

Основы теории безопасного преобразования биометрических данных в код личного ключа доступа. Язов Ю.К., Остапенко О.А
.pdfИдеальная настройка порога квантователя должна приводить к нулевому значению энтропии разряда кода «Свой»:
var( i |
max(H (" xi |
")) 1.0 бит; |
|
|
) |
H ("ci ") 0.0 бит. |
(2.3) |
||
|
|
|
||
В этом случае вероятность ошибки первого рода (отказ в доступе «Своему») становится нулевой, преобразователь «биометрия-код» безошибочно узнает образ «Свой», и одновременно обеспечивается максимально возможное значение энтропии для кодов «Чужой». Процедура настройки однопороговых квантователей поясняется на рис. 2.1 и 2.2, при этом необходимо иметь в виду следующее.
Обычно распределение данных «Свой» значительно ỳже распределения данных «Все Чужие», и это зависит от стабильности воспроизведения биометрического образа. На сегодняшний день самыми стабильными являются данные рисунка радужной оболочки глаза [3]. Данные рис. 2.1 и 2.2 соответствуют рукописному почерку, для которого вариации параметров образа «Свой» оказываются примерно в три раза меньше вариаций того же биометрического параметра для образов «Все Чужие».
Так как первоочередной задачей является хорошее распознавание биометрических данных «Свой», при настройке порога выбирают максимум или минимум значений распределения параметра «Свой». Выбор осуществляют исходя из близости правой или левой границы распределения «Свой» к центру распределения «Все Чужие». Чем ближе граница «Свой» в центру распределения
21
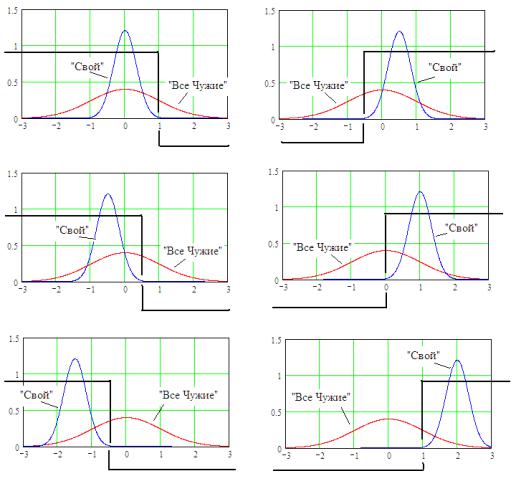
параметра образов «Все Чужие», тем выше значение энтропии данных «Чужие».
Рис. 2.3. Одностороннее выделение образа «Свой» состоянием «1» по порогу
Из рис. 2.3 видно, что в первом приближении распределения данных «Свой» достаточно хорошо описыва-
22
ются нормальными законами. В связи с этим при настройке порогов квантователей можно пользоваться гипотезой нормальности, считая, что практически все данные «Свой» попадают в интервал [E( )-3 ( ); E( )+3 ()]. То есть для настройки значения порога квантования достаточно знать среднеквадратическое отклонение данных «Свой» ( ), математическое ожидание данных «Свой» E(), а также математическое ожидание данных «Все Чужие» Е( ), которое обычно оказывается нулевым Е()=0.
2.3. Энтропия биометрических кодов «Чужой»
Параллельно с высоким уровнем узнавания образов «Свой» при настройке квантователей нужно обеспечить высокий уровень отклонения «Чужих» (высокий уровень энтропии кодов «Все Чужие»). В этом отношении описанный выше алгоритм настройки квантователей «нечетких экстракторов» весьма конструктивен, так как каждый из квантователей настраивается независимо. Оценить энтропию i-го разряда после настройки можно по Шеннону путем учета вероятностей появления короткого алфавита, состоящего всего из двух состояний «0» и «1»:
Н("xi ") P("0i ") log2 (P("0i ")) P("1i ") log2 (P("1i ")) (2.4)
Очевидно, что нет каких-либо проблем и при вычислении совместной энтропии двух разрядов биокода, так как алфавит их возможных состояний остается коротким:
|
|
|
|
4 |
|
|
|
|
|
|
|
|
|
|
Н("x |
, x |
2 |
") |
P ("x |
, x |
2 |
") log |
2 |
(P ("x |
, x |
2 |
")) |
||
1 |
|
|
i |
1 |
|
|
i |
1 |
|
|
||||
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
(2.5)
23

Проблемы вычисления энтропии по Шеннону начинаются для биокодов с большим числом разрядов. Так, биокод, полученный Даугманом [3] для рисунка радужной оболочки глаза, имеет 2048 разрядов. Для того чтобы оценить энтропию столь длинного кода, придется использовать огромное число опытов. Задача вычисления энтропии по Шеннону кодов длиной 2048 бит
2 |
2 |
048 |
|
|
Н("x |
, x |
2 |
,..., x |
") |
P ("x |
, x |
2 |
,..., x |
") log |
2 |
(P ("x |
, x |
2 |
,..., x |
")) |
||
1 |
|
|
2048 |
i |
1 |
|
|
2048 |
i |
1 |
|
|
2048 |
||||
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
(2.6)
является технически не выполнимой.
Обойти проблему вычисления энтропии длинных кодов удается, если отказаться от процедур Шеннона, в которых предполагается поиск редких событий при обработке больших массивов исходных кодов. Необходимо от наблюдения редких событий перейти к предсказанию вероятности их появления. Для этой цели необходимо перейти из пространства кодов «Все Чужие» - "x" в пространство расстояний Хэмминга1 между кодом аутентификации «Свой» и кодами «Все Чужие»
2048 h(" x") " xi " "ci " i 1
(2.7)
Пример распределения расстояний Хэмминга между кодом аутентификации «Свой» и кодами «Все Чужие» дан на рис. 2.4 для кодов длинной 2048 бит.
1 метрика была сформулирована Ричардом Хэммингом для определения меры различия между двоичными векторами и определяется как число позиций, в которых они различны
24
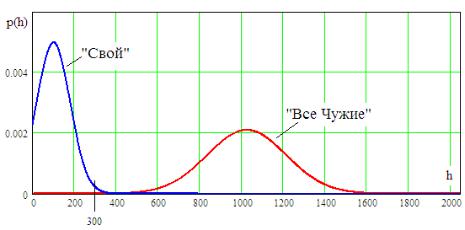
Рис. 2.4. Распределения расстояний Хэмминга между кодом «Свой» и «Все Чужие», а также между кодом «Свой» и ошибочными кодами «Свой»
Корректно настроенные квантователи всегда дают практически нормальный закон распределения расстояний Хэмминга до кодов «Все Чужие» с математическим ожиданием равным половине длины биокода.
Для настройки квантователей необходимо знать математическое ожидание и среднеквадратическое отклонение распределения данных «Свой» по каждому из биометрических параметров. Если обучать «нечеткий экстрактор» на 20 примерах образа «Свой», относительная ошибка вычисления математического ожидания параметра с высокой вероятностью составит примерно 20%. Сходные результаты получаются и при оценке среднеквадратического отклонения данных «Свой».
Из-за малого числа используемых при обучении примеров образа «Свой» не удается точно настроить квантователи контролируемых биометрических параметров. По этой причине коды-отклики на образ «Свой» не совпадают
25

с кодом аутентификации «Свой». На рис. 2.3 эта ситуация отображена появлением распределения расстояний Хэмминга между кодом аутентификации «Свой» и ошибочными кодами «Свой».
Обычно ошибки кодов «Свой» в «нечетких экстракторах» правят классическими избыточными самокорректирующимися кодами [9-11]. Предположим, что 97% неверных бит биокода не будут превышать значения 300 бит и будут правиться за счет избыточности самокорректирующимся кодом. В этом случае вероятность ошибок второго рода «нечеткого экстрактора» составит:
|
1 |
|
300 |
|
(E(h(" x ") u) |
2 |
|
|
|||
P |
|
|
exp |
|
du. |
||||||
|
|
|
|
2 |
|
|
|
||||
2 |
(h(" x ")) |
2 |
|
2 |
(h(" x ")) |
|
|
||||
|
|
|
|
|
|
|
|
||||
(2.8)
Если известна вероятность ошибок второго рода, то можно оценить энтропию кодов длиной 2048 бит:
Н (" x1, x2 ,..., x2048 ") log2 (P2 ). |
(2.9) |
Заметим, что при вычислениях по формулам (2.8) и (2.9) нет необходимости использовать миллиарды биокодов «Чужие». Вполне достаточно 200 кодов «Все Чужие»: этих данных вполне достаточно для оценки математического ожидания и среднеквадратического отклонения распределения расстояний Хэмминга «Все Чужие» с относительной погрешностью порядка 5%.
26
2.4.Применение классических кодов с избыточностью для корректировки биометрических ошибок
Следует подчеркнуть, что длина ключа криптографической аутентификации не должна быть большой, так длина криптографического ключа для шифрования по отечественному стандарту ГОСТ 28147-89 составляет 256 бит, такую же длину ключа использует ГОСТ Р 34.10-94 при формировании цифровой подписи. Получается, что биокод Даугмана [3] длинной 2048 бит оказывается в 8 раз длиннее кода ключа доступа. Следует воспользоваться этим обстоятельством для обнаружения и корректировки ошибок в био-коде. Общий принцип обнаружения и корректировки ошибок избыточными кодами иллюстрируется табл.2.1.
Таблица 2.1 Обнаружение ошибок и их исправление простейшим
кодом с пятикратным дублированием
Повторение |
1* |
1 |
0 |
1* |
1 |
0 |
1 |
1 |
|
0 |
0* |
0 |
0 |
1 |
1* |
1 |
0* |
||
0 |
1 |
0 |
0 |
1 |
1* |
1 |
1 |
||
0 |
1 |
0 |
0 |
0* |
0 |
1 |
1 |
||
1* |
1 |
0 |
0 |
1 |
0 |
0* |
0* |
||
|
|||||||||
ИТОГО |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
Как видно из табл. 2.1, простейший код с пятикратным дублированием информации длиной 5х8=40 бит позволяет исправлять до двух ошибок в каждом из 8 столбцов, то есть до 16 ошибок (до 40%) при избыточности в 400%. Код строится на анализе частоты появления состояния «0» и «1» в столбцах. Верным считается наиболее вероятное состояние анализируемых разрядов в столбце. По этой причине код не способен обнаруживать и править 3 и
27
лее ошибки в одном столбце, что является его главным недостатком.
Этот недостаток ослабляется, если пользоваться более сложными кодами с более сложными правилами обнаружения и корректировки ошибок [9-11]. Обычно классические самокорректирующиеся коды имеют явно выраженную информационную часть и избыточную часть, которая получается из информационной части. Структура получения подобных кодов и их применения приведена на рис. 2.5.
Вход |
|
|
|
Вычисление избыточной части |
|
Среда, вносящая ошибки |
в передаваемые данные |
|
|
|
|||||
|
|
|
|||||
|
|
|
|
||||
|
|
||||||
|
|
|
|
|
|
|
Обнаружение и корректировка |
ошибок |
Выход |
|
|
|
Рис. 2.5. Ввод и устранение избыточной информации при использовании самокорректирующихся кодов
Независимо от используемого правила обнаружения ошибок все классические самокорректирующиеся коды требуют большой избыточности и не могут эффективно исправлять более половины ошибок в коде. Для корректировки 4% ошибок требуется пятидесятипроцентная избыточность кода. Для полной корректировки 6% ошибок, в
28
любой их последовательности требуется код с избыточность 100%. Размер избыточной части кода экспоненциально растет с ростом необходимого числа обнаруживаемых и исправляемых ошибок. Для того чтобы править порядка 50% ошибок, самокорректирующийся код должен практически полностью состоять из избыточной части, имея очень короткую информативную часть.
Кроме того, классические самокорректирующиеся коды строились для каналов связи, где хорошо работает гипотеза равновероятного распределения ошибок. Для биометрических кодов гипотеза равновероятного распределения ошибок в разрядах неприемлема. Квантование биометрических данных обычно приводит к появлению стабильных и нестабильных разрядов со строго фиксированным положением. Информацию о показателе стабильности каждого из разрядов кода «Свой» классические самокорректирующиеся коды не способны учитывать и как следствие их корректирующая способность уступает нейросетевым корректорам биометрических ошибок. Преимущества нейросетевых корректоров обусловлено тем, что во время обучения они становятся способны учитывать местоположение и показатель стабильности корректируемых разрядов.
29
2.5. Компрометация биометрических данных образа «Свой» в пространстве расстояний Хэмминга
Важным элементом биометрических технологий защиты информации является тайна применяемого при аутентификации образа «Свой». Проще всего сохранить втайне данные биометрического образа «Свой», разместив их в аппаратной части средств биометрической аутентификации и исключив возможность программного доступа к «нечеткому экстрактору». Подобное техническое решение дороже программной защиты «нечетких экстракторов», в связи с этим значительное внимание уделяется исследованию вопросов трудоемкости извлечения биометрической информации из «нечетких экстракторов».
Из теории известно, что обратные задачи всегда намного сложнее прямых задач. То есть настроить квантователи «нечеткого экстрактора» и синтезировать для него соответствующий самокорректирующийся код много проще, чем извлечь данные из настроенного «нечеткого экстрактора». Попытаемся оценить сложность задачи восстановления неизвестного биометрического образа «Свой», если известен биометрический код аутентификации «Свой». В этом случае можно восстановить избыточную часть самокорректирующегося кода «Свой» и экспериментально найти коды-отклики тестовой базы образов «Чужие». В итоге можно получить гистограмму распределение расстояний Хэмминга между кодами «Свой» и «Чужие» (рис. 2.6). Практика показала, что для проведения подобного численного эксперимента вполне достаточно тестовой базы примерно из 10 000 биометрических образов «Чужой».
30