

Программная реализация алгоритмов
Меню находится в функции main и используется для вызова четырёх основных функций и завершения работы программы. Логика работы может быть описана следующим образом:
объявляются две переменные – bool execution = true и char choose. Пока первая равна true, выполняется цикл вывода пунктов меню и считывание пользовательского выбора в choose;
введённый символ проверяется на наличие буквы и если буквы нет, активируется оператор switch, который и запускает выбранную пользователем функций либо выход из программы;
Меню содержит 5 пунктов – вывод всей базы данных, поиск по ней, добавление нового элемента, удаление существующего и остановка программы.
Блок-схема алгоритма работы меню представлена на рисунке 2
При выборе варианта 1 запускается функция db_out(), которая служит для вывода всей сохранённой базы данных на экран с возможностью выполнить сортировку по одному из четырёх параметров – фамилии, дате вылета, авиакомпании и цене билета. На вход не принимается никаких параметров, на выходе их функции происходит возврат числа 0 как знака успешного завершения. Логика работы функции может быть описана следующим образом:
после запуска с помощью функции count_of_lines() подсчитывается количество строк в базе данных, выделяется под неё место в динамическом массиве, после чего массив заполняется данными из файла с помощью функции read_data();
у пользователя запрашивается параметр, по которому будет сортироваться выводимая таблица;
после получения параметра запускается одна из четырёх функций сортировки массива либо не запускается ни одна, если пользователь ввёл соответствующее значение;
на экран построчно выводится вся база данных;
Блок-схема функции db_out() представлена на рисунке 3
Функция search() запускается при выборе параметра 2 используется для запроса у пользователя столбца базы данных, по которому будет вестись поиск, а также для чтения из файла данных в динамический массив аналогичным использованному в предыдущей функции образом. В качестве входного значения принимается параметр bool id_option, значение которого зависит от места, из которого запускается функция search и в дальнейшем передаётся в функций следующего уровня. Логика работы может быть описана следующим образом:
после запуска с помощью функции count_of_lines() подсчитывается количество строк в базе данных, выделяется под неё место в динамическом массиве, после чего массив заполняется данными из файла с помощью функции read_data();
у пользователя запрашивается, в каком столбце базы данных будет осуществляться поиск;
с помощью оператора switch вызывается функция engine(), в которую передаётся адрес массива с данными, его длина, выбор пользователя и параметр id_option;
Блок-схема функции search() представлена на рисунке 4
При выборе функции 3 запускается adding(). Данная функция служит для добавления в базу данных новых записей о билетах. На вход не принимается ни одного параметра, на выходе из функции происходит возврат числа 0 как знака успешного завершения. Логика работы функции может быть описана следующим образом:
создаются переменные для всех столбцов базы данных;
запускается бесконечный цикл. Пользователем вводится фамилия. Если было введено значение «0», происходит выход из цикла;
если нет, то считываются остальные столбцы базы данных. Запрашивается подтверждение записи в файл. Если оно получено, с помощью функции id_function() из другого файла считывается значение id, увеличивается на единицу, записывается обратно и в файл базы данных. После этого в файл базы данных записываются и все остальные столбцы, приведённые к стандартному формату. Начинается новая итерация цикла;
Блок-схема алгоритма работы функции adding() представлена на рисунке 5.
Для удаления элементов из базы данных используется функция deleting(). Логика её работы может быть описана следующим образом:
из файла считываются данные в массив tickets;
вызывается функция search() с параметром id_option = true, которая выводит на экран строки базы данных по запросу с уникальным id у каждой из них;
пользователь вводит id, соответствующие которым строки необходимо удалить из базы данных. Выбранные строки выводятся на экран и спрашивается подтверждение;
если подтверждение получено, открывается для записи с начала файл базы данных и в него последовательно записываются все, кроме выбранных, строки базы данных. Предыдущие записи затираются. Если же подтверждение не получено, функция завершает свою работу;
Блок-схема алгоритма работы функции представлена на рисунке 6
Для подсчета количества записей в базе данных используется count_of_lines(). Данная функция очень простая по своей структуре, но имеет ключевое значение для корректной работы всех остальных модулей программы. Логика её работы может быть описана следующим образом:
создаётся переменная-счётчик со значением 0;
последовательно считываются все строки из файла базы данных. Если прочитанная строка является символом-разделителем, предшествующим каждой записи, переменная-счётчик инкрементируется;
по достижении конца файла функция возвращает значение счётчика;
Блок-схема алгоритма работы функции представлена на рисунке 7
Функция MyToLower() используется для понижения регистра символов, в том числе кириллических. При вызове в неё передаётся символ в виде параметра. Логику работы можно представить следующим образом:
с помощью оператора switch перебираются все варианты и если полученный при вызове заглавный символ есть в списке, функция возвращает его же в пониженном регистре;
Функция Engine() используется функцией search() для выполнения поиска по массиву строк базы данных. Логика её работы может быть представлена следующим образом:
функция получает из вызвавшей функции указатель на массив с элементами базы данных и выбранную пользователем категорию поиска;
с помощью модуля switch, принимающего выбранную категорию, запускается один из четырёх вариантов поиска. Вариант по умолчанию не используется, так как ошибка ввода отсекается ещё на этапе работы в функции search();
в каждом из четырёх вариантов пользователь вводит ключ или ключи для поиска и функция последовательно проходит по массиву и в случае совпадения нужного значения с ключом соответствующая строка выводится на экран;
Блок-схема алгоритма работы функции представлена на рисунке 8
Функция header_print() используется для вывода статичного стандартного заголовка таблицы. Логику её работы можно представить следующим образом:
вывод на экран записанного в коде заголовка таблицы с разделителем, который печатается с помощью функции separator_output();
Функция Separator_output() используется для вывода линии из заданных символов заданной ширины. При вызове в неё передаются символ, которым должен быть выведен разделитель, и ширину разделителя. Логику её работы можно представить следующим образом:
с помощью цикла выводится указанное при вызове количество символов разделителя;
выводится перенос строки;
Функция Print() также является одной из самых простых и предназначена для вывода одной строки базы данных, адрес которой она получает при вызове вместе с параметром id_option. Логику её работы можно представить следующим образом:
в случае, если параметр id_option равен true, выводится id строки. Если нет, то выводится порядковый номер, который также передаётся при вызове функции;
далее через разделители выводятся все остальные поля строки базы данных;
Блок-схема алгоритма работы функции представлена на рисунке 9
Функция read_data() используется для чтения строк из файла базы данных для дальнейшего использования в других функциях программы. Логика её работы может быть представлена следующим образом:
при вызове функция получает указатель на созданный динамический массив, который содержит равное количеству записей в базе данных количество ячеек;
последовательно считываются строки из файла. Как только встречается строка-разделитель, следующие записи считываются в соответствующую ячейку массива. Данный функционал необходим на случай повреждения базы данных – если из файла пропала одна или несколько строк, неправильно заполненными будут поля только одной строки базы данных, а не всех последующих;
Блок-схема алгоритма работы функции представлена на рисунке 10
Функция Word_comparsion() используется для сравнения двух слов для расположения их в алфавитном порядке. На вход принимаются две строки, содержащие слова, возвращается логическое значение. Логика работы функции может быть представлена следующим образом:
в цикле последовательно сравниваются 4 первых символа каждой из строк. В случае, если символ первой строки стоит в алфавите перед соответствующим символом второй строки, функция возвращает значение true. Если иначе – функция возвращает значение false. В случае, если символы равны между собой, сравниваются следующие;
в случае, если все четыре первых символа обеих строк одинаковы, строки признаются равными, возвращается значение true;
В работе программы используются четыре функции сортировки – по фамилии, по дате, по авиакомпании и по цене. В случае со строковыми типами данных – фамилии и авиакомпании – используется сортировка методом пузырька, в случае с числовыми – быстрая сортировка. Логика работы парных функций различается только сравниваемыми значениями, поэтому в отчёте представлены блок-схемы только двух разных функций сортировки. Полный код всех функций расположен в приложении.
Для упрощения алгоритма сортировки по дате реализовано преобразование формата из воспринимаемого человеком в количество дней после начала 2000 года, которое хранится в переменной date_simp структуры ticket.
Функции сортировки по фамилии или по авиакомпании в своей работе сравнивают слова, для чего используют созданную функцию word_comparsion(). В остальном алгоритм ничем не отличается от стандартной сортировки пузырьком.
Блок-схема алгоритма быстрой сортировки по дате представлена на рисунке 11
Блок-схема алгоритма сортировки пузырьком по фамилии представлена на рисунке 12
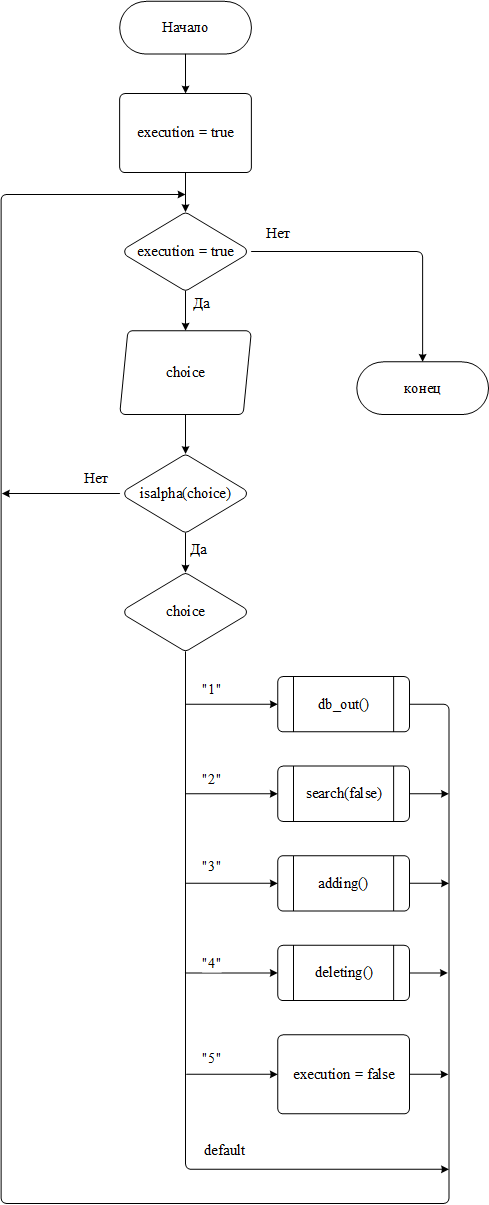
Рисунок 2 – Блок-схема алгоритма работы меню
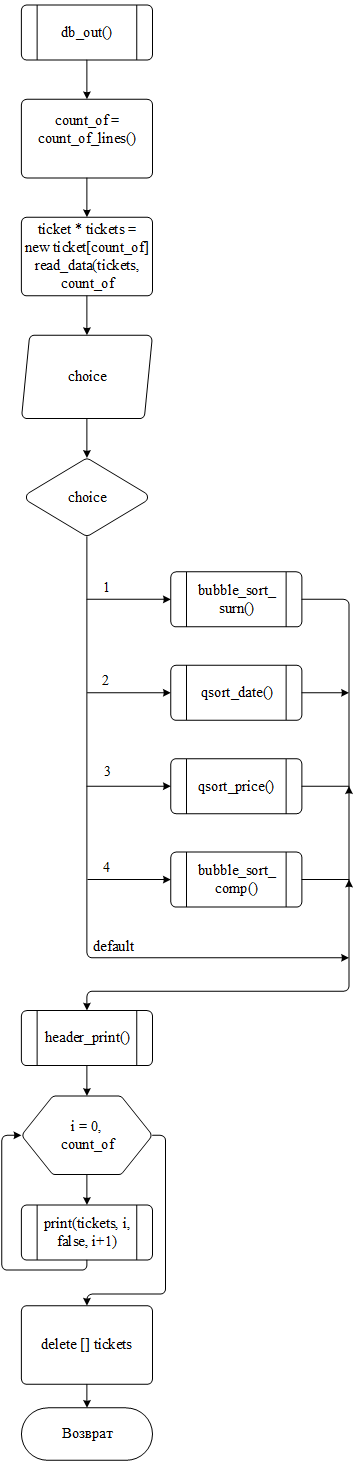
Рисунок 3 – Блок-схема функции db_out()
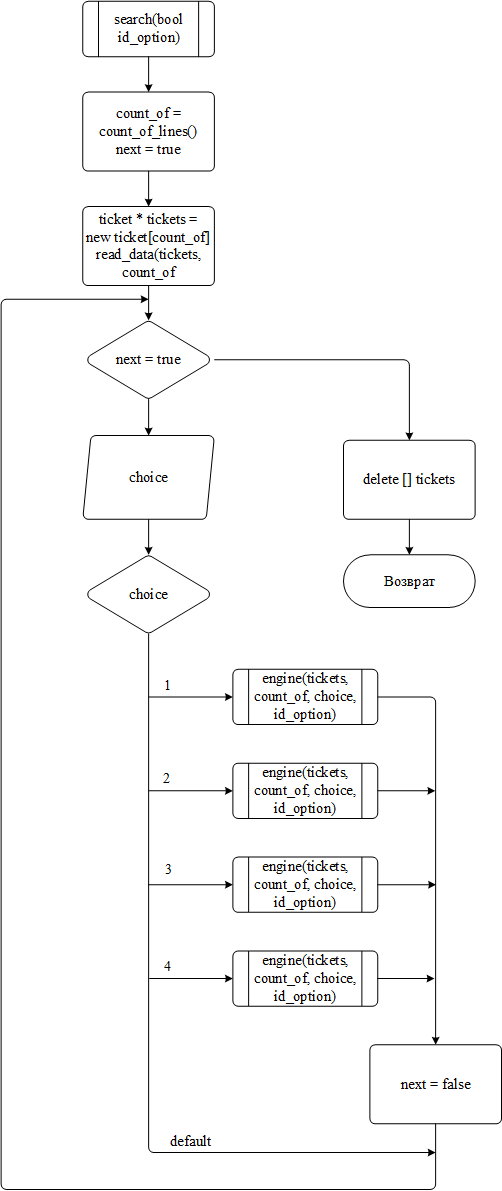
Рисунок 4 – Блок-схема функции search()

Рисунок 5 – Блок-схема функции adding()
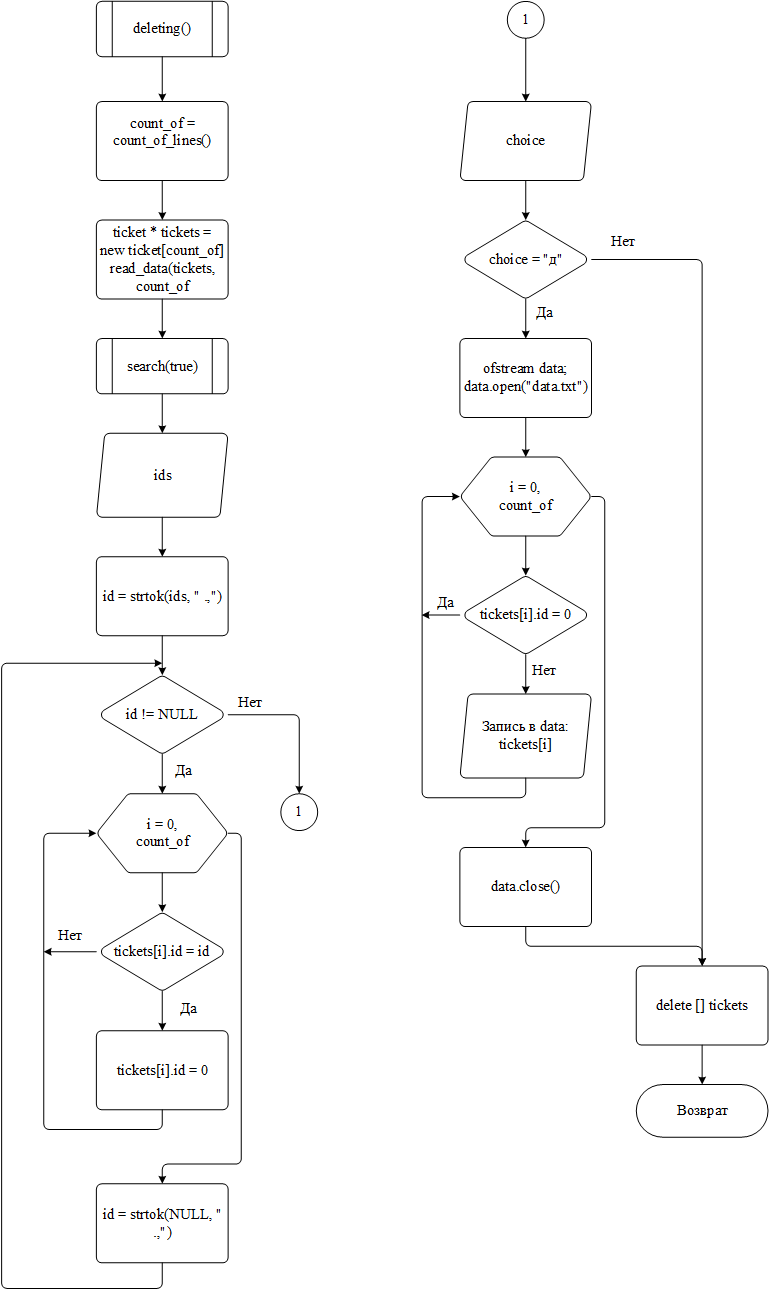
Рисунок 6 – Блок-схема алгоритма работы функции deleting()
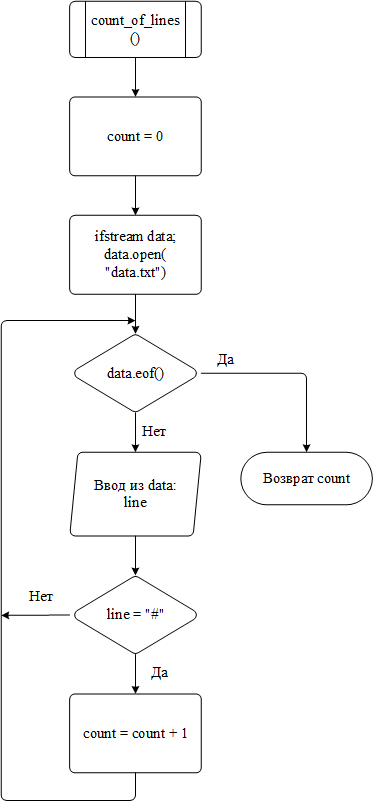
Рисунок 7 – Блок-схема алгоритма работы функции count_of_lines()
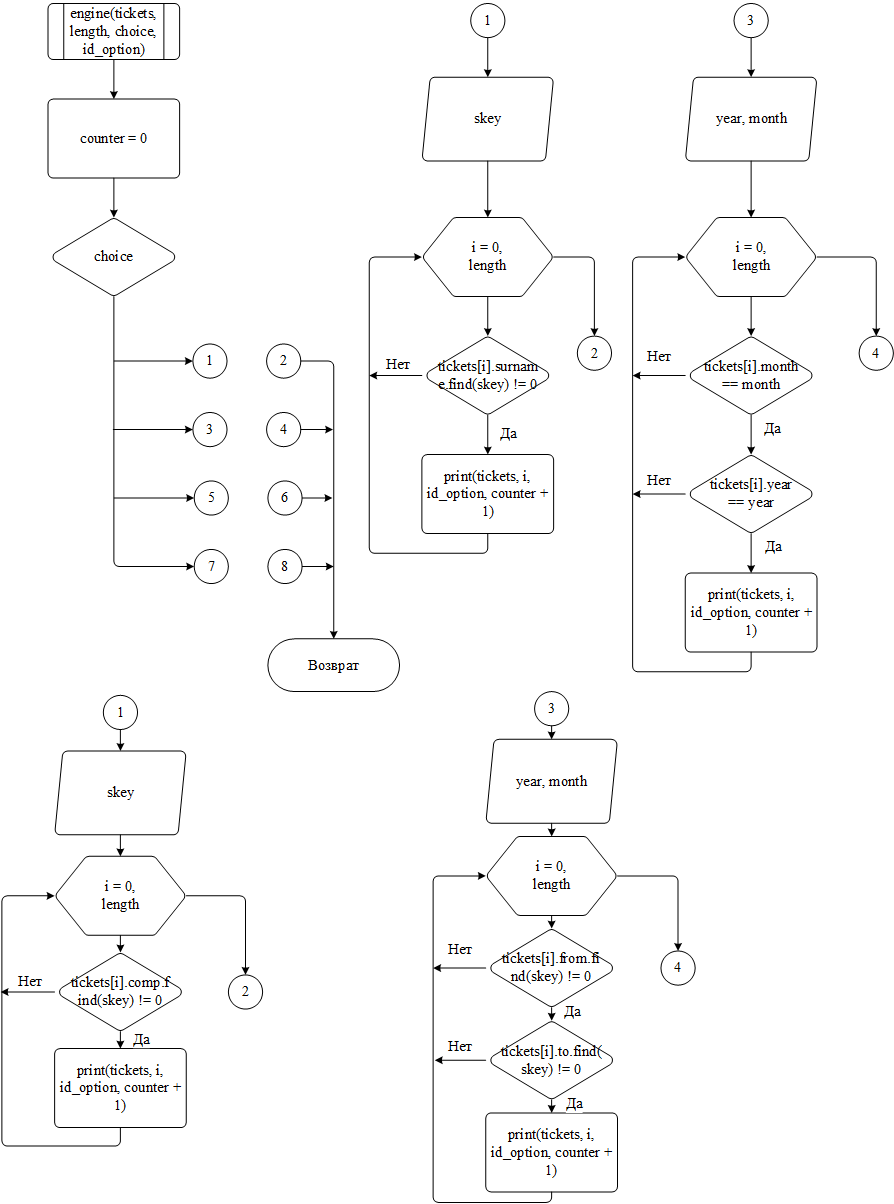
Рисунок 8 – Блок-схема алгоритма работы функции engine()
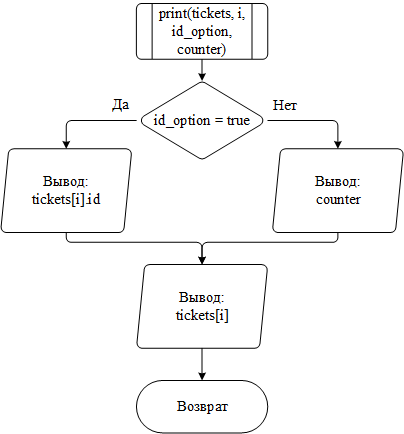
Рисунок 9 – Блок-схема алгоритма работы функции print()
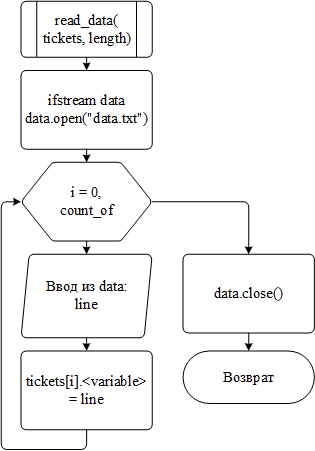
Рисунок 10 – Блок-схема алгоритма работы функции read_data()
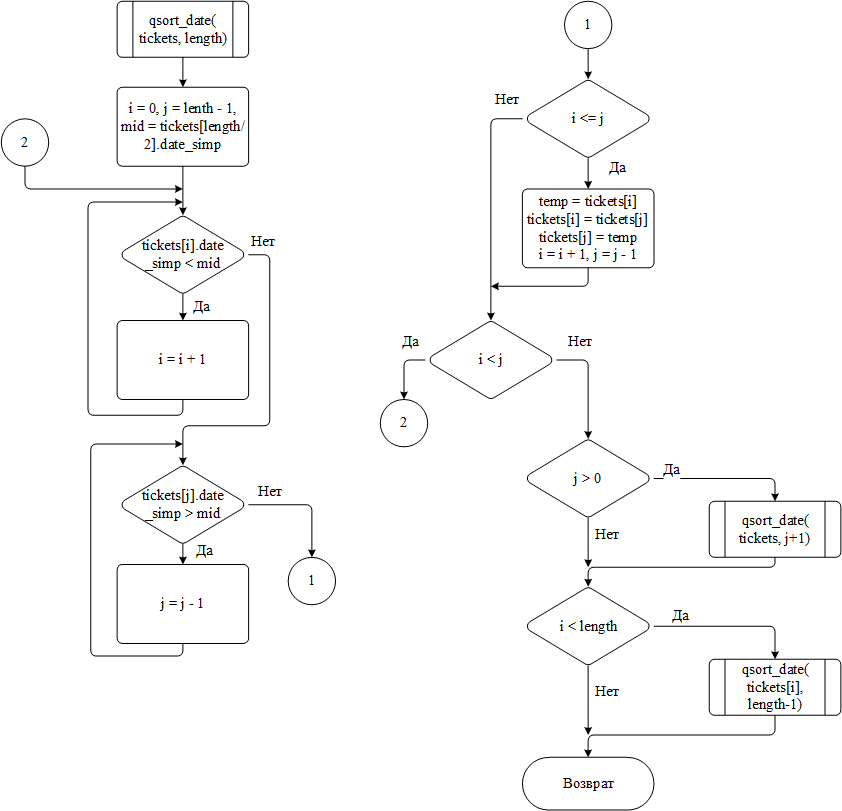
Рисунок 11 – Блок-схема алгоритма быстрой сортировки по дате
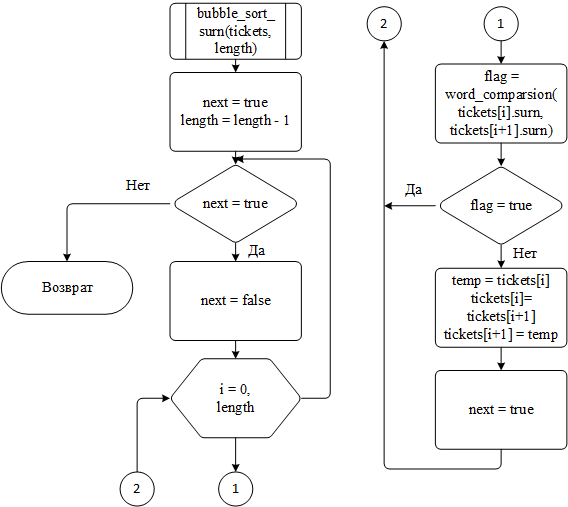
Рисунок 12 – Блок-схема алгоритма сортировки пузырьком по фамилии
В данном разделе представлено описание всех созданных в ходе разработки программы функций. Полностью описан их функционал и логика работы, а также получаемые при вызове и возвращаемые при завершении работы аргументы. Каждая функция сопровождается алгоритмом в виде блок-схемы.