к определенному сорту, какова цена этого влияния (поддержка) и какова достоверность правила.
В «Что-если» можно проанализировать, к какому кластеру относится
зерна пшеницы, обладающими определенными геометрическими
свойства (рис. 18).
Рисунок 18 – Визуализатор «Что-если»
Реализация дерева решений в Python
Классификация на основе дерева решений в Python реализуется в модели
DecisionTreeClassifier из пакета SciKitLearn.
Установка пакета для вычислений SciKitLearn: pip3 install sklearn
Подключение модуля классификации (деревья решений): from sklearn import tree
Инициализация модели дерева решений с максимальной глубиной 3
(max_depth=3):
dtree = tree.DecisionTreeClassifier(max_depth=3)
Перед применением модель должна быть обучена на тренировочной выборке из набора данных:
dtree.fit(in_data_train, out_data_train)
Тренировочную выборку для обучения можно получить из вашего предобработанного набора данных, используя встроенную в sklearn
функцию train_test_split(). Например, выделение из общего набора данных тренировочной (80%) и тестовой выборки (20%):
in_data_train, in_data_test, out_data_train, out_data_test =
train_test_split(in_data, out_data, test_size=0.2,
stratify=out_data)
in_data – предобработанный входной набор данных; out_data – выходной набор данных (значения классов).
Параметр stratify=out_data позволяет делать выборку с сохранением пропорции распределения классов.
Выходной набор данных (out_data) может быть получен простым выделением колонки с классами, при этом, если классы в колонке представлены строковыми категориями, необходимо приведение данных категорий к числовым (int) значениям, например, по индексам:
Дано: [«Синий», «Зеленый», «Красный»]
Приведение по индексам: [0, 1, 2]
Основная задача при реализации и применении дерева решений – это предобработка начального набора данных и формирование in_data. Базовые методы предобработки аналогичны методами, применяемым при реализации логистической регрессии, например: удаление незначительных признаков с помощью анализа по графикам кросс-табуляции или с помощью простого логического анализа; one-hot кодирование строковых категорий и т.д.
Ознакомиться подробнее с методами предобработки данных для классификации можно ознакомиться в методических рекомендациях по работе с логистической регрессией в Python.
После обучения модели можно применять данную модель на любом другом однотипном наборе данных. Например, классификация на тестовой выборке (in_data_test), полученной в результате разделения входных данных:
y_predicted = dtree.predict(in_data_test)
Переменная y_predicted будет содержать список значений классов в порядке, соответствующем записям в in_data_test. Программа из примера добавляет данный список как колонку к in_data_test и сохраняет общую таблицу с результатами в файл dtree_result.csv.
После выполнения классификации программа оценивает точность классификатора на данном наборе и на выходе генерирует отчет с оценкой точности по каждому классу (рис. 19):
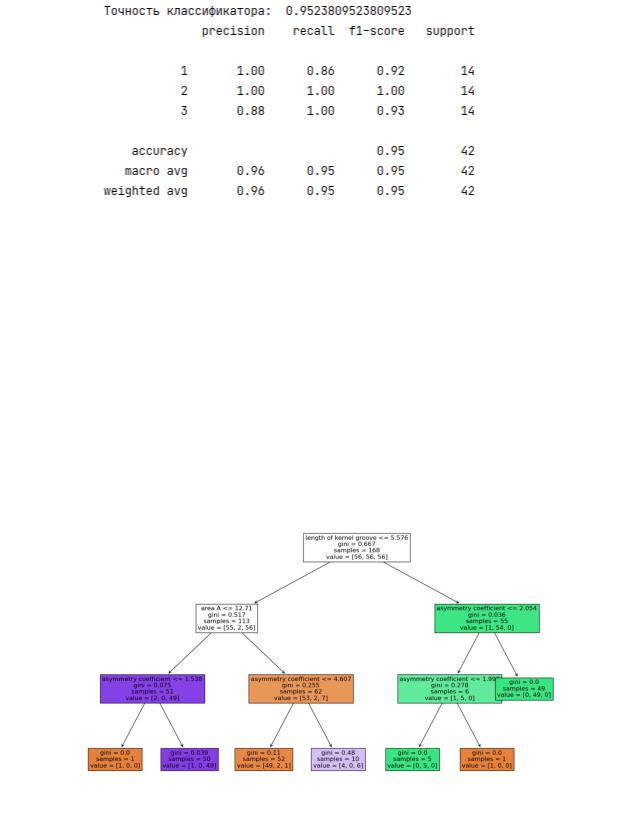
Рисунок 19 – Вывод отчета по итогам прогнозирования
Программа также формирует графическое представление обученной модели с помощью инструкции:
tree.plot_tree(dtree, feature_names=list(dataset.columns),
filled=True, fontsize=12)
Графическое представление автоматически сохраняется в файл
Decision_tree_saved.png:
Рисунок 20 – Графическое представление дерева решений из файла
Decision_tree_saved.png
Рассмотрим параметры, отображённые в узлах дерева.
Первый узел дерева (корень) будет отображать наиболее «весомый» признак, в данном случае – это Length of Kernel Groove <= 5.576. Обратите внимание, что значения ключевых признаков в программе Python и в
Deductor Studio (см. рис. 15) примерно совпадают – это условие также должно быть выдержано и в процессе выполнения лабораторной работы.
Помимо значений ключевых признаков в узлах дерева представлен параметр gini (индекс Джини). Данный параметр количественно определяет
«чистоту» группировки классифицируемых объектов:
gini > 0 – объекты, содержащиеся в этом узле, относятся к разным
классам.
gini = 0 – узел чистый, т.е. в этом узле сгруппирован только один класс.
По значению gini можно также определить достаточную глубину дерева:
если gini < 0.2, то можно предположить, что на данном уровне мы можем получить приемлемую точность классификации.
ВАЖНО: термин «Индекс Джини» (в общем случае) используется как статистический показатель для оценки экономического неравенства, т. о.
индекс Джини, используемый при классификации – это совсем другая величина!
samples – общее количество объектов в данной группе (узле).
value = [c1, c2, c3] – количественное отображение объектов по классам,
т.е. c1 – количество объектов в классе 1, c2 – в классе 2 и т.д. Обратите внимание как данные значения коррелируются с индексом Джини.
Список литературы:
1.Дерево решений: https://basegroup.ru/deductor/function/algorithm/decision-tree
2.Дерево решений: https://habr.com/ru/company/ods/blog/322534/#kak-stroitsya-derevo- resheniy
3.Дерево решений в SciKitLearn: https://www.machinelearningmastery.ru/scikit-learn- decision-trees-explained-803f3812290d
4. Справка по программе ПП «Deductor Studio»