

ЛР-3 MapReduce in Hadoop
.docxМинистерство цифрового развития, связи и массовых коммуникаций Российской Федерации
Ордена Трудового Красного Знамени
Федеральное государственное бюджетное образовательное учреждение высшего образования
Кафедра «Математическая кибернетики и информационные технологии»
Отчёт по лабораторной работе №3
по дисциплине «Математические методы в больших данных» на тему:
««MapReduce in Hadoop»
Выполнили: студенты БСТ****
Проверила: Пугачёва Мария Алексеевна
Москва 2021
Оглавление
Министерство цифрового развития, связи и массовых коммуникаций Российской Федерации 1
Ордена Трудового Красного Знамени 1
Федеральное государственное бюджетное образовательное учреждение высшего образования 1
Кафедра «Математическая кибернетики и информационные технологии» 1
Отчёт по лабораторной работе №3 1
по дисциплине «Математические методы в больших данных» на тему: 1
««MapReduce in Hadoop» 1
1
Выполнили: студенты БСТ**** 1
Проверила: Пугачёва Мария Алексеевна 1
1
Москва 2021 1
Оглавление 1
Цель работы: ознакомится с процессом MapReduce на примере подсчета слов в файле. 3
Задачи: Написать программу для подсчета количества слов на языке 3
java или воспользоваться примерами программ. И выполнить следующую последовательность действий: 3
1. Перед запуском примера необходимо создать места ввода и вывода в формате HDFS. 3
2. Создайте примеры текстовых файлов для использования в качестве 3
входных данных и переместите их в каталог/user/cloudera/wordcount/input в HDFS. Вы можете использовать любые файлы по своему выбору; 3
3. Скомпилируйте класс WordCount. 3
4. Создайте файл JAR для приложения WordCount. 3
5. Запустите приложение WordCount из файла JAR, передав пути к входным и выходным каталогам в формате HDFS. 3
6. Если вы хотите запустить образец снова, сначала вам нужно удалить выходной каталог. Используйте следующую команду. 3
hadoop fs -rm -r /user/cloudera/wordcount/output 3
1. Создание каталога ввода для программы 4
4
2. Создание файлов ввода и их перемешение в каталог ввода 4
4
3. Компиляция класса WordCount. 4
4
4. Создание jar файла. 4
5
5. Запуск WordCount 5
5
6
6
6
6. Результат 7
7
Мы ознакомились с процессом MapReduce на примере подсчета слов в файле. 8
Задание
Цель работы: ознакомится с процессом MapReduce на примере подсчета слов в файле.
Задачи: Написать программу для подсчета количества слов на языке
java или воспользоваться примерами программ. И выполнить следующую последовательность действий:
Перед запуском примера необходимо создать места ввода и вывода в формате HDFS.
Создайте примеры текстовых файлов для использования в качестве
входных данных и переместите их в каталог/user/cloudera/wordcount/input в HDFS. Вы можете использовать любые файлы по своему выбору;
Скомпилируйте класс WordCount.
Создайте файл JAR для приложения WordCount.
Запустите приложение WordCount из файла JAR, передав пути к входным и выходным каталогам в формате HDFS.
Если вы хотите запустить образец снова, сначала вам нужно удалить выходной каталог. Используйте следующую команду.
hadoop fs -rm -r /user/cloudera/wordcount/output
Выполнение работы
1. Создание каталога ввода для программы

2. Создание файлов ввода и их перемешение в каталог ввода
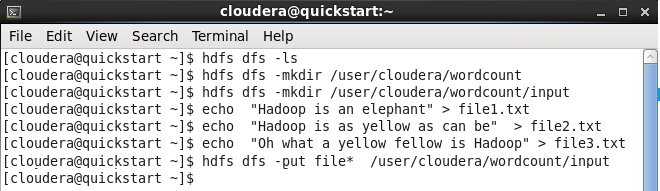
3. Компиляция класса WordCount.

4. Создание jar файла.

5. Запуск WordCount
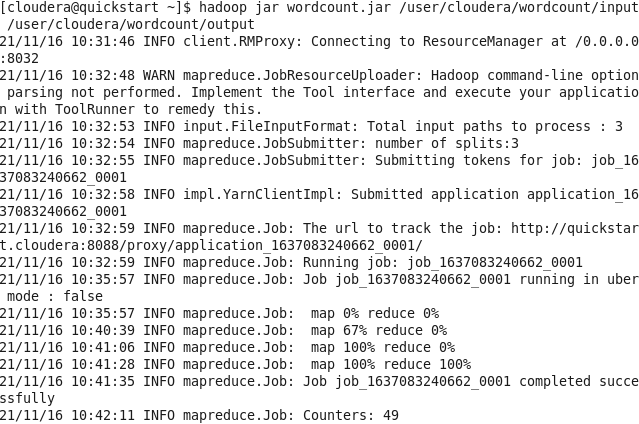
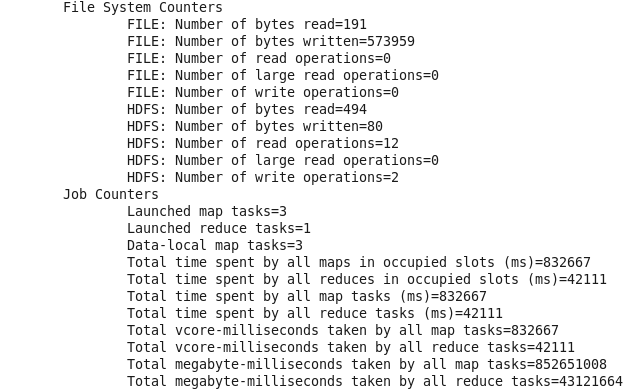
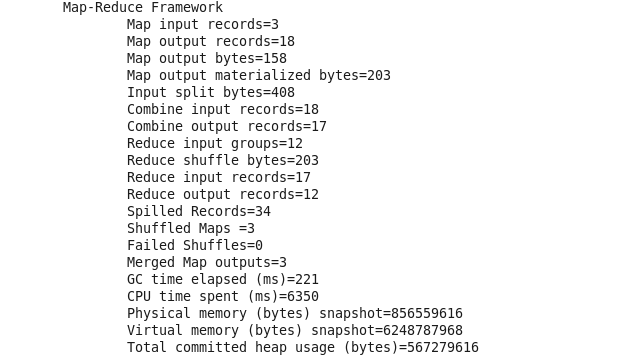

6. Результат

Вывод
Мы ознакомились с процессом MapReduce на примере подсчета слов в файле.