

§7. Приближенное решение задач оптимального управления методом динамического программирования Беллмана
Рассмотрим (только для простоты записи) задачу оптимального управления для стационарной динамической системы и критерием оптимальности, зависящим только от вектора управления:
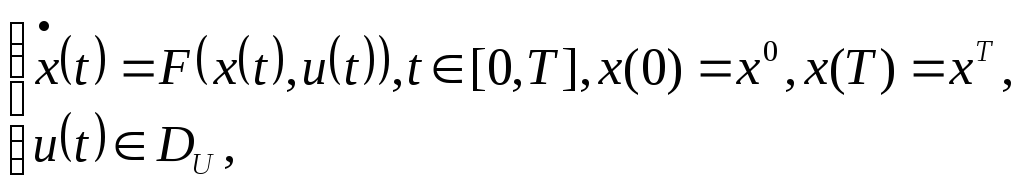 (1)
(1)
 (2)
(2)
Обратим
внимание на то, что, в отличие от того,
как это делалось ранее, для обозначения
![]() фазового вектора использована маленькая
букваx,
а для обозначения
фазового вектора использована маленькая
букваx,
а для обозначения
![]() вектора управления – маленькая букваu.
вектора управления – маленькая букваu.
Покроем
интервал
![]() сеткой
сеткой![]() с шагом
с шагом![]() (рисунок 1).
(рисунок 1).

Рисунок
1 - Равномерная
временная сетка на интервале
![]()
Систему ОДУ (1) заменим ее конечно-разностным аналогом
![]() , (3)
, (3)
а функционал (2) заменим его приближенным значением, вычисленным по формуле прямоугольников
 , (4)
, (4)
где
![]() есть
есть![]() -матрица.
-матрица.
Таким образом, задача оптимального управления (1), (2) в дискретной форме имеет вид (3), (4).
Аналогично
матрице
![]() введем в рассмотрение
введем в рассмотрение![]() -матрицу
-матрицу![]() и сформулируем принцип оптимальности
(см. параграф 6) для задачи (3), (4).
и сформулируем принцип оптимальности
(см. параграф 6) для задачи (3), (4).
Утверждение
1 (принцип оптимальности для дискретной
системы). Пусть
![]() =
=![]() - оптимальное управление для задачи
оптимального управления (3), (4) и пусть
- оптимальное управление для задачи
оптимального управления (3), (4) и пусть![]() =
=![]() - соответствующая оптимальная фазовая
траектория. Тогда для любых
- соответствующая оптимальная фазовая
траектория. Тогда для любых![]() управление
управление![]() и соответствующая траектория
и соответствующая траектория![]() будут оптимальными на интервале времени
будут оптимальными на интервале времени![]() ●
●
Другими
словами, если траектория
![]() оптимальна, то и любая ее завершающая
часть, начинающаяся из точки
оптимальна, то и любая ее завершающая
часть, начинающаяся из точки![]() ,
будет оптимальной на последних
,
будет оптимальной на последних![]() шагах. А всякая другая траектория из
того же состояния, вообще говоря, не
является оптимальной на этих шагах
(рисунок 2).
шагах. А всякая другая траектория из
того же состояния, вообще говоря, не
является оптимальной на этих шагах
(рисунок 2).

Рисунок
2 - К принципу
оптимальности для дискретной системы.
![]()
Обозначим
значение функционала (4) на завершающих
![]() шагах
шагах
![]() ,
,
![]() .
.
Тогда
если на завершающих
![]() шагах управление оптимально, имеет
место равенство
шагах управление оптимально, имеет
место равенство
![]() =
=![]() , (5)
, (5)
где
![]() -функция
Беллмана последних
-функция
Беллмана последних
![]() шагов для дискретной задачи оптимального
управления (3), (4).
шагов для дискретной задачи оптимального
управления (3), (4).
Из
утверждения 1 следует, что на последнем
шаге (когда
![]() )
)
![]() =
= . (6)
. (6)
Найдем
рекуррентное соотношение, связывающее
между собой функции
![]() ,
,![]() .
Положим для этого, что функция
.
Положим для этого, что функция![]() известна. Тогда если наk-ом
шаге с начальным состоянием
известна. Тогда если наk-ом
шаге с начальным состоянием
![]() выбрать управление
выбрать управление![]() ,
то процесс перейдет в состояние
,
то процесс перейдет в состояние![]() (начальное для последующих
(начальное для последующих![]() шагов). Если этот переход оптимален, то
опять же из утверждения 1 следует искомое
соотношение
шагов). Если этот переход оптимален, то
опять же из утверждения 1 следует искомое
соотношение
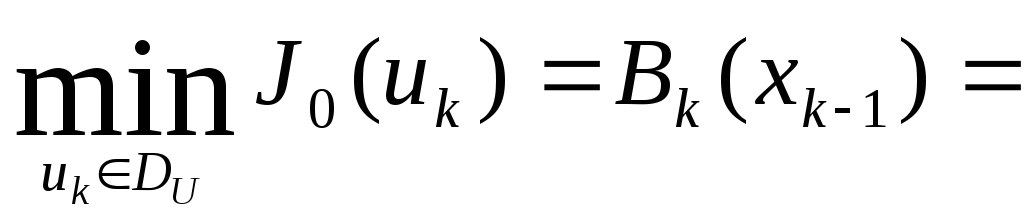
 . (7)
. (7)
Уравнения
(6), (7) позволяют последовательно найти
функции
![]() ,
,![]() ,…,
,…,![]() и называютсяуравнениями
Беллмана для дискретной системы
(3), (4). Отметим, что одновременно с
нахождением функций
и называютсяуравнениями
Беллмана для дискретной системы
(3), (4). Отметим, что одновременно с
нахождением функций
![]() ,
,![]() ,…,
,…,![]() оказываются определенными и управления
оказываются определенными и управления![]() .
Поскольку управление
.
Поскольку управление![]() зависит от состояния
зависит от состояния![]() ,
это управление называетсяусловно
оптимальным управлением.
,
это управление называетсяусловно
оптимальным управлением.
После
нахождения условно оптимальных управлений
![]() можно найти искомые управления
можно найти искомые управления![]() по следующей схеме:
по следующей схеме:
поскольку состояние
 известно, находим управление
известно, находим управление ;
с этим управлением по формуле (3)
находим состояние
;
с этим управлением по формуле (3)
находим состояние ;
;поскольку состояние
 известно, находим управление
известно, находим управление ;
с этим управлением по формуле (3) находим
состояние
;
с этим управлением по формуле (3) находим
состояние ;
;……
поскольку состояние
 известно, находим управление
известно, находим управление ;
очевидно, что
;
очевидно, что =
= .
.
Схема приближенного решения задач оптимального управления методом динамического программирования Беллмана
Этап 1
Шаг 1. Из условия (6) находим условно оптимальное управление
 и функцию Беллмана
и функцию Беллмана .
.Шаг 2. Используя результаты предыдущего шага, из условия (7) находим условно оптимальное управление
 и функцию Беллмана
и функцию Беллмана .
.…………………..
Шаг N. Используя результаты предыдущего шага, из условия (7) находим условно оптимальное управление
 и функцию Беллмана
и функцию Беллмана .
.